本文主要是介绍Hadoop 权威指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 一 集群规范
- 网络拓扑
- 二 集群的构建和安装
- 1安装 Java 16 及其以上
- 2 创建 Hadoop 用户
- 3 安装 Hadoop
- 4 测试安装
- 三 SSH 配置
- 四 Hadoop 配置
- 1 配置管理
- 2 环境设置
- 21 内存
- 22 Java
- 23 系统日志文件
- 24 SSH 设置
- 3 Hadoop 守护进程的关键属性
一. 集群规范
Hadoop 运行在商业硬件上。用户可以选择普通硬件供应商生产的标准化的,广泛有效的硬件来构建集群,无需使用特定供应商生产的昂贵、专有的硬件设备。
但有几点需要注意:
1. 商业硬件并不等同于低端硬件。
2. 也不推荐使用大型的数据库级别的机器,因为性价比太低了
3. 强烈建议采用 ECC 内存(使用非 ECC 内存会产生校验和错误)
尽管各个集群采用的硬件规格肯定有所不同,但是 Hadoop 一般使用多核 CPU 和多磁盘,以充分利用硬件的强大功能。
扩展:为何不使用 RAID?
- 尽管建议采用 RAID (磁盘阵列)作为 namenode 的存储器以保护元数据,但是若将 RAID 作为 datanide 的存储设备则不会给 HDFS 带来益处。HDFS 所提供的节点间的数据复制技术已经满足数据备份需求,无需使用RAID 的冗余机制
- 此外尽管 RAID 条带化技术(RAID 0) 被广泛用于提升性能,但是其速度仍然比用在 HDFS 里的 JBOD (Just a Bunch Of Disks)配置慢
- 最后,若 JBOD 配置的某一磁盘发生故障,HDFS 可以忽略它,继续工作,而 RAID 的某一盘片故障会导致整个磁盘阵列不可用,进而使相应节点失效
在一个小集群(几十个节点)而言,在一台 master 机器上同时运行 namenode 和 jobtracker 通常没有问题(需确保至少一份 namenode 的元数据被另存在远程文件系统中)。
随着 HDFS 中的集群和文件数不断增长,namenode 需要使用更多内存,在这种情况下 namenode 和 jobtracker ,最好分别放在不同的机器中。(即 resourcemanager 放在不同的机器中?)
辅助 namenode 可以和 namenode 一起运行子啊同一台机器上,但是同样由于内存使用的原因(辅助 namenode 和主 namenode 的内存需求相同),二者最好运行在独立的硬件上;且运行 namenode 的机器一般采用 64 位硬件,以避免在 32 位体系结构下 Java 堆的 3GB 内存限制。
网络拓扑
Hadoop 集群架构通常包含两级网络拓扑,如图所示。一般来说,各机架装配 30~40 个服务器,共享一个 1GB 的交换机(图中只画3台服务器),各机架的交换价又同感上行链路与一个核心交换机或路由器(通常为 1GB 或更高)互联。该机架的突出特点是同一机架内部的节点之间的总太宽要远高于不同机架上的节点间的带宽。
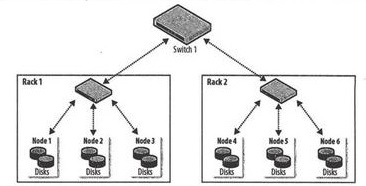
为了达到 Hadoop 的最佳性能,配置 Hadoop 系统以让其了解网络拓扑状况就极为关键。如果集群只包含一个机架,就无需做什么,因为就是默认配置。但是对于多机架的集群来说,描述清楚节点-机架间的映射关系就很有必要了。这样的话,当 Hadoop 将 Mapreduce 任务分配到各个节点时,会倾向于执行机架内的数据传输(拥有更多带宽),而非跨机架数据传输。HDFS 将能够更加机智地放置副本(replica),以取得性能和弹性的平衡。
namenode 使用网络位子来确定在哪里放置块的副本,MapReduce 的调度器根据网络位置来查找最近的副本,将它作为 map 任务的输入。
在上面的网络拓扑中,可将 node1、node2 和 node3 映射到 /rack1 ,将 node4、node5 和 node6 映射到 /rack2 中。但是大多数安装并不需要额外实现新的接口,只需要使用默认的 ScriptBasedMapping 实现即可,它运行用户定义的脚本来描述映射关系。如果没有指定脚本位置,默认情况下会将所有节点映射到单个网络位置,即 /default-rack。
二. 集群的构建和安装
2.1安装 Java (1.6 及其以上)
2.2 创建 Hadoop 用户
最好创建特定的 Hadoop 用户账号以区分 Hadoop 和本机上的其他服务。
2.3 安装 Hadoop
从官网上发布页面上下载 Hadoop 发布包,并在某一本地目录解压缩,例如 /usr/local (/opt 是另一个标准选项)。注意,鉴于 hadoop 用户的 home 目录可能挂载在 NFS 上,Hadoop 系统最好不要安装在目录上。
cd /usr/local
sudo tar
sudo chown - R hadoop:hadoop 一些管理员喜欢将 HDFS 和 MapReduce 安装在同一系统的不同位置中。但即使独立安装 HDFS 和 MapReduce ,它们仍然可以共享配置信息,其方法是使用 –config 选项(启动守护进程)指向同一配置目录。鉴于它们所产生的日志文件的名称不同,不会导致冲突,因此仍然可以将日志输出到同一个目录中。
2.4 测试安装
三. SSH 配置
尽管期望无密码登陆,但无口令的密钥并不是一个好的选择。因此当系统提示输入口令时,用户最好指定一个口令。可以使用 ssh-agent 以避免为每个连接逐一输入密码。
测试是否可以从主机器 SSH 到工作机器。若可以,则表明 ssh-agent 正在运行。再运行 ssh-add 来存储口令。这样的话,用户即可不用输入口令就能 ssh 到一台工作机器。
四. Hadoop 配置
| 文件名称 | 格式 | 描述 |
|---|---|---|
| hadoop-env.sh | Bash 脚本 | 记录脚本中要用到的环境变量,以运行 Hadoop |
| core-site.xml | Hadoop 配置 XML | Hadoop Core 的配置项,例如 HDFS 和 MapReduce 常用的 I/O 设置等 |
| hdfs-site.xml | Hadoop 配置 XML | Hadoop 守护进程的配置项,包括 namenode,SecondNamenode 和 datanode |
| mapred-site.xml | Hadoop 配置 XML | MapReduce 守护进程的配置项,包括 jobtracker 和 tasktracker |
| masters | 纯文本 | 运行 SecondNamenode 的机器列表(每行一个) |
| slaves | 纯文本 | 运行 datanode 和 tasktracker 的机器列表(每行一个) |
| hadoop-metrics.properties | Java 属性 | 控制如何在 Hadoop 上发布度量的属性 |
| log4j.properties | Java 属性 | 系统日志文件、namenode 审计日志、tasktracker 子进程的任务日志的属性 |
配置目录 conf 被重新放在文件系统的其他地方( Hadoop 安装的外面,以便于升级 ),但是守护进程启动时需要使用 –config 选项,以指向本地文件系统的某个目录。
4.1 配置管理
Hadoop 提供一个基本工具来进行同步配置文件,即rsync,此外 dsh 或 pdsh 等并行 shell 工具也可以完成该任务。虽然用户可以使用控制脚本来管理 Hadoop ,仍然建议使用控制管理工具管理集群。
1. 控制脚本
为了运行这些脚本,需要预先知道集群中所有机器。masters 和 slaves 文件可以实现。其中 masters 主要记录拟运行 SecondNamenode 的所有机器。slaves 文件记录了 datanode 和 tasktracker 的所有机器。而这两个文件无需分发到各个节点,因为只有运行在 namenode 上的控制脚本能使用这些文件。
在运行 start-dfs.sh 后,Hadoop 执行流程如下:
- 在本地机器上启动一个 namenode(脚本所运行的机器)
- 在 slaves 文件中记录的各机器上启动一个 datanode
- 在 masters 文件中记录的所有机器上均启动一个 SecondNamenode
上述 start-dfs.sh 脚本是调用了 hadoop-daemon.sh 脚本来启动和终止 Hadoop 守护进程。如果用户已经使用前述脚本,则不宜直接调用 hadoop-daemon.sh 。类似地,hadoop-daemons.sh 用于在多个主机上启动同一个守护进程。
2. master 节点场景
对于大集群来说,最好让这些守护进程分别运行在不同机器上。
namenode 在内存中保存整个命名空间中的所有文件元数据和块元数据,其内存需求很大。SecondNamenode 在大多数时间里是空闲的,但是它在创建检查点时的内存需求与主 namenode 差不多。一旦文件系统包含大量文件,单台机器的物理内存便无法同时运行 主namonode 和 SecondNamenode 。
SecondNamenode 保存一份最新的检查点,记录它创建的文件系统的元数据。将这些历史信息备份到其他节点上,有助于在数据丢失之后(或系统崩溃之后)下恢复 namenode 的元数据文件。
在运行一个大量 MapReduce 作业的高负载集群上,jobtracker (resourcemanager?)会占用大量内存和 CPU 资源,因此最好将它运行在一个专用的节点上。
4.2 环境设置
主要讨论如何设置 hadoop-env.sh 文件中的变量
4.2.1 内存
在默认情况下, Hadoop 为各个守护进程分配 1000MB (1GB)内存。该内存值由 hadoop-env.sh 文件的 HADOOP_HEAPSIZE 参数控制。
一个 tasktracker 所能够同时运行的最大 map 、reduce 任务默认都是 2。但是一个 tasktracker 上能够同时运行的任务数取决于一台机器有多少个处理器。由于 MapReduce 作业通常是 I/O 受限的(即完成整项计算任务的时间开销主要在于 I/O ,作)。因此将此任务数设定为超出处理器数也有一定道理,能够获得更好的利用率。根据经验法则是任务数(包括 map 和 reduce 任务)与处理器数的比值最好在 1 和 2 之间。
精准的内存设置极度依赖于集群自身的特性,用户需要监控集群的内存使用情况,并实时设定优化分配方案。
1000MB 内存(默认配置)通常足够管理数百万个文件。但是根据经验来看,保守估计需要为每一百万数据块分配 1000MB 内存空间。以一个含 200 节点的集群为例,假设每个节点有 4TB 磁盘空间,数据块大小是 128MB,副本数是 3 的话,则约有 2 百万个数据块(甚至更多);200*4 000 000MB / (128 MB * 3)。因此,在本例中,namenode 的内存空间最好一开始就设为 200 MB。可以通过设置 HADOOP_NAMENODE_OPTS 来实现。且一旦更改 namenode 的内存分配的话,还需要对辅助 namenode 做相同更改。
4.2.2 Java
需要设置 Hadoop 系统的 Java 安装的位置。两个方法
- 在 hadoop-env.sh 文件中设置 JAVA_HOME 项
- 在 shell 中设置 JAVA_HOME 环境变量
第一种方法更好,因为只需要操作一次就能够保证整个集群使用同一版本的 Java。
4.2.3 系统日志文件
默认情况下,系统日志输出在 $HADOOP_HOME/logs ,可以通过 hadoop-env.sh 文件中的 HADOOP_LOG_DIR 来进行修改。建议修改默认设置,使之发生独立于 Hadoop 的安装目录。这样的话,即使 Hadoop 升级之后安装路径发生变化,也不会影响日志文件的位置。通常可以将日志文件存放在 /var/log/hadoop 目录中。实现方式就是在 hadoop-env.sh 中加入下面这一行:
export HADOOP_LOG_DIR=/var/log/hadoop运行在各台机器上的各个 Hadoop 守护进程会产生两类日志文件。
日志文件(以 “.log” 作为后缀名)是通过 log4j 记录的。鉴于大部分的应用程序的日志消息都写到该日志文件中,故障斩断的首要步骤即为检查该文件。标准的 Hadoop log4j 配置采用日常滚动文件后缀策略(Daily Rolling File Appender)来命名日志文件。系统并不自动删除过期的日志文件,而是保留待用户定期删除或存档,以节省本地磁盘空间。
日志文件后缀名为 “.out” ,记录标准输出和标准错误日志。由于 Hadoop 使用 log4j 记录日志,所以该文件通常只包含少量记录,甚至为空。重启守护进程时,系统会创建一个新文件来记录此日志。系统仅保留最新的 5 个日志文件。旧的日志文件会附加一个介于 1 和 5 之间的数字后缀,5 表示最旧的文件。
4.2.4 SSH 设置
hadoop-env.sh 文件中的 HADOOP_SSH_OPTS 变量可以向 SSH 传递很多选项,进行 SSH的 自定义。例如:
- 使用 ConnectTimeout 选项来设定减小连接超时,可以避免控制脚本长时间等待宕机节点的响应(当然,也不能设置得太低,使得繁忙节点被跳过)
- 使用 StrickHostKeyChecking 选项设定为 no,则会将新主机键加入已知主机文件中。该值默认为 ask,不适合大型集群环境
通过 rsync工具,hadoop 控制脚本能够将配置文件分发到集群的各个节点中。默认该功能未启用,可以通过设置 hadoop-env.sh 中的 HADOOP_MASTER 变量启动。启用 rsync 后,当工作节点的守护进程启动后,会把以 HADOOP_MASTER 为根的目录树与本地的 HADOOP_INSTALL 目录同步。
在大型集群中,若 rsync 已启用,则集群启动时所有工作节点几乎同时启动,且同时向主节点发出 rsync 请求,可能导致主节点瘫痪。这就需要设置 hadoop-env.sh 中的另一个变量:HADOOP_SLAVE_SLEEP,将它设置为一小段时间(例如0.1秒)。该变量度量为“秒”。
4.3 Hadoop 守护进程的关键属性
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
这些文件的典型设置中的属性大多被标记为 final,以避免被作业配置重写。
这篇关于Hadoop 权威指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





