本文主要是介绍Hazelcast--Map数据类型中文版之前篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
4.1.Map
4.1.1.概要:
Hazelcast Map(即IMap)继承java.util.Map引用java.util.concurrent.ConcurrentMap接口.简单来说,它是java Map的一种分布式实现.
IMap的一般操作,比如说进行读/写时,与我们常见的map的读写方法一样,IMap定义的读/写方法也为Get和Put方法.
分布式的Map是怎样工作的呢?
Hazelcast会将你的Map键值对集合,差不多平均的分离至所有的Hazelcast的成员中.每个成员携带近似"(1/n * total-data) + backups",n为cluster中的节点数量.
为了帮助大家更好的理解,接下来我们创建一个Hazelcast 实例(即节点)然后创建一个名为Capitals的map,键值对参考以下代码:
public class FillMapMember {public static void main( String[] args ) { HazelcastInstance hzInstance = Hazelcast.newHazelcastInstance();Map<String, String> capitalcities = hzInstance.getMap( "capitals" ); capitalcities.put( "1", "Tokyo" );capitalcities.put( "2", "Paris” );capitalcities.put( "3", "Washington" );capitalcities.put( "4", "Ankara" );capitalcities.put( "5", "Brussels" );capitalcities.put( "6", "Amsterdam" );capitalcities.put( "7", "New Delhi" );capitalcities.put( "8", "London" );capitalcities.put( "9", "Berlin" );capitalcities.put( "10", "Oslo" );capitalcities.put( "11", "Moscow" );......capitalcities.put( "120", "Stockholm" )}
}当你运行这段代码的时候,将会创建一个节点并且在此节点上创建一个map,此节点将被添加至节点集合,该集合为分布式的.
下面这幅图可以很形象的说明此段代码的运行效果,现在我们有了一个独立的cluster节点啦!!
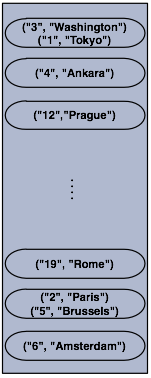
 NOTE: Please note that some of the partitions will not contain any data entries since we only have 120 objects and the partition count is 271 by default. This count is configurable and can be changed using the system property
NOTE: Please note that some of the partitions will not contain any data entries since we only have 120 objects and the partition count is 271 by default. This count is configurable and can be changed using the system property hazelcast.partition.count. Please see Advanced Configuration Properties.
接下来我们创建第二个cluster节点.此处备份的数据也会被创建.请注意关于备份这部分知识我们将在Hazelcast Overview这节详细讲解.
好啦话不多说,我们运行刚才的代码进行第二个节点的创建吧.下面是两个节点的示意图,详细的展示了数据与备份数据存储的方式,显而易见备份数据是分布式的喔~
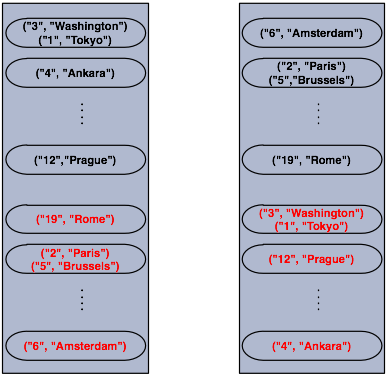
如你所见,当一个新成员加入cluster中时,它将会承担部分数据的备份责任.最终,它将携带大约"(1/n * total-data) + backups"的备份数据,从而减少其他节点的负载.
HazelcastInstance::getMap实际上将会返回一个继承自java.util.concurrent.ConcurrentMap 的com.hazelcast.core.IMap实例.
有些方法像ConcurrentMap.putIfAbsent(key,value)、ConcurrentMap.replace(key,value),可以用于分布式map中,下面我们看一个例子:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import java.util.concurrent.ConcurrentMap;HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();Customer getCustomer( String id ) {ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );Customer customer = customers.get( id );if (customer == null) {customer = new Customer( id );customer = customers.putIfAbsent( id, customer );}return customer;
} public boolean updateCustomer( Customer customer ) {ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );return ( customers.replace( customer.getId(), customer ) != null );
}public boolean removeCustomer( Customer customer ) {ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap( "customers" );return customers.remove( customer.getId(), customer );
} 所有ConcurrentMap的操作,比如说put和remove操作,在key被其他本地或远端JVM线程锁住时都将进行等待,可是它们终将返回成功. ConcurrentMap操作永远不会抛出java.util.ConcurrentModificationException.
Also see:
-
Data Affinity.
-
Map Configuration with wildcards.
4.1.2.Map的备份
Hazelcast将map分布式的存储于对个JVM上(cluster members).每个JVM将会hold住一部分数据,当JVM发生崩溃时,数据将不会丢失.
分布式的Map在一个成员崩溃时,拥有一个该成员数据的备份,从而,此次崩溃将不会对数据产生丢失.备份操作是同步的,当map.put(key, value)操作返回时,它将保证此次操作会在另一个节点上进行重复操作,从而在另一个节点上进行数据的备份.对于读取来说,它将保证 map.get(key)返回最新的键值对.请记住分布式map的键值对是严格一致地.
同步备份
为了保证数据安全,Hazelcast允许你指定备份的数量.当你指定数量后JVM将数据拷贝至其他的JVM,具体配置备份数量请使用backup-count标签.
<hazelcast><map name="default"><backup-count>1</backup-count></map>
</hazelcast>
当数量是1时,意味着有它的数据备份在另一个cluster节点上.当设置为2时,它的数据备份在另两个节点上.当然它也可以设置为0,当设置为0时,将不会备份数据.
比如说,当性能要求比数据备份要求高时.最大备份数量上限是6.
Hazelcast支持同步备份也支持异步备份.缺省的备份方式为同步备份方式. (configured with backup-count).在这种情况下,备份操作将执行阻塞操作,即只有当上一个备份操作返回成功信息时才会执行下一个备份操作(此处删除也同样适用).因此,在put操作时,你要确认你的备份已经被更新.当然,同步备份操作的阻塞问题,将带来一些潜在的问题及消耗.
异步备份
异步备份,从另一方面来说,它将不会进行阻塞操作.异步备份将不会要求返回确认信息(备份操作将在一些时间点执行).异步备份的配置,请使用async-backup-count标签.
<hazelcast><map name="default"><backup-count>0</backup-count><async-backup-count>1</async-backup-count></map>
</hazelcast>
NOTE: Backups increase memory usage since they are also kept in memory. So for every backup, you double the original memory consumption.
NOTE: A map can have both sync and aysnc backups at the same time.
备份数据的读取
缺省情况下,Hazelcast拥有一份同步备份数据.如果备份数量大于1时每个成员将保存本身的键值数据以及其他成员的备份数据.因此对于调用 map.get(key) 方法时,它有可能调用该成员在本成员中已经备份的key, map.get(key) 将会读取实际上拥有该键的成员的值从而来保证数据的一致性.如果将 read-backup-data 设置为true,那么它有可能直接从本成员中读取其他成员备份在此处的数据. 为了增强数据的一致性,read-backup-data的默认值是false.将此值设置为true将增强读取的性能.
<hazelcast><map name="default"><backup-count>0</backup-count><async-backup-count>1</async-backup-count><read-backup-data>true</read-backup-data></map>
</hazelcast>此处说的特性,当且仅当有至少1个同步或异步备份的情况下可用喔.
4.1.3.剔除(Eviction)
除非你从map人工删除数据或使用剔除策略,否则他们将会遗留在map中.Hazelcast支持分布式map的基于策略的剔除.一般的策略为LRU(Least Recently Used)以及LFU (Least Frequently Used).
以下是另外的一些配置声明:
<hazelcast><map name="default">...<time-to-live-seconds>0</time-to-live-seconds><max-idle-seconds>0</max-idle-seconds><eviction-policy>LRU</eviction-policy><max-size policy="PER_NODE">5000</max-size><eviction-percentage>25</eviction-percentage>...</map>
</hazelcast>接下来,我们说明一下各个配置.
-
time-to-live: Maximum time in seconds for each entry to stay in the map. If it is not 0, entries that are older than and not updated for this time are evicted automatically. Valid values are integers between 0 andInteger.MAX VALUE. Default value is 0 and it means infinite. Moreover, if it is not 0, entries are evicted regardless of the seteviction-policy. -
max-idle-seconds: Maximum time in seconds for each entry to stay idle in the map. Entries that are idle for more than this time are evicted automatically. An entry is idle if noget,putorcontainsKeyis called. Valid values are integers between 0 andInteger.MAX VALUE. Default value is 0 and it means infinite. -
eviction-policy: Valid values are described below.- NONE: Default policy. If set, no items will be evicted and the property
max-sizewill be ignored. Of course, you still can combine it withtime-to-live-secondsandmax-idle-seconds. - LRU: Least Recently Used.
- LFU: Least Frequently Used.
- NONE: Default policy. If set, no items will be evicted and the property
-
max-size: Maximum size of the map. When maximum size is reached, map is evicted based on the policy defined. Valid values are integers between 0 andInteger.MAX VALUE. Default value is 0. If you wantmax-sizeto work,eviction-policyproperty must be set to a value other than NONE. Its attributes are described below.-
PER_NODE: Maximum number of map entries in each JVM. This is the default policy.<max-size policy="PER_NODE">5000</max-size> -
PER_PARTITION: Maximum number of map entries within each partition. Storage size depends on the partition count in a JVM. So, this attribute may not be used often. If the cluster is small it will be hosting more partitions and therefore map entries, than that of a larger cluster.<max-size policy="PER_PARTITION">27100</max-size> -
USED_HEAP_SIZE: Maximum used heap size in megabytes for each JVM.<max-size policy="USED_HEAP_SIZE">4096</max-size> -
USED_HEAP_PERCENTAGE: Maximum used heap size percentage for each JVM. If, for example, JVM is configured to have 1000 MB and this value is 10, then the map entries will be evicted when used heap size exceeds 100 MB.<max-size policy="USED_HEAP_PERCENTAGE">10</max-size>
-
-
eviction-percentage: Whenmax-sizeis reached, specified percentage of the map will be evicted. If 25 is set for example, 25% of the entries will be evicted. Setting this property to a smaller value will cause eviction of small number of map entries. So, if map entries are inserted frequently, smaller percentage values may lead to overheads. Valid values are integers between 0 and 100. Default value is 25.
剔除配置样本
<map name="documents"><max-size policy="PER_NODE">10000</max-size><eviction -policy>LRU</eviction -policy> <max-idle-seconds>60</max-idle-seconds>
</map>在此样本中,documents map将在大小超过10000时开始剔除数据操作.剔除操作进行剔除的是最少使用到的数据.具体的是剔除超过60秒未被使用的数据.
剔除键值对数据特性
通过上述剔除政策的解读我们发现,通过配置可以适用于整个map的数据.满足条件的数据将会被剔除.
但是当你想剔除特定的数据时你该怎么办呢?在这个例子中,你可以在调用map.put()方法时,使用ttl以及timeunit参数来手动设置这个键值对的剔除操作.下面给出本操作的代码.
myMap.put( "1", "John", 50, TimeUnit.SECONDS )此处实现的效果是,当键“1”放入myMap时,将在50s后被剔除.
剔除所有键值对
调用evictAll()方法将剔除map中除了上锁的键值对以外的所有键值对.如果一个map中定义了MapStore,那么调用evictAll()方法时将不会调用deleteAll方法.如果你希望deleteAll方法,请调用clear()方法.
下面给出一个例子~~:
public class EvictAll {public static void main(String[] args) {final int numberOfKeysToLock = 4;final int numberOfEntriesToAdd = 1000;HazelcastInstance node1 = Hazelcast.newHazelcastInstance();HazelcastInstance node2 = Hazelcast.newHazelcastInstance();IMap<Integer, Integer> map = node1.getMap(EvictAll.class.getCanonicalName());for (int i = 0; i < numberOfEntriesToAdd; i++) {map.put(i, i);}for (int i = 0; i < numberOfKeysToLock; i++) {map.lock(i);}// should keep locked keys and evict all others.map.evictAll();System.out.printf("# After calling evictAll...\n");System.out.printf("# Expected map size\t: %d\n", numberOfKeysToLock);System.out.printf("# Actual map size\t: %d\n", map.size());}
}执行效果如下:
# After calling evictAll...
# Expected map size : 4
# Actual map size : 4
NOTE: Only EVICT_ALL event is fired for any registered listeners.
后续章节敬请关注.
关于翻译的一点说明:仅作为学习交流之用.如有错误,请大家指出,谢谢!
---------------------------------------------------------------------------------------------------------------------------------------------
英文文档:http://docs.hazelcast.org/docs/3.3/manual/html-single/hazelcast-documentation.html
这篇关于Hazelcast--Map数据类型中文版之前篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





