本文主要是介绍LLVM Cpu0 新后端3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章:
LLVM 后端实践笔记
代码在这里(还没来得及准备,先用网盘暂存一下):
链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?pwd=vd6s 提取码: vd6s
这一章主要增加了大量的算数和逻辑指令,第三章的两节我们放在一起分析了,修改的文件如下:
目录
1. Cpu0ISelLowering.cpp/.h
2. Cpu0InstrInfo.td
3. Cpu0RegisterInfo.td
4. Cpu0SEISelDAGToDAG.cpp/.h
5. Cpu0SEInstrInfo.cpp/.h
6. Cpu0Schedule.td
7. Cpu0Subtarget.cpp
1. Cpu0ISelLowering.cpp/.h
这里设计了类型合法化的声明,使用 setOperationAction 函数,指定将 div 和 rem 在对 i32 类型下的操作做 expand,Cpu0 无法处理 sext_inreg,指定对各类型的sext_inreg做扩展,其实就是指定使用 LLVM 内置的函数来展开他们的实现(位于 TargetLowering.cpp 中)。
在这里特殊处理除法和求余运算的 lowering 操作,实现了一个 performDivRemCombine 函数,这是因为在 DAG 中,除法和求余的节点是同一个节点,叫 ISD::SDIVREM,节点中有个值来表示这个节点是计算商还是计算余数,虽然 Cpu0 后端本身并不关心要计算哪个值,因为都是通过 div 来计算的,但 DAG 一级还是会根据 C 代码的逻辑来区分的。当然我们的输出也需要考虑把哪个值(Hi 或 Lo)返回。div 运算会将商放到 Lo 寄存器,将余数放到 Hi 寄存器。
static SDValue performDivRemCombine(SDNode *N, SelectionDAG& DAG,TargetLowering::DAGCombinerInfo &DCI,const Cpu0Subtarget &Subtarget) {if (DCI.isBeforeLegalizeOps())return SDValue();EVT Ty = N->getValueType(0);unsigned LO = Cpu0::LO;unsigned HI = Cpu0::HI;unsigned Opc = N->getOpcode() == ISD::SDIVREM ? Cpu0ISD::DivRem :Cpu0ISD::DivRemU;SDLoc DL(N);SDValue DivRem = DAG.getNode(Opc, DL, MVT::Glue,N->getOperand(0), N->getOperand(1));SDValue InChain = DAG.getEntryNode();SDValue InGlue = DivRem;// insert MFLOif (N->hasAnyUseOfValue(0)) {SDValue CopyFromLo = DAG.getCopyFromReg(InChain, DL, LO, Ty, InGlue);DAG.ReplaceAllUsesOfValueWith(SDValue(N, 0), CopyFromLo);InChain = CopyFromLo.getValue(1);InGlue = CopyFromLo.getValue(2);}// insert MFHIif (N->hasAnyUseOfValue(1)) {SDValue CopyFromHi = DAG.getCopyFromReg(InChain, DL, HI, Ty, InGlue);DAG.ReplaceAllUsesOfValueWith(SDValue(N, 1), CopyFromHi);}return SDValue();
}performDivRemCombine 函数内会将架构无关的DAG节点ISD::SDIVREM/ISD::UDIVREM lower成架构相关的Cpu0ISD::DivRem/Cpu0ISD::DivRemU。然后将对应的对于余数的use点都替换成MFLO,将对于商的use点都替换成MFHI。这个过程是在DAGCombine阶段做的。
2. Cpu0InstrInfo.td
这一部分是这一章节的主要的改动点,增加了大量的算数和逻辑指令的定义。
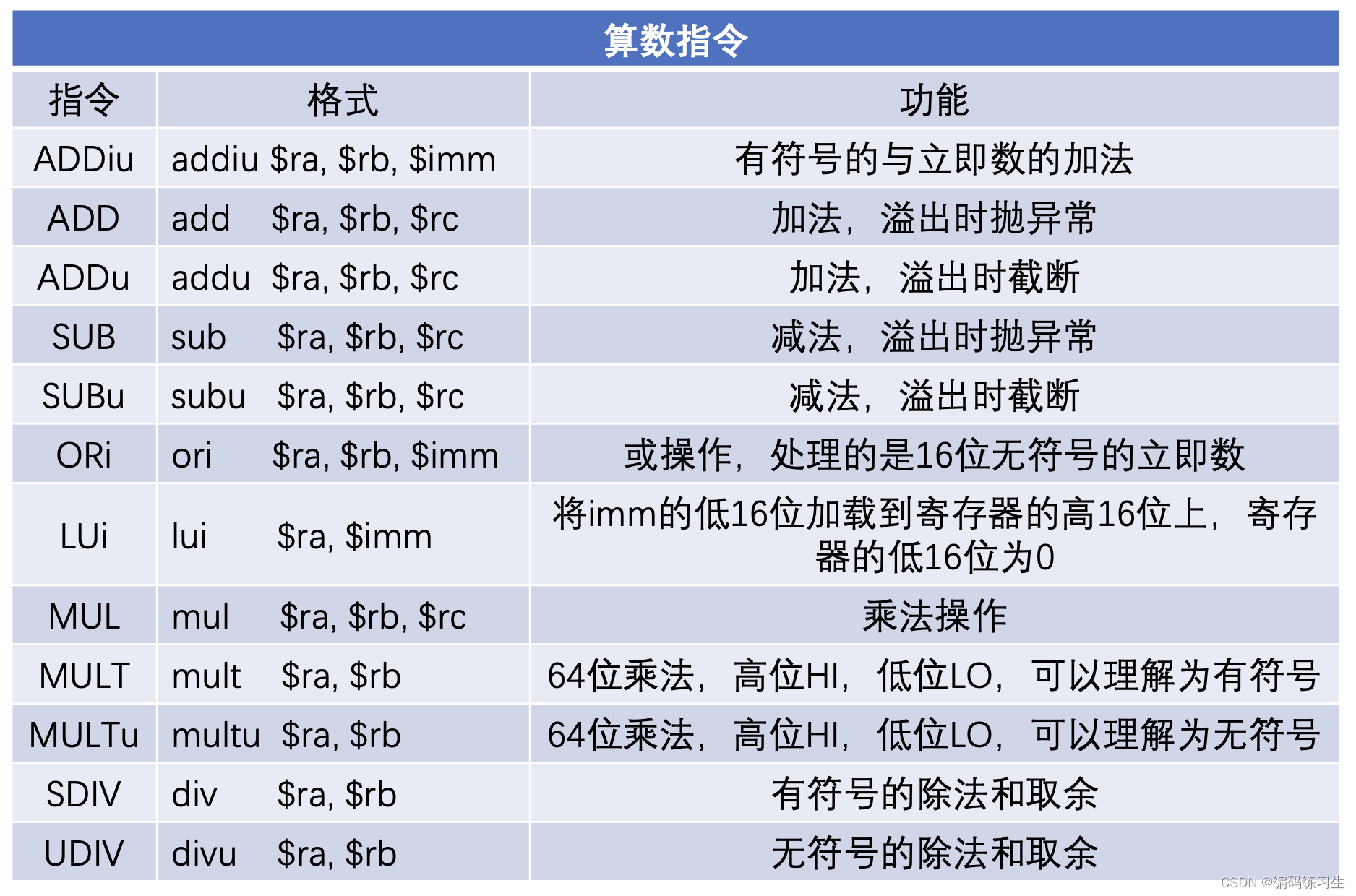
我们加了 -cpu0-enable-overflow 编译选项,它可以让编译器生成 addu 和 subu指令(这两个指令是会截断加减法结果的)或者 add 和 sub(这两个指令是会抛出溢出错误的)。不加该选项(默认是 false),可以查看汇编代码中,生成了 addu 和 subu 指令;然后增加该选项我们能看到对应的指令变成了 add 和 sub 。
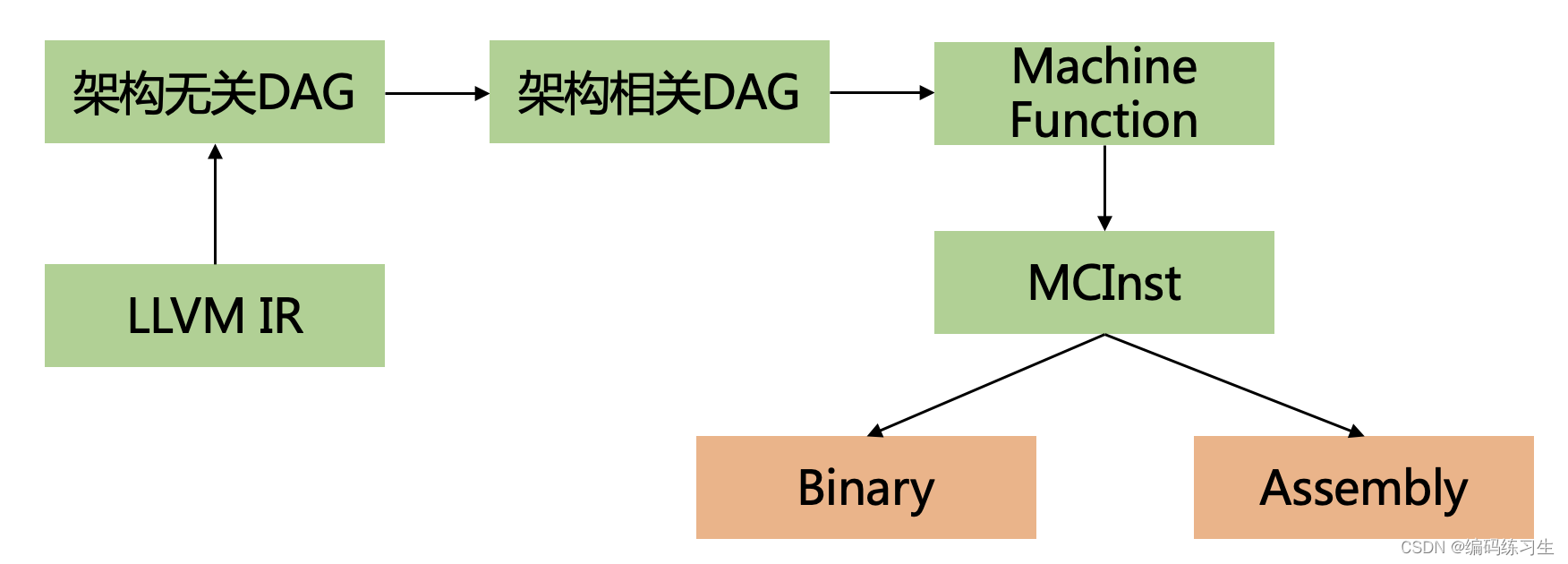
这里是LLVM中中端IR到后端的指令转化形式的简易版本,下述是带上一些关键流程的详细版本:
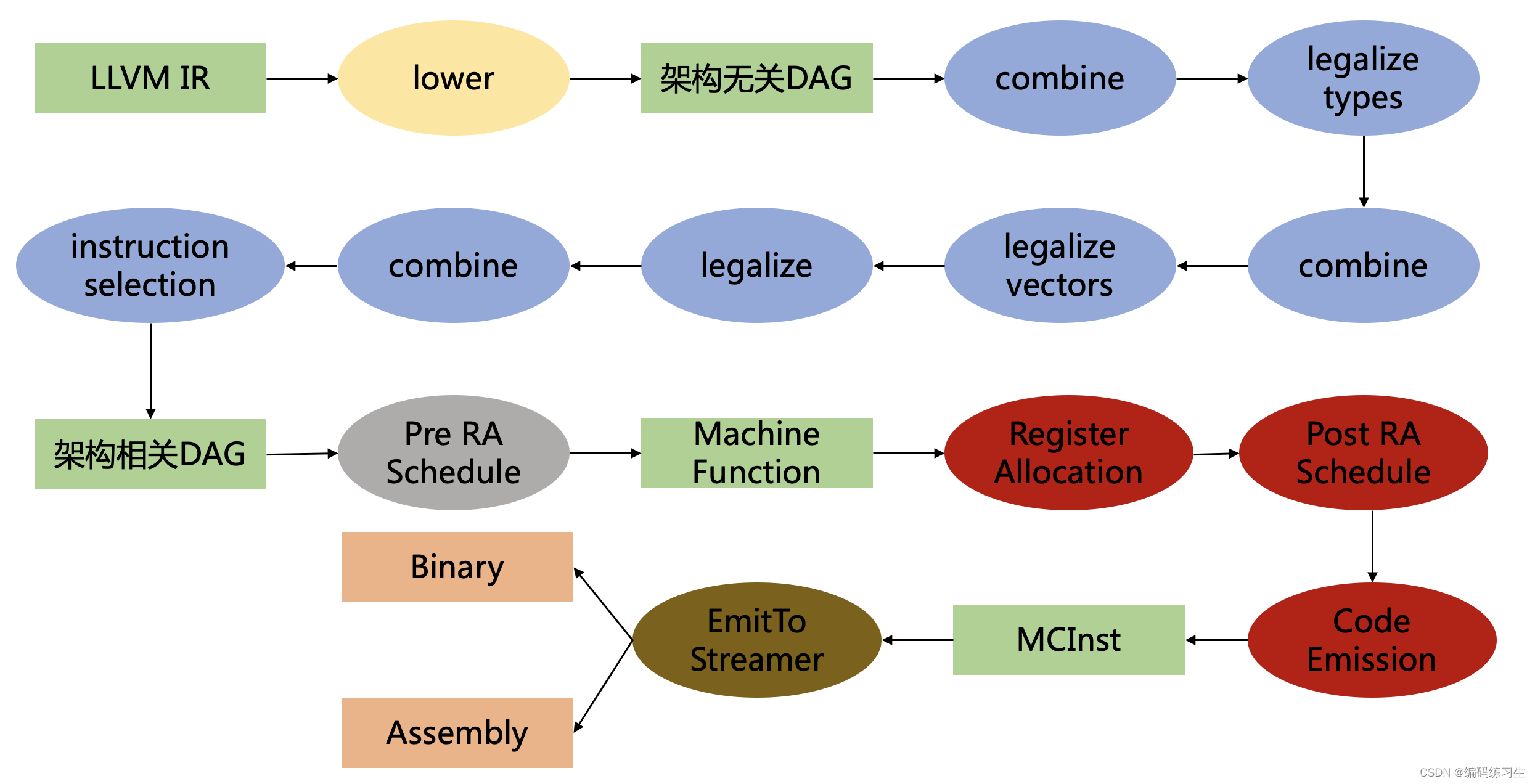
后半部分的流程其实就是我们前几节课完成的,当中的寄存器分配和指令调度优化不在本课程的范围呢,后续有时间再进一步讲解(其实我也还没彻底打通~)。我们今天主要关注前半部分的流程,我们以Cpu0的位移操作的指令转化为例。
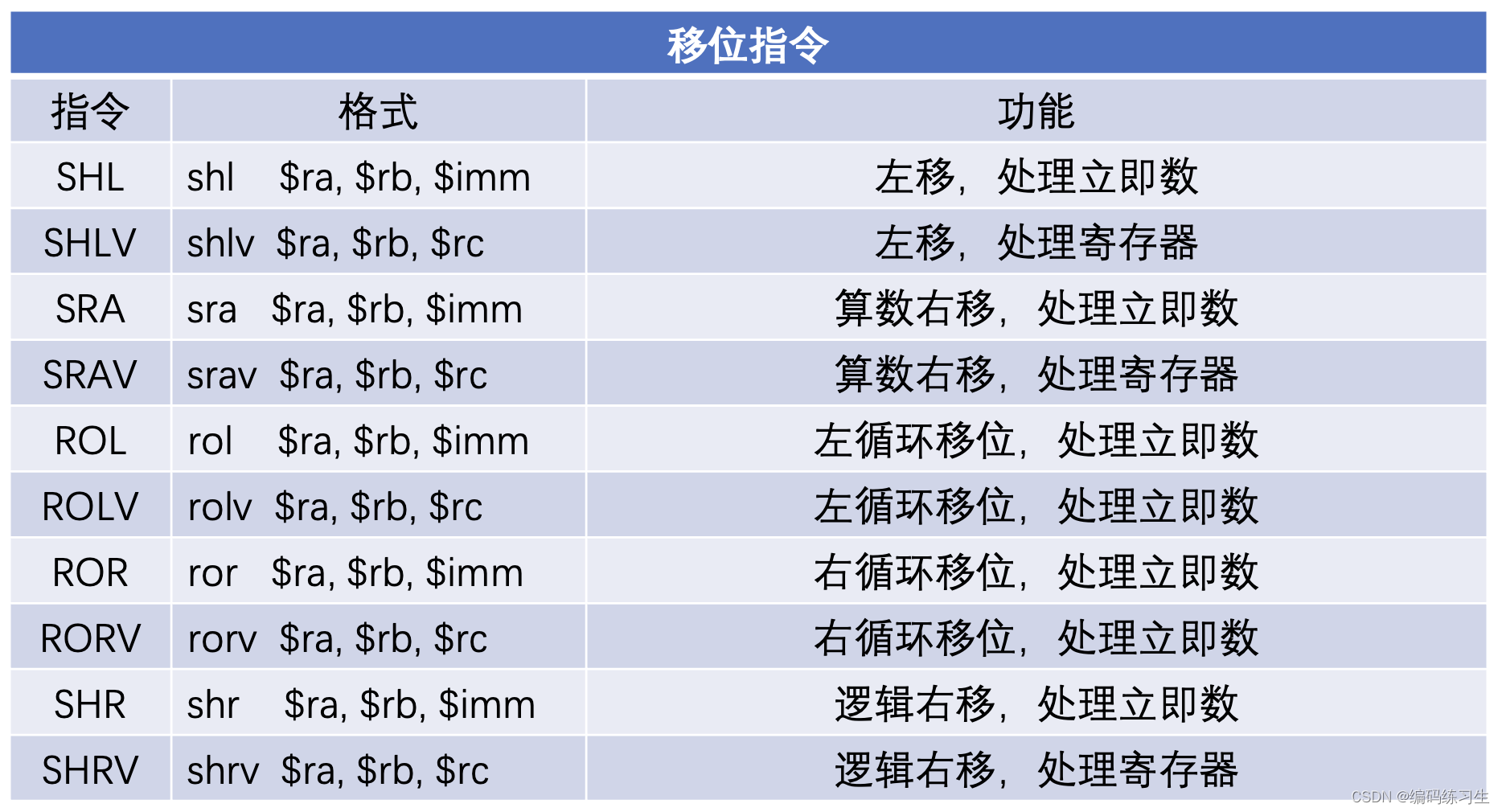
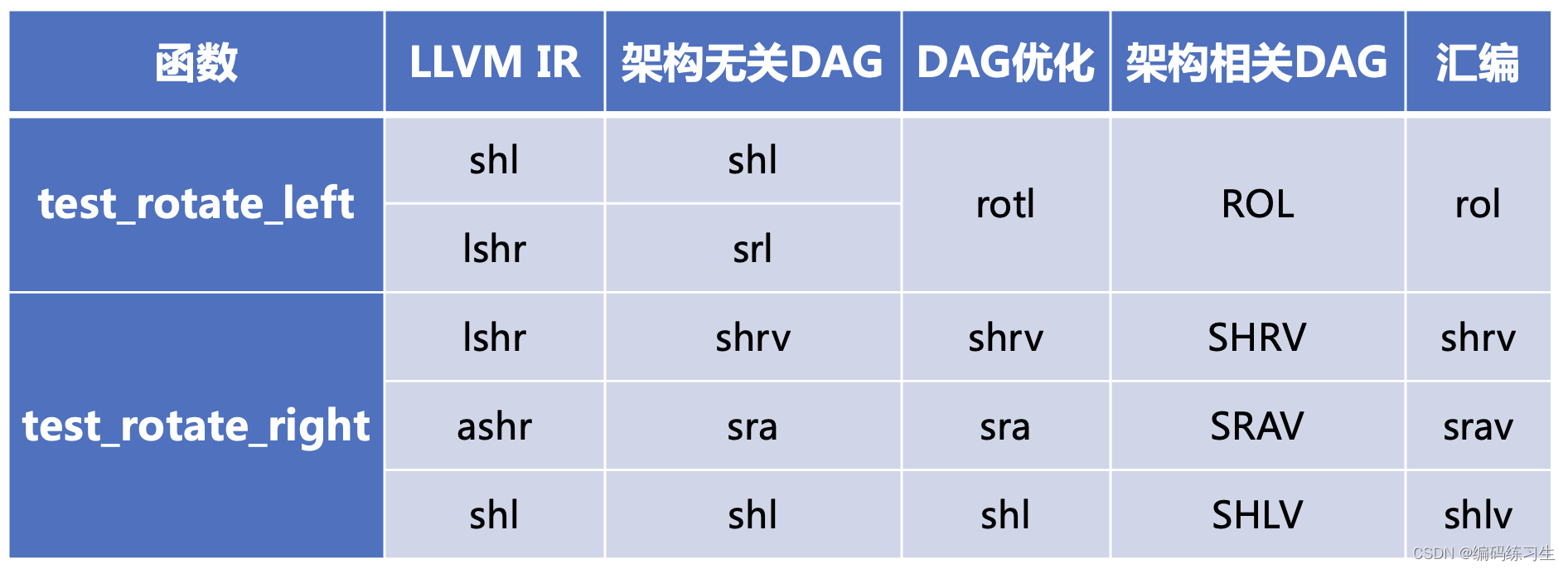
LLVM IR转化成架构无关的DAG的操作主要是在SelectionDAGISel::SelectBasicBlock函数内实现的,函数内通过visit的方式来将每一条指令lower成对应的DAG节点。(对于要遍历各种指令实现不同操作的需求来说,LLVM的visit的方式是很方便的,我们也可以继承LLVM的InstVisitor类,来直接复用重写其visit的功能,这是比较方便的一种方式,也可以自己定义visit,SelectionDAGISel类就是全部自己定义的。)然后在SelectionDAGISel::CodeGenAndEmitDAG函数内会进行各种DAG的优化操作,包括combine和legalize等操作,test_rotate_left函数内将shl和srl指令优化成一条rotl指令就是在combine内实现的。然后会运行到SelectionDAGISel::DoInstructionSelection接口执行指令选择的操作,将之前生成的DAG中的节点,转换成我们在Cpu0架构内定义的相应的节点,最后在生成汇编的时候输出相应的汇编指令。
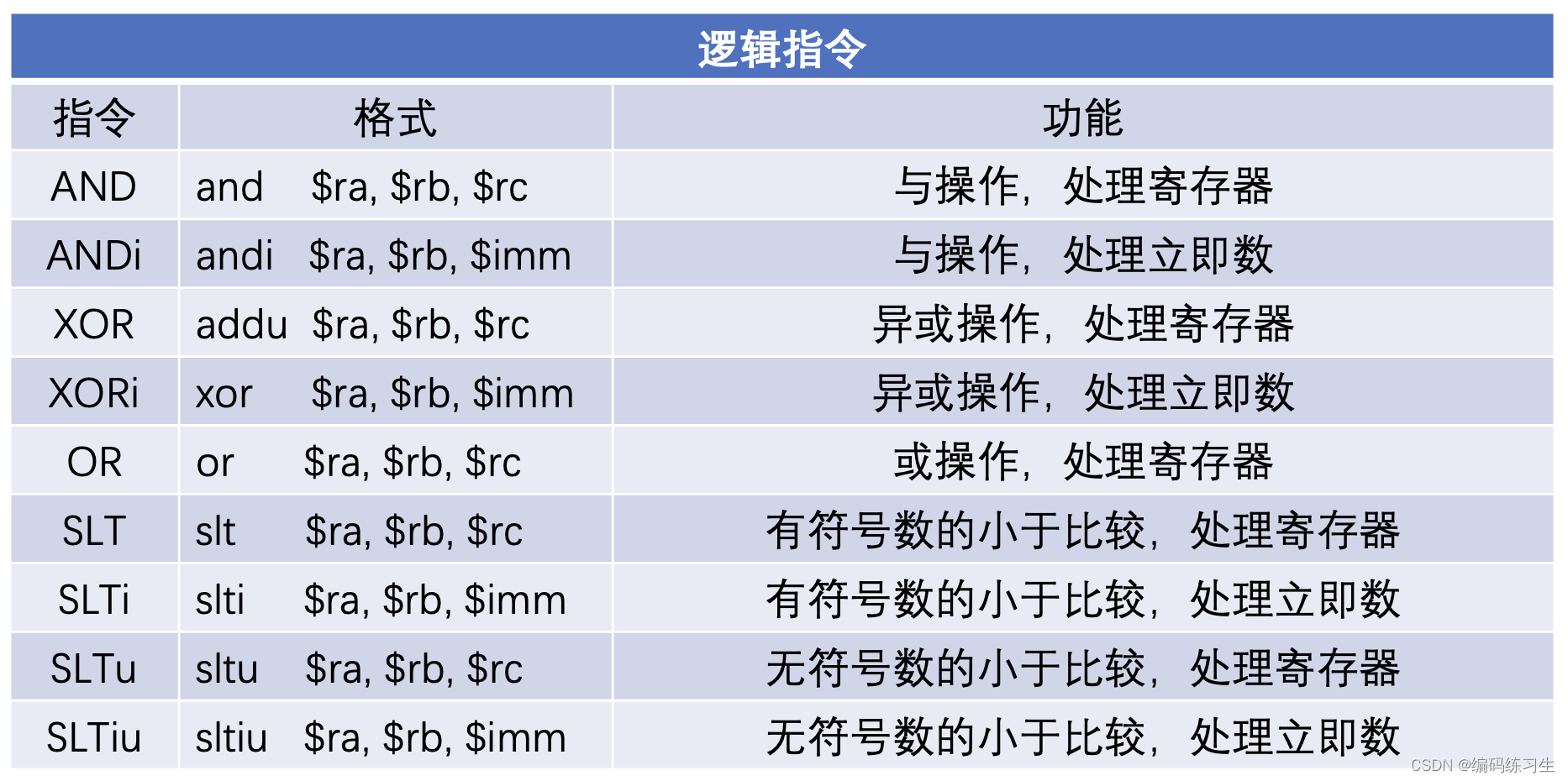
需要说明的一个设计是,在 cpu032I 中使用 cmp 指令完成比较操作,但在 cpu032II 中使用 slt 指令作为替代,slt 指令比 cmp 指令有优势,它使用通用寄存器来代替 $sw 寄存器,能够使用更少的指令来完成比较运算,比较运算 cmp 指令返回的值是 $sw 寄存器编码值,所以要针对我们需要的做一次转换,比如说我们要计算 a < b,指令中是 cmp $sw, a, b,我们要将 $sw 中的值分析出来,并最终将比较结果放到一个新的寄存器中。虽然 slt 指令返回一个普通寄存器的值,但因为它计算的是小于的结果,所以如果我们需要计算 a >= b,那就要对其结果做取反的运算。
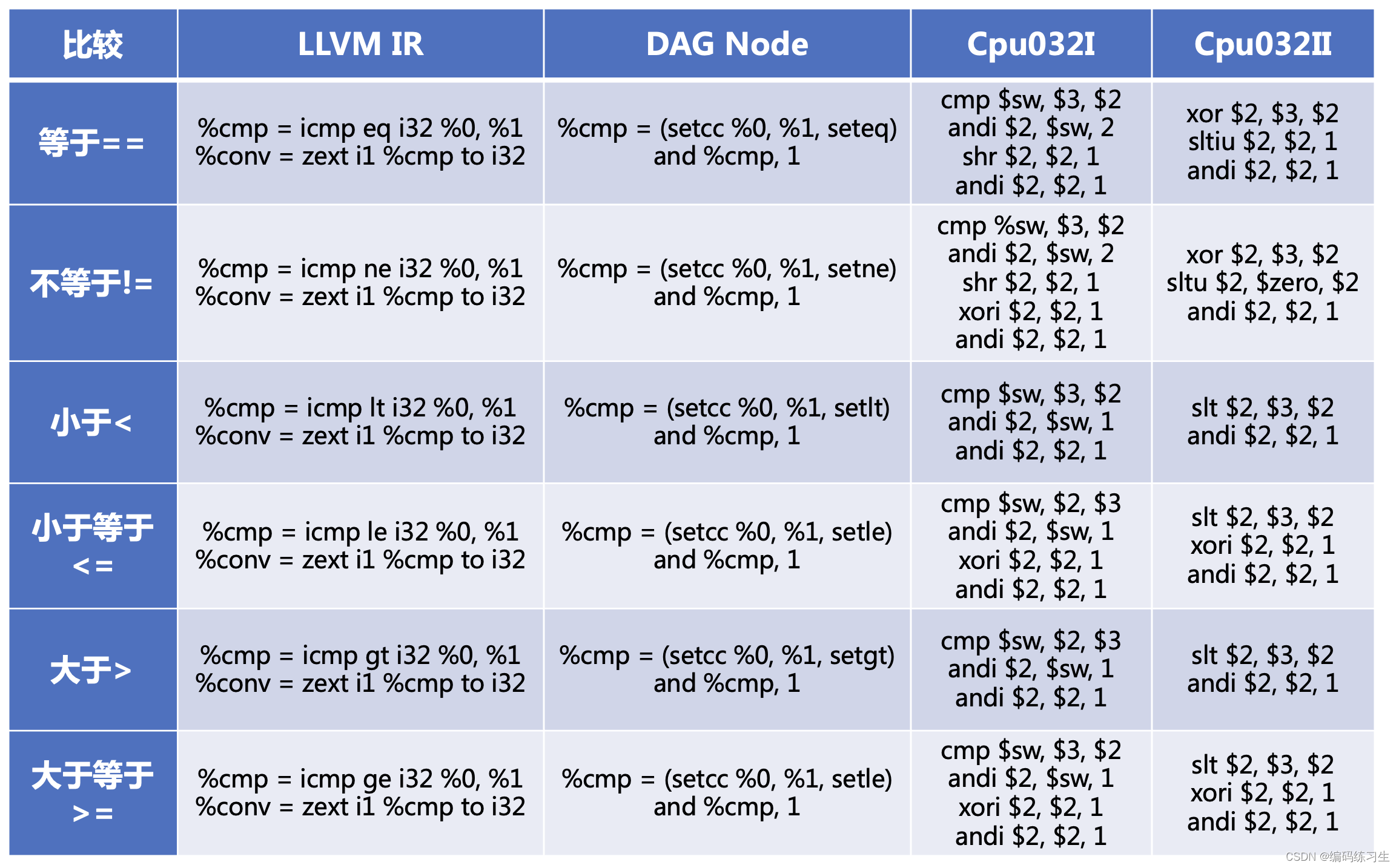
针对这些逻辑运算设计了它们的 pattern 等信息。
// Pat - A simple (but common) form of a pattern, which produces a simple result
// not needing a full list.
class Pat<dag pattern, dag result> : Pattern<pattern, [result]>;multiclass SeteqPatsCmp<RegisterClass RC> {// a == bdef : Pat<(seteq RC:$lhs, RC:$rhs),(SHR (ANDi (CMP RC:$lhs, RC:$rhs), 2), 1)>;// a != bdef : Pat<(setne RC:$lhs, RC:$rhs),(XORi (SHR (ANDi (CMP RC:$lhs, RC:$rhs), 2), 1), 1)>;
}
multiclass SeteqPatsSlt<RegisterClass RC, Instruction SLTiuOp, Instruction XOROp,Instruction SLTuOp, Register ZEROReg> {// a == bdef : Pat<(seteq RC:$lhs, RC:$rhs),(SLTiuOp (XOROp RC:$lhs, RC:$rhs), 1)>;// a != bdef : Pat<(setne RC:$lhs, RC:$rhs),(SLTuOp ZEROReg, (XOROp RC:$lhs, RC:$rhs))>;
}这里的匹配过程是这样的。对于cmp类型的Cpu032I指令,如果匹配到了 seteq+两个寄存器操作数的指令形式(可以看到上边DAG Node有类似指令),那我们就匹配上了,将这条指令替换成cmp+andi+shr三条Cpu032I指令。那么为什么是这三条指令呢?首先,使用 cmp $sw, a, b 将比较结果的 flag 放到 $sw 寄存器中,$sw 寄存器的最低两位分别是 Z (bit 1)和 N (bit 0),如果 a 与 b 相等,那么 Z = 1, N = 0,如果 a 与 b 不相等,那么 Z = 1, N 可为 0 或 1。这样,我们后边只需要对 $sw 寄存器做与 0b10 的与运算,提取这两位,然后右移 1 位拿到 Z 的值,它的值赋给另一个寄存器,这便是 a == b 的结果。
对于slt类型的Cpu032II指令,如果匹配到了 seteq+两个寄存器操作数的指令形式(可以看到上边DAG Node有类似指令),那我们就匹配上了,将这条指令替换成xor+sltiu两条Cpu032II指令。那么为什么是这两条指令呢?如果a与b相等,异或的结果是0,不等的话异或的结果一定是非0,然后我们将其与1进行无符号的小于比较,无符号的小于比较中,只有0小于1,因此替换成这两条指令。
这就是Pat类模式匹配的过程,第一个操作数是要匹配的模式,第二个操作数是模式匹配上的话输出的结果。
将两种比较的方式都实现,并在 def 时使用 HasSlt 和 HasCmp 来选择定义。Cpu032II 中是同时包含有 slt 和 cmp 指令的,但默认是优先选择 slt 指令。其小于运算不需要做这种映射,因为 slt 指令本身就是计算小于结果的。
3. Cpu0RegisterInfo.td
主要实现了 HI 和 LO 寄存器,以及 HILO 寄存器组,当中包括HI和LO,这个语法的使用我们之前介绍过。
4. Cpu0SEISelDAGToDAG.cpp/.h
主要实现了 selectMULT() 函数,用来处理乘法的高低位运算。在 ISD 中的乘法是区分 MUL 和 MULH 的,也就是用两个不同的 Node 来分别处理乘法返回低 32 位和高 32 位。selectMULT() 会放到 trySelect() 接口函数中,专用来处理 MULH 的特殊情况,并将 HI 作为返回值创建新的 Node。
5. Cpu0SEInstrInfo.cpp/.h
主要实现了 copyPhysReg() 函数,用来生成一些寄存器 move 的操作,会根据要移动的寄存器类型,生成不同的指令来处理。这个函数是基类的虚函数,直接覆盖实现,不需要考虑调用问题。如果目的寄存器和源寄存器都是通用寄存器,会使用 addu 来完成,这是一种通用做法。如果源寄存器是 HI 或 LO,会选择生成 mfhi 或 mflo 来处理。反之,如果目的寄存器是 Hi 或 Lo,会选择生成 mthi 和 mtlo 来处理。这里作为最后的指令选择阶段,可以直接使用 BuildMI 生成 MI 结构的指令。
6. Cpu0Schedule.td
实现了乘除法和 HILO 操作的指令行程类。
7. Cpu0Subtarget.cpp
这个文件中新增了一个控制溢出处理方式的命令行选项:-cpu0-enable-overflow,默认是 false,如果在调用 llc 时的命令行中使用这个选项,则为 true。false 时,表示当算术运算出现溢出时,会触发 overflow 异常,true 时,表示算术运算出现溢出时,会截断运算结果。我们将 add 和 sub 指令设计为溢出时触发 overflow 异常,把 addu 和 subu 设计为不会触发异常,而是截断结果。在 subtarget 中,将命令行选项的结果传入 EnableOverflow 类属性。
这篇关于LLVM Cpu0 新后端3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![Windows编译Hikari-LLVM15[llvm-18.1.8rel]并集成到Android Studio NDK](https://i-blog.csdnimg.cn/direct/325a10ddfe1940a38c135df0c09090f2.png)