本文主要是介绍19.配置glance使用ceph作为后端存储,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ceph作为后端存储:
ceph提供三种存储:
1.对象存储
2.文件存储
3.块存储
框架图:
元数据服务器 MD/MDS
集群监视器MON
对象存储服务器OSD

实际部署的时候,新建了node1(RHEL7.1)和node2(RHEL7.1),其中node1作为MD/MON/OSD1,node2作为OSD2
更新hosts文件:


配置下yum源:
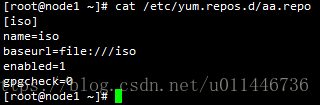

上传软件包ceph软件包:


安装并部署ceph:
# yum install /ceph/* -y


创建步骤:
所有的操作都是在node1上配置,其中node1作为MD/MON/OSD1,node2作为OSD2
1.随意创建一个目录
mkdir xx ; cd xx
2.创建一个ceph集群
ceph-deploy new node1
3.修改ceph配置的配置ceph.conf
osd_pool_default_size = 2
osd_pool_default_min_size = 1
4.创建mon
ceph-deploy mon create-initial
如果配置文件修改了,想重新初始化的话:
ceph-deploy --overwrite-conf mon create-initial
5.准备OSD
ceph-deploy osd prepare node1:/yy node2:/xx
ceph-deploy osd activate node1:/yy node2:/xx
6.创建MD
ceph-deploy mds create node1
7.把密钥拷贝到所有的节点上去
ceph-deploy admin node1 node2
具体步骤如下:
1.随意创建一个目录
mkdir xx ; cd xx
2.创建一个ceph集群
ceph-deploy new node1

3.修改ceph配置的配置ceph.conf
osd_pool_default_size = 2
osd_pool_default_min_size = 1
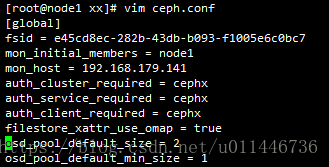
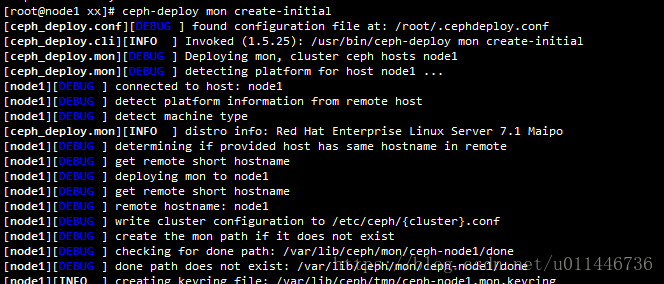
4.创建mon
ceph-deploy mon create-initial
如果配置文件修改了,想重新初始化的话:
ceph-deploy --overwrite-conf mon create-initial
检查集群:

这篇关于19.配置glance使用ceph作为后端存储的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





