本文主要是介绍英特尔MRT技术在互联网大厂的应用案例解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
内存故障预测与可靠性提升案例解读
1.SK海力士
英特尔与SK海力士合作,双方团队识别出一小批存在可复制内存故障的DDR4 RDIMM,为深入分析提供了宝贵样本。基于这些样本,英特尔得以进行详尽分析,揭示故障根源。同时,英特尔利用自身数据中心的大规模数据完成了全面的内存故障分析,积累了丰富的实证数据。
DIMM Sample 1在搭载Intel MRT的Intel Sky Lake服务器上的测试情况,目的是验证该技术在预防内存故障方面的效能。
-
传统预测性故障分析(PFA,Predictive Failure Analysis )设置:启用操作系统的传统PFA功能,采用10/24策略,意味着如果操作系统在24小时内检测到某个页面发生10次可纠正错误(Correctable Errors, CEs),则自动将该页面离线。
-
故障现象:测试中,多次CE发生在特定的行地址0x1c998以及列地址0x00至0x3c8之间。在短短9分钟内,共记录到34次CE,随后发生了致命的不可纠正错误(Uncorrectable Error, UE),导致系统崩溃。系统日志显示,PFA机制仅成功离线了一个有问题的页面。
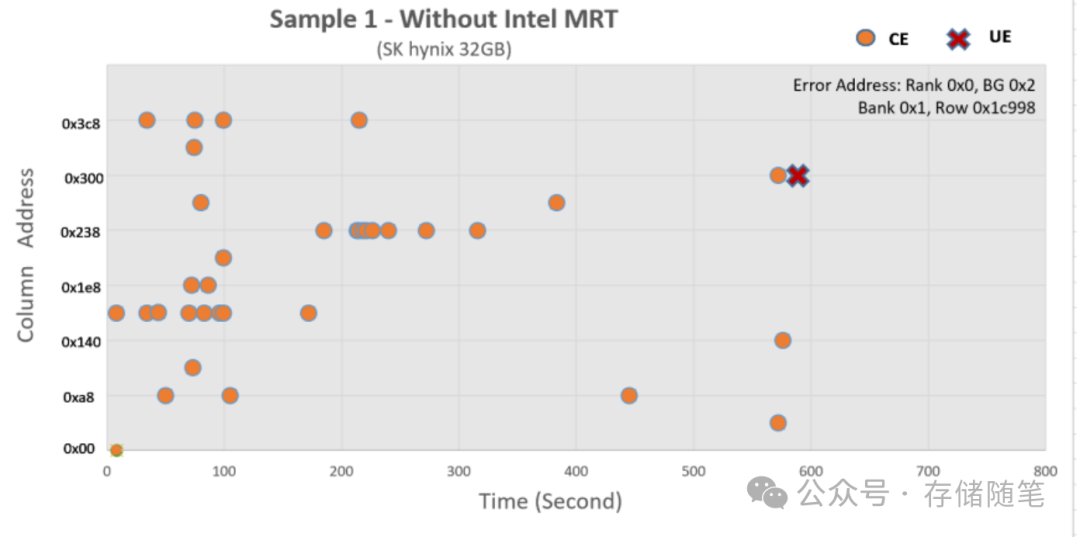
在相同的测试条件下,启用MRT技术后成功识别了内存错误模式,迅速触发与错误相关的多个页面离线,从而阻止了更多CE的发生。相较于之前的测试,这次没有再记录到新的CE,总共离线了8个页面,memtester在大约3小时后顺利完成了测试,未再出现任何错误,证明系统稳定运行。
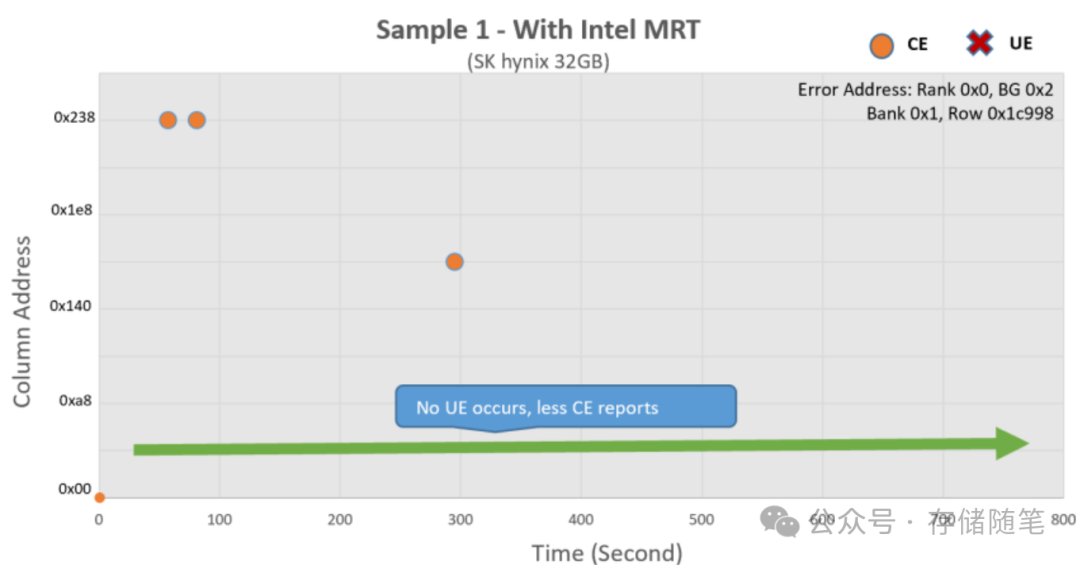
通过对比两次测试,可以明显看出Intel MRT技术的有效性。
-
在没有启用该技术的情况下,即使有PFA策略,系统仍然因为未能及时识别并隔离所有问题页面而导致了致命错误和系统崩溃。
-
而一旦启用Intel MRT技术,它能更快速、准确地识别内存错误模式,提前采取行动,有效避免了错误累积到不可控的地步,从而保持了系统的稳定和连续运行。
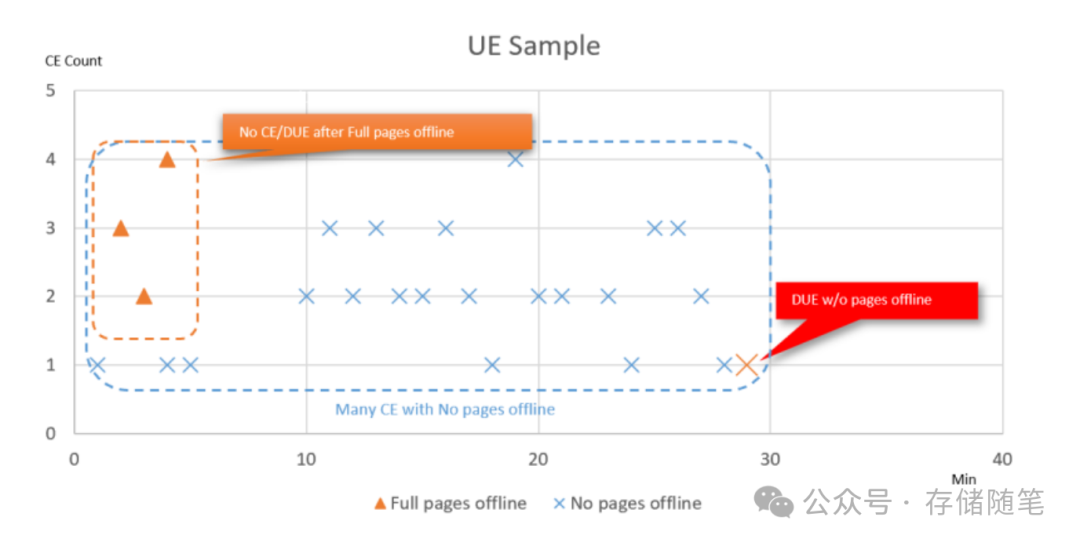
根据SK海力士展示了一项关键的对比实验结果,突出了实时故障分析与迅速预防措施的必要性。在此图表中,横轴(X轴)表示时间,纵轴(Y轴)代表内存错误的数量。通过两个不同的测试场景,用蓝色虚线矩形和橙色虚线矩形分别表示,揭示了启用和未启用内存页面离线功能时,内存错误行为的显著差异。
-
蓝色虚线矩形所代表的测试情景中,没有采取任何页面离线操作。在这种情况下,经过一段时间后,在多次可纠正错误(CEs)之后,仅在30分钟内便出现了不可纠正错误(UE)。这表明,一旦开始出现可纠正错误,系统可能迅速恶化至不可控状态,最终导致系统崩溃或数据丢失。
-
橙色虚线矩形则描绘了另一种情况,即所有与错误相关的页面都被Intel MRT预判并及时离线处理。在这个测试中,没有记录到任何CE或UE的发生,证明了该技术能够有效防止错误累积并演变为更严重的系统问题。
这些测试结果清晰地指出,从出现CE到UE的时间间隔可能短至几分钟乃至几小时,这一发现强烈呼吁对内存故障进行实时分析,并立即采取预防措施。Intel MRT的这种提前干预机制,通过主动识别错误模式并离线潜在危险页面,显著提高了系统的可靠性和稳定性,减少了因内存错误导致的意外停机风险。
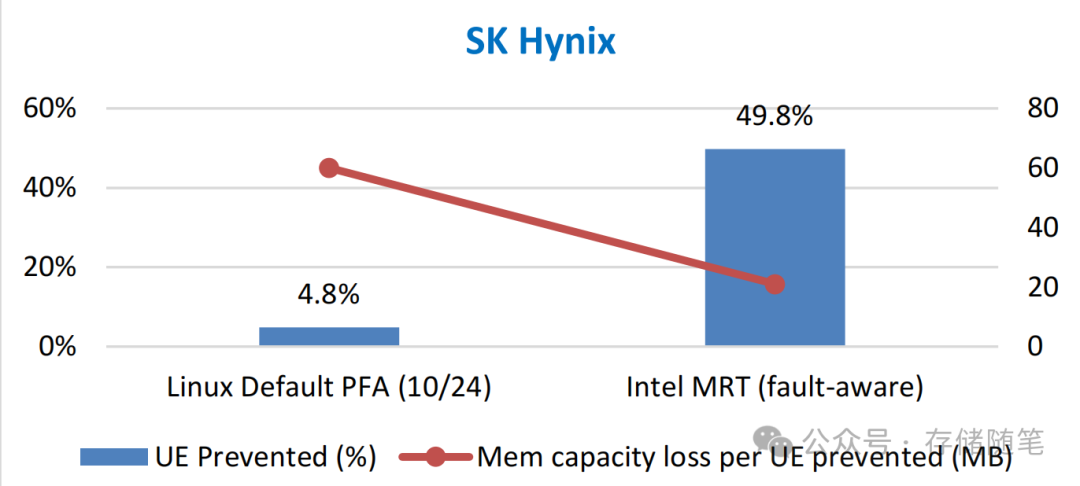
英特尔与SK海力士合作,于2022年6月至11月期间,在数千台服务器(包括Intel SkyLake和Cascade Lake系列)上比较了Intel MRT与Linux默认的预失败分析(PFA)的性能,收集到的数据经过过滤和汇总:
-
Intel MRT的表现:这项技术成功预防了49.8%的内存故障,且每预防一个不可纠正错误(UE)所需的内存容量损失平均少于21MB。这表明,它在减少内存故障影响的同时,对系统内存资源的影响相对较小。
-
Linux默认PFA的表现:相比之下,Linux的默认PFA仅能预防4.8%的内存故障,且每预防一个UE需要牺牲60MB的内存空间,成本效益远低于Intel MRT。
-
DRAM部件对UE预防率的影响:不同SK海力士DRAM部件的UE预防率变化较大,范围从27.6%到84.3%,平均预防率为49.8%。这说明Intel MRT的效率受到DRAM故障模式和特定部件的影响,某些类型的DRAM故障和部件能获得更高的故障检测能力和UE预防表现。
2.腾讯
面对着数据中心内存故障这一关键硬件问题的挑战,特别是内存故障对服务器的可靠性、可用性与可服务性(RAS)产生直接影响。为此,腾讯采用了Intel内存故障预测(Intel MFP,Memory Failure Prediction)技术,在其基于Intel至强可扩展处理器的数千台服务器上进行测试部署,以减少由服务器内存故障引起的停机时间,提升系统稳定性。
Intel MFP(Intel Memory Failure Prediction)与MRT(Memory Resilience Technology)是Intel推出的两项针对数据中心内存管理与维护的不同技术,它们各有侧重,旨在从不同维度提升服务器的可靠性和效率。
Intel MFP专注于预测潜在的内存故障。它通过在线机器学习算法分析历史数据,从DIMM、bank、列、行、单元直至内存细胞级别的错误信息,给出健康评分,从而预测未来可能出现的故障。帮助用户在内存故障发生之前采取行动,如迁移工作负载、更换故障的DIMM,减少计划外的停机时间和成本。
Intel MRT专注于提高内存的韧性,即在内存发生错误时减少或避免系统中断的能力。它通过实时监控内存状态并在检测到潜在问题时采取措施,如错误纠正、页面离线等,以避免系统崩溃。增强系统的稳定性与连续运行,即时应对内存错误,减少不可纠正错误(UE)的发生,从而提高服务器的可靠性和服务的可用性。
技术原理与实施步骤:
-
实时内存健康洞察:IntelMFP利用在线机器学习技术,深入分析服务器内存的错误记录,从DIMM、bank、列、行、cell级别到抽象错误源,给出健康评分,预测未来的潜在故障。
-
错误注入测试:通过EINJ表,腾讯可以在测试环境中模拟内存错误,验证错误检测和纠正机制的准确性。这包括了错误类型的选择、内存地址的注入、地址掩码设定等,最后触发错误注入并观察系统响应。
-
系统级整合与决策优化:基于Intel MFP的分析,腾讯可以做出更好的决策,如迁移关键工作负载到识别出内存问题的服务器,或者更换故障的DIMM,减少UE事件,提升服务器的可用性和运行时间。它与腾讯现有的管理系统集成,通过分析历史数据预测潜在的内存故障事件,防止潜在的灾难性故障发生。

初步测试显示,腾讯使用Intel MFP在DIMM级别的故障预测准确率上提高了5倍。通过优化页面离线策略,Intel MFP显著降低了由内存故障导致的停机时间。腾讯的运营效率提高,避免了不必要的DIMM采购成本,因为可以更精确地识别何时需要更换,而非预防性替换。
3.美团
美团点评作为中国领先的生活服务电商平台,其业务涵盖餐饮、外卖、出行、酒店等多个领域,服务遍及全国乃至海外,对数据中心的稳定性有着极高的要求。在数据中心的运维挑战中,内存故障是导致服务器宕机的主因之一,约占7%。因此,美团携手英特尔,通过部署Intel内存故障预测技术(Intel MFP),针对基于Intel 至强可扩展处理器的服务器进行了大规模测试,以提升内存可靠性并减少由内存故障引发的宕机时间。
解决方案与实施:
-
Intel MFP部署:美团将其集成到现有管理系统中,通过分析内存故障数据预测潜在故障,优化内存问题处理策略,预防宕机,优化DIMM更换政策。
-
实时预测与优化:Intel MFP利用机器学习,深入分析历史错误日志,从DIMM到具体内存单元,预测未来故障,提供健康评分。
-
故障响应机制:检测到高风险内存错误,Intel MFP建议离线问题页面,减少UE风险,优化服务器稳定性。

效果与效益:
-
预测准确率提升:测试显示,Intel MFP在美团的预测准确性上相比传统策略提高了40%,大幅减少硬件故障。
-
成本节省:美团减少因硬件故障带来的每分钟损失高达9000美元,小企业损失137至427美元,MFP的高效降低宕机直接减少成本。
-
效率提升:优化运维与资源管理,减少不必要DIMM购买,提升整体运营效率。
4.阿里云
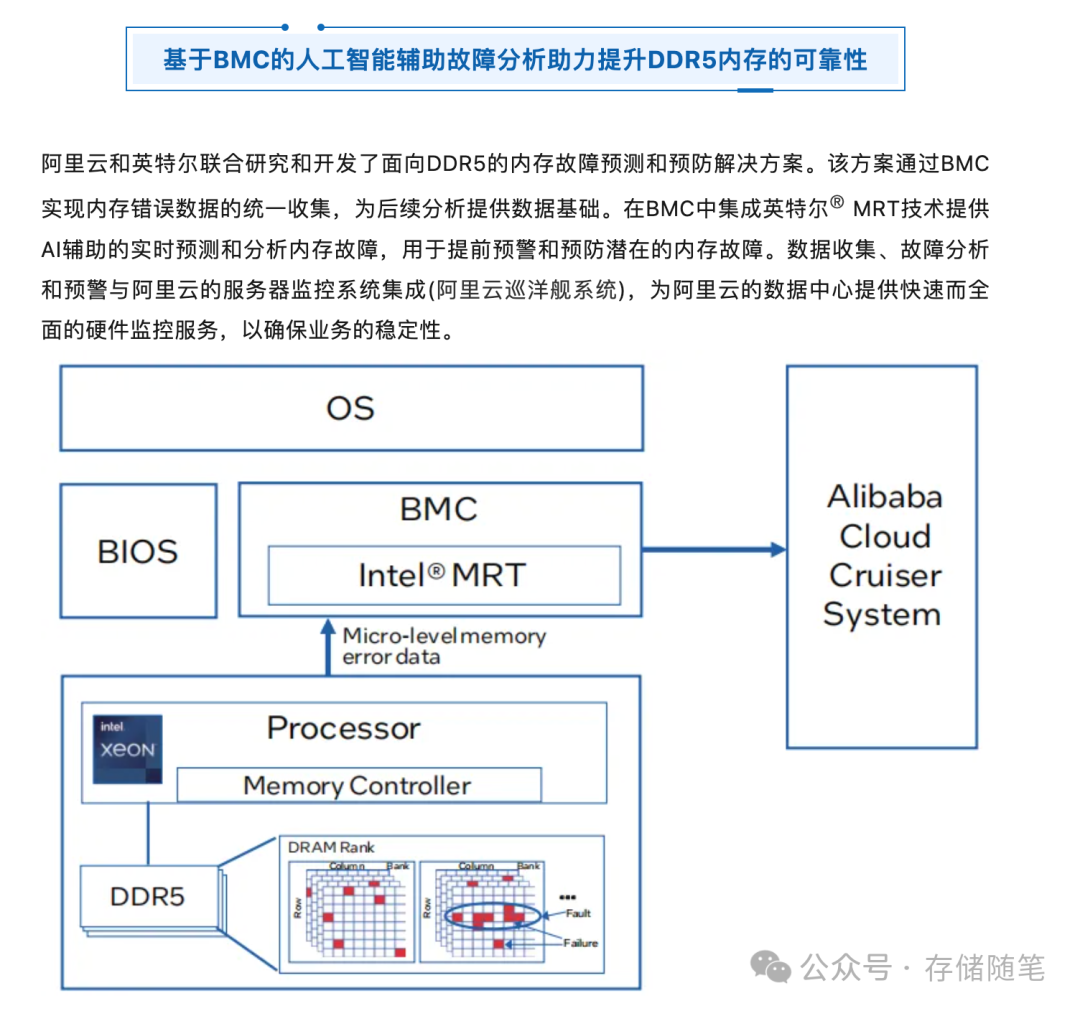

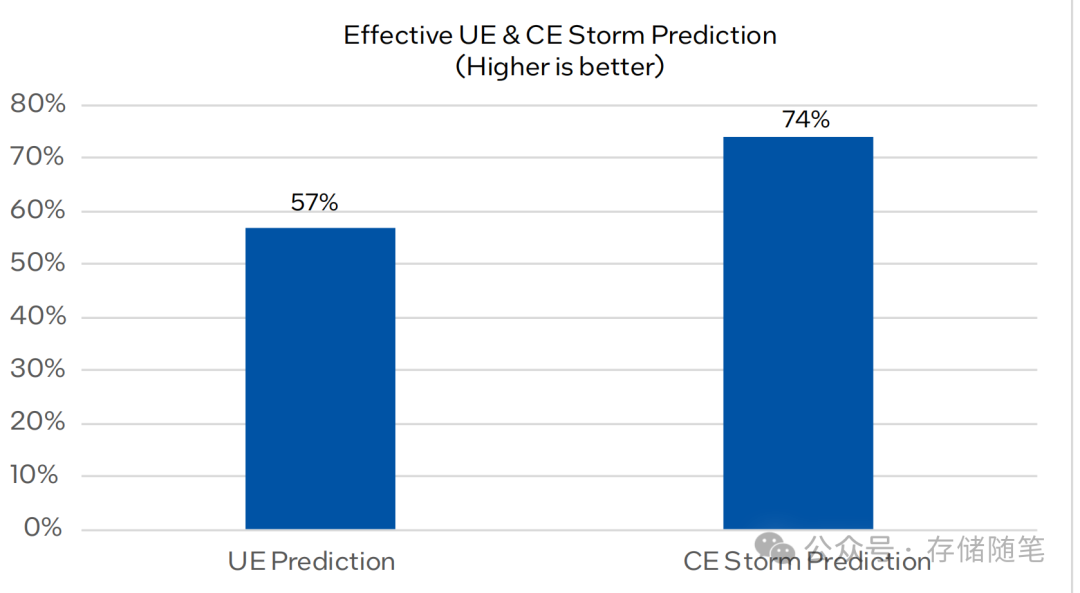
根据Intel公布的数据显示,该方案成功预测UE发生前预警,提前避免CE风暴。预测时差数分钟到小时不等,模型迭代后预计UCE预测准确率可达57% ,CE风暴预测准确率预计可达74%
5.字节跳动
不可纠正的内存错误是数据中心中导致服务器崩溃的主要硬件故障原因。页面离线是一种现代操作系统中实施的错误预防机制。传统的离线策略基于过去时间段内页面的可纠正错误(CE)率。然而,CE只是表象,根本原因是内存电路故障。比如,行故障可能影响多个页面。同时,并非所有故障均易发生成不可纠正错误(UE)。

英特尔与字节合作,提出了一个故障感知的页面离线策略。策略中,首先基于CE观察确定行故障作为初步离线候选。行故障识别:观察行CE模式,若过去T小时内跨区长度lr、唯一位置数θr,则认为行故障。

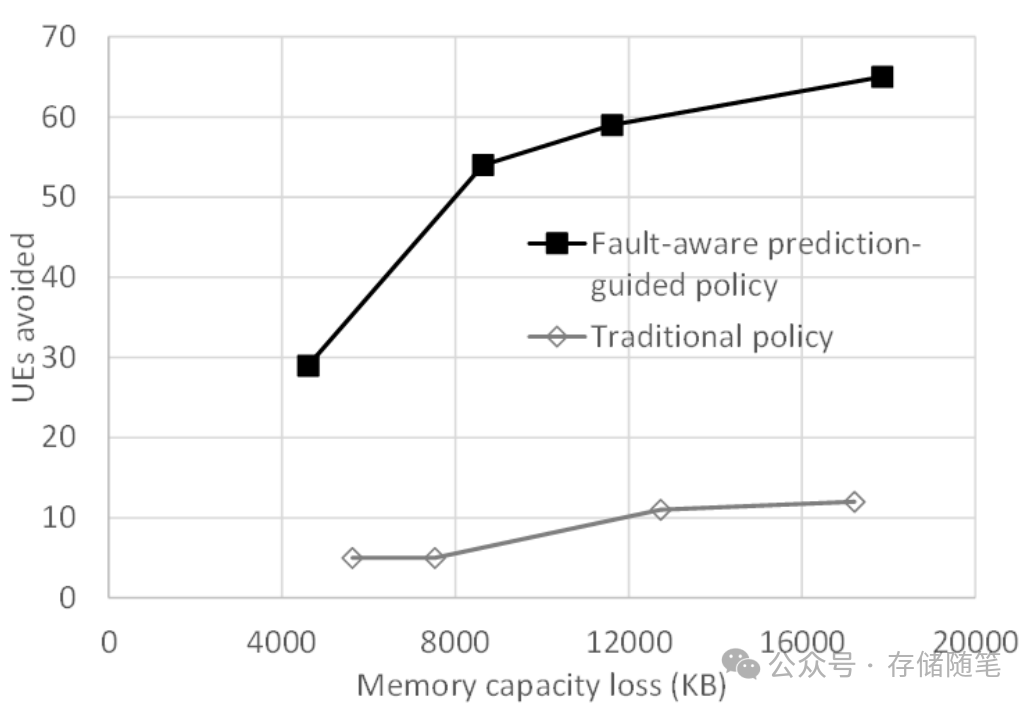
利用纠错码知识,我们基于错误位模式设计预测器,预测行是否易发UE。受UE行影响的页面随后离线。使用字节大规模集群的错误日志的实证,提出的策略相比传统策略,在因页面离线导致的内存容量损失相当情况下,能避免更多UE。
6.三星
在数据中心环境中,内存错误是导致服务器故障的重要原因之一,这些错误往往未被用户或运营者忽视。尽管单个别的时候这些错误看似微不足挂齿,但累积起来却会对性能产生负面影响,降低服务器可靠性并可能中断数据中心的连续性。内存故障直接影响到服务器的可靠性、可用性和可维护性(RAS),特别是不可纠正错误(UE)可能导致服务器意外崩溃。例如,在某全球云服务提供商的数据中心,发现约50%的硬件导致的停机时间归咎于内存故障。
传统解决方案中的页面离线技术,即在现代操作系统中实现的错误预防机制,主要基于过去一段时间内页面的可纠正错误(CE)率。然而,CE仅是现象,其背后的根本在于内存电路故障。像行故障可能影响多个页面,而并非所有故障同等程度上都易于产生UE。此外,过去期间的CE率不是未来UE的好预测指标。
当DRAM中的行发生故障时,为了确保故障行隔离,具有相同行地址的多个页面必须同时离线。一次行故障导致的总内存影响大小取决于DRAM模型,通常限制在几百KB内。也就是说,当DRAM中的一行出现问题时,为防止这个故障影响其他数据,所有共享同一行地址的页面都要一起被离线(即不再使用)。这样的操作影响有限,一般只占几百KB,视DRAM型号而定。
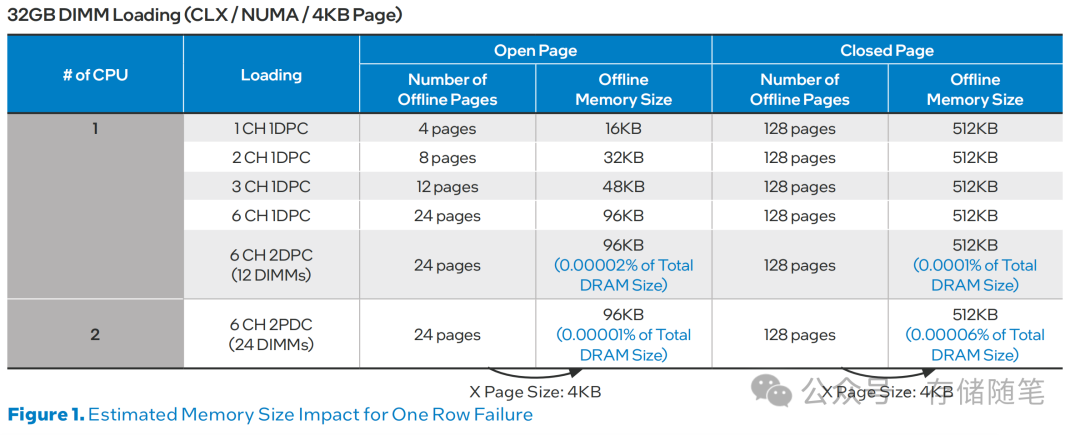
三星与英特尔合作研究发现,要有效防止UE和减少通过页面离线需要综合解决方案。这包括对底层DRAM故障的细粒度分析以及平台特定纠错码(ECC)知识;多页面离线,针对共用同一缺陷电路的持续CE和UE;检查OS内存地址到DRAM位置映射。短期方案是将OS页面离线阈值从每24小时10CE减至2CE。长期看,引入人工智能(AI)。

对比标准OS策略、改进的OS策略(降低CE阈值)、Intel MRT策略,即使CPU在离线后还能报告UE(不可纠正错误),但因为页面已离线,所以不会对整个系统造成危害。
写最后:
-
Intel英特尔在内存故障预测与可靠性方面,投入很多的技术研究,并与业内互联网巨头有很多成果落地。
-
但是好像AMD、ARM这方面的发声很少,AMD CPU和ARM CPU有哪些类似的内存可靠性提升技术,欢迎评论区交流,非常感谢!
参考文献:
-
https://www.intel.cn/content/www/cn/zh/software/intel-memory-resilience-technology.html
-
https://ieee-ras.conferences.computer.org/2024/program-structure/
-
https://ieeexplore.ieee.org/document/9643830
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
磁带存储:“不老的传说”依然在继续
-
浅析3D NAND多层架构的可靠性问题
-
SSD模拟器MQSim简介与资料分享
-
孙凝晖院士万字长文|人工智能与智能计算的发展
-
探究NVMe SSD HMB应用场景与影响
-
深度剖析:大容量QLC SSD为何遭疯抢?
-
SSD突然掉电,是谁保护了用户数据?
-
漫谈HAMR硬盘的可靠性
-
万物皆可计算|下一个风口:近内存计算
-
SSD数据错误如何修复?
-
CXL与PCIe世界的尽头|你相信光吗?
-
全景剖析SSD SLC Cache缓存设计原理
-
存储革新:下一代低功耗PCM相变存储器
-
3D DRAM虽困难重重,最快明年到来
-
字节跳动入局存储内存SCM
-
PCIe 7.0|不要太卷,劝你先躺平
-
SSD LDPC软错误探测方案解读
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
对于超低延迟SSD,IO调度器已经过时了吗?
-
浅析CXL P2P DMA加速数据传输的原理
-
浅析LDPC软解码对SSD延迟的影响
-
为什么QLC NAND才是ZNS SSD最大的赢家?
-
SSD在AI发展中的关键作用:从高速缓存到数据湖
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!
这篇关于英特尔MRT技术在互联网大厂的应用案例解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





