本文主要是介绍NETDEV 协议,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是NAPI
NAPI是linux一套最新的处理网口数据的API,linux 2.5引入的,所以很多驱动并不支持这种操作方式。简单来说,NAPI是综合中断方式与轮询方式的技术。数据量很低与很高时,NAPI可以发挥中断方式与轮询方式的优点,性能较好。如果数据量不稳定,且说高不高说低不低,则NAPI会在两种方式切换上消耗不少时间,效率反而较低一些。
下面会用到netdev_priv()这个函数,这里先讲解下,每个网卡驱动都有自己的私有的数据,来维持网络的正常运行,而这部分私有数据放在网络设备数据后面(内存概念上),这个函数就是通过dev来取得这部分私有数据,注间这部分私有数据不在dev结构体中,而是紧接在dev内存空间后。
static inline void *netdev_priv(const struct net_device *dev)
{
return (char *)dev + ALIGN(sizeof(struct net_device), NETDEV_ALIGN);
}
弄清这个函数还得先清楚dev这个结构的分配
alloc_netdev() -> alloc_netdev_mq()
struct net_device *alloc_netdev_mq(int sizeof_priv, const char *name,
void (*setup)(struct net_device *), unsigned int queue_count)
{
……
alloc_size = sizeof(struct net_device);
if (sizeof_priv) {
/* ensure 32-byte alignment of private area */
alloc_size = ALIGN(alloc_size, NETDEV_ALIGN);
alloc_size += sizeof_priv;
}
/* ensure 32-byte alignment of whole construct */
alloc_size += NETDEV_ALIGN - 1;
p = kzalloc(alloc_size, GFP_KERNEL);
if (!p) {
printk(KERN_ERR "alloc_netdev: Unable to allocate device./n");
return NULL;
}
……….
}
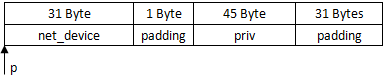
可以看到,dev在分配时,即在它的后面分配了private的空间,需要注意的是,这两部分都是32字节对齐的,如下图所示,padding是加入的的补齐字节:

举个例子,假设sizeof(net_device)大小为31B,private大小45B,则实际分配空间如图所示:
b44_interrupt():当有数据包收发或发生错误时,会产生硬件中断,该函数被触发
struct b44 *bp = netdev_priv(dev);
取出网卡驱动的私有数据private,该部分数据位于dev数据后面
istat = br32(bp, B44_ISTAT);
imask = br32(bp, B44_IMASK);
读出当前中断状态和中断屏蔽字
if (istat) {
……
if (napi_schedule_prep(&bp->napi)) {
bp->istat = istat;
__b44_disable_ints(bp);
__napi_schedule(&bp->napi);
}
设置NAPI为SCHED状态,记录当前中断状态,关闭中断,执行调度
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
list_add_tail(&n->poll_list, &__get_cpu_var(softnet_data).poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
local_irq_restore(flags);
}
__get_cpu_var():得到当前CPU的偏移量,与多CPU有关
将napi的poll_list加入到softnet_data队列尾部,然后引起软中断NET_RX_SOFTIRQ。
似乎还没有真正的收发函数出现,别急;关于软中断的机制请参考资料,在net_dev_init()[dev.c]中,注册了两个软中断处理函数,所以引起软中断后,最终调用了net_rx_action()。
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
下面来看下net_rx_action()函数实现:
static void net_rx_action(struct softirq_action *h)
{
struct list_head *list = &__get_cpu_var(softnet_data).poll_list; // [1]
……
n = list_first_entry(list, struct napi_struct, poll_list); // [2]
……
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight); // [3]
trace_napi_poll(n);
}
……
}
__get_cpu_var是不是很熟悉,在b44_interrupt()中才向它的poll_list中加入了一个napi_struct;代码[2]很简单了,从poll_list的头中取出一个napi_struct,然后执行代码[3],调用poll()函数;注意到这里在interrupt时,会向poll_list尾部加入一个napi_struct,并引起软中断,在软中断处理函数中,会从poll_list头部移除一个napi_struct,进行处理,理论上说,硬件中断加入的数据在其引起的软中断中被处理。
poll函数实际指向的是b44_poll(),这是显而易见的,但具体怎样调用的呢?在网卡驱动初始化函数b44_init_one()有这样一行代码:
netif_napi_add(dev, &bp->napi, b44_poll, 64);
而netif_napi_add()中初始化napi并将其加入dev的队列,
napi->poll = poll;
这行代码就是b44_poll赋给napi_poll,所以在NET_RX_SOFTIRQ软中断处理函数net_rx_action()中执行的b44_poll()。
怎么到这里都还没有收发数据包的函数呢!b44_poll()就是轮询中断向量,查找出引起本次操作的中断;
static int b44_poll(struct napi_struct *napi, int budget)
{
……
if (bp->istat & (ISTAT_TX | ISTAT_TO))
b44_tx(bp);
……
if (bp->istat & ISTAT_RX)
work_done += b44_rx(bp, budget);
if (bp->istat & ISTAT_ERRORS)
……
}
可以看到,查询了四种中断:ISTAT_TX、ISTAT_TO、ISTAT_RX、ISTAT_ERRORS
#define ISTAT_TO 0x00000080 /* General Purpose Timeout */
#define ISTAT_RX 0x00010000 /* RX Interrupt */
#define ISTAT_TX 0x01000000 /* TX Interrupt */
#define ISTAT_ERRORS (ISTAT_DSCE|ISTAT_DATAE|ISTAT_DPE|ISTAT_RDU|ISTAT_RFO|ISTAT_TFU)
如果是TX中断,则调用b44_tx发送数据包;如果是RX中断,则调用b44_rx接收数据包。至此,从网卡驱动收发数据包的调用就是如此了。
最后,给个总结性的图:

纠结了好多天,终于弄懂了B440X的处理。
上篇讲到通过中断,最终网卡调用了b44_rx()来接收报文
对这个函数中的一些参数,可以这样理解:
bp->rx_cons – 处理器处理到的缓冲区号
bp->rx_pending – 分配的缓冲区个数
bp->rx_prod – 当前缓冲区的最后一个缓冲号
这里要参数B440X的手册了解下寄存器的作用:
#define B44_DMARX_ADDR 0x0214UL /* DMA RX Descriptor Ring Address */
#define B44_DMARX_PTR 0x0218UL /* DMA RX Last Posted Descriptor */
#define B44_DMARX_STAT 0x021CUL /* DMA RX Current Active Desc. + Status */
仅b44_rx()来说,B44_DMARX_ADDR储存了环形缓冲的基地址,B44_DMARX_PTR存储了环形缓冲最后一个缓冲区号,这两个寄存器都由处理来设置;B44_DMARX_STAT储存了状态及网卡当前处理到的缓冲区号,这个寄存器只能由网卡来设置。
网卡中DMA也很重要:
在网卡初始化阶段,b44_open() -> b44_alloc_consistent()
bp->rx_buffers = kzalloc(size, gfp); // size = B44_RX_RING_SIZE * sizeof(struct ring_info)
bp->rx_ring = ssb_dma_alloc_consistent(bp->sdev, size, &bp->rx_ring_dma, gfp);
// size = DMA_TABLE_BYTES
rx_ring是DMA映射的虚拟地址,rx_rind_dma是DMA映射的总线地址,这个地址将会写入B44_DMARX_ADDR寄存器,作为环形缓冲的基地址。
bw32(bp, B44_DMARX_ADDR, bp->rx_ring_dma + bp->dma_offset);
稍后在rx_init_rings() -> b44_alloc_rx_skb()
mapping = ssb_dma_map_single(bp->sdev, skb->data,RX_PKT_BUF_SZ,DMA_FROM_DEVICE);
将rx_buffers进行DMA映射,并将映射地址存储在rx_ring中
dp->addr = cpu_to_le32((u32) mapping + bp->dma_offset); // dp是rx_ring中一个
DMA的大致流程:
不准确,但可以参考下大致意思

网卡读取B44_DMARX_ADDR与B44_DMARX_STAT寄存器,得到下一个处理的struct dma_desc,然后根据dma_desc中的addr找到报文缓冲区,通过DMA处理器将网卡收到报文拷贝到addr地址处,这个过程CPU是不参与的。
prod – 网卡[硬件]处理到的缓冲区号
prod = br32(bp, B44_DMARX_STAT) & DMARX_STAT_CDMASK;
prod /= sizeof(struct dma_desc);
cons = bp->rx_cons;
根据上面分析,prod读取B44_DMARX_STAT寄存器,存储网卡当前处理到的缓冲区号;cons存储处理器处理到的缓冲区号。
while (cons != prod && budget > 0) {
处理报文当前时刻网卡接收到的所有报文,每处理一个报文cons都会加1,由于是环形缓冲,因此这里用相等,而不是大小比较。
struct ring_info *rp = &bp->rx_buffers[cons];
struct sk_buff *skb = rp->skb;
dma_addr_t map = rp->mapping;
skb和map保存了当关地址,下面在交换缓冲区后会用到。
ssb_dma_sync_single_for_cpu(bp->sdev, map,RX_PKT_BUF_SZ,DMA_FROM_DEVICE);
CPU取得rx_buffer[cons]的控制权,此时网卡不能再处理该缓冲区。
rh = (struct rx_header *) skb->data;
len = le16_to_cpu(rh->len);
….
len -= 4;
CPU取得控制权后,取得报文头,再从报文头取出报文长度len,len-=4表示忽略了最后4节字的CRC,从这里可以看出,B440X网卡驱动不会检查CRC校验。而每个报文数据最前面添加了网卡的头部信息struct rx_header,这里是28字节。
struct sk_buff *copy_skb;
b44_recycle_rx(bp, cons, bp->rx_prod);
copy_skb = netdev_alloc_skb(bp->dev, len + 2);
copy_skb作为传送报文的中间量,在第三句为其分配了len + 2的空间(为了IP头对齐,稍后提到)。b44_recycle_rx()函数很关键,它作了如下工作:
1. 将缓冲区号cons赋值给缓冲区号rx_prod;
2. rx_buffers[cons].skb = NULL
3. 将缓冲区号rx_prod控制权给网卡
简单来说,就是将cons号缓冲区交由CPU处理,而用rx_prod号缓冲区代替其给网卡使用。
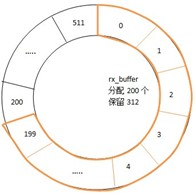

a. b44_recycle_rx前 b. b44_recycle_rx后
以起始状态为例,缓冲区rx_ring分配了512个,但rx_buffers仅分配了200个,此时cons = 0,rx_prod = 200。执行b44_recycle_rx()后,网卡处理缓冲区变为1~200,而0号缓冲区交由CPU处理,将报文拷贝,并向上送至协议栈。注意rx_ring和rx_buffer是不同的。
这样做的好处在于,不用等待CPU处理完0号缓冲区,网卡的缓冲区数保持200,而不会减少,这也是rx_pending = 200的原因所在。
skb_reserve(copy_skb, 2);
skb_put(copy_skb, len);
关于skb的操作自己去了解,这里skb_reserve()在报文头部保留了两个字节,我们知道链路层报头是14字节,正常IP报文会从14字节开始,这样就不是4字节对齐了,所以在头部保留2字节,使IP报文从16字节开始。
skb_copy_from_linear_data_offset(skb, RX_PKT_OFFSET,copy_skb->data, len);
skb = copy_skb;
CPU将报文从skb拷贝到copy_skb中,跳过了网卡报头的额外信息,因为这部分信息在上层协议站是没用的,所以去掉。在函数开始时说过skb是保存了cons号的地址,因为在b44_recycle_rx()后cons号不再引用skb指向的空间,而仅由skb引用,这样便可以向上层传送,而不用额外复制。
netif_receive_skb(skb);
received++;
budget--;
next_pkt:
bp->rx_prod = (bp->rx_prod + 1) & (B44_RX_RING_SIZE - 1);
cons = (cons + 1) & (B44_RX_RING_SIZE - 1);
netif_receive_skb()将报文交由上层协议栈处理,这是下一节的内容,然后CPU处理下一个报文,rx_prod和cons各加1,它们代表的含义开头有说明。
如此循环,直到cons == prod,此时网卡收到的报文都已被CPU处理,更新变量:
bp->rx_cons = cons;
bw32(bp, B44_DMARX_PTR, cons * sizeof(struct dma_desc));
在netif_receive_skb()函数中,可以看出处理的是像ARP、IP这些链路层以上的协议,那么,链路层报头是在哪里去掉的呢?答案是网卡驱动中,在调用netif_receive_skb()前,
skb->protocol = eth_type_trans(skb, bp->dev);
该函数对处理后skb>data跳过以太网报头,由mac_header指示以太网报头:

进入netif_receive_skb()函数
list_for_each_entry_rcu(ptype,&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list)
按照协议类型依次由相应的协议模块进行处理,而所以的协议模块处理都会注册在ptype_base中,实际是链表结构。
net/core/dev.c
static struct list_head ptype_base __read_mostly; /* Taps */
而相应的协议模块是通过dev_add_pack()函数加入的:
void dev_add_pack(struct packet_type *pt)
{
int hash;
spin_lock_bh(&ptype_lock);
if (pt->type == htons(ETH_P_ALL))
list_add_rcu(&pt->list, &ptype_all);
else {
hash = ntohs(pt->type) & PTYPE_HASH_MASK;
list_add_rcu(&pt->list, &ptype_base[hash]);
}
spin_unlock_bh(&ptype_lock);
}
以ARP处理为例
该模块的定义,它会在arp_init()中注册进ptype_base链表中:
static struct packet_type arp_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_ARP),
.func = arp_rcv,
};
然后在根据报文的TYPE来在ptype_base中查找相应协议模块进行处理时,实际调用arp_rcv()进行接收
arp_rcv() --> arp_process()
arp = arp_hdr(skb);
……
arp_ptr= (unsigned char *)(arp+1);
sha= arp_ptr;
arp_ptr += dev->addr_len;
memcpy(&sip, arp_ptr, 4);
arp_ptr += 4;
arp_ptr += dev->addr_len;
memcpy(&tip, arp_ptr, 4);
操作后这指针位置:

然后判断是ARP请求报文,这时先查询路由表ip_route_input()
if (arp->ar_op == htons(ARPOP_REQUEST) &&
ip_route_input(skb, tip, sip, 0, dev) == 0)
在ip_route_input()函数中,先在cache中查询是否存在相应的路由表项:
hash = rt_hash(daddr, saddr, iif, rt_genid(net));
缓存的路由项在内核中组织成hash表的形式,因此在查询时,先算出的hash值,再用该项- rt_hash_table[hash].chain即可。这里可以看到,缓存路由项包括了源IP地址、目的IP地址、网卡号。
如果在缓存中没有查到匹配项,或指定不查询cache,则查询路由表ip_route_input_slow();
进入ip_route_input_slow()函数,最终调用fib_lookup()得到查询结果fib_result
if ((err = fib_lookup(net, &fl, &res)) != 0)
如果结果fib_result合法,则需要更新路由缓存,将此次查询结果写入缓存
hash = rt_hash(daddr, saddr, fl.iif, rt_genid(net));
err = rt_intern_hash(hash, rth, NULL, skb, fl.iif);
在查找完路由表后,回到arp_process()函数,如果路由项指向本地,则应由本机接收该报文:
if (addr_type == RTN_LOCAL) {
……
if (!dont_send) {
n = neigh_event_ns(&arp_tbl, sha, &sip, dev);
if (n) {
arp_send(ARPOP_REPLY,ETH_P_ARP,sip,dev,tip,sha,dev->dev_addr,sha);
neigh_release(n);
}
}
goto out;
}
首先更新邻居表neigh_event_ns(),然后发送ARP响应 – arp_send。
至此,大致的ARP流程完成。由于ARP部分涉及到路由表以及邻居表,这都是很大的概念,在下一篇中介绍,这里直接略过了。
这篇关于NETDEV 协议的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





