本文主要是介绍机器学习科学计算库使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
matplotlib使用
-
设置图片大小
fig = plt.figure (figsize = (20,8),dpi = 80)
长,宽; dpi==>每英寸像素,数值越大越清晰
matplot回值折线图
-
导入pyplot工具
import import matplotlib.pyplot as plt -
设置中文显示。若不设置,在绘制图片时中文不能显示。方法有三种,分别如下:
-
方法1
-
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 -
方法2
# 修改显示中文的方法2:使用rc来进行修改 # from matplotlib import pyplot as plt '''font = {'family' : 'monospace','weight' : 'bold','size' : 'larger'}rc('font', **font) # pass in the font dict as kwargs ''' -
方法3
# 修改显示中文的方法3: 使用font_manage中的FontProperties方法实例一个对象进行设
-
-
设置图片大小,使用figure方法
plt.figure(figsize=(20,8),dpi=80) -
处理参数
x:很坐标参数是可迭代对象,可以是range,tuple,list等,生成器不可以
y:可迭代对象形式给定
-
对坐标刻度及刻度描述标签进行设置,使用 xticks/yticks 属性(方法)进行设定
plt.xticks(_x[::3], _xticks_lables[::3],rotation = 45) # 至少传入两个参数,第一个是x的刻度,第二个是x轴的刻度标签,两者是一一对应的关系,rotation设置显示角度 -
调用绘图命令,不同的图形显示使用不同的命令,命令表格如下:
plt.comand(x,y,关键字传参)comand: plot:绘制折线图
scatter: 绘制散点图
bar:绘制矩形图,横向显示的使用barh

-
# 添加图例,显示上面设置的label标签 plt.legend() -
# 设置坐标轴的标签显示 plt.xlabel('时间') plt.ylabel('温度') plt.show()
numpy的使用
numpy介绍即数据结构
-
创建数组:
-
a = np.array([1,2,3,4,5]) b = np.array(range(1,6)) c = np.arrage(1,6) # 以上三个语句的内容相同 # arange方法中有dtype属性指定生成的数组中的元素数据类型- 注意arange和range的区别,都是生成一个可迭代数据类型,arange是np中的一种方法,生成一个numpy.ndarray的类,等间距的数组(Array of evenly spaced values.)
-
-
数组的形状
-
查看数组的形状
a.shape()方法可以查看数组的形状(维度)
-
修改数组的形状
a.reshape(x,y):方法实现将数组修改为x行y列的数组形式。
a.reshape(n,):n是数组元素数量,方法实现将数组修改为1维数组时,注意后面需要添加“ , ”
reshape方法不改变原来的数据格式,返回一个参数要求的数组
a.flatten():方法实现将数组修改为1维数组

-
-
数组的运算
同维度的数组运算
- 两个数组相加,结果是两个数组对应位置的元素相加的和作为同维度数组的结果
- 两个数组相乘,结果是两个数组对应位置的元素相乘的积作为同维度对应位置的元素的数组
不同维度的数组运算
-
a = np.array([[1,2,3],[4,5,6],[7,8,9]]) b = np.array([[1,2,3]]) print(a+b) print(a*b) -
结果:
[[ 2 4 6][ 5 7 9][ 8 10 12]] [[ 1 4 9][ 4 10 18][ 7 16 27]]
结论:列相同的数组进行算数运算,结果等于对应位置的元素算数运算后组成的数组
-
a = np.array([[1,2,3],[4,5,6],[7,8,9]]) b = np.array([[1,2,3]]).reshape(3,1) '''b= [[1][2][3]] ''' print(a+b) print(a*b) -
[[ 2 3 4][ 6 7 8][10 11 12]] [[ 1 2 3][ 8 10 12][21 24 27]]
不同维度的数组进行运算时,相同的形状的对应位置进行计算。
-
轴
- 轴在数组中可以理解为方向,即向量
- 一维数组有一个轴,三维数组有三个轴,0轴,1轴,2轴。三维数组的块是0轴,行是0轴,列是1轴
numpy读取数据
问题点:1.bool索引
-
数据文件格式 : CSV:comma-separated value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
-
调用函数
np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
二维数组中的转置方法:
-
t.transpose(): 此函数为转置函数
-
t.T
-
t.swapaxes(1,0) 交换轴函数,也可以实现数组的转置
-
-
numpy中的索引和切片
-
取单行
t[n,:]: 表示取第n+1行
-
取多行
t[n:m,:]:表示取第n到m-1行
-
取不连续的多行,取第n,m,k行
t[[n,m,k],:]
-
取列,在数组名后面的参数列表中添加逗号,逗号之后表示的是列,逗号之前表示的是行
t[:,n:m]:表示取n行m列
-
取连续的列
t[:,n:m] 表示取n到m列的数据
-
取不连续的列
t[:,[n,m,k]]
-
取连续行连续列
t[a:b,n:m]
-
取对应行对应列
-
-
numpy中数值修改
只需要取出后直接赋值就可以
-
ndarry中条件选取内容并重新赋值的方法
# 给数组中小于10的数赋值为3 # bool索引 t[t<10]=3 # t<10 的方法返回一个由bool类型数值组成的和t相同维度的数组,满足条件的元素为true,否则为false t[t<10]# 返回的是t数组中满足数值小于10的元素组成的数组 -
三元运算符
使用np.where(t<10,0,10): 满足小于10的值替换为0,不满足的替换为10
-
clip(裁剪),将clip参数范围外的数值替换为参数边缘数值
t.clip(10,18):将小于10 的替换为10,大于18 的替换为18
-
-
数组的拼接
两种拼接方式:竖直拼接,水平拼接
np.vstack(t1,t2):将t1和t2进行竖直方向上 的拼接,t1在上,t2在下
np.hstack(t1,t2):将t1和t2进行水平方向上的拼接,t1在左,t2在右
注意:水平分割是竖直画条线,与水平拼接是互逆过程,竖直分割同理
-
数组的行列交换
使用索引和切片的方式
行交换:t[[1,2],:] = t[[2,1],:]# 交换1行和2行的数据
列交换:t[:,[0,2]] = t[:,[2,0]]# 交换0列和2列的数据
-
获取最大值最小值的位置
- np.argmax(t,axis=0)
- np.argmin(t,axis=1)
-
numpy生成随机数

np.random.rand()
-
numpy中的nan型数据是浮点数,nan即缺失数据
-
np.nan==np.nan结果是false,np.nan!=np.nan
-
统计数组中nan值的个数方法:根据以上的结论,使用np.count_nonzero(t!=t)可以获取数组中nan的个数
-
np.count_nonzero(np.isnan(t)): 也可以获取数组中nan的个数
-
nan和任何数值运算都是nan
-
np.sum(t,axis=0):axis表示计算那个方向上的各元素的和,以0方向为轴,计算每列的和,和行的结构一样
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k6OaQo62-1591710125176)(C:\Users\sang\AppData\Roaming\Typora\typora-user-images\image-20200112201816031.png)]
-
-
-
数组中有nan的计算方法:将nan的数值替换为均值或者中值。
t.mean(axis=0):求平均值
numpy中的常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)
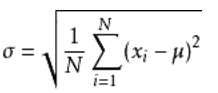
- 标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较 大;一个较小的标准差,代表这些数值较接近平均值,反映出数据的波动稳定情况,越大表示波动越大,约不稳定
numpy中的nan替换方法
-
-
查看每列是否有nan值,对数组进行遍历
-
根据nan!=nan的特性,判断当前列中是否有nan,有nan的位置会返回true,然后使用count_nonzero()方法(统计非零数量),若有True,说明有符合条件的数组元素,
-
通过如下语句获取非nan数组元素,返回一个不含nan的数组。
-
temp_col_1 = temp_col[temp_col == temp_col]
-
pandas使用
帮助我们处理非数值型的数据
常用的数据类型
1. series,一维数据,带标签的数组
-
pd.Series(内部添加一维数组)
-
第一列是索引(标签)
-
第二列是数据
-
字典创建;
Series(dict )
2. Dataframe,二维数据,Series容器
- 读取后在数据的开头和结尾有新增行和列,列称为ind ex,行称为Colum

pandas读取外部数据
-
pandas.read_csv(文件路径)
-
pd.DataFrame(data)
-
pandas 中对数据进行排序:
使用sort_values(by=“字段名”,ascending=False) ascending 表示升序还是降序
-
pandas中取行取列
同之前的numpy方法一样,
-
使用loc或者iloc方法获取数据
loc是通过标签来获取数据信息,
iloc通过位置索引获取数据信息
-
pandas中不能使用连续的关系符号,需要使用&或者|连接,用来进行条件判断
-
pandas中判断数据是否是nan,使用isnull方法,如果是nan,返回true,否则,返回false
-
notnull()非nan数据判断。
-
inplace参数:替换
-
删除nan所在的行列使用dropna
-
填充数据使用fillna方法,fillna()中可以传参,一般使用平均值填充,或者指定参数进行处理
-
处理0数据:将0数据替换成nan数据,根据实际情况进行处理,当然也不是每次的0数据都需要处理
pandas常用统计方法
-
使用pandas读取电影数据,并都各个类型的电影数量进行读取展示
方法:对电影的分类采用一个列表,各个列为电影分类;读取数据中Genre中的参数信息
# 导包 import pandas as pd import numpy as np import matplotlib.pyplot as plt file_path = 'youtube_video_data/IMDB-Movie-Data.csv' df = pd.read_csv(file_path) # print(df.head()) print(df['Genre']) # 对于一组电影数据,统计电影分类情况,重新构造一个全0 的数组,列名 # 为分类,如果某一条数据中分类出现过就让0 标为1 # 将genere取出,转换成字符串格式后,使用字符串分割,取出各个元素,然后组成列表 temp_list = df['Genre'].str.split(',').tolist() # print(temp_list) # 使用set去重的属性将,将所有的标签取出,让后再使用set去重 genere_list = list(set([i for j in temp_list for i in j])) # genere_list = list(set(temp_list)) # print(temp_list.dtype()) # print(genere_list) # 构造全为0 的数组 zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genere_list))),columns=genere_list) # print(zeros_df) # 给每个电影应出现分类的位置赋值1 for i in range(df.shape[0]):zeros_df.loc[i,temp_list[i]] = 1 # print(zeros_df.head()) # 统计每个分类的电影数量和 # axis 指定轴方向,时最后结果呈现的形式与axis有关 genre_count = zeros_df.sum(axis = 0).sort_values() # print(genre_count) # 绘图 _x = genre_count.index _y = genre_count.values plt.figure(figsize = (20,8),dpi = 80) plt.bar(_x,_y) plt.show() -
pandas数据合并
默认情况下他时把航航索引相同的数据合并到一起
问题
获取行索引用什么,shape(1)?shape[1]是什么
set_index后,原数据是否改变
reset_index,是添加还是替换?
data[:10]获取前10行元素
1
print(zeros_df.head())
统计每个分类的电影数量和
axis 指定轴方向,时最后结果呈现的形式与axis有关
genre_count = zeros_df.sum(axis = 0).sort_values()
print(genre_count)
绘图
_x = genre_count.index
_y = genre_count.values
plt.figure(figsize = (20,8),dpi = 80)
plt.bar(_x,_y)
plt.show()
* pandas数据合并默认情况下他时把航航索引相同的数据合并到一起# 问题获取行索引用什么,shape(1)?shape[1]是什么set_index后,原数据是否改变reset_index,是添加还是替换?data[:10]获取前10行元素这篇关于机器学习科学计算库使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





