本文主要是介绍Netty中的ByteBuf使用介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ByteBuf有三类:
- 堆缓存区:
JVM堆内存分配 - 直接缓冲区:有计算机内存分配,
JVM只是保留分配内存的地址信息,相对于堆内存方式较为昂贵; - 复合缓冲区:复合缓冲区CompositeByteBuf,它为多个ByteBuf 提供一个聚合视图。比如HTTP 协议,分为消息头和消息体,这两部分可能由应用程序的不同模块产生,各有各的 ByteBuf,将会在消息被发送的时候组装为一个ByteBuf,此时可以将这两个ByteBuf聚 合为一个CompositeByteBuf,然后使用统一和通用的ByteBuf API来操作;
ByteBufAllocator
当在需要ByteBuf时,用这个类进行获取,它提供了3中类型的ByteBuf获取。
// 返回一个基于堆或直接内存的ByteBuf
ByteBuf buffer();ByteBuf buffer(int initialCapacity);ByteBuf buffer(int initialCapacity, int maxCapacity);
// 返回一个适用于IO操作的ByteBufByteBuf ioBuffer();ByteBuf ioBuffer(int initialCapacity);ByteBuf ioBuffer(int initialCapacity, int maxCapacity);
// 返回一个基于堆内存的ByteBufByteBuf heapBuffer();ByteBuf heapBuffer(int initialCapacity);ByteBuf heapBuffer(int initialCapacity, int maxCapacity);
// 返回一个基于直接内存的ByteBufByteBuf directBuffer();ByteBuf directBuffer(int initialCapacity);ByteBuf directBuffer(int initialCapacity, int maxCapacity);
// 返回一个包含指定数量的ByteBuf的复合ByteBufCompositeByteBuf compositeBuffer();CompositeByteBuf compositeBuffer(int maxNumComponents);
// 返回一个包含指定数量的堆内存ByteBuf的负荷ByteBufCompositeByteBuf compositeHeapBuffer();CompositeByteBuf compositeHeapBuffer(int maxNumComponents);
// 返回一个包含指定数量的直接内存ByteBuf的负荷ByteBufCompositeByteBuf compositeDirectBuffer();CompositeByteBuf compositeDirectBuffer(int maxNumComponents);
// 判断是否池化的直接内存对象boolean isDirectBufferPooled();
// 根据最小和最大容量计算出一个新的容量int calculateNewCapacity(int minNewCapacity, int maxCapacity);
在netty中使用方式例如下面再入站里的handler调用:
protected void channelRead0(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf) throws Exception {System.out.println("客户端收到:" + byteBuf.toString(CharsetUtil.UTF_8));ByteBuf bb = channelHandlerContext.alloc().heapBuffer();ByteBuf db = channelHandlerContext.alloc().directBuffer();channelHandlerContext.channel();}
它由上下文对象ChannelHandlerContext调用alloc()方法获取ByteBufAllocator。
API
我们先看下下面这几个API,需要熟悉理解的:
// 返回一个ByteBufAllocator,创建ByteBuf使用
public abstract ByteBufAllocator alloc();
// 返回可以被读取的字节的开始索引public abstract int readerIndex();
public abstract ByteBuf readerIndex(int readerIndex);
// 返回可被写入字节的开始索引public abstract int writerIndex();public abstract ByteBuf writerIndex(int writerIndex);
// 可被读取的字节数public abstract int readableBytes();
// 可被写入的字节数public abstract int writableBytes();
// 是否可读public abstract boolean isReadable();
// 是否可读,参数是是否可读入指定字节数public abstract boolean isReadable(int size);
// 是否可写public abstract boolean isWritable();
// 是否可写,参数是是否可读入指定字节数public abstract boolean isWritable(int size);
// 清空数据public abstract ByteBuf clear();
// 标记当前的可被读取的开始索引public abstract ByteBuf markReaderIndex();
// 重置可被读取的索引,就是重置为标记的索引,或是0public abstract ByteBuf resetReaderIndex();
// 标记可被写入的开始索引public abstract ByteBuf markWriterIndex();
// 重置可被写入的索引,就是重置为标记的索引,或是0public abstract ByteBuf resetWriterIndex();
// 丢弃读取过的字节(0到readerIndex的部分)public abstract ByteBuf discardReadBytes();
虽然上面注释有写过,但还是再提醒一遍;
readerIndex表示可以被读取数据的开始索引,或者说已经读取了readerIndex个字节;
writerIndex表示可以被写入数据的开始索引,或者说已经写入了writerIndex个字节;
discardReadBytes丢弃的是读取过的字节数据,同时writerIndex会相应减少对应的字节长度;
看几个例子,再次加深记忆:
ByteBuf byteBuf = new PooledByteBufAllocator().buffer();System.out.println("--------------测试get/set 与 read/write方法的区别");byteBuf.setBytes(0, "qwer".getBytes());System.out.println("数据:" + byteBuf.toString(CharsetUtil.UTF_8));System.out.println("set 之后 readIndex:" + byteBuf.readerIndex());System.out.println("set 之后 wirteIndex:" + byteBuf.writerIndex());System.out.println("get 之后 readIndex:" + byteBuf.readerIndex());System.out.println("get 之后 wirteIndex:" + byteBuf.writerIndex());// 没有数据被写进去System.out.println(byteBuf.toString(CharsetUtil.UTF_8));// 写入12个字节数据,writerIndex=12byteBuf.writeBytes("天气不错".getBytes(CharsetUtil.UTF_8));System.out.println("数据:" + byteBuf.toString(CharsetUtil.UTF_8));// 没有读取,readerIndex=0System.out.println("write 之后 readIndex:" + byteBuf.readerIndex());System.out.println("write 之后 wirteIndex:" + byteBuf.writerIndex());// get方式获取字节,readerIndex不会移动byteBuf.getByte(3);System.out.println("get 之后 readIndex:" + byteBuf.readerIndex());System.out.println("get 之后 wirteIndex:" + byteBuf.writerIndex());// read方式读取,readerIndex=3,没有涉及写入,writerIndex不变byteBuf.readBytes(3);System.out.println("read 之后 readIndex:" + byteBuf.readerIndex());System.out.println("read 之后 wirteIndex:" + byteBuf.writerIndex());// 因为读取了3个字节(一个汉字),可被读取的数据从第二个汉字开始System.out.println("数据:" + byteBuf.toString(CharsetUtil.UTF_8));// 容量256System.out.println("容量:" + byteBuf.capacity());// 将数据的第6个索引开始替换为指定的字节数据,注意,这个长度要在指定索引和writerIndex差值内,不然会报异常(因为没有数据可以被操作)byteBuf.setBytes(6, "123".getBytes());System.out.println("setBytes 之后:" + byteBuf.toString(CharsetUtil.UTF_8));System.out.println("-------------测试byteBuf其他的一些方法");System.out.println("readableBytes 可被读取的字节数:" + byteBuf.readableBytes());System.out.println("writableBytes 可被写入的字节数:" + byteBuf.writableBytes());System.out.println("isReadable 是否可读:" + byteBuf.isReadable());System.out.println("isWritable 是否可写:" + byteBuf.isWritable());System.out.println("-----------测试标记与重置");// 重置也就是readerIndex=writerIndex=0byteBuf.resetReaderIndex();byteBuf.resetWriterIndex();System.out.println("reset 之后 readIndex:" + byteBuf.readerIndex());System.out.println("reset 之后 wirteIndex:" + byteBuf.writerIndex());// 重新写入数据,测试后面的方法byteBuf.writeBytes("天气真好".getBytes(CharsetUtil.UTF_8));// 再次读取3个字节byteBuf.readBytes(3);// 标记当前的readerIndexbyteBuf.markReaderIndex();// 标记当前的writerIndexbyteBuf.markWriterIndex();// 重置,只会重置为上一次mark的索引byteBuf.resetReaderIndex();byteBuf.resetWriterIndex();System.out.println("mark-reset 之后 readIndex:" + byteBuf.readerIndex());System.out.println("mark-reset 之后 wirteIndex:" + byteBuf.writerIndex());System.out.println("-------------测试丢弃");// 丢弃数据,释放内存,原来是写入了12个字节,writerIndex=12,执行丢弃,会把已经读取的丢弃(3个字节)// 所以,执行后的writerIndex=9,readerIndex=0byteBuf.discardReadBytes();System.out.println("容量:" + byteBuf.capacity());System.out.println("丢弃 之后 readIndex:" + byteBuf.readerIndex());System.out.println("丢弃 之后 wirteIndex:" + byteBuf.writerIndex());
结果如下:

对于上面的操作,可以看下面这个图解:

资源的释放
资源释放针对的主要是ByteBuf这个对象;
为什么说要释放ByteBuf这个对象,这个对象不是在方法中被创建的吗,方法结束后不就会被JVM回收吗?
如果说ByteBuf是一般对象的话,这个说法是对的,可是,这个对象ByteBuf是netty实现的,并且实现于ReferenceCounted,而这个接口是用于引用计数管理对象生命周期的,需要我们手动进行计数管理;
我们看下这个接口提供的方法,对这个管理便会更加清晰:
public interface ReferenceCounted {/*** 返回对象的引用计数; 如果计数=0,表示对象不被引用可以被安全回收*/int refCnt();/*** 引用计数+1*/ReferenceCounted retain();/*** 引用计数+increment(增加指定的计数)*/ReferenceCounted retain(int increment);/*** 记录当前的访问位置;* 如果发生内存泄漏,返由 ResourceLeakDetector(资源泄漏探测器)返回这些信息*/ReferenceCounted touch();/*** 记录当前的访问位置,以及额外的信息*/ReferenceCounted touch(Object hint);/*** 引用次数-1;释放当前资源*/boolean release();/*** 引用次数-decrement(减少指定计数)*/boolean release(int decrement);
}
那为什么netty要实现这么一个需要手动释放的对象?
主要几点:
- 优化内存管理:
ByteBuf支持池化(Pooled),可以重用之前分配,但已回收的内存块,减少内存分配和垃圾回收的开销;非池化(Unpooled)每次使用时都要创建对象实例,分配内存,相对于池化对象,它过于频繁的分配内存和释放操作; - 引用计数机制/性能提升:更精准的控制对象的生命周期,在JVM中,利用各种算法,如标记清除、标记整理、复制等算法决定哪些对象可以被回收,并且在某些场景下,如一个方法中的创建并且被使用的变量,需要在变量离开作用域或方法执行完,也或是被明确复制为null时,才能被判定为无引用,而
ByteBuf可以决定什么时候不被引用,做到在需要时及时回收,提高系统整体性能和响应能力; - 诊断内存泄漏:
netty提供了ResourceLeakDetector类来跟踪ByteBuf的分配,在检测到内存泄漏时打印相关日志信息;
有人会问:netty这个框架不就是为了方便于开发,对socket进行封装,对业务流程步骤进行抽象,它就不能做到自动释放?
哎,netty确实对ByteBuf做了自动释放,只是ByteBuf在handler之间流转时,这个经过业务处理,可能已经不是原来的ByteBuf,这个过程中可能创建了新的ByteBuf,而旧的ByteBuf就需要我们手动释放;
在piple中有一个handler链,我们可以自由添加handler,但是头尾handler都是默认添加的,我们来看下面代码:

这部分是piple实例化时执行的,它默认会添加TailContext和HeadContext两个handler,尾部的handler就负责释放ByteBuf对象,也就是在这个handler链中,除了我们自己添加的handler,还有两个handler分别在头部和尾部,而尾部的handler其中一个功能就是释放handler链中传递的ByteBuf对象。
位置:io.netty.channel.DefaultChannelPipeline.TailContext#channelRead

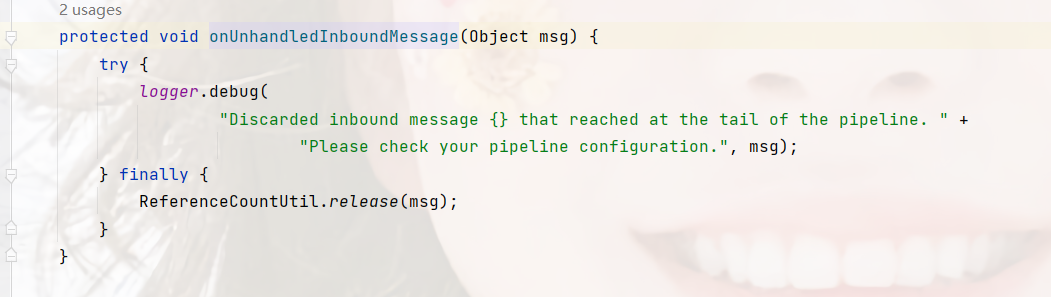
可以看到ReferenceCountUtil.release(msg);的,这里就是释放对象的地方;
ReferenceCountUtil这个是netty自己封装的用于处理实现了引用计数接口对象的工具类。
这篇关于Netty中的ByteBuf使用介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




