本文主要是介绍人工智能在【肿瘤生物标志物】领域的最新研究进展|顶刊速递·24-06-08,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小罗碎碎念
本期文献速递的主题是——人工智能在“
肿瘤生物标志物”领域的最新研究进展。

重点关注
今天推荐的6篇文献中,第二篇和第三篇是小罗最喜欢的,因为对于临床来说,比较具有实际意义,也和自己的想法很契合。
尤其是第三篇,进行了前瞻性探索,这个必定是趋势。我在组会上也提过类似的建议,但貌似没有被采纳,希望其他感兴趣的老师能探索一下AI与临床结合的前瞻性试验,这个方向绝对是没有问题的。
我是罗小罗同学,我们明天见!!
交流群
欢迎大家来到【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。

一、SERS-深度学习分析,检测乳腺癌患者接受曲妥珠单抗免疫治疗的疗效

文献概述
这篇文章是关于一种新型的深度学习
辅助监测技术,该技术基于表面增强拉曼光谱(SERS)免疫分析法,用于监测HER2(人表皮生长因子受体2)过度表达的乳腺癌患者接受曲妥珠单抗(Trastuzumab,也称Herceptin®)治疗的效果。
曲妥珠单抗是一种靶向HER2的药物治疗,对于转移性乳腺癌非常有效,但一些患者可能对该药物产生抗性,因此监测其疗效至关重要。
研究团队开发了一种基于SERS的免疫分析法,通过检测患者尿液中肿瘤衍生的外泌体生物标志物来监测曲妥珠单抗的疗效。他们制备了带有特定SERS标签和外泌体捕获基质的个体拉曼报告器,收集SERS标签信号以准备深度学习训练数据。
利用深度神经网络(DNN)算法,成功地量化和分类了各种复杂的SERS标签混合物。通过SERS-深度学习分析,确定了五种细胞衍生外泌体的外泌体抗原水平,并与通过定量逆转录聚合酶链反应(qRT-PCR)和西方印迹分析获得的结果进行了比较。
最后,研究者使用来自接受曲妥珠单抗治疗的小鼠的尿液外泌体,通过SERS-深度学习分析监测了药物的疗效。研究表明,使用这种监测系统可以对任何抗药性问题做出积极反应。
文章还讨论了转移性乳腺癌的严重性,以及曲妥珠单抗治疗的重要性和局限性。此外,还介绍了外泌体作为癌症伴侣诊断的潜力,以及SERS技术在免疫分析中的应用。
研究者还详细描述了SERS标签的制备和表征,以及用于外泌体捕获的基质的制备。通过实验结果,证实了SERS-深度学习方法在监测曲妥珠单抗疗效方面的有效性,并讨论了该技术的潜在应用前景。
重点关注
用于监测乳腺癌患者曲妥珠单抗疗效的深度学习辅助表面增强拉曼光谱(SERS)免疫分析法。
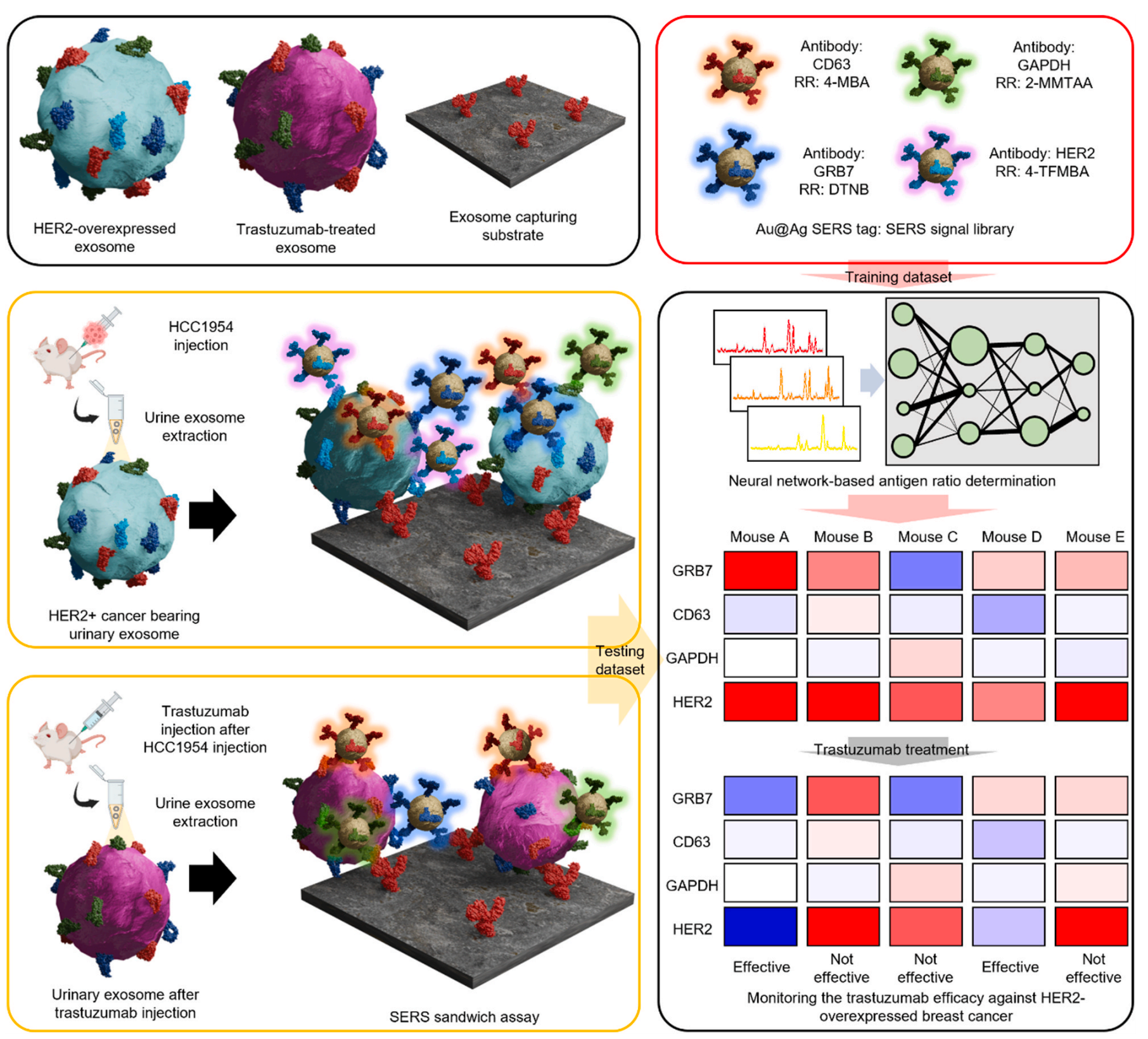
以下是对图1的分析:
-
整体流程:图1展示了从样品准备到深度学习分析的整个流程。首先,通过特定方法(如Exo-spin™ kit)从乳腺癌患者的尿液中提取外泌体。然后,这些外泌体被放置在预先准备好的、带有外泌体捕获抗体的基质上。
-
外泌体捕获:使用带有特定抗体(如CD63, CD9, 和 CD81)的基质来捕获外泌体,确保只有目标外泌体被固定在基质上。
-
SERS标签:将带有拉曼报告器的SERS标签与外泌体上的特定抗原(如HER2或GRB7)结合。这些SERS标签是具有表面等离子体共振效应的纳米粒子,能够显著增强拉曼散射信号。
-
信号收集:当SERS标签与外泌体结合后,使用拉曼光谱仪收集SERS信号。这些信号是外泌体上特定生物标志物的光学指纹。
-
深度学习分析:收集到的SERS信号被用作深度学习算法的训练和测试数据。深度学习模型通过学习这些信号的特征,能够区分和量化外泌体上的不同生物标志物。
-
结果解释:深度学习算法处理SERS信号后,提供了关于外泌体上生物标志物表达水平的定量信息。这些信息可以用来评估曲妥珠单抗的疗效,例如,通过监测HER2和GRB7的水平变化。
-
监测疗效:通过比较治疗前后的生物标志物水平变化,可以评估曲妥珠单抗对乳腺癌患者的效果。如果生物标志物水平显著下降,这可能表明药物有效。
-
反馈和调整治疗:根据监测结果,医生可以调整治疗方案,以更好地应对患者的个体反应和可能的抗药性问题。
图1的示意图是理解该研究方法的关键,它清晰地展示了从样品处理到最终分析的每个步骤,以及如何利用深度学习技术提高生物标志物检测的准确性和效率。
二、深度学习+病理组学,对用于临床试验的患者进行预筛选

文献概述
这篇文章描述了一种基于组织病理学图像的深度学习算法的开发和部署,该算法用于临床试验中的患者预筛选。
作者提出的算法能够识别肿瘤中的遗传变异,例如成纤维细胞生长因子受体(FGFR),这对于靶向治疗至关重要。然而,分子测试可能因时间和组织需求量而延迟患者护理。该AI算法的开发、验证和部署能够降低筛选成本并加快患者招募。
研究团队使用了3000多张来自晚期尿路上皮癌患者的H&E染色全切片图像来训练深度学习算法,优化其高灵敏度以避免排除符合试验条件的患者。
该算法在一个包含350名患者的数据集上进行了验证,实现了0.75的曲线下面积(AUC)、在88.7%的灵敏度下具有31.8%的特异性,并预计可以减少28.7%的分子测试。
研究团队成功地将该系统部署在一个非干预性研究中,涵盖了89个全球研究临床场所,并展示了其在优先分配/取消分配分子测试资源以及在药物开发和临床环境中提供重大成本节约方面的潜力。
文章还讨论了将这种基于H&E图像的FGFR+筛查设备部署在临床试验或临床实践中的潜在价值,包括通过避免对不太可能携带遗传突变的患者进行分子测试来降低成本,以及通过为医生提供快速、可行的见解来减少患者入组或接受适当靶向治疗的时间(例如,通过丰富可能为FGFR+的患者队列)。
此外,文章还提到了算法的开发、验证和部署的具体过程,包括使用公共数据库、商业来源和内部临床试验的数据集,以及算法在多个独立大规模数据集和前瞻性实时临床环境中的稳健验证。研究团队还展示了该技术如何通过减少筛查负担和提高试验效率来改善临床护理,并推动精准医疗的发展。
重点关注
研究设计、数据集使用以及从算法开发到验证和部署的工作流程。
以下是对图内容的分析:
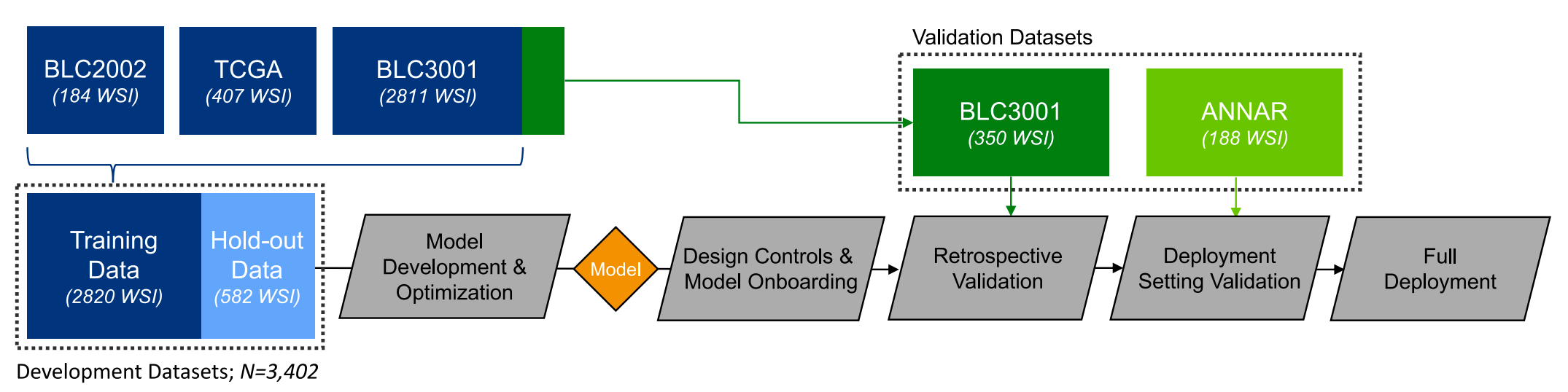
-
模型开发数据集:使用了来自三个不同队列的全切片图像(WSI)进行模型开发:
- 407张来自癌症基因组图谱(The Cancer Genome Atlas, TCGA)联盟。
- 3161张来自BLC3001(NCT03390504)的临床试验。
- 184张来自BLC2002(NCT03473743)的临床试验,这两个试验均与erdafitinib(一种药物)相关。
-
数据集的划分:从BLC3001队列中特别挑选了350个样本(150个FGFR阳性,200个FGFR阴性)用于模型的回顾性验证。这个子集被富集了FGFR阳性样本,以实现大约93%的统计功效。
-
独立验证数据集:此外,还从ANNAR(NCT03955913)试验中留出了188个样本,用于在算法打包成可部署设备并集成到部署平台后进行回顾性验证。
-
避免数据重复使用:确保没有患者样本同时在开发和回顾性验证中使用,以保证验证的独立性和结果的可靠性。
-
探索性分析:在工具部署后,为了评估算法在实体瘤上的性能,使用了来自不同肿瘤组织的361张切片组成的额外队列(即PAN-Tumor),这作为探索性分析。
-
算法部署:算法经过开发和优化后,被打包成一个部署设备,并集成到了部署平台上。
-
前瞻性应用:在ANNAR试验中,算法被前瞻性地应用于患者样本,以评估其在实际临床工作流程中的整合情况。
上图提供了一个清晰的视觉表示,说明了算法开发的严谨过程,包括数据的收集、模型训练、验证以及最终的部署。这个过程遵循了科学和临床验证的标准,确保了算法的可靠性和有效性。
三、AI+前瞻性队列,确定“杂合性丧失”是预测“垂体神经内分泌肿瘤”侵袭性、治疗抵抗性行为最有力的变量

文献概述
研究主要关注了垂体神经内分泌肿瘤(PitNETs)的基因组变异情况,尤其是那些表现出侵袭性、难以治疗的肿瘤。
研究涉及两组患者:一组是手术前同意进行基因组测序的前瞻性患者群体(66人),另一组是回顾性患者群体(26人),包括那些具有侵袭性/高风险PitNETs的患者。
研究发现,与良性肿瘤相比,侵袭性、难以治疗的PitNETs具有更高的突变负担和杂合性丧失(LOH)的比例。特别是在皮质激素细胞系中,12条特定染色体上的复发性染色体LOH模式与治疗抵抗性相关。此外,研究还发现TP53基因突变的肿瘤中有更高比例的LOH。
研究使用了机器学习方法,确定了LOH是预测侵袭性、治疗抵抗性行为的最有力的变量,其准确性(0.88,95% CI: 0.70–0.96)超过了最常见的基因水平变异TP53。这项研究表明,侵袭性、治疗抵抗性PitNETs的特点是显著的非整倍性,这是由广泛的染色体LOH造成的,尤其是在皮质激素肿瘤中。LOH以高准确性预测治疗抵抗性,并代表了这一定义不清的PitNETs类别的新型生物标志物。
论文还详细介绍了研究材料和方法,包括患者的纳入标准、免疫组化、基因组测序和分析、荧光原位杂交(FISH)实验以及机器学习的应用。研究结果部分详细描述了患者的人口统计学特征、基因组景观、复发性体细胞变异的基因水平、治疗抵抗性PitNETs中的复发性基因组广泛LOH以及随机森林建模基因组标记。
最后,论文讨论了研究结果的意义,强调了LOH作为预测PitNETs治疗抵抗性的潜力,并指出**需要进一步的前瞻性研究和长期临床随访来验证这些发现。
重点关注
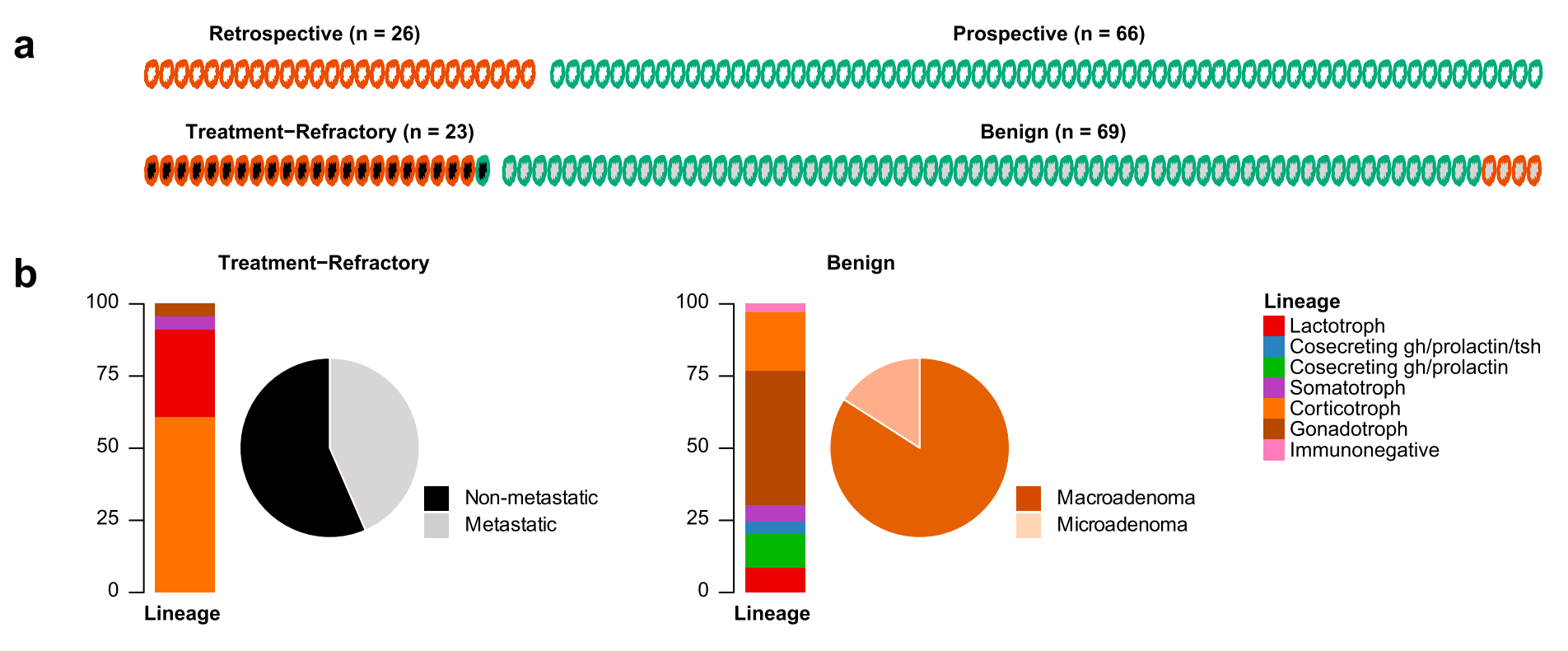
Figure 1 在文章中提供了有关侵袭性、治疗抵抗性(aggressive, treatment-refractory)和良性(benign)垂体神经内分泌肿瘤(PitNETs)的基因组变异和临床特征的比较分析。
以下是对该图的详细分析:
(a) 临床行为与患者群体的关系图
- 这部分提供了一个示意图,展示了回顾性群体(retrospective group)和前瞻性群体(prospective group)之间的关系,以及它们与临床行为的联系。
- 回顾性群体由接受了标准治疗(包括手术、传统药物治疗和初次放疗)后仍然进展的肿瘤患者组成。
- 前瞻性群体则是手术前同意参与测序研究的患者。
(b) 肿瘤亚型和转移状态的总结
- 这部分总结了治疗抵抗性肿瘤和良性肿瘤亚型,以及数据冻结时(data freeze)治疗抵抗性亚群的转移疾病状态。
- 治疗抵抗性肿瘤的亚型包括皮质激素细胞系(corticotroph)、催乳激素细胞系(lactotroph)等,并且指出了这些肿瘤的转移情况。
© 肿瘤驱动基因的Oncoprint图
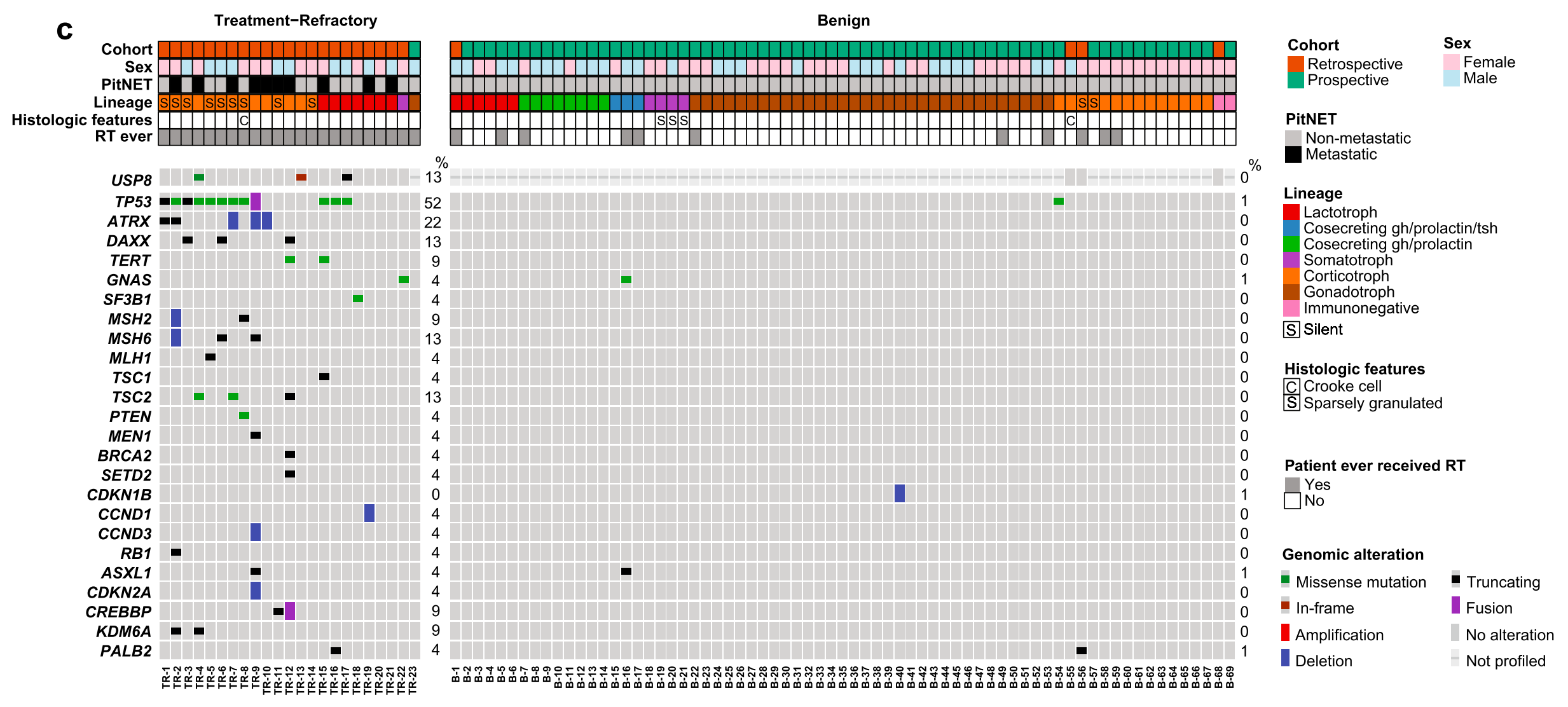
- Oncoprint图展示了治疗抵抗性(左侧,n=23)和良性(右侧,n=69)PitNETs中反复改变的驱动基因。
- 该图列出了患者人口统计学特征和临床病理学特征,然后是常见的基因变异(右侧显示每种临床类别的百分比)。
- 如果进行了全外显子重捕获测序(whole-exome recapture),则会报告USP8状态。
综合分析
- Figure 1 强调了基因组变异在PitNETs的侵袭性和治疗抵抗性中的重要性。
- 治疗抵抗性肿瘤与良性肿瘤相比,可能有更多的基因变异和不同的基因变异模式。
- 该图还突出了肿瘤异质性,即使是同一患者的多个肿瘤样本也可能展现出不同的基因变异组合。
- 此外,USP8基因的变异状态是特别关注的,因为它在PitNETs中是一个已知的复发性事件,可能与肿瘤的侵袭性有关。
总的来说,Figure 1 为理解PitNETs的基因组变异提供了一个全面的视角,并揭示了这些变异与肿瘤的临床行为之间的关系。
四、基于组织病理的深度学习分类器,预测高级别浆液性卵巢癌(HGSOC)患者对铂类化疗的反应

文献概述
这篇文章是关于一种新型的基于组织病理学图像的深度学习分类器(Pathologic Risk Classifier for High-Grade Serous Ovarian Cancer, PathoRiCH)的研究,该分类器用于预测高级别浆液性卵巢癌(HGSOC)患者对铂类化疗的反应。
以下是对文章内容的概括:
-
研究背景:卵巢癌是女性最常见的妇科恶性肿瘤之一,HGSOC是其中一种亚型,通常在诊断时已处于晚期,预后较差。铂类化疗是HGSOC的标准治疗,但患者对治疗的反应差异很大。目前没有可用的生物标志物能够快速预测对铂类治疗的反应。
-
PathoRiCH开发:研究者开发了PathoRiCH,这是一种基于组织病理图像的分类器,旨在预测HGSOC患者对铂类化疗的反应。该模型在
内部队列(n=394)上进行了训练,并在两个独立的外部队列(n=284和n=136)上进行了验证。 -
研究结果:PathoRiCH预测的有利反应组和不良反应组在所有三个队列中的
无铂间期(platinum-free intervals, PFI)有显著差异。结合PathoRiCH和分子生物标志物可以提供更强大的工具,用于HGSOC患者的分层。 -
模型解释:PathoRiCH的决策通过可视化和转录组分析进行了解释,增强了模型决策的可靠性。PathoRiCH显示出比当前分子生物标志物更好的预测性能。
-
研究意义:PathoRiCH为开发创新工具提供了坚实的基础,这些工具可以改变目前HGSOC的诊断流程。
-
方法和材料:研究分析了
814名HGSOC患者,包括三个队列:Yonsei Severance Hospital (SEV)队列、Cancer Genome Atlas Ovarian Cancer (TCGA)数据库队列和Samsung Medical Center (SMC)队列。研究使用了多种多实例学习(MIL)模型,并探索了不同的图像区域和放大倍数。 -
结论:PathoRiCH是一个有前景的工具,可以集成到HGSOC的初步病理诊断实践中,为临床医生选择初步和维持治疗、规划监测频率和指导患者参与临床试验提供指导。
文章还详细描述了研究的方法、队列特征、模型性能、以及PathoRiCH如何作为一个独立的预后因素。此外,还包括了对模型预测结果的可视化分析和转录组分析,以及对BRCA突变和同源重组缺陷(HRD)状态的预测。
重点关注
图1提供了研究中使用的多实例学习(MIL)模型的概述。
以下是对图1内容的分析:
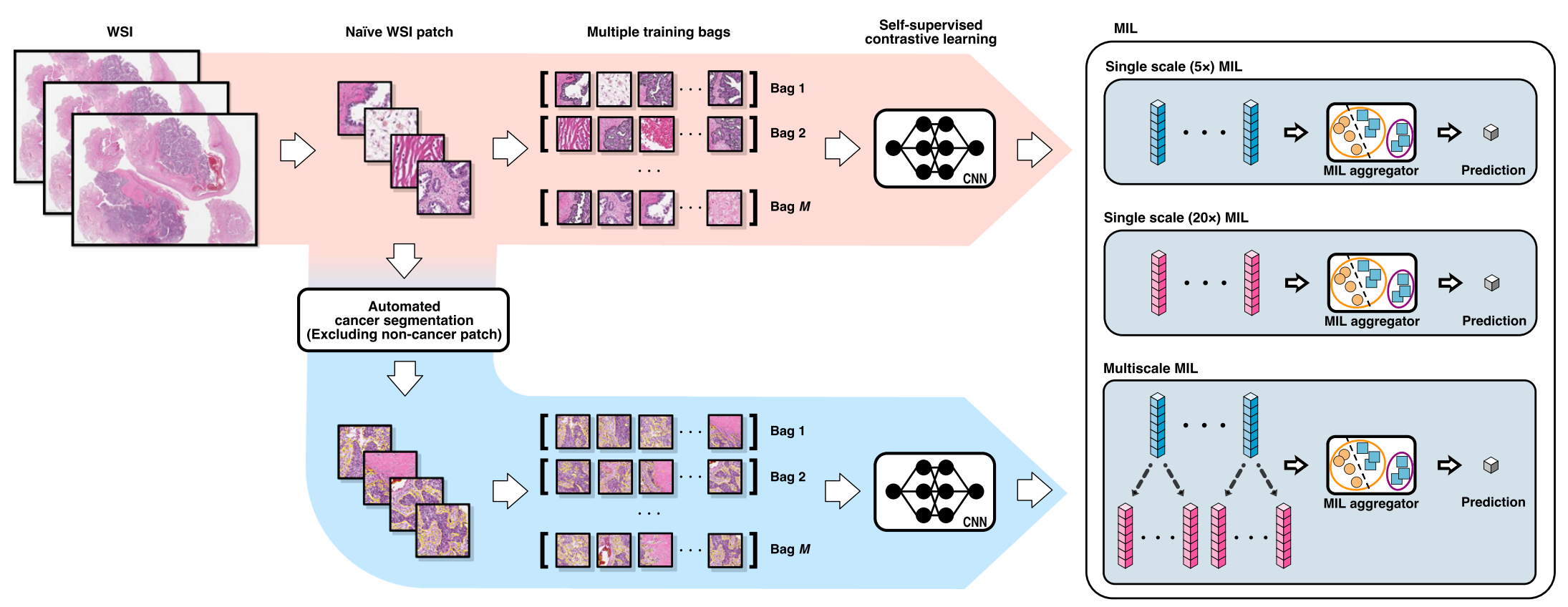
-
图像块提取:从全切片图像(WSIs)中提取了不同放大倍数(5倍和20倍)的图像块。这些图像块是构成WSIs的基本单元。
-
自动化癌症分割:使用自动化癌症分割模型处理这些图像块,目的是排除那些不含癌细胞的图像块。这一步骤是为了确保输入到后续模型的数据质量,只保留含有癌症特征的信息。
-
对比自监督学习算法:经过癌症分割的图像块被送入对比自监督学习算法(图中蓝箭头路径)。这种算法可以帮助模型学习图像特征的表示,而无需依赖于标记数据。
-
全组织图像块输入:作为另一种选择,所有图像块,包括不含癌细胞的图像块,也可以直接输入到自监督学习算法中,以包含WSIs中的所有组织(图中红箭头路径)。这种方法可能会捕获到癌症微环境的更多信息。
-
多实例学习方法:研究中使用了两种单尺度(5倍和20倍)和一种多尺度(5倍和20倍结合)的MIL方法。每种图像区域(全组织和癌症分割区域)都应用了这些方法,因此生成了六个不同的MIL模型。
-
特征金字塔:对于多尺度MIL,通过连接不同尺度WSIs的嵌入(embeddings),形成了特征金字塔。这些特征金字塔用于训练MIL聚合器,以整合不同尺度的信息,增强模型对图像特征的理解。
-
模型生成:通过上述步骤,生成了六种不同的MIL模型,每种模型都针对特定的图像区域和尺度设置进行了优化。
图1展示了一个复杂的深度学习流程,旨在通过不同的方法和尺度来提高模型对HGSOC组织病理图像的分析能力,从而更准确地预测患者对铂类化疗的反应。
五、机器学习构建预测模型,预测双重免疫阻断疗法治疗后血浆蛋白质组的变化

文献概述
这篇文章是一项关于
双重免疫阻断疗法(Dual Blocker Therapy, DBT)的研究,主要探讨了DBT治疗后血浆蛋白质组的变化,以及如何通过这些变化监测治疗反应。
研究涉及22位接受抗PD-1和抗CTLA-4 DBT治疗的患者的113个纵向血浆样本。
研究发现,在第一轮DBT治疗后,免疫反应和胆固醇代谢上调,特别是在疾病非进展组(Disease Nonprogressive, DNP)中,胆固醇代谢被激活。临床指标如前白蛋白(Prealbumin, PA)、游离三碘甲状腺原氨酸(Free Triiodothyronine, FT3)和三碘甲状腺原氨酸(Triiodothyronine, T3)与胆固醇代谢显著正相关。
研究还通过整合蛋白质组学和放射学方法,观察到DNP组中高密度脂蛋白的部分重塑,并识别了一个能反映DBT反应的候选生物标志物APOC3。此外,研究建立了一个机器学习模型来预测DBT反应,并通过独立队列验证了模型的性能,平衡准确率达到0.96。
文章还讨论了免疫检查点抑制剂(Immune Checkpoint Inhibitors, ICIs)在临床肿瘤治疗中的应用,以及DBT作为提高响应率、增加治愈率和延长反应持续时间的策略。研究强调了开发预测性生物标志物的重要性,以识别患者是否会对DBT产生反应,并提出了整合免疫组化、临床指标和基因表达特征来改进预测算法的潜力。
最后,文章提出了通过整合临床和蛋白质组数据,利用机器学习算法构建的预测模型,可以作为DBT反应的有力工具,并在独立队列中验证了其高准确性。研究结果不仅增进了对DBT治疗反应的生物学理解,而且为未来精准免疫治疗的临床试验提供了假设基础。
重点关注
队列设计和血浆蛋白组分析流程。
它分为两个部分:
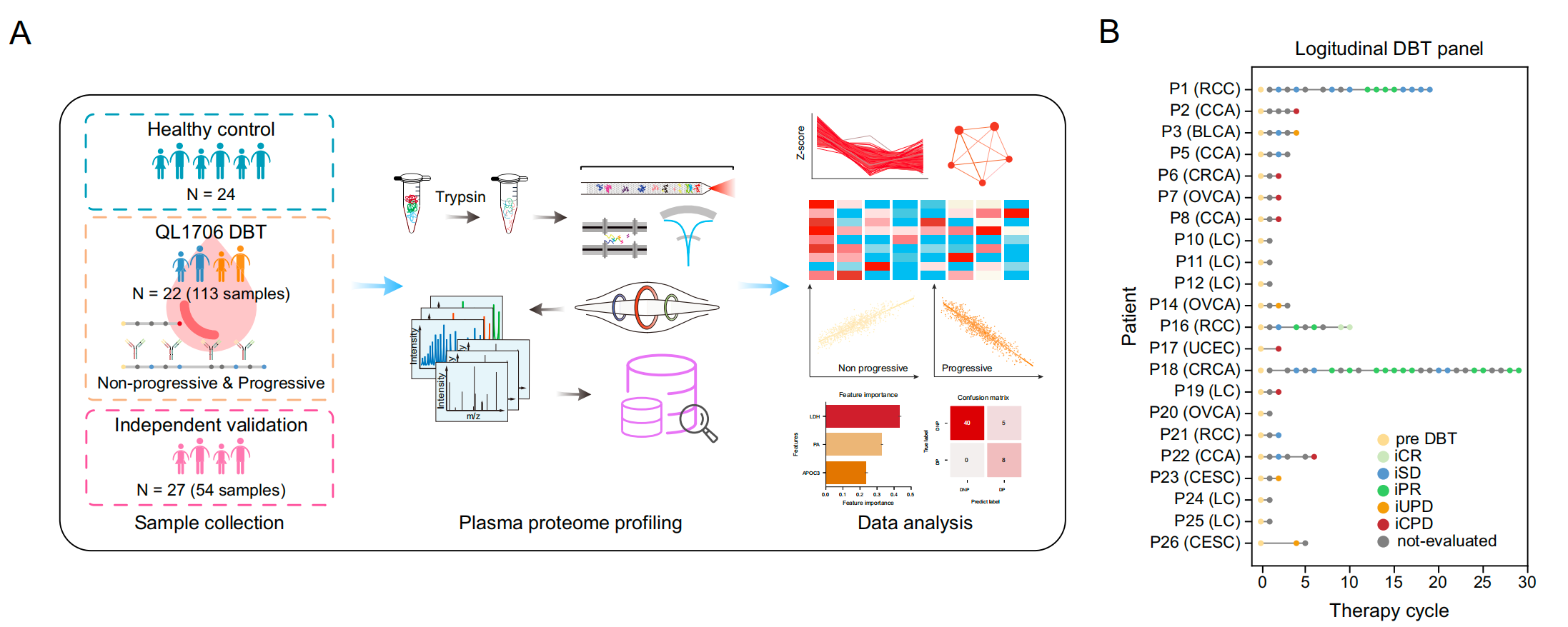
A部分:描述了双特异性抗体治疗(DBT)队列和健康对照队列的样本收集、处理、测序和数据分析的工作流程。这个流程说明了如何从患者那里获取血浆样本,随后进行样本的前处理,包括蛋白质的分离和鉴定,然后通过质谱等技术进行蛋白质组的分析,最终对数据进行综合分析以探究DBT的治疗效果。
B部分:展示了每位患者的纵向DBT治疗面板。图中的点代表患者的评估状态,使用不同的颜色来区分不同的治疗反应:
- 黄色代表治疗前(pre DBT)的状态。
- 浅绿色代表完全缓解(complete response, iCR)。
- 绿色代表部分缓解(partial response, iPR)。
- 蓝色代表疾病稳定(stable disease, iSD)。
- 粉红色代表未确认的疾病进展(unconfirmed progressive disease, iUPD)。
- 红色代表确认的疾病进展(confirmed progressive disease, iCPD)。
- 灰色代表未评估的状态(not-evaluated)。
此外,图中还包括了不同类型的癌症,例如肺癌(LC)、胆管癌(CCA)、肾细胞癌(RCC)、卵巢癌(OVCA)、结直肠癌(CRCA)、宫颈癌(CESC)、膀胱癌(BLCA)和子宫体子宫内膜癌(UCEC)。
源数据以源数据文件的形式提供,供读者进一步参考和分析。
六、乳腺癌、结直肠癌和胃癌患者的临床亚型与肠道菌群之间的关系

文献概述
这篇文章是一项关于肠道微生物群与乳腺癌(BC)、结直肠癌(CRC)和胃癌(GC)患者临床亚型相关性的研究。
研究团队使用机器学习方法分析了这些癌症患者的肠道微生物群,以识别它们共享的代谢途径及其在癌症发展中的重要性。
基于与肠道微生物群相关的代谢途径、人类基因表达谱和患者预后数据,研究者建立了一个新的乳腺癌亚型系统,并识别出了一个称为“具有挑战性的乳腺癌”(challenging BC)的亚型。这种亚型的肿瘤比其他亚型具有更多的基因突变和更复杂的免疫环境。
研究者还提出了一个评分指数,用于深入分析,并发现它与患者预后显著负相关。特别是,TPK1-FOXP3介导的Hedgehog信号通路和TPK1-ITGAE介导的mTOR信号通路的激活与高评分的“具有挑战性的乳腺癌”患者的不良预后相关,这一点在患者衍生的异种移植(PDX)模型中得到了验证。
此外,研究者的亚型系统和评分指数是当前新辅助治疗方案反应的有效预测因子,评分指数与治疗效果和免疫细胞数量显著负相关。因此,这些发现为预测“具有挑战性的乳腺癌”患者的分子特征和治疗反应提供了宝贵的见解。
研究还探讨了肠道微生物群在不同癌症中的不同微生物组成,以及它们如何通过共同的代谢产物和途径影响各种疾病。研究使用了16S rRNA测序数据,并通过Wilcoxon检验和随机森林模型识别了正常组和癌症组之间显著不同的细菌属。通过自组织图(SOM)方法对患者进行聚类,发现了与不同癌症类型相关的肠道微生物群特征。
此外,研究还使用了PICRUSt软件和ANOVA分析确定了在不同亚型中显著不同的KEGG途径,特别关注了三种癌症类型共有的36条代谢途径。
文章强调了肠道微生物群与乳腺癌之间的强关联,并指出微生物失衡可能影响各种乳腺癌亚型的发生率。研究结果表明,肠道微生物群可以影响雌激素和孕酮的代谢,从而不同程度地影响激素受体阳性和激素受体阴性乳腺癌的发生。研究者呼吁进一步研究改善肠道微生物群组成的机制,以改善乳腺癌患者的生存结果和优化抗癌疗法。
重点关注
基于机器学习对乳腺癌(BC)、结直肠癌(CRC)和胃癌(GC)患者的肠道微生物群特征和聚类分析的结果。
以下是对图中各部分的详细分析:
(A) 流程图:描述了肠道微生物群分析的步骤,从样本收集到数据分析和结果解释的整个流程。

(B-D) 不同属的重要性:展示了在CRC、GC和BC患者中显著不同的细菌属的重要性。图中可能通过条形图或点图来表示这些属在癌症中的上调(Up)和下调(Down)情况,即在癌症患者中相对于正常样本显著增加或减少的基因。
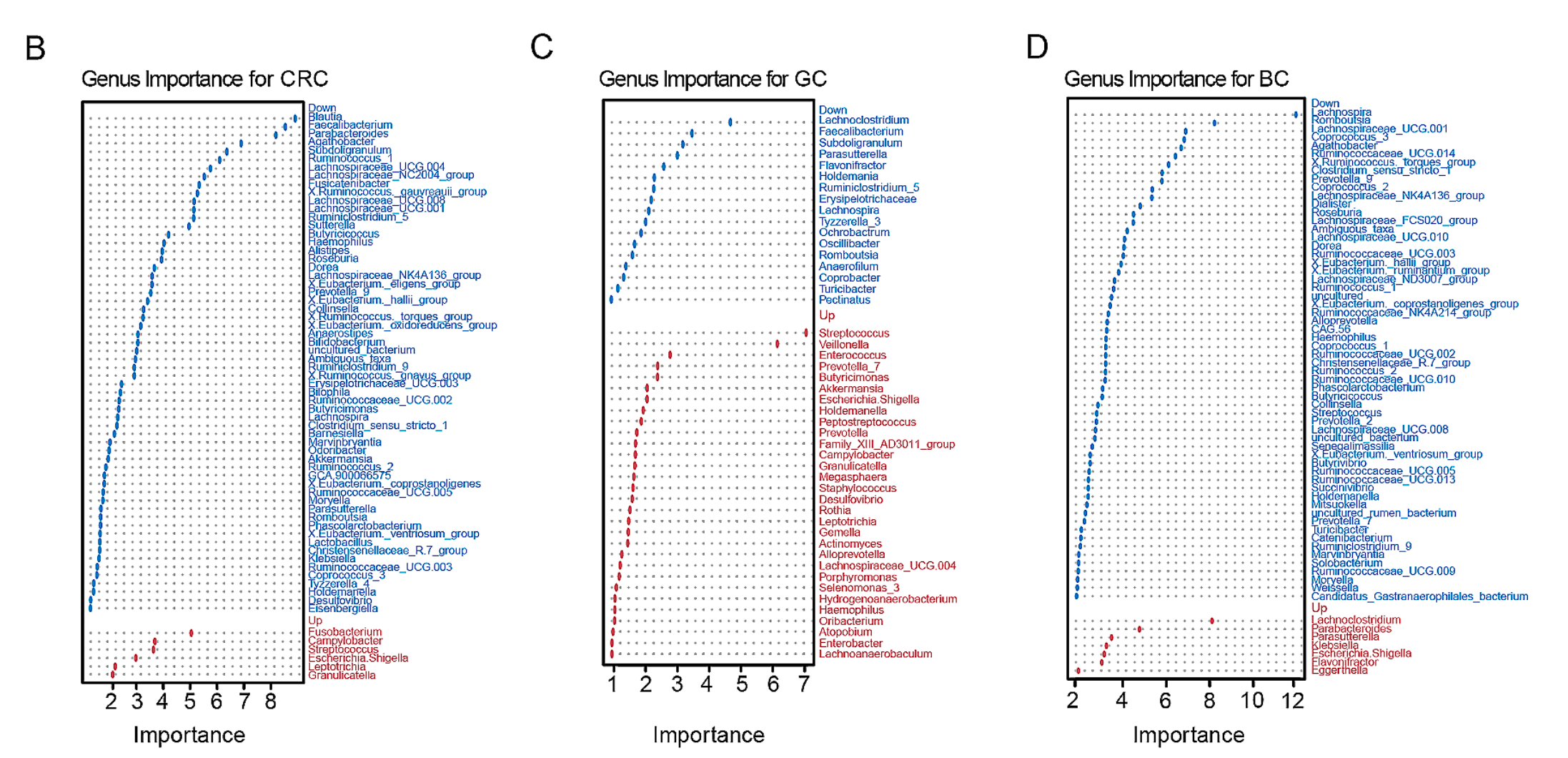
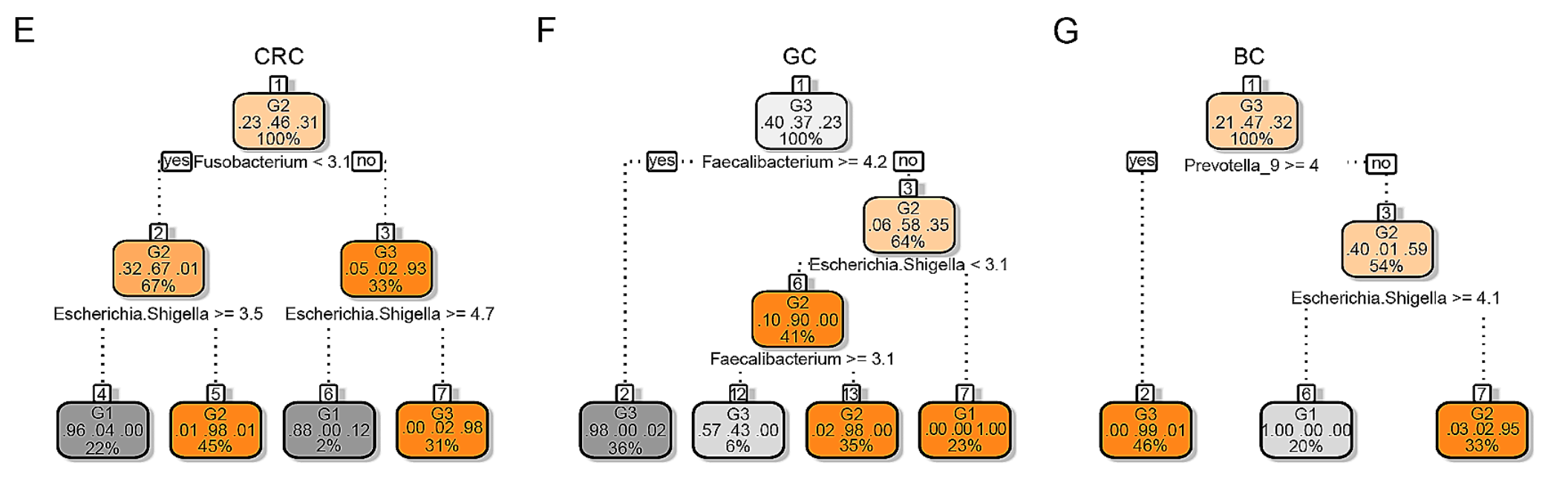
(E-G) 样本聚类:使用自组织图(SOM)方法对三种癌症类型的样本进行了聚类,将它们分为G1、G2和G3三个亚组。每种癌症类型都有其特定的关键属(key genera),例如:
- CRC患者的Fusobacterium和Escherichia Shigella。
- GC患者的Faecalibacterium和Escherichia Shigella。
- BC患者的Prevotella_9和Escherichia Shigella,这些属在各自癌症的聚类中起到了标记作用。
(H) Venn图:展示了三种癌症之间显著不同的细菌属的重叠情况。图中表明,三种癌症之间在细菌属方面的重叠并不广泛,几乎有一半的属是每种癌症独有的,这可能与肿瘤特异性有关。
(I) 热图:展示了三种癌症中不同聚类亚组的微生物功能的差异性富集情况。热图可能通过颜色的深浅来表示代谢途径在不同聚类中的富集程度。图中指出,BC队列中的微生物功能与CRC和GC队列中的相似,表明不同癌症类型之间存在一些共享的微生物代谢途径。

总体而言,Fig. 1 强调了肠道微生物群在不同癌症中的特定变化,并揭示了它们在癌症发展中的潜在作用,特别是在代谢途径方面的共享性。这些发现为理解肠道微生物群如何影响癌症的发生和发展提供了重要信息,并可能有助于开发新的癌症治疗策略。
这篇关于人工智能在【肿瘤生物标志物】领域的最新研究进展|顶刊速递·24-06-08的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







