本文主要是介绍关于hdfs 你需要知道的10件事情,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
公众号:数据猿温大大
小猴&温大大对话



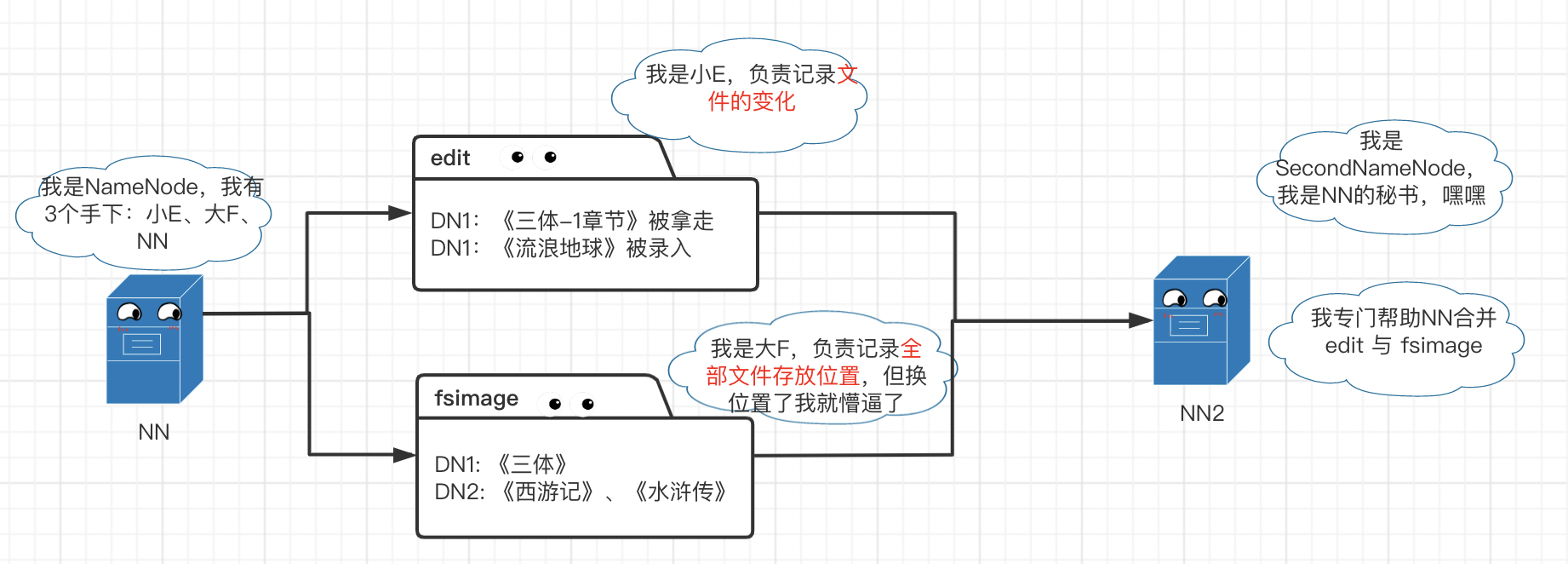
hdfs 角色简介





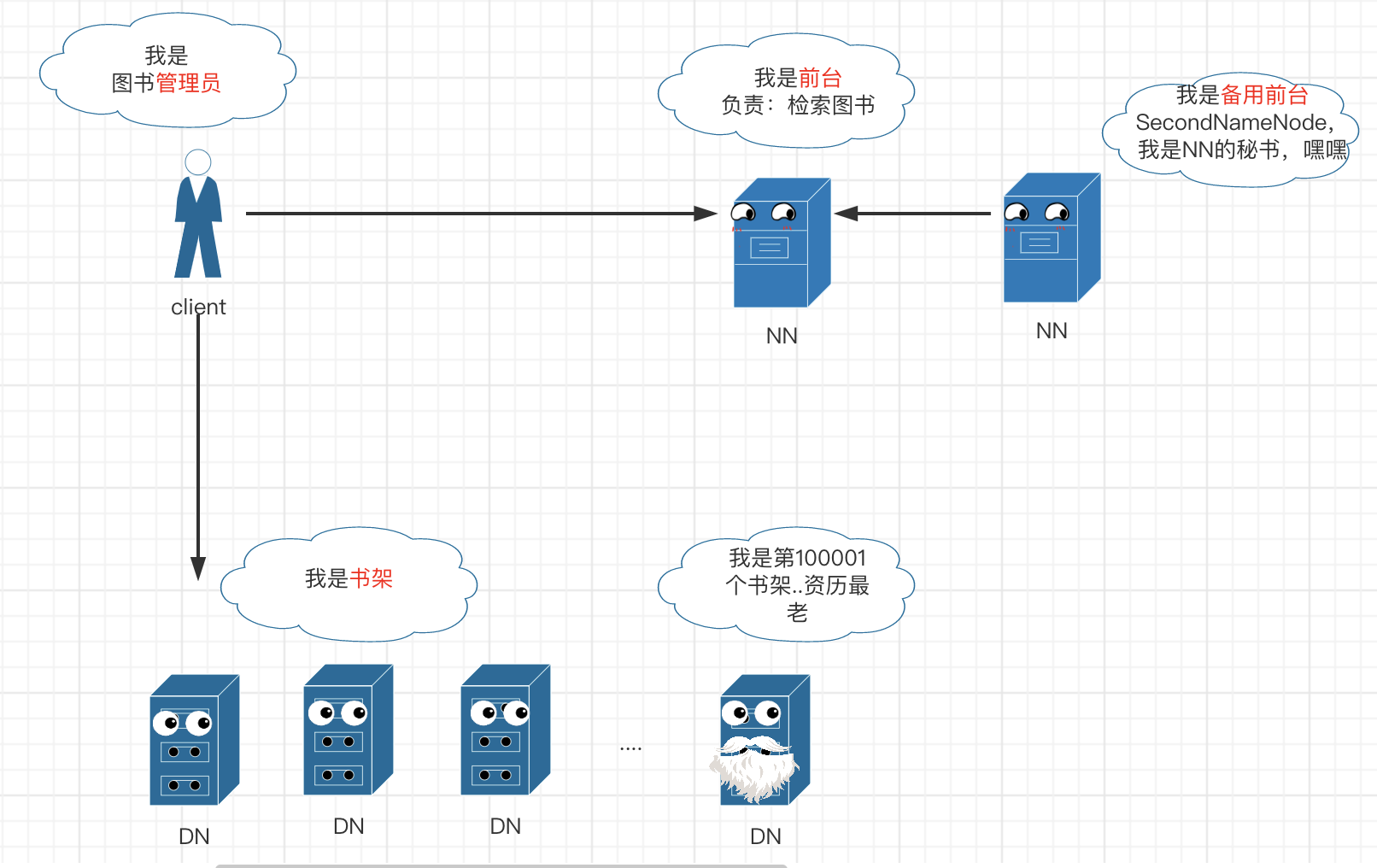
- Client:通过 CLI 或 API 来操作 DataNode(读 / 写操作)和 NameNode(获取文件位置信息),就像图书馆的管理员一样负责书籍的借取/录入。
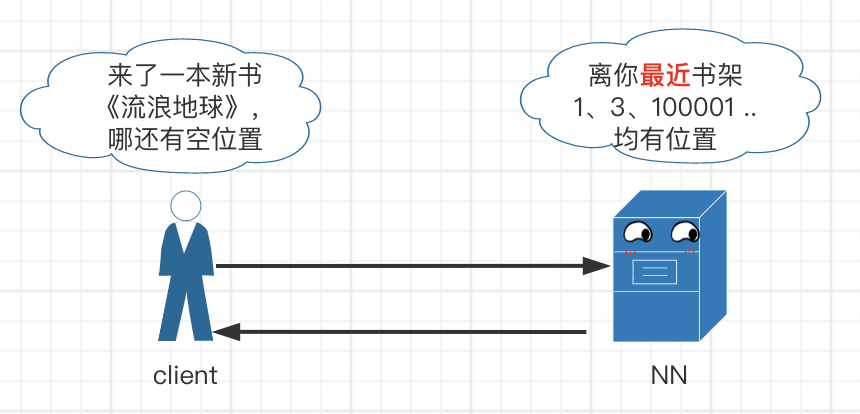
- NameNode:管理整个文件系统的元数据,如命名空间、数据块(Block)映射信息、副本策略及处理客户端读写请求,就像图书馆的前台一样负责检索图书所在位置。
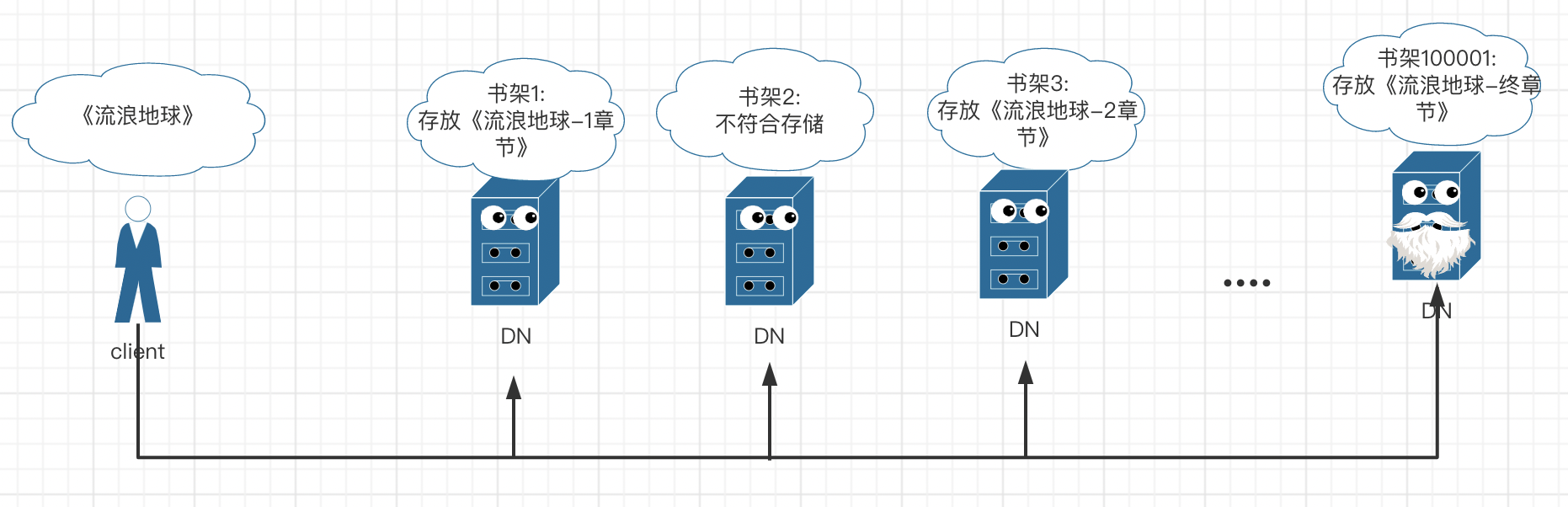
- DateNode:管理每个数据块,如存储实际的数据块,处理客户端对数据块的读/写操作,就像图书馆的书架一样存放具体的书籍。
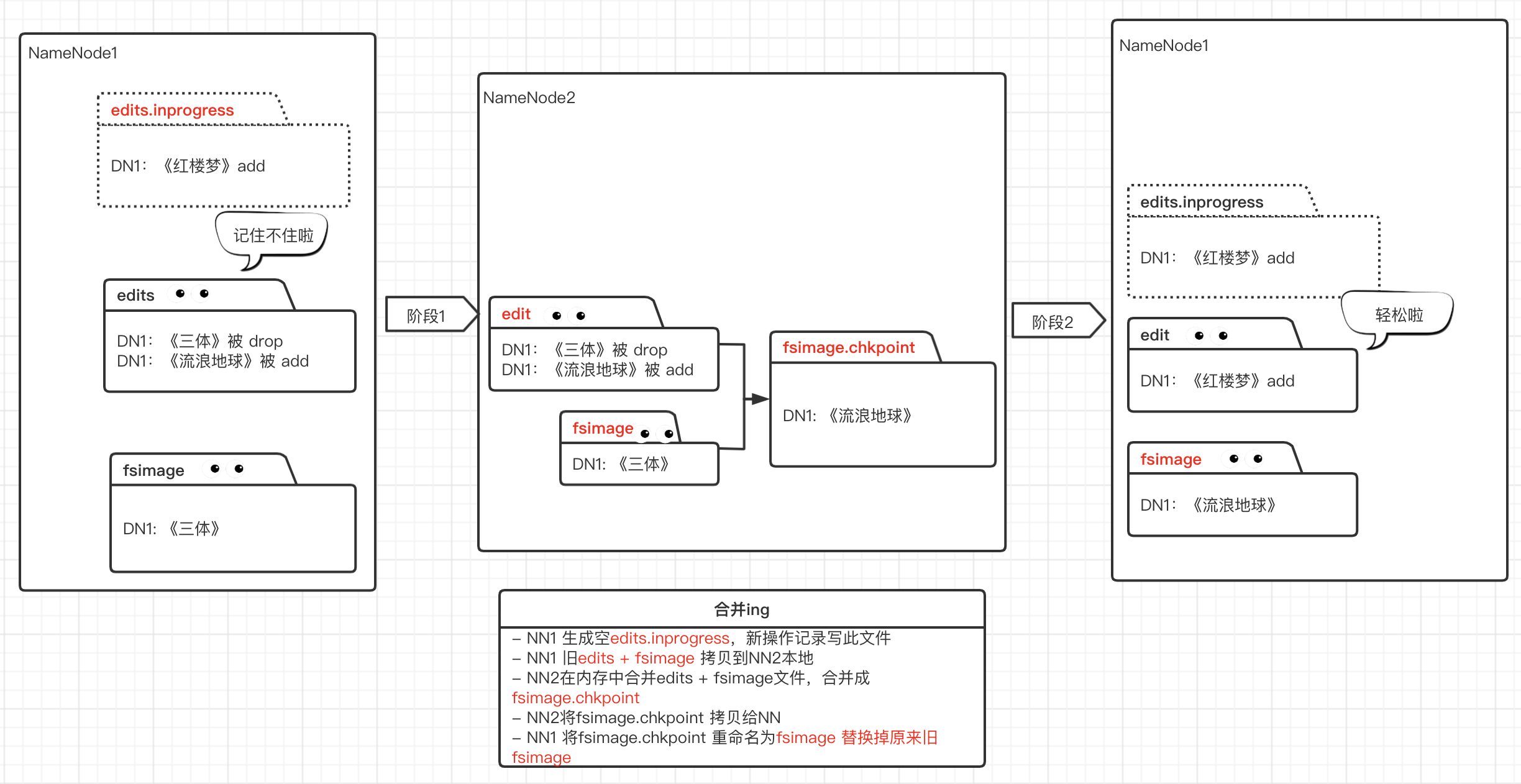
- Secondary NameNode:辅助 NameNode 分担工作量,定期合并 fsimage(命名空间镜像) 和 fsedits(修改日志) 并推送给 NameNode,就像第二个前台专门用来备份检索信息。
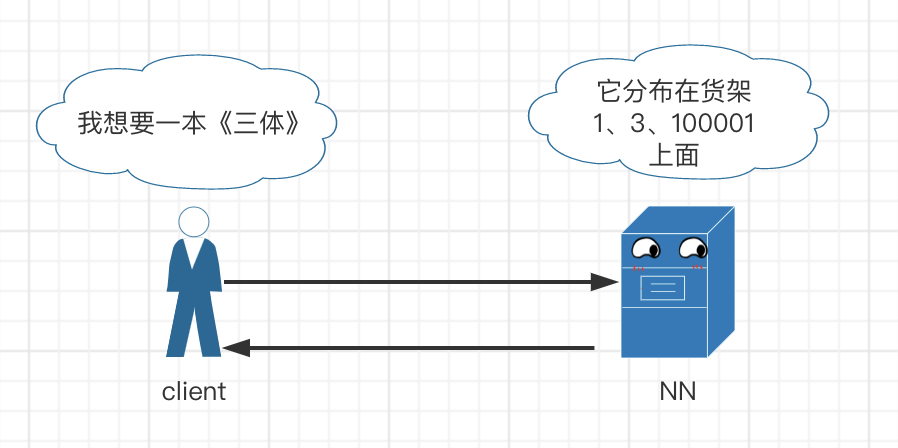
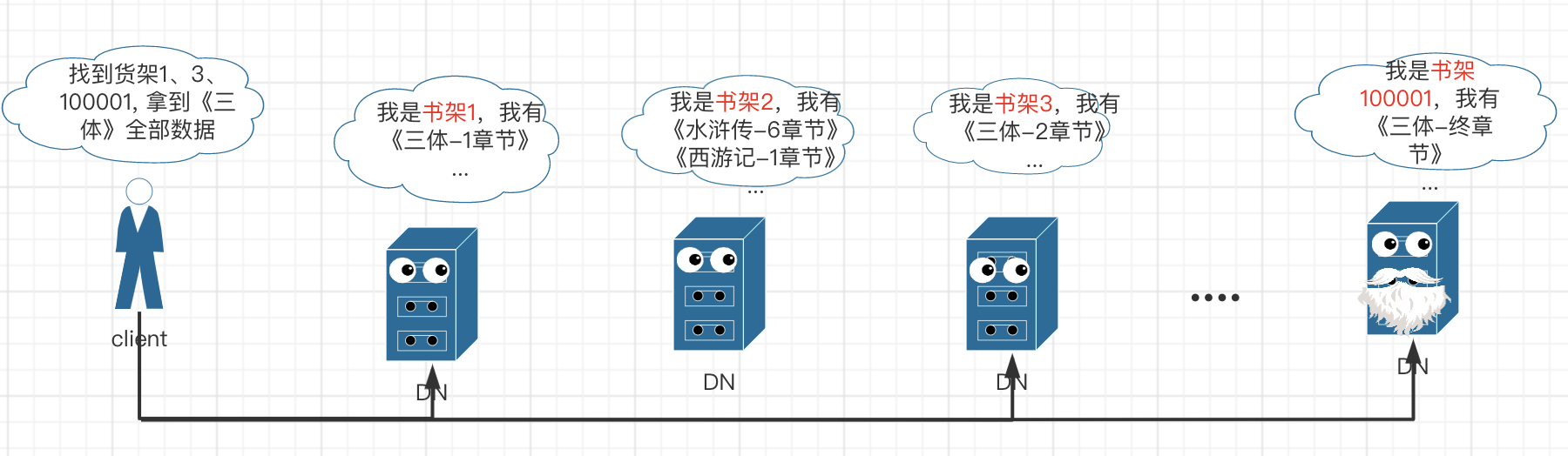
hdfs 读流程(借书)

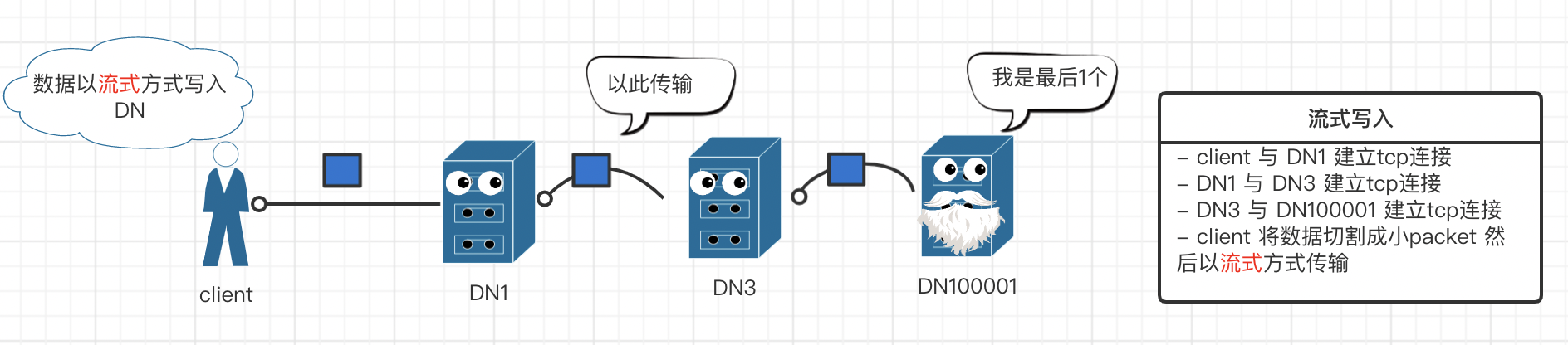
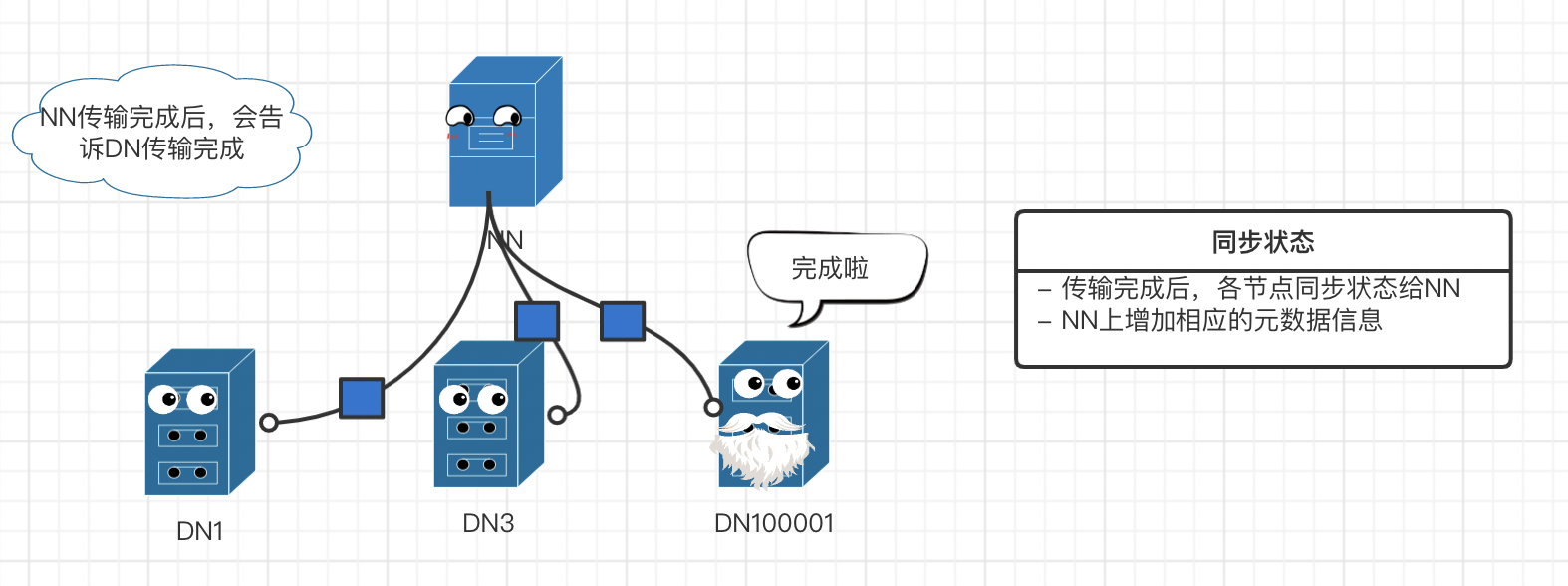
hdfs 写流程(存书)

hdfs Second NameNode流程(秘书)


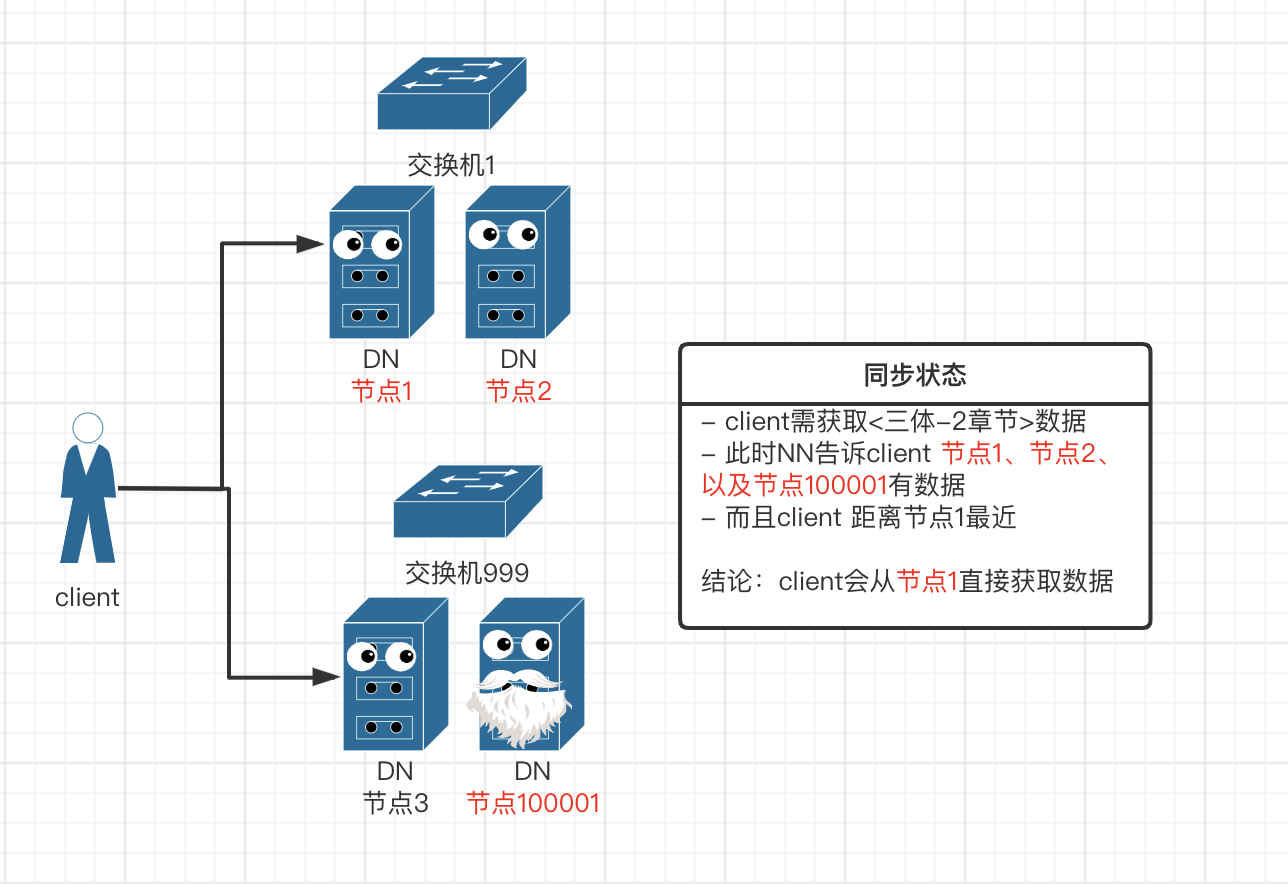
hdfs 网络拓扑(距离)



如下所示:client会从节点1获取数据,而不是从节点2、节点100001获取,原因是节点100001跨交换机会有网络损耗,节点1、2虽然都在同1台交换机上,但client就在节点1上,所以client最终会从节点1获取数据。
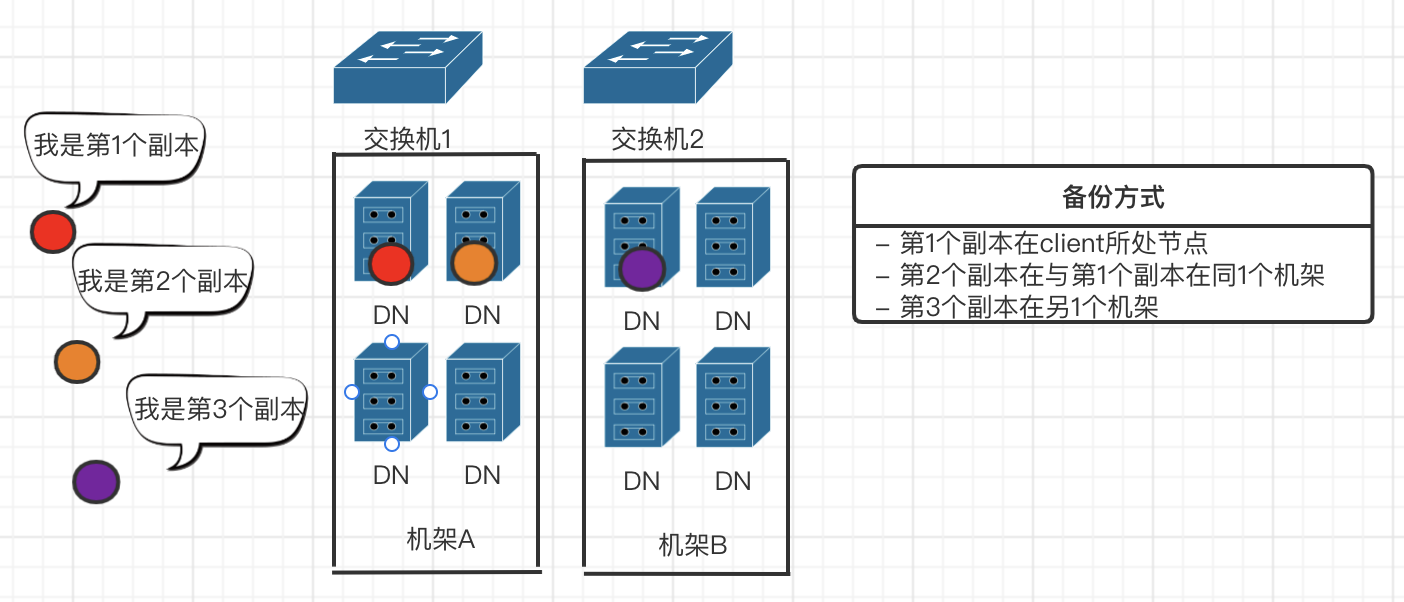
考虑:网络带宽的稀缺性,所以节点之间备份按照“彼此临近”传输,
计算如果将数据中心 d1 里的机架 r1 上的节点 n1 定义为 /d1/r1/n1 的话,
那么
- 同一节点上的两个应用程序:distance(/d1/r1/n1,/d1/r1/n1) = 0 2. 同一机架上的两个节点:distance(/d1/r1/n1,/d1/r1/n2) = 2
- 同一数据中心里不同机架上的两个节点:distance(/d1/r1/n1,/d1/r2/n3) = 4
- 不同数据中心的两个节点:distance(/d1/r1/n1, /d2/r4/n1) = 6

hdfs 副本策略(备份)

hdfs 容错性


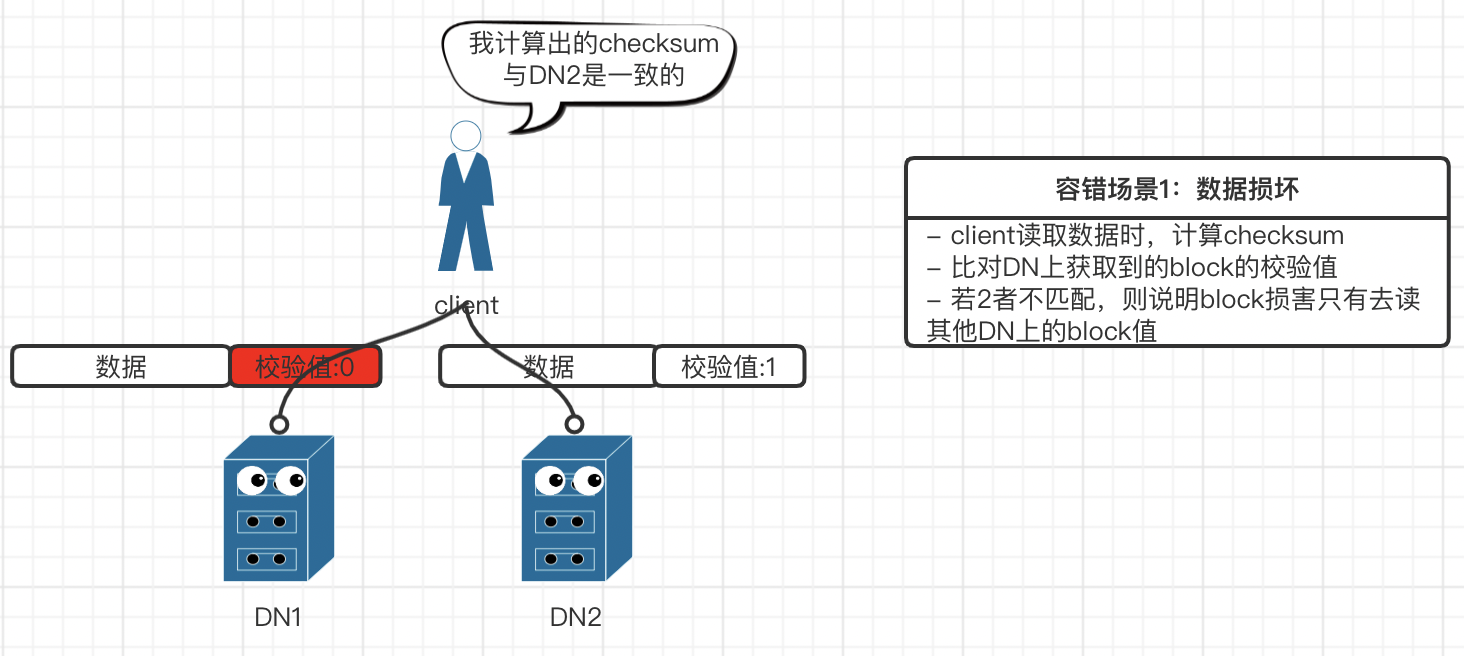
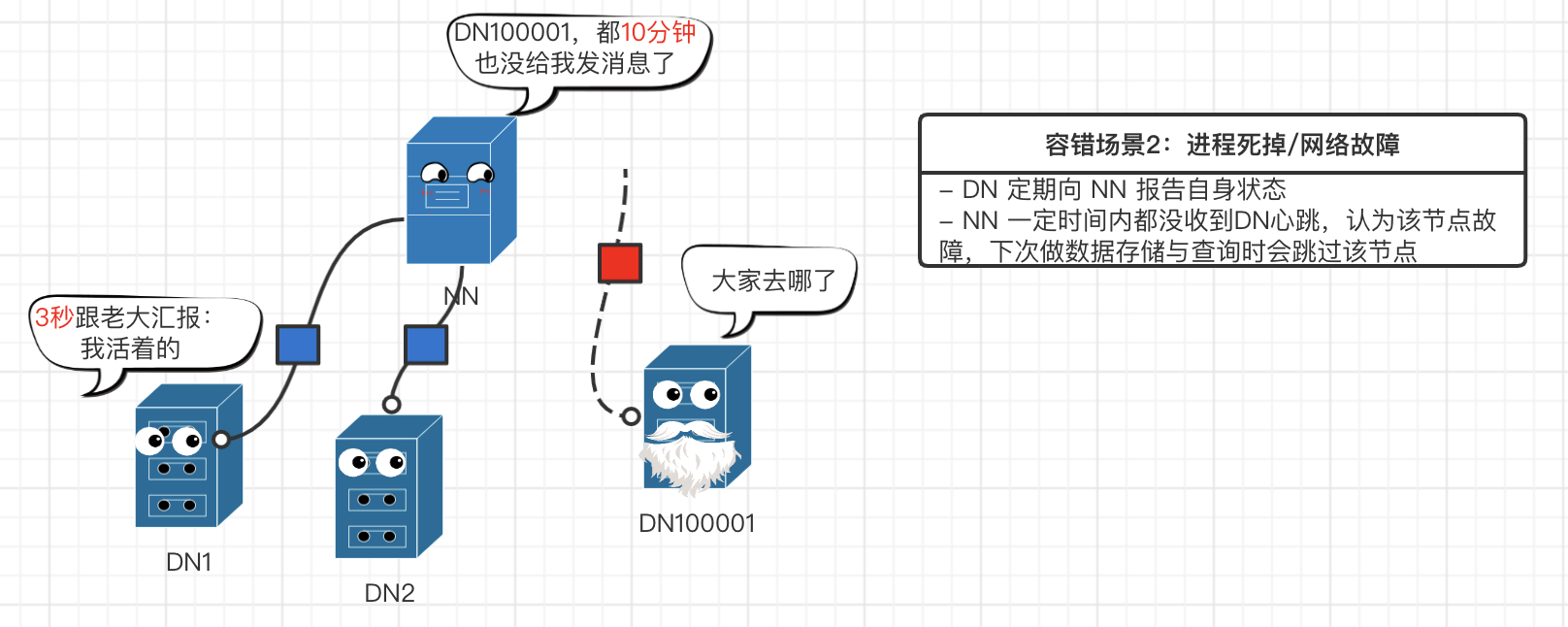
hdfs 总结

更多精彩内容关注公众号:数据猿温大大

这篇关于关于hdfs 你需要知道的10件事情的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![业务中14个需要进行A/B测试的时刻[信息图]](https://img-blog.csdnimg.cn/img_convert/aeacc959fb75322bef30fd1a9e2e80b0.jpeg)