本文主要是介绍Tomcat源码解析(八):一个请求的执行流程(附Tomcat整体总结),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Tomcat源码系列文章
Tomcat源码解析(一):Tomcat整体架构
Tomcat源码解析(二):Bootstrap和Catalina
Tomcat源码解析(三):LifeCycle生命周期管理
Tomcat源码解析(四):StandardServer和StandardService
Tomcat源码解析(五):StandardEngine、StandardHost、StandardContext、StandardWrapper
Tomcat源码解析(六):Connector、ProtocolHandler、Endpoint
Tomcat源码解析(七):底层如何获取请求url、请求头、json数据?
Tomcat源码解析(八):一个请求的执行流程
文章目录
- 前言
- 一、Engine管道内容
- 1、StandardEngineValve
- 2、如何通过Engine找到Host
- 二、Host管道内容
- 1、ErrorReportValve(拼接html错误页面)
- 2、StandardHostValve
- 3、如何通过Host找到Context(上下文)
- 三、Context管道内容
- 1、StandardContextValve
- 2、如何通过Context找到Wrapper
- 四、Wrapper管道内容
- 1、StandardWrapperValve
- 1.1、创建过滤器链
- 1.2、执行过滤器链
- 1.2.1、Request和Response的门面模式
- 1.2.2、doFilter方法
- Tomcat最终总结
前言
前文中我们介绍了NIO解析请求数据,网络字节流转化为Request和Response对象。接下来介绍拿到Req和Res之后如何走到Servelt,以及正常响应返回。
回顾之前篇章,NioEndpoint通过socket服务端ServerSocketChannel.accept()监听8080端口接收连接,获取到连接扔给连接池处理,SocketProcessor从NioChannel通道中读取数据到ByteBuff缓冲区再赋值给对应属性,最后通过适配器CoyoteAdapter生成容器Req和Res调用容器管道的执行方法。

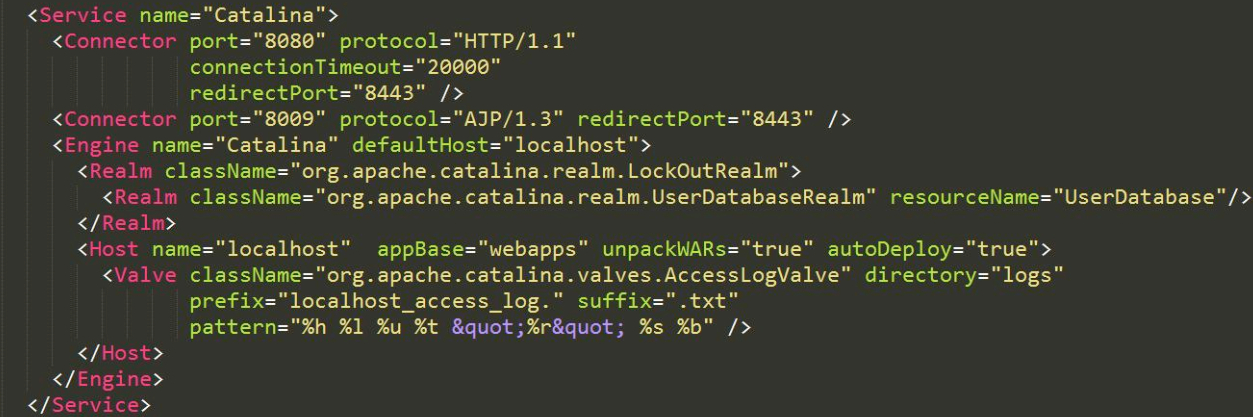
Endpoint是连接器Connector的核心组件之一,那么NioEndpoint接受到的连接最后交给自己的连接器connector;由如下server.xml可知,Service对象由一个容器Engine和多个连接器Connector组成,所以结合上面核心代码connector.getService().getContainer()获取到的就是自己的顶级容器Engine。
以前第一篇文章Tomcat源码解析(一):Tomcat整体架构最后一部分有说过管道的结构。这里再简单的说下容器管道,其实可以理解为容器Engine、Host、Context、Wrapper设置的拦截器,一个请求进来,需要通过每个容器设置的拦截器(如下链状结构,可以设置多个),也就是说每个容器可能有多个处理点。作用其实就是在请求Servelt之前可以拦截请求做一些额外处理。另外一方面,也是从顶级容器Engine找到Wrapper从而找到Servelt执行我们写的业务逻辑
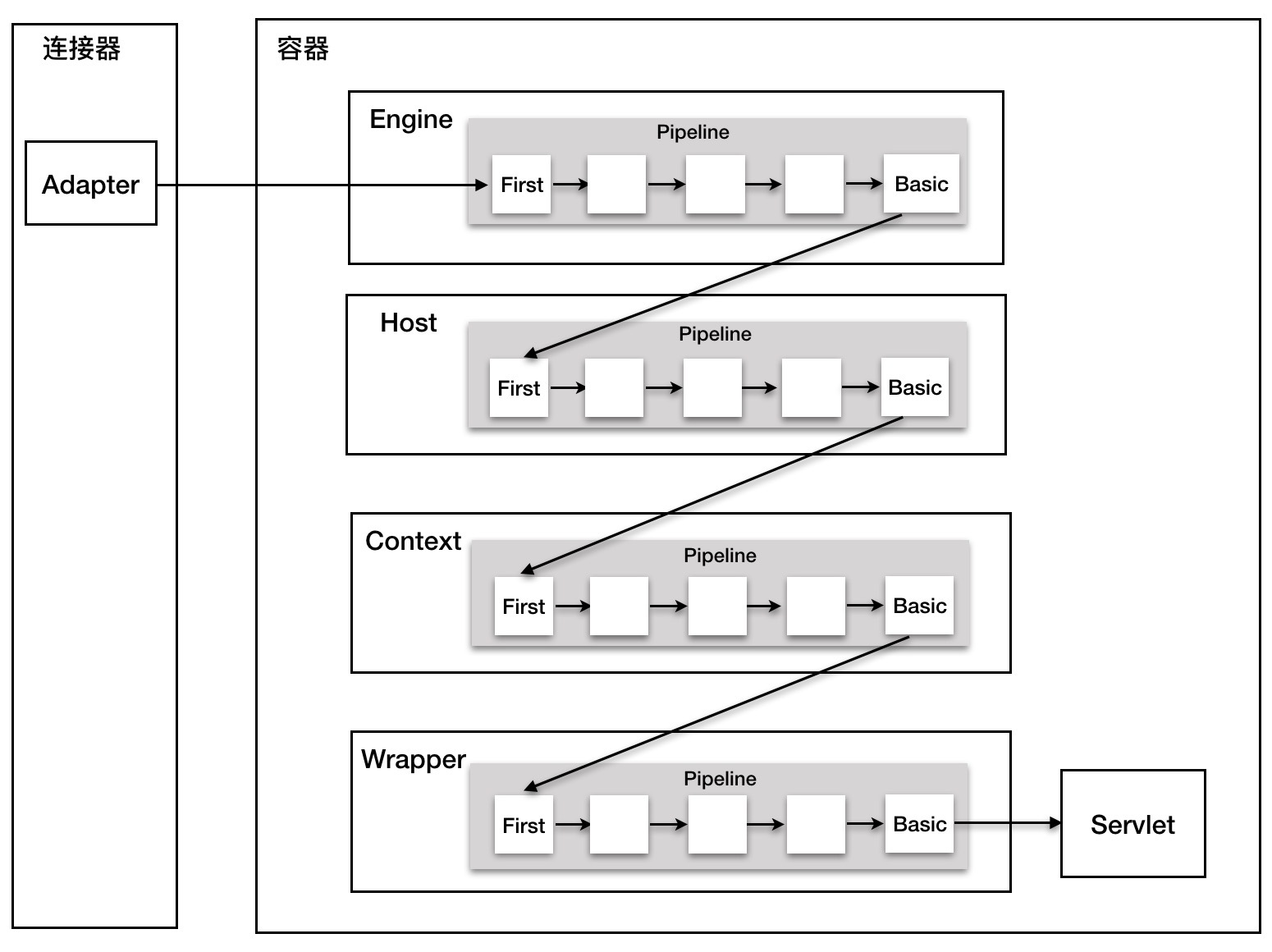
一、Engine管道内容
1、StandardEngineValve
这里感觉没啥核心内容,其实就是找到对应的Host,然后调用Host的管道执行方法。
final class StandardEngineValve extends ValveBase {...@Overridepublic final void invoke(Request request, Response response)throws IOException, ServletException {// 从request中获取虚拟主机hostHost host = request.getHost();if (host == null) {response.sendError(HttpServletResponse.SC_BAD_REQUEST,sm.getString("standardEngine.noHost",request.getServerName()));return;}if (request.isAsyncSupported()) {request.setAsyncSupported(host.getPipeline().isAsyncSupported());}// 请此主机处理此请求,调用对应主机的管道执行方法host.getPipeline().getFirst().invoke(request, response);}
}
2、如何通过Engine找到Host
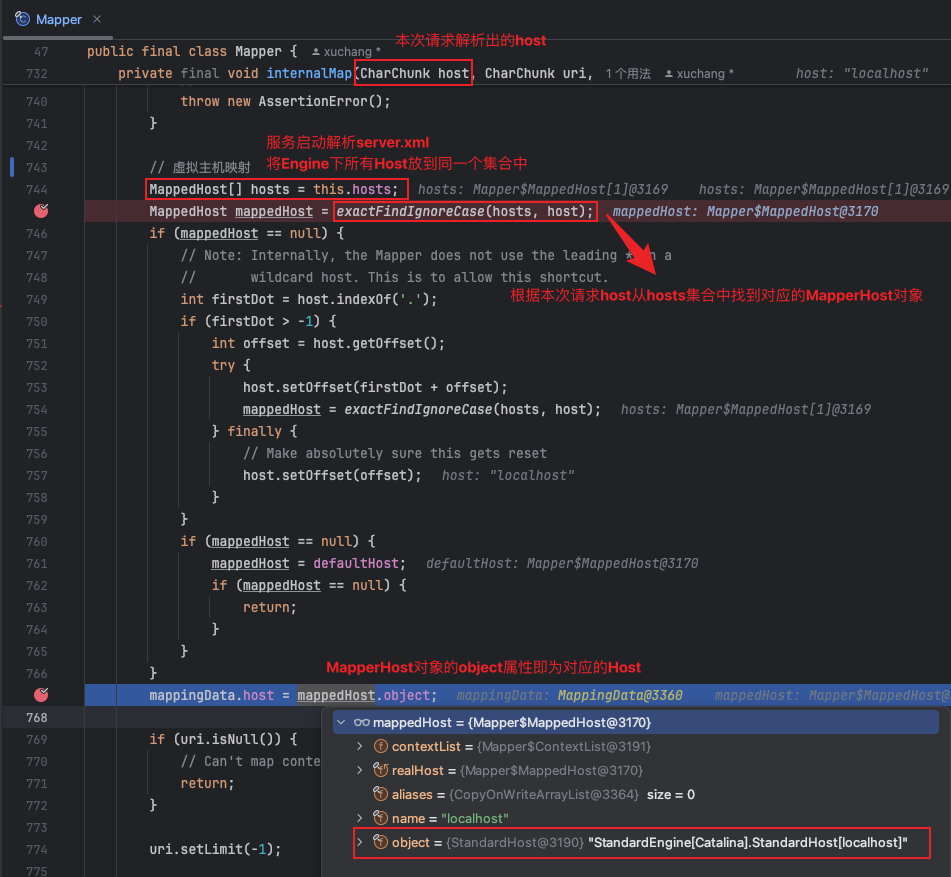
顶级容器Engine下可以有多个虚拟主机Host(主机名称和ip地址,默认localhost);在上篇文章中讲过NIO解析请求数据,里面自然包括请求ip地址,此时只要比对下即可在多个虚拟主机Host中找到。
在解析请求后会调用如下方法,最终会将获取到Host对象的mappingData.host属性赋值给Request,这样上面request.getHost()就能获取到对应的Host了。
二、Host管道内容
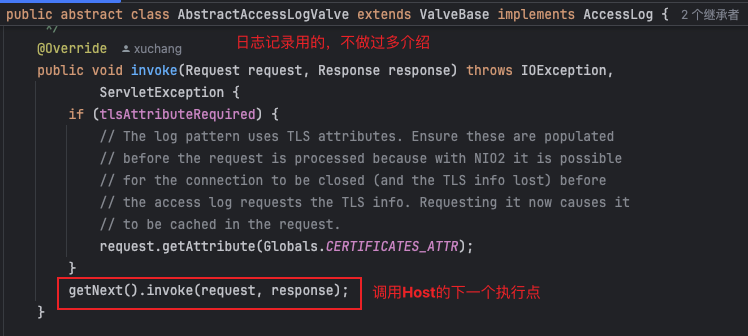
AccessLogValve
- 这个处理点是日志记录用的,具体也没研究干啥的
- 这里可以理解为Host的拦截器链,这个执行点执行完,调用下一个
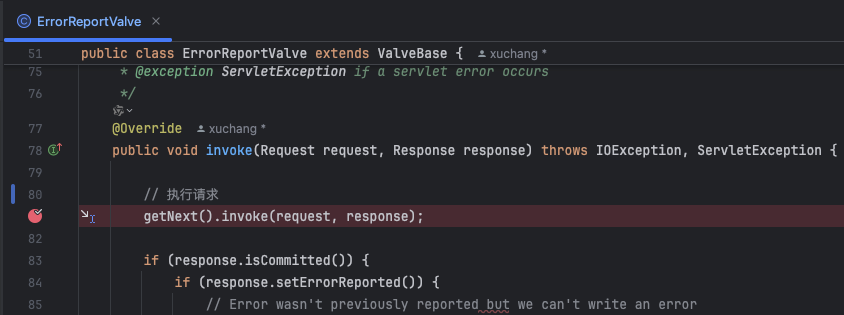
1、ErrorReportValve(拼接html错误页面)
- 接下来这个处理点,就是本单元的主要讲的内容,错误页面的拼接
public class ErrorReportValve extends ValveBase {...@Overridepublic void invoke(Request request, Response response) throws IOException, ServletException {// 执行请求getNext().invoke(request, response);...// 此异常是执行请求时候捕获的,如我们的业务逻辑抛出的异常,这里就能获取到// 后面会讲到Throwable throwable = (Throwable) request.getAttribute(RequestDispatcher.ERROR_EXCEPTION);...try {// 返回html的错误页面report(request, response, throwable);} catch (Throwable tt) {ExceptionUtils.handleThrowable(tt);}}...
}
- 在1xx、2xx和3xx状态下不执行任何操作
- 4xx客户端错误,5xx服务端错误则需要组装错误响应业务
- html字符串拼接完成后,将数据通过网络写出到客户端
// ErrorReportValve类方法
protected void report(Request request, Response response, Throwable throwable) {int statusCode = response.getStatus();// 在 1xx、2xx 和 3xx 状态下不执行任何操作// 4xx客户端错误,5xx服务端错误则需要组装错误响应业务if (statusCode < 400 || response.getContentWritten() > 0 || !response.setErrorReported()) {return;}...// sb即为拼接的html返回字符串StringBuilder sb = new StringBuilder();sb.append("<!doctype html><html lang=\"");sb.append(smClient.getLocale().getLanguage()).append("\">");sb.append("<head>");sb.append("<title>");sb.append(smClient.getString("errorReportValve.statusHeader",String.valueOf(statusCode), reason));sb.append("</title>");sb.append("<style type=\"text/css\">");sb.append(TomcatCSS.TOMCAT_CSS);sb.append("</style>");sb.append("</head><body>");sb.append("<h1>");sb.append(smClient.getString("errorReportValve.statusHeader",String.valueOf(statusCode), reason)).append("</h1>");if (isShowReport()) {sb.append("<hr class=\"line\" />");sb.append("<p><b>");sb.append(smClient.getString("errorReportValve.type"));sb.append("</b> ");if (throwable != null) {sb.append(smClient.getString("errorReportValve.exceptionReport"));} else {sb.append(smClient.getString("errorReportValve.statusReport"));}sb.append("</p>");if (!message.isEmpty()) {sb.append("<p><b>");sb.append(smClient.getString("errorReportValve.message"));sb.append("</b> ");sb.append(message).append("</p>");}sb.append("<p><b>");sb.append(smClient.getString("errorReportValve.description"));sb.append("</b> ");sb.append(description);sb.append("</p>");if (throwable != null) {String stackTrace = getPartialServletStackTrace(throwable);sb.append("<p><b>");sb.append(smClient.getString("errorReportValve.exception"));sb.append("</b></p><pre>");sb.append(Escape.htmlElementContent(stackTrace));sb.append("</pre>");int loops = 0;Throwable rootCause = throwable.getCause();while (rootCause != null && (loops < 10)) {stackTrace = getPartialServletStackTrace(rootCause);sb.append("<p><b>");sb.append(smClient.getString("errorReportValve.rootCause"));sb.append("</b></p><pre>");sb.append(Escape.htmlElementContent(stackTrace));sb.append("</pre>");// In case root cause is somehow heavily nestedrootCause = rootCause.getCause();loops++;}sb.append("<p><b>");sb.append(smClient.getString("errorReportValve.note"));sb.append("</b> ");sb.append(smClient.getString("errorReportValve.rootCauseInLogs"));sb.append("</p>");}sb.append("<hr class=\"line\" />");}if (isShowServerInfo()) {sb.append("<h3>").append(ServerInfo.getServerInfo()).append("</h3>");}sb.append("</body></html>");try {try {response.setContentType("text/html");response.setCharacterEncoding("utf-8");} catch (Throwable t) {ExceptionUtils.handleThrowable(t);}Writer writer = response.getReporter();if (writer != null) {// 将响应的html写到响应对象Response的一个字符缓冲区CharBuffer中writer.write(sb.toString());// 将响应缓冲区中的数据通过网络发送给客户端response.finishResponse();}} catch (IOException e) {// Ignore} catch (IllegalStateException e) {// Ignore}
}
- html字符串对应业务关键内容

2、StandardHostValve
- 回到执行请求那里,继续向里走
- 一旦我们业务代码抛出异常,这里会获取到,然后设置响应码
response.setStatus(500)等等 - 这些都是为上面说的拼接html错误页面做准备
// StandardHostValve类方法
@Override
public final void invoke(Request request, Response response)throws IOException, ServletException {// 获取请求的Context(上下文)Context context = request.getContext();if (context == null) {return;}...try {...try {if (!response.isErrorReportRequired()) {// 下一个执行点NonLoginAuthenticatorcontext.getPipeline().getFirst().invoke(request, response);}} catch (Throwable t) {...}...// 此异常是执行请求时候捕获的,如我们的业务逻辑抛出的异常,这里就能获取到Throwable t = (Throwable) request.getAttribute(RequestDispatcher.ERROR_EXCEPTION);// Look for (and render if found) an application level error pageif (response.isErrorReportRequired()) {if (t != null) {// 设置响应信息// public static final int SC_INTERNAL_SERVER_ERROR = 500;// response.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);throwable(request, response, t);} else {status(request, response);}} ...} finally {...}
}
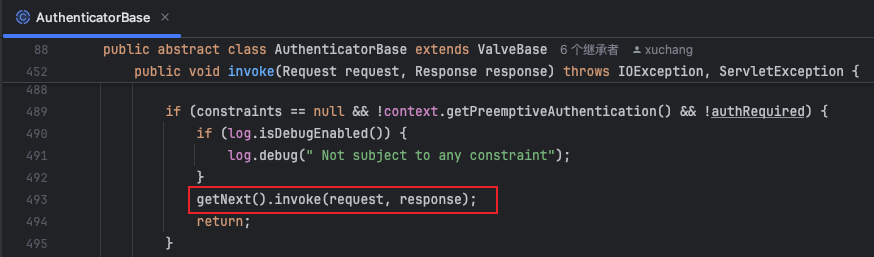
NonLoginAuthenticator
- 此处理点主要是tomcat登录权限以及其他权限校验,暂不做研究
- 接着继续下一个就是Context的处理点
3、如何通过Host找到Context(上下文)
虚拟主机Host下可能有多个项目,即webapps目录下的文件夹,每个文件夹就是一个应用项目,而这个文件夹的名称即请求url的统一前缀。
在解析请求后调用如下方法,最终会将获取到Context对象的mappingData.context属性赋值给Request,这样上面request.getContext()就能获取到上下文Context。

三、Context管道内容
1、StandardContextValve
- 禁止直接访问
WEB-INF或META-INF下的资源 - 获取Wrapper,找不到设置错误码
404,最后调用Wrapper的处理点
// StandardContextValve类方法
@Override
public final void invoke(Request request, Response response)throws IOException, ServletException {// 禁止直接访问 WEB-INF 或 META-INF 下的资源MessageBytes requestPathMB = request.getRequestPathMB();if ((requestPathMB.startsWithIgnoreCase("/META-INF/", 0))|| (requestPathMB.equalsIgnoreCase("/META-INF"))|| (requestPathMB.startsWithIgnoreCase("/WEB-INF/", 0))|| (requestPathMB.equalsIgnoreCase("/WEB-INF"))) {response.sendError(HttpServletResponse.SC_NOT_FOUND);return;}// 获取请求的WrapperWrapper wrapper = request.getWrapper();if (wrapper == null || wrapper.isUnavailable()) {response.sendError(HttpServletResponse.SC_NOT_FOUND);return;}// 确认请求try {// 最终会调用 Http11Processor#ack() 方法// 也就是简单地将 HTTP/1.1 100 加上回车换行符写给客户端// public static final byte[] ACK_BYTES = ByteChunk.convertToBytes("HTTP/1.1 100 " + CRLF + CRLF);response.sendAcknowledgement();} catch (IOException ioe) {container.getLogger().error(sm.getString("standardContextValve.acknowledgeException"), ioe);request.setAttribute(RequestDispatcher.ERROR_EXCEPTION, ioe);response.sendError(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);return;}if (request.isAsyncSupported()) {request.setAsyncSupported(wrapper.getPipeline().isAsyncSupported());}// 调用Wrapper的处理点wrapper.getPipeline().getFirst().invoke(request, response);
}
2、如何通过Context找到Wrapper
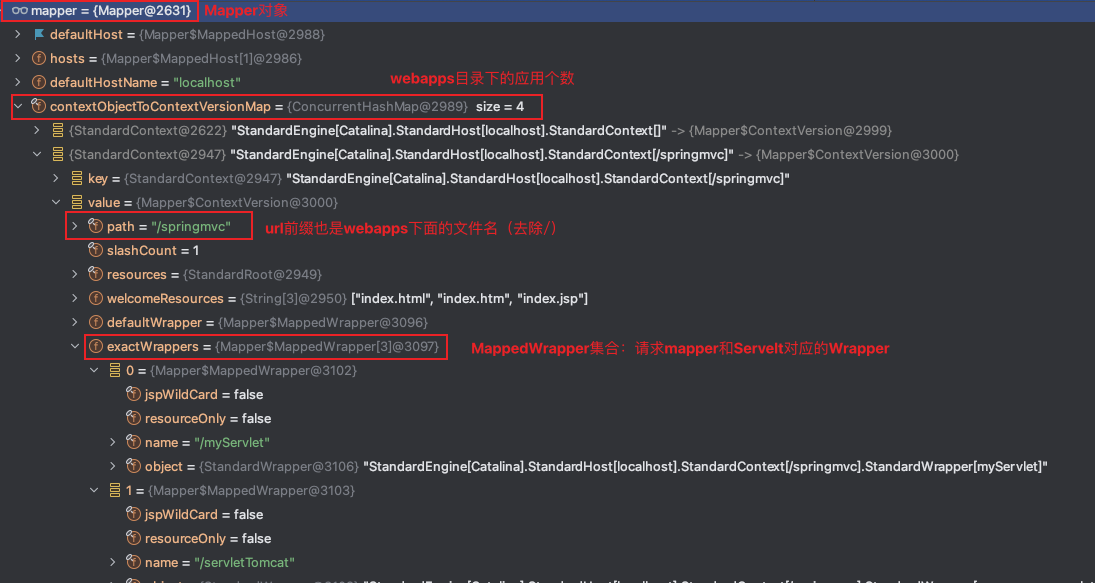
tomcat启动时候,在将所有Servelt实例化以后,会将所有的映射url和Wrapper组成MappedWrapper统一放到esactWrappers集合中。
在解析请求后调用如下方法,通过请求解析的path找到esactWrappers集合中对应的MappedWrapper,最终会将获取到Wrapper对象的mappingData.wrapper属性赋值给Request,这样上面request.getWrapper()就能获取到Wrapper,从而找到Servelt。
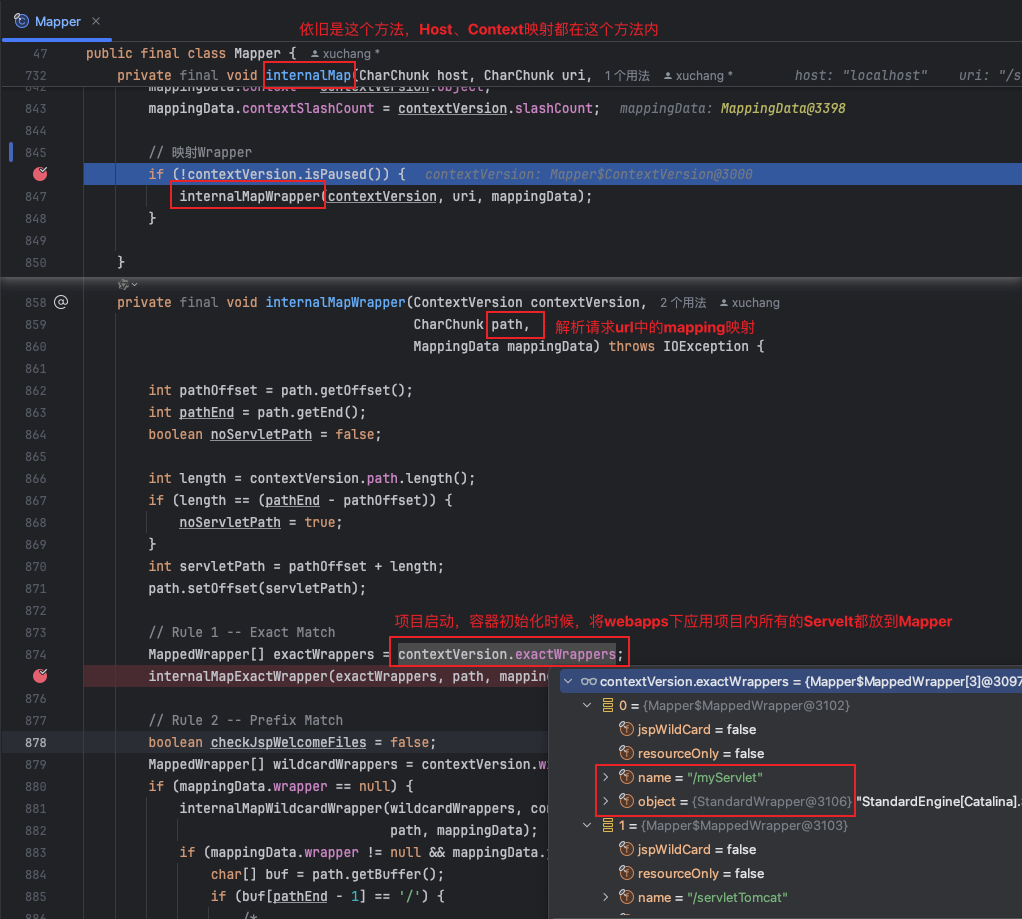
之前篇章Tomcat源码解析(五):StandardEngine、StandardHost、StandardContext、StandardWrapper最后一节Mapper组件介绍过Mapper的组成,下面再来看下Mapper中对应映射和Wrapper的位置。
四、Wrapper管道内容
1、StandardWrapperValve
- 第一步:获取Wrapper中的Servelt实例(
loadOnStartup>0的已经在项目启动时候实例化和初始化),如果loadOnStartup默认值-1则表示此时才会实例化和初始化Servelt并返回 - 第二步:
为此请求创建过滤器链(包括要执行的Servelt),过滤器链先添加Servelt,再通过过滤器的urlPatterns和servletNames匹配当前servelt添加到过滤器链中 - 第三步:过滤器链执行完以后,释放过滤器链,
将过滤器链中的过滤器和Servelt置为空,因为下个请求还需要重新创建过滤器链
// StandardWrapperValve类方法
@Override
public final void invoke(Request request, Response response)throws IOException, ServletException {..// 获取WrapperStandardWrapper wrapper = (StandardWrapper) getContainer();Servlet servlet = null;Context context = (Context) wrapper.getParent();...// 分配一个 servlet 实例来处理此请求// 如果是loadOnStartup>0的Servlet直接从Wrapper中获取即可,否则需要实例化创建try {if (!unavailable) {servlet = wrapper.allocate();}} catch (xxxException e) {...} // 解析请求的mapping映射// 如:http://localhost:8080/springmvc/servletTomcat,这里为/serveltTomcatMessageBytes requestPathMB = request.getRequestPathMB();... // 为此请求创建过滤器链(包括要执行的Servelt)ApplicationFilterChain filterChain =ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);// 为此请求调用过滤器链// 注意:这也调用了servlet的service()方法try {if ((servlet != null) && (filterChain != null)) {...// 执行连接器链filterChain.doFilter(request.getRequest(),response.getResponse());...}} catch (xxxException e) {throwable = e;// 将异常添加到request,并设置错误码500exception(request, response, e);}// 释放过滤器链,将过滤器链中的过滤器和Servelt置为空if (filterChain != null) {filterChain.release();}...
}
1.1、创建过滤器链
- 从req从获取过滤器链,没有的话创建
ApplicationFilterChain过滤器链对象 - 将
servelt添加到过滤器链中 - 获取项目启动时候实例化的所有过滤器
- 先根据过滤器的
urlPatterns匹配当前servelt,匹配成功添加到过滤器链中 - 再根据过滤器的
servletNames匹配当前servelt,匹配成功添加到过滤器链中
// ApplicationFilterFactory类方法
public static ApplicationFilterChain createFilterChain(ServletRequest request,Wrapper wrapper, Servlet servlet) {// 如果servelt为空,则返回nullif (servlet == null)return null;// 创建过滤器链对象,并设置给requestApplicationFilterChain filterChain = null;if (request instanceof Request) {Request req = (Request) request;if (Globals.IS_SECURITY_ENABLED) {// Security: Do not recyclefilterChain = new ApplicationFilterChain();} else {filterChain = (ApplicationFilterChain) req.getFilterChain();if (filterChain == null) {filterChain = new ApplicationFilterChain();req.setFilterChain(filterChain);}}} else {// Request dispatcher in usefilterChain = new ApplicationFilterChain();}// 将servelt添加到过滤器链中filterChain.setServlet(servlet);filterChain.setServletSupportsAsync(wrapper.isAsyncSupported());// 获取上下文及项目启动加载的所有过滤器StandardContext context = (StandardContext) wrapper.getParent();FilterMap filterMaps[] = context.findFilterMaps();// 如果没有过滤器,我们就完成了,自己返回,里面只有serveltif ((filterMaps == null) || (filterMaps.length == 0))return (filterChain);// 拦截方式配置也就是资源被访问的形式(没明白)DispatcherType dispatcher =(DispatcherType) request.getAttribute(Globals.DISPATCHER_TYPE_ATTR);...String servletName = wrapper.getName();// 根据过滤器的urlPatterns匹配当前serveltfor (int i = 0; i < filterMaps.length; i++) {if (!matchDispatcher(filterMaps[i] ,dispatcher)) {continue;}if (!matchFiltersURL(filterMaps[i], requestPath)){continue;}ApplicationFilterConfig filterConfig = (ApplicationFilterConfig)context.findFilterConfig(filterMaps[i].getFilterName());if (filterConfig == null) {continue;}// 添加到过滤器链filterChain.addFilter(filterConfig);}// 根据过滤器的servletNames匹配当前serveltfor (int i = 0; i < filterMaps.length; i++) {if (!matchDispatcher(filterMaps[i] ,dispatcher)) {continue;}if (!matchFiltersServlet(filterMaps[i], servletName)){continue;}ApplicationFilterConfig filterConfig = (ApplicationFilterConfig)context.findFilterConfig(filterMaps[i].getFilterName());if (filterConfig == null) {// FIXME - log configuration problemcontinue;}// // 添加到过滤器链filterChain.addFilter(filterConfig);}// 返回完整的过滤器链return filterChain;
}
1.2、执行过滤器链

1.2.1、Request和Response的门面模式
在调用拦截器链之前,先看下request.getRequest(), response.getResponse()这两个方法,在这之前Request指的是Request implements HttpServletRequest,Response指的是Response implements HttpServletResponse。从这个方法进入以后,Request指的是RequestFacade implements HttpServletRequest,Response指的是ResponseFacade implements HttpServletResponse。这里是利用门面模式,将Req和Res的内容分别包装在RequestFacade和ResponseFacade里面,后者就是起到一个传递作用,为的是保护Req和Res中的属性方法,只在后者暴露想让业务调用者调用的属性和方法。
获取RequestFacade和ResponseFacade
- 其实很简单,就是在RequestFacade和ResponseFacade对象中分别设置request和response属性
- 外界获取属性方法都是在RequestFacade的方法中调用Req和Res所得
// Request类方法
public HttpServletRequest getRequest() {if (facade == null) {facade = new RequestFacade(this);}if (applicationRequest == null) {applicationRequest = facade;}return applicationRequest;
}
// RequestFacade构造方法
protected Request request = null;
public RequestFacade(Request request) {this.request = request;
}// Response类方法
public HttpServletResponse getResponse() {if (facade == null) {facade = new ResponseFacade(this);}if (applicationResponse == null) {applicationResponse = facade;}return applicationResponse;
}
// ResponseFacade构造方法
protected Response response = null;
public ResponseFacade(Response response) {this.response = response;
}
1.2.2、doFilter方法

- 核心方法,先执行拦截器链,再执行Servelt实例
private void internalDoFilter(ServletRequest request,ServletResponse response)throws IOException, ServletException {// 如果有,请调用下一个过滤器。n是过滤器的个数,pos默认值是0if (pos < n) {ApplicationFilterConfig filterConfig = filters[pos++];try {Filter filter = filterConfig.getFilter();...filter.doFilter(request, response, this);...} catch (IOException | ServletException | RuntimeException e) {throw e;} return;}// 调用Servelt实例try {...servlet.service(request, response);...} catch (IOException | ServletException | RuntimeException e) {throw e;}
}
拦截器实例,拦截器的foFilter方法最后一定要调用filterChain.doFilter(servletRequest,servletResponse)这样整个拦截器链包括Servelt实例才能调用完整。
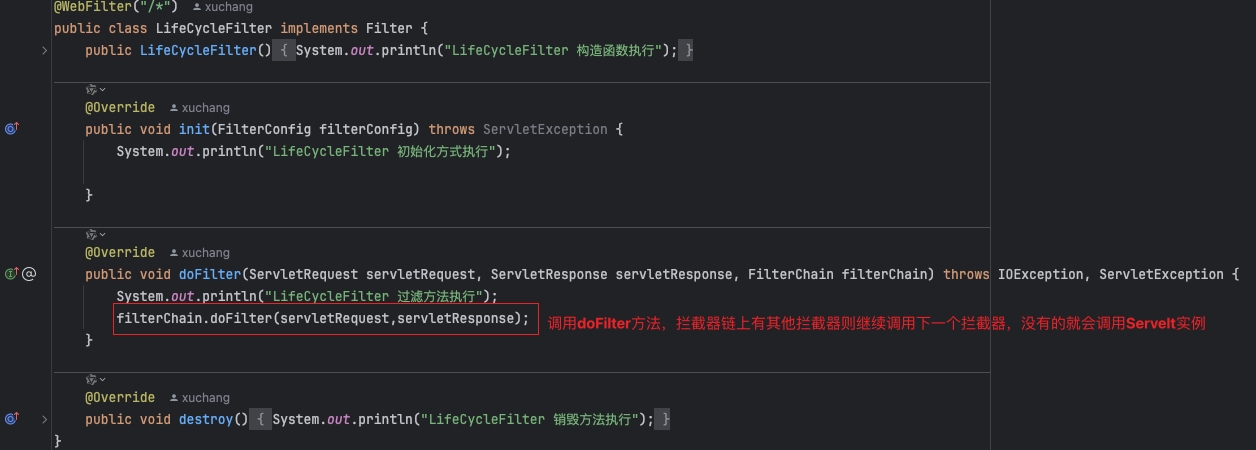
就这样,一个请求的执行流程执行完毕。
Tomcat最终总结
看着server.xml更容易理解
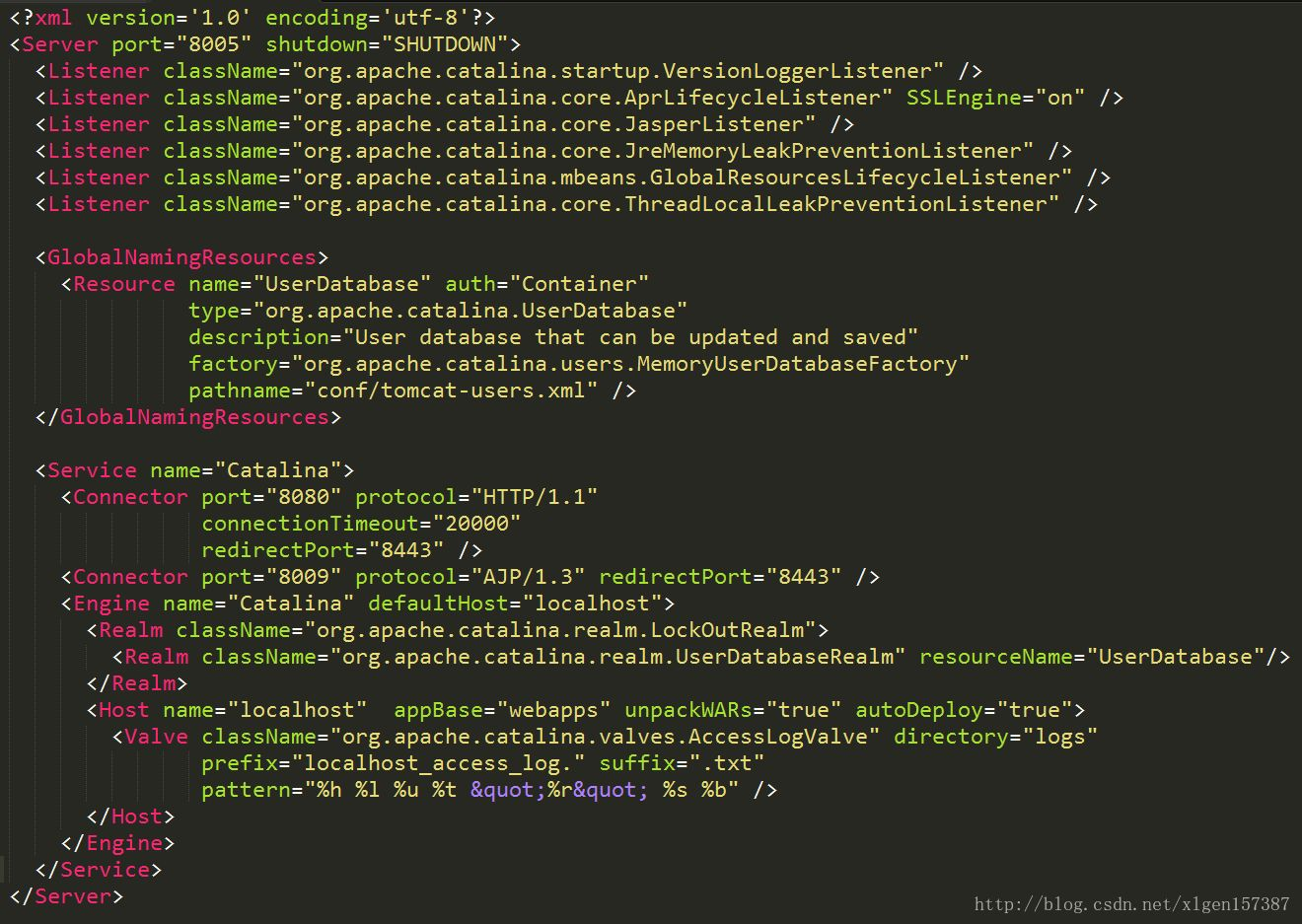
- 一个Server类的实例就代表了一个Tomcat的容器,一个
Tomcat进程只会有一个Server实例,也是Tomcat的主线程。Socket监听8005端口,ServerSocket服务端只要接受到Socket客户端发送消息“SHUTDOWN”(不论大小写),就会停止Tomcat应用 - 一个Server实例可以包含多个Service对象,Service对象由一个容器和多个连接器组成
- 容器:加载和管理
Servlet,以及具体处理Request请求 - 连接器:处理
Socket连接,负责网络字节流与Request和Response对象的转化
- 容器:加载和管理
- 容器分为:顶级容器Engine,虚拟主机Host,Web应用程序Context,Servelt包装类Wrapper
- Engine:从一个或多个Connector中接受请求并处理,并将完成的响应返回给Connector,最终传递给客户端。解析server.xml获取它下面所有的Host引用
- Host:运行多个Web应用(一个Context代表一个Web应用 ),并负责安装、展开、启动和结束每个Web应用。Context和Wrapper中解析出的请求映射和Servelt的内容统一放到Mapper中获取
- Context:一个web应用。加载webapps目录下的web应用,实例化和初始化监听器、过滤器、Servlet
- 考虑到不同网络通信和应用层协议,所以会有不同的连接器
- 默认8080端口的http协议,8009的AJP协议
- 连接器核心组件Endpoint使用三种线程接受处理请求
- Acceptor线程:一直死循环通过SocketChannel的accept方法接受连接,阻塞方法
- Poller线程:获取到Acceptor线程的连接,通过SocketChannel注册监听读事件,交给连接池处理
- 任务线程:读取解析socket请求数据封装为request和response调用Servelt方法
- 请求的处理流程(结合上面server.xml理解)
- 连接器
Connector监听解析拿到请求,通过Service对象找到唯一的顶级容器Engine - 顶级容器下有
多个虚拟主机Host,与本次请求解析的url对比,获取本次请求的Host - 虚拟主机下的webapps下有
多个web应用,与本次请求url的path对比,获取本次请求web应用 - web应用下有
多个Servelt,通过Mapper中记录的请求Mapping映射和Servelt对应关系找到Servevlt
- 连接器
这篇关于Tomcat源码解析(八):一个请求的执行流程(附Tomcat整体总结)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!