本文主要是介绍C语言过度C++语法补充(面向对象之前语法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. C++相较于C语言新增的语法
0. C++ 中的输入输出
1. 命名空间
1. 我们如何定义一个命名空间?
2. 如何使用一个命名空间
3. 命名空间中可以定义什么?
4. 在 相同或者不同 的文件中如果出现 同名的命名空间 会如何?
5. 总结~~撒花~~
2. 缺省参数(默认参数)
1. 全缺省
2. 半缺省
3. 用途
3. 函数重载
1. 什么是函数重载
2. 为什么C语言不支持函数重载,而C++支持函数重载
4. 引用
1. 什么是引用,如何定义一个引用
2. 权限的放大和缩小?
2. C++相较于C语言有所变化的几个点
1. "auto" 关键字
2. "NULL" 与 "nullptr"
3. 内联函数 "inline"
4. 结构体
3. 总结
前言:
各位小伙伴在学完C语言之后,向C++进军的话,有一些需要补充的小知识点,也是C++祖师爷对C语言的一下小不满,这篇文章就带大家这这些琐碎的知识点一网打尽~~!!!
今天是2024年6月7日,顺便说一句:高考加油,奥里给!!!
1. C++相较于C语言新增的语法
0. C++ 中的输入输出
有C语言的基础,我们直接来看C++的代码:

这里的 using namespace std; 我们先不关注,在下一部分 “命名空间” 中我们再细说~!
C++ 中的 cin 对应 C语言中的 scanf() ,但是不再使用 & 符号,称为“流提取”
C++ 中的 cout 对应 C语言中的 printf() ,并且我们不再需要关注数据的类型, 称为 “流插入”
这里 cin、cout 中的 c 代表的是 console 控制台
这里的 endl 指的是 end + line 有换行的含义
1. 命名空间
相较于C语言,C++中首次引入了命名空间的概念,其主要的目的是解决变量/结构/函数命名冲突的问题~!
这里为大家举一个例子:
下面这样的代码,当我们运行的时候,就会报这样的错误,因为在<stdlib.h>中 rand 是被定义为产生随机值的函数的,所以我们这样使用就报错了。

那么,为了解决这样类似的命名冲突的问题,C++中就有了命名空间,那么命名空间是如何使用的呢?
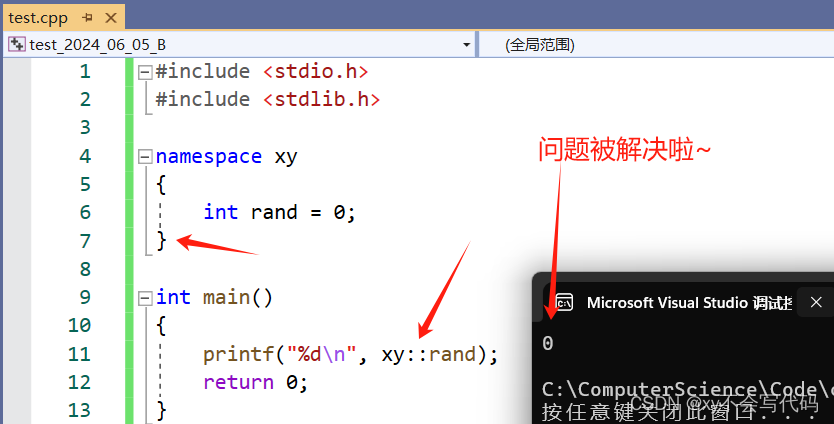
首先,我们能看到我们前面的关于命名冲突的问题被解决啦~,之后我们看图上的两个另外的红色箭头!
1. 我们如何定义一个命名空间?
namespace 命名空间的名称
{// 命名空间的内容
}
如:
namespace xy
{int rand = 0;
}值得注意的是:相较于C语言的自定义类型(结构体、枚举、联合体(共用体))来说,命名空间这里的 右边大括号 后边是没有 ";" 分号的~!
2. 如何使用一个命名空间
我们看到我们上图(不是代码框)中 中间向左下的那个红色箭头,使用 :: 来访问命名空间,这就是关于命名空间最基础的使用方法,直接访问指定命名空间内的指定成员,但是命名空间不仅仅可以这样!
结合 “C++中的输入输出”中的 using namespace std; 我们就能看出命名空间的第二种用法,就是完全展开命名空间,这里的展开命名空间与头文件的展开有所不同:
头文件的展开是将头文件内的内容全部拷贝到展开头文件的地方,但是命名空间的展开往往是一种声明,怎么理解呢?
我们知道 C语言 编译器的默认访问顺序是:
先访问局部作用域,再访问全局作用域。
在C++中,如果没有完全展开命名空间,编译器的默认访问顺序是和C语言的完全一致的(为了兼容C语言),但是如果完全展开了命名空间,就会在访问完全局作用域之后,去访问完全展开的命名空间。
这里还有一个 小Tips, 就是 如果我们同时展开多个命名空间,如果展开的多个命名空间中有相同的 名称,也会有重定义的错误!
还有一种命名空间的使用方法,就是鉴于上面的这个tips的风险,我们可以指定展开命名空间中的成员。我们直接上代码解释:
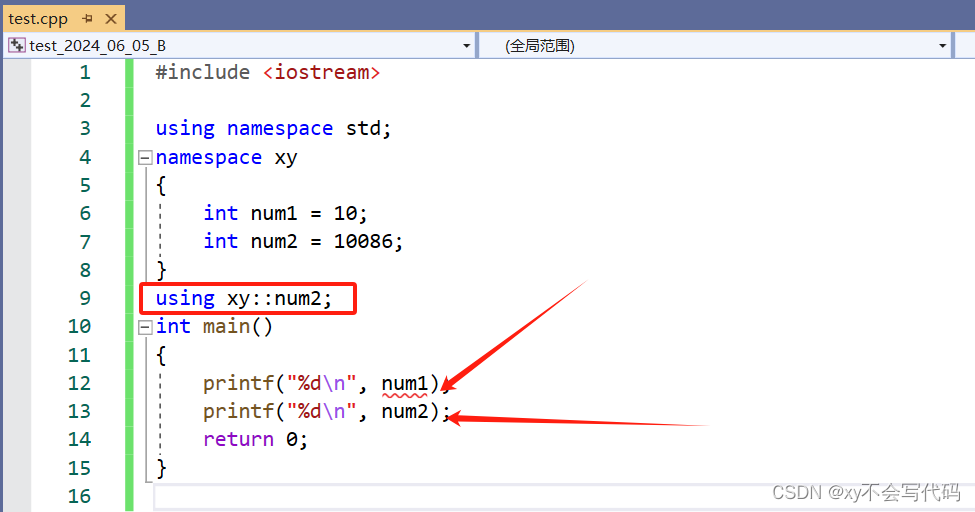
我们可以看到,当我们展开了 命名空间 xy 中的 num2 之后,编译器就认识 num2, 但是不认识num1 。这就是命名空间的最后一种使用方法啦~~
3. 命名空间中可以定义什么?
我们知道了,命名空间的目的和命名空间的定义和使用,那我们再来看看,命名空间中可以定义什么呢?

我们可以看到,命名空间中 几乎就是一个加了一点小限制的(需要一些声明)全局域,可以定义 变量、自定义类型、函数、甚至是命名空间!
这里我们再说一个编译器比较智能的地方,就是假如说,我们指定访问了A命名空间中的一个结构体来创建了一个变量,那么我们在后期使用这个变量的相关操作函数的时候,编译器会默认去找这个变量所在命名空间中的方法来操作这个变量,即使在全局域有相同名称,相同参数的函数!
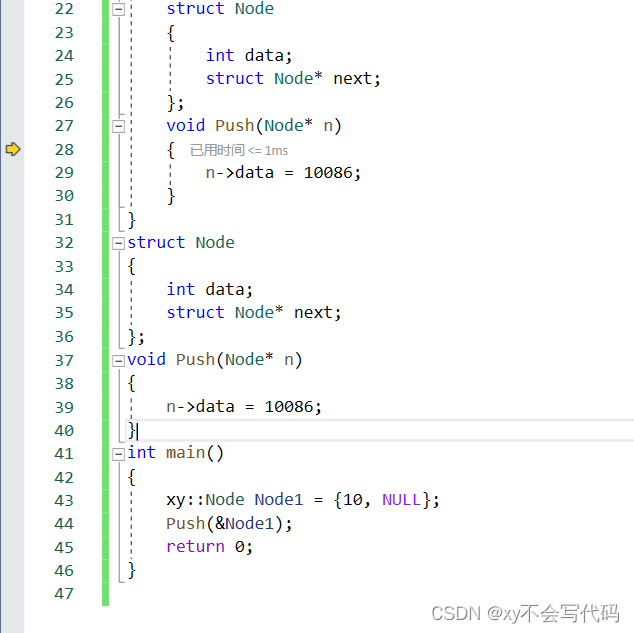
如图,我们在调用 Push函数的时候,并没有指定调用 xy 命名空间中的 Push函数,理论上他应该是去全局域找Push函数,但是我们在调试的时候发现,他是去调用了 xy 命名空间中的 Push函数。
4. 在 相同或者不同 的文件中如果出现 同名的命名空间 会如何?
这里我们 就直接说答案叭!对于 相同或者不同 的文件中如果出现 同名的命名空间 编译器就像他们自行和并,合成一个融合了多个相同命名空间的一个命名空间。
5. 总结~~撒花~~
关于命名空间的内容呢,到这里就结束啦,我们可以总结一下,使用命名空间时候的访问顺序,这里为大家将一个小故事,以便于大家理解:
小明的妈妈在做饭的时候,发现家里没有葱了,让小明去地里搞点葱回来。正常情况下,小明应该是先去自己家的地里,看没有葱,如果自己家里没有,再去看村子里的野外地里有没有葱,正常是不会去隔壁王大爷家里搞点葱叭?这就对应了,如果我们不声明展开命名空间,是访问不到命名空间内的成员的。如果王大爷提前说了,“小明,下次吃菜,可以来王大爷家的地里搞点吃”,这样我们就可以去王大爷家的地里拿到葱,同样也可以拿到其他蔬菜。这就对应了,我们就命名空间完全展开,如果王大爷告诉小明妈妈,下次吃葱直接来我们家地里搞,这就对应了,直接访问指定命名空间内的指定成员,还有一种情况就说,王大爷说“乡亲们,我们家里的白菜比较多,你们想吃可以来我们家地里搞点吃”,这就对应了命名空间展开特定的成员。
好啦,命名空间的内容其实也是比较多的,但是并不难,大家可以在学习的过程中,慢慢理解,妈慢慢体会~!
2. 缺省参数(默认参数)
1. 全缺省
在C++中,函数可以在定义的时候,我们可以在函数形参位置指定参数的值,这样在函数调用的时候就可以直接调用,或者传入参数调用。

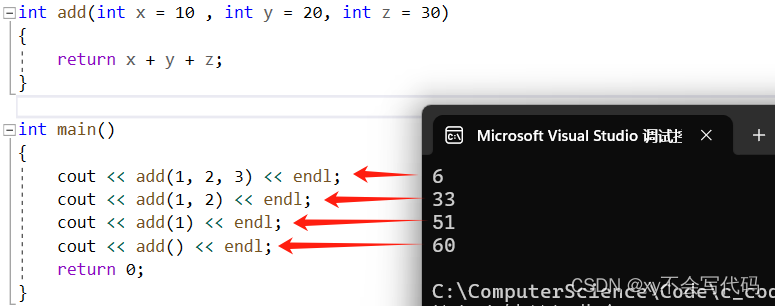
注意点:缺省参数,不能同时写在函数定义中和函数声明中!因为要避免出现两个地方默认值不同的情况,就算两个地方写的默认参数是一样的也不可以~~!
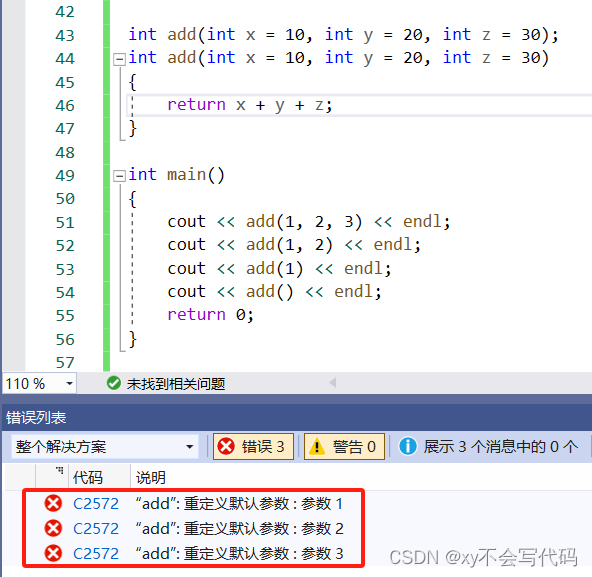
2. 半缺省
我们可以之给定其中一部分形式参数的默认值,但是这里有一个规定,就是缺省必须从右向左依此缺省
因为要 避免编译器不知道将那个实参传给对应的形参。给大家看几种情况。
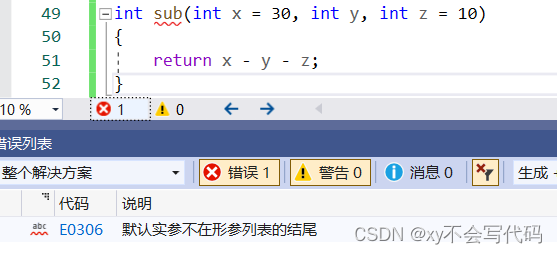
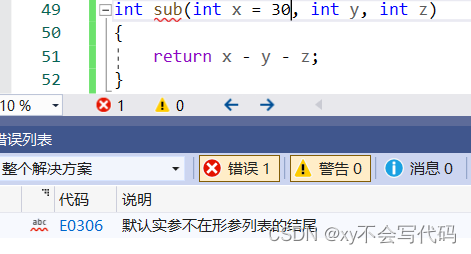

必须从右向左依此缺省!
3. 用途
我们回忆,我们使用C语言实现顺序表的时候,是不是不能灵活的控制,开多大的空间,通常是给一个默认值,在此基础上二倍增长,在这种情况下(知道变量大小,或者不知道变量大小的情况同时存在)缺省参数就能用到了:可以作为malloc时候的大小,如果知道多少就传入,不知道就不传入,使用默认参数。
3. 函数重载
1. 什么是函数重载
函数重载,简单的说,就是函数(方法)名相同,参数列表不同(参数的:个数、类型、顺序),几个相同名称,不同参数列表的函数,相互称为:重载函数。
这里有一个注意点:函数重载一定是发生在同一作用域,如果不是同一作用域,是用不到函数重载的~!

在这里也有一个要注意的点:“返回值不影响重载”!
注意点:

在这里呢,Add(1.0, 2.0) ,由于 1.0和2.0字面量的默认类型都是double,我们没有提供与它对应的函数,所以他会发生隐式类型转换,它即可以转化为int类型,又可以转化为float类型,编译器不知道调用哪一个?所以就出现了歧义----多个重载函数。
这里说一个问题?如果是,我们将两个命名空间同时展开,在这两个命名空间中,有一个函数名相同,参数列表不同的函数,他们算不算函数重载?
答案是:不算~~!,因为总归不是同一作用域,按照上文在命名空间中的总结来说,展开了命名空间,不是说,王大爷家的菜地就变成村子里的野地了,只是有了一个声明。所有对于上面的情况,如果调用那个两个命名空间都有的函数,结果只能是:编译错误,歧义~!
2. 为什么C语言不支持函数重载,而C++支持函数重载
我们知道C语言,C++在编译的时候,都是经历了四个步骤:
预处理 -- 编译 -- 汇编 -- 链接 这四个步骤我们在这里就不详细说了,后期专门一篇文章来说~
在多个文件中函数相互调用,都是在链接拿函数名时候去找的,在C语言编译器上,是不会对函数名做一些修饰的,在C++中是是会对函数名做一些修饰的,比如说在函数名的前面加上函数名的字符个数,在函数名的后面加上函数的参数列表的简称。
知道了这些,我们就可以反推出为什么函数的返回值不能作为函数重载了~!,因为函数是可以直接调用,比如说,一个就返回值的函数,我们可以不接受他的返回值,直接去调用它,这样编译器就没有办法去区分调用那个函数了!如下图:
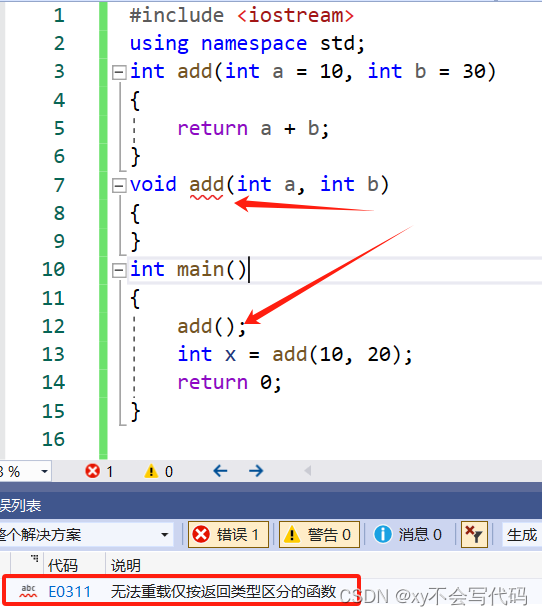
你能想到 第一个 add() 函数去调用那个吗?
4. 引用
1. 什么是引用,如何定义一个引用
在C++中,引入了引用的概念,他的作用是 给一个已有的变量起别名,比如:李逵又叫黑旋风,对于变量来说,无论是变量本身还是引用,他们操作的都是同一块内存空间,也就是说他们的内存地址相同的,并且:同一个变量可以有多个别名。

注意点:引用在定义的时候必须要初始化,并且在之后不能再引用其他同类型的变量。
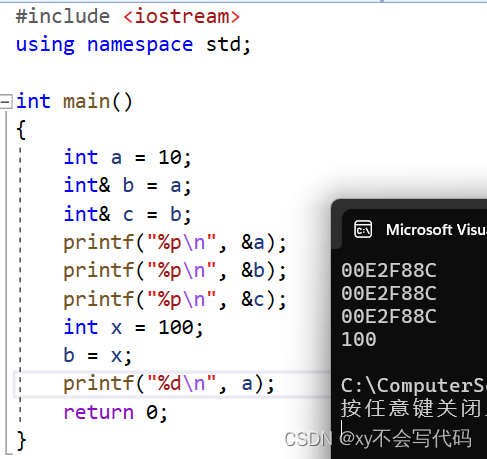
在之后呢,所有 使用引用的地方,我们都可以将他等价替换成该引用 引用的变量~!
在这里,我们再来看看,引用的另一个作用:作为函数参数。

在C语言中,我们如果想要使用函数交换两个变量,我们就要使用到指针,因为函数栈帧的原因,形参只是实参的一份临时拷贝,所以修改形参不会改变实参,所以我们要使用指针,但是在C++中就可以使用 引用,来交换两个变量!
2. 权限的放大和缩小?
我们在前文中知道了:引用是给已有的变量起别名,那么现在就会有一些问题:

如果说我们现在定义了一个变量,他的类型是 const int,现在我们搞一个 int 类型的引用去引用这个变量,我们原始的变量是const 的 ,是不能修改的,但是我们现在用一个 int 类型的引用,引用这个变量,反而让他可以改了,这样 是不是 有一个 权限的放大。这样是不被允许的!
权限的平移,和权限的缩小 都是可以的比如:
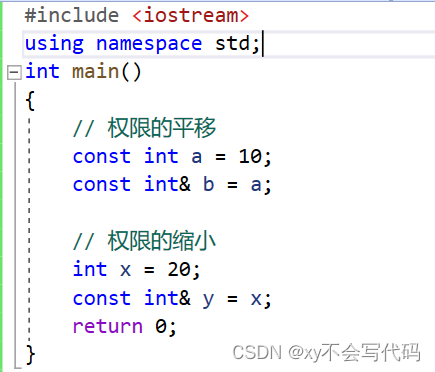
这里有一个注意点:
普通的变量的赋值是不涉及权限的放大和缩小,只有指针和引用是设计权限的放大和缩小的!
2. C++相较于C语言有所变化的几个点
1. "auto" 关键字
在C语言中,auto 关键字是默认省略的,在我们定义的每一个变量之前,都是有一个auto的,但是在C++中,auto 关键字 有自动推导变量类型的作用,往往是使用在迭代器中,由于迭代器类型比较长,写起来有点费劲,就可以使用 auto 关键字来自动推导。
2. "NULL" 与 "nullptr"
在C语言中,NULL是被宏定义为 一个将0强制转换为void*类型的一个泛型指针,但是在C++中,NULL不再是指针类型,而是被定义为 0 ,而通常是使用nullptr来代表空指针!如下图:
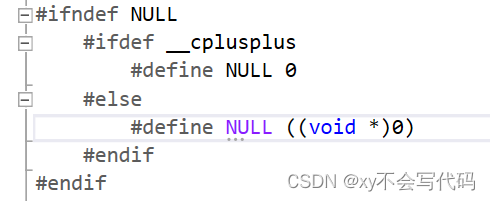
C++中使用 NULL 也是可以的,但是在C++11 之后,还是更建议使用 nullptr 来代表空指针。
3. 内联函数 "inline"
在C语言和C++中,inline 关键字 都是定义内联函数,但是呢这都是对编译器的建议,建议将一些比较简短的函数,直接展开,减少函数栈帧开辟和销毁的消耗,但是实际还是要看编译器自己的处理。
C语言与C++不同的是,C语言,是要自己将 inline 写出来才有效,但是在C++中,所有的函数前面都隐式的添加了 inline 关键字,就如同上文中 C语言中的 aotu关键字一样~!
4. 结构体
结构体,因为涉及到C++中的面向对象,我们这里就先不细说了,我们就提一下:
1. C语言中,结构体中是不能定义函数的,C++中,结构体中是可以定义函数的。
2. 由于 第一点 就涉及到了 C++中结构体的大小了
目前就说这些,详细的以后在C++面向对象的文章中再说~~!
3. 总结
C语言过度C++,面向对象之前的语法总体上来说是不太难的,但是需要我们多多练习,慢慢体会~~

祖师爷保佑~~,大家写的代码都没BUG!!!
这篇关于C语言过度C++语法补充(面向对象之前语法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






