本文主要是介绍C语言:双链表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是双链表?
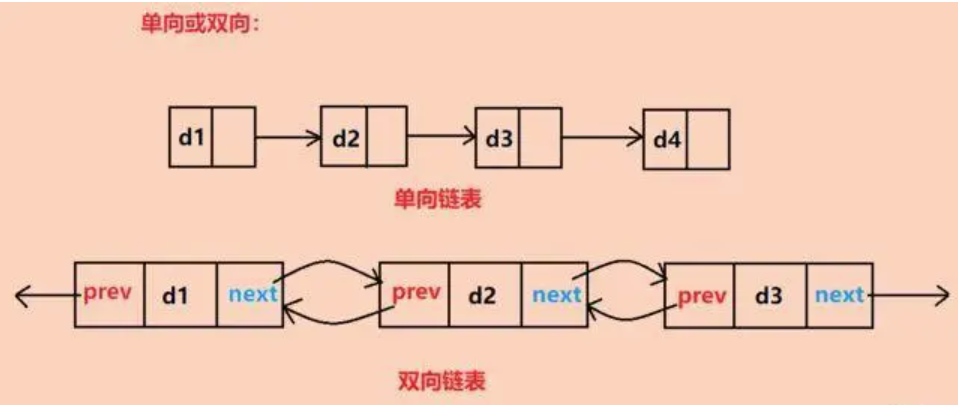
双链表,顾名思义,是一种每个节点都包含两个链接的链表:一个指向下一个节点,另一个指向前一个节点。这种结构使得双链表在遍历、插入和删除操作上都表现出色。与单链表相比,双链表不仅可以从头节点开始遍历,还可以从尾节点开始遍历,甚至从中间某个节点开始双向遍历。
二、双链表的特点
双向性:每个节点都包含两个指针,一个指向前一个节点,一个指向后一个节点。这使得双链表在遍历上更加灵活。
动态性:链表的大小可以根据需要动态地增加或减少,无需预先分配固定大小的内存空间。
三、实现双链表
typedef int LTDataType;
typedef struct ListNode
{LTDataType data;struct ListNode* next;struct ListNode* prev;
}LTNode;
三、实现的功能
LTNode* LTInit();// 初始化双链表
void LTDestroy(LTNode* phead);//销毁
void LTPrint(LTNode* phead);//打印
bool LTEmpty(LTNode* phead);//判断链表是否为空·void LTPushBack(LTNode* phead, LTDataType x);//尾插
void LTPopBack(LTNode* phead);//尾删void LTPushFront(LTNode* phead, LTDataType x);//头插
void LTPopFront(LTNode* phead);//头删
//在pos位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x);
void LTErase(LTNode* pos);//指定删除
LTNode* LTFind(LTNode* phead, LTDataType x);//查找1.创建节点
// 创建新的双链表节点
LTNode* LTBuyNode(LTDataType x) { LTNode* newNode = (LTNode*)malloc(sizeof(LTNode)); if (newNode == NULL) { perror("malloc fail!"); exit(1); } newNode->data = x; newNode->next = NULL; newNode->prev = NULL; return newNode;
} 使用malloc函数在堆上动态地分配内存空间,以存储LTNode结构体的大小。
检查malloc是否成功分配了内存。如果返回NULL,表示内存分配失败,此时调用perror函数打印错误消息,并使用exit(1)退出程序。
如果内存分配成功,将新节点的数据成员data设置为参数x的值。
初始化新节点的next和prev指针为NULL,表示这个新节点在创建时并不指向任何其他的节点。
返回指向新创建节点的指针。
2.初始化
LTNode* LTInit() { LTNode* pheda = LTBuyNode(-1); // 使用-1作为哨兵位头节点的数据 pheda->next = pheda; // 指向自己,表示链表为空 pheda->prev = pheda; return pheda;
}3.双链表的尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);// 创建一个新节点newnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;}newnode->prev = phead->prev; 将新节点的prev指针设置为当前链表的尾节点。
newnode->next = phead; 将新节点的next指针设置为头节点。phead->prev->next = newnode; 更新当前尾节点的next指针,使其指向新节点。
phead->prev = newnode; 更新头节点的prev指针,使其指向新节点
4.双链表的尾删
//尾删
void LTPopBack(LTNode* phead)
{assert(phead && phead->next != phead);LTNode* del = phead->prev;del->prev->next = phead;phead->prev = del->prev;free(del);del = NULL;
}prev指针指向链表的最后一个节点
del->prev->next = phead; 和 phead->prev = del->prev; 这两行代码更新了链表的链接,将尾节点从链表中移除。
5.双链表的头插
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode ->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}newnode ->next = phead->next;将新节点的next指针指向当前链表的第一个节点
newnode->prev = phead;将新节点的prev指针指向链表的头节点
phead->next->prev = newnode;更新当前链表第一个节点的prev指针,使其指向新节点。
phead->next = newnode;:更新链表的头节点的next指针,使其指向新节点,这样新节点就成为了链表的第一个节点。
6.双链表的头删
void LTPopFront(LTNode* phead)
{assert(phead && phead->next != phead);LTNode* del = phead->next;phead->next = del->next;phead->next->prev = phead;free(del);del = NULL;}LTNode* del = phead->next;:将待删除的节点的地址赋给del指针。
phead->next = del->next;:更新链表的头节点的next指针,使其跳过待删除的节点,直接指向下一个节点。
phead->next->prev = phead;:由于我们刚刚更新了phead->next,现在它指向的是原第一个节点的下一个节点。我们将这个新节点的prev指针更新为指向链表的头节点。
7.双链表的打印
void LTPrint(LTNode* phead)
{LTNode* pcur = phead->next;while (pcur != phead){printf("%d ", pcur->data);pcur = pcur->next;}printf("\n");
}8.在pos位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = LTBuyNode(x); newnode-> next = pos->next;newnode->prev = pos;pos->next->prev = newnode;pos->next = newnode;
}9.指定删除
void LTErase(LTNode* pos)
{assert(pos);assert(pos != pos->next);pos->prev->next = pos->next;// 更新pos的前一个节点的next指针pos->next->prev = pos->prev;//更新pos的下一个节点的prev指针free(pos);pos = NULL;
}10.判空
bool LTEmpty(LTNode* phead)
{return phead->next == phead;
}11.销毁
//销毁
void LTDestroy(LTNode* phead)
{LTNode* cur = phead->next;while (cur != phead){LTNode* tmp = cur;cur = cur->next;free(tmp);}free(phead);
}四、全部源码
LTNode* LTBuyNode(LTDataType x)
{LTNode* Node = (LTNode*)malloc(sizeof(LTNode));if (Node == NULL){perror("malloc fail!");exit(1);}Node->data = x;Node->next = NULL; Node->prev = NULL; return Node;
}
LTNode* LTInit() {LTNode* pheda = LTBuyNode(-1); // 使用-1作为哨兵头节点的数据 pheda->next = pheda; // 指向自己,表示链表为空 pheda->prev = pheda; return pheda;
}//销毁
void LTDestroy(LTNode* phead)
{LTNode* cur = phead->next;while (cur != phead){LTNode* tmp = cur;cur = cur->next;free(tmp);}free(phead);
}
//打印
void LTPrint(LTNode* phead)
{LTNode* pcur = phead->next;while (pcur != phead){printf("%d ", pcur->data);pcur = pcur->next;}printf("\n");
}
//判断链表是否为空·
bool LTEmpty(LTNode* phead)
{return phead->next == phead;
}
//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;}
//尾删
void LTPopBack(LTNode* phead)
{assert(phead && phead->next != phead);LTNode* del = phead->prev;del->prev->next = phead;phead->prev = del->prev;free(del);del = NULL;
}//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode ->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}
//头删
void LTPopFront(LTNode* phead)
{assert(phead && phead->next != phead);LTNode* del = phead->next;phead->next = del->next;phead->next->prev = phead;free(del);del = NULL;}
//查找LTNode* LTFind(LTNode* phead, LTDataType x)
{LTNode* cur = phead->next;while (cur != phead){if (cur->data == x){return cur;}cur=cur->next;}return NULL;
}在pos位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = LTBuyNode(x); newnode-> next = pos->next;newnode->prev = pos;pos->next->prev = newnode;pos->next = newnode;
}//指定删除
void LTErase(LTNode* pos)
{assert(pos);assert(pos != pos->next);pos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);pos = NULL;
}五、结语
让我们一起在编程的道路上不断前行,创造更加美好的未来!
这篇关于C语言:双链表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








