本文主要是介绍计算机组成结构—多处理器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、SISD、SIMD、MIMD 和向量处理器
1. 费林分类法
2. SIMD 和向量处理器
二、硬件多线程
三、多核处理器和 SMP
1. 多核处理器
2. 共享内存多处理器(SMP)
3. MPP 和集群
一、SISD、SIMD、MIMD 和向量处理器
通过改进系统结构,可以有效地提升计算机的性能,一个方向就是 并行处理。指令流水线就是一种典型的并行处理技术,它提供的是 指令 的并行;而另一种思路则是考虑让 数据 的处理并行起来。
1. 费林分类法
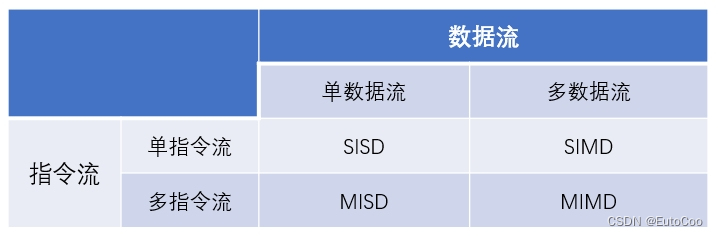
美国计算机科学家迈克尔 · 费林(Michael Flynn)根据指令和数据是否并行,将计算机体系结构分为四类:
-
SISD(Single Instruction stream, Single Data stream):单指令流单数据流。普通的串行执行结构,CPU 同时只能执行一条指令,处理一条数据;
-
SIMD(Single Instruction stream, Multiple Data streams):单指令流多数据流。单条指令可以同时对应处理多个数据,从而实现了数据的并行处理;
-
MISD(Multiple Instruction streams, Single Data stream):多指令流单数据流。多条指令同时执行,但只处理一条数据,这种架构非常罕见,只是作为一种理论模型;
-
MIMD(Multiple Instruction streams, Multiple Data streams):多指令流多数据流。同时执行多条不同的指令,它们分别处理不同的数据;这种方式实现了线程、指令和数据的全方位并行处理。
2. SIMD 和向量处理器
SIMD 的特点是,设置了多个并行的执行单元,而所有的执行单元都是同步的,执行的指令从同一个 PC 中取出,由同一个控制单元来进行调度管理。SIMD 对应的程序设计风格可以跟 SISD 非常相近,但要求程序中必须存在大量同构的数据,以便实现 数据级并行。
向量处理器是 SIMD 架构的一种具体实现,可以并行执行一组数据(向量)的计算任务。
向量处理器的基本原理是,从主存中收集数据,将它们按照顺序放到一组 向量寄存器 中,使用流水线式的执行单元在寄存器中依次进行操作,然后将结果写回主存。
二、硬件多线程
相比 SIMD,MIMD 提高了更高的并行程度。MIMD 需要同时执行不同的指令流,这就要依赖多个 进程(process) 或者 线程(thread) 同时执行,让处理器时刻保持忙碌状态。
对于一个处理器,可以允许多个线程以重叠的方式,共享处理器的功能部件;当一个线程停顿时,就切换到另一个线程,从而更加充分地利用了硬件资源。这种技术就称为 硬件多线程(hardware multithreading)。
在支持硬件多线程的 CPU 中,需要为每个线程提供单独的寄存器堆和 PC 等资源,这样就可以在共享资源的同时保持线程的独立状态。
硬件多线程主要有两种实现方法。
-
细粒度多线程
每条指令执行后就进行线程切换,从而实现多线程在时间上的交叉执行。这种交叉执行是轮转进行的,并且会跳过停顿的任何线程。
-
粗粒度多线程
仅在发生高开销的停顿时(例如末级 cache 失效),才进行线程切换。对于流水线中的停顿,需要清空或者冻结流水线,因此流水线的重启开销比较大。
除此之外,硬件多线程还可以结合流水线多发技术,进一步降低成本、提高并行效率,这就是 同时多线程(Simultaneous Multithreading,SMT)。同时多线程是硬件多线程的一种变体,它结合使用多发射、动态调度流水线的处理器资源,来实现 线程级 和 指令级 并行。
英特尔(Intel)公司的 “ 超线程 “(Hyper-Threading)技术,就是一种在单个 CPU 上实现硬件多线程的方式。
三、多核处理器和 SMP
1. 多核处理器
另一种实现线程级并行的方式,就是在一个处理器芯片上,集成多个处理单元。为了区分不同的概念,每个处理单元就称为一个 ” 核 “(core),有多个核的处理器就被称为 多核处理器。
要想充分利用多核处理器的性能,应该采用多线程的方式执行程序。这样,多个线程可以在不同的核上并行执行,大大提升运行效率。
多核处理器一般也采用硬件多线程技术,为了进行区分,有时会将单个核心上同时运行多个线程称为有多个 ”逻辑内核“,而对应的真正的核心则称为 ”物理内核“。
在多核处理器中,一般所有内核会有自己独立的寄存器和 L1、L2 缓存,而共享更低级的 cache(L3)和主存。

如果不对处理单元进行集成,也可以用同样的架构将多个处理器联合在一起,这就是所谓的 多处理器。广义上讲,多核处理器也是一种多处理器。
2. 共享内存多处理器(SMP)
编写运行在多处理器上的并行程序会更加复杂。在架构上,一个很重要的影响因素是,是否为所有处理器提供一个共享的统一物理地址空间;换句话说,所有处理器(核心)是否可以访问同一个主存储器。于是多处理器又可以划分为两种架构。
共享内存多处理器(Shared Memory Processor,SMP)为所有处理器提供统一的物理地址空间。处理器通过存储器中的 共享变量 进行通信,所有处理器都能通过加载(Load)和存储(Store)指令访问任意的主存位置。
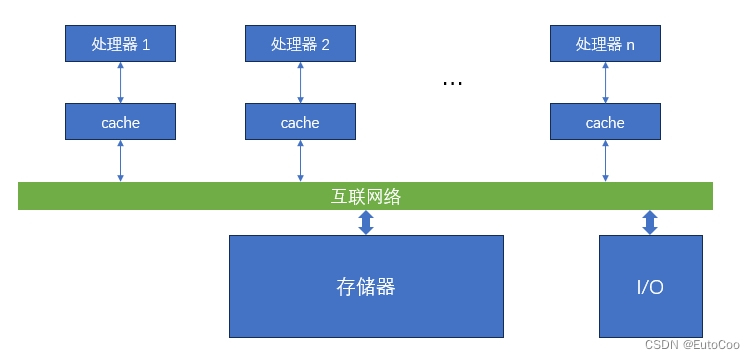
尽管物理地址空间是统一的、共享的,但如果存储器本身也采取了并行架构(例如多模块存储器),不同的处理器对存储器不同部分的访问可能就会有区分。因此 SMP 又可以有两种类型。
-
统一内存访问(Unified Memory Access,UMA)多处理器
不管是来自哪个处理器的访存指令,延迟都是一致的。这样,每个处理器对所有存储单元的访问时间都大致相同,是对称的系统架构。
-
非统一内存访问(Non-Unified Memory Access,NUMA)多处理器
访存指令的延迟不一致,取决于哪个处理器去访问哪个存储单元。一般架构中,每个处理器(CPU)会单独直接连接一部分主存,称为 本地内存;其它主存部分则通过总线进行访问,称为 远程内存。
3. MPP 和集群
如果不采用共享内存的方式,而是让每个处理器都拥有私有的地址空间,这样就可以让各个处理器更加独立、获得更好的并行性和可扩展性。这种架构被称为 大规模并行处理(Massive Parallel Processing,MPP)。
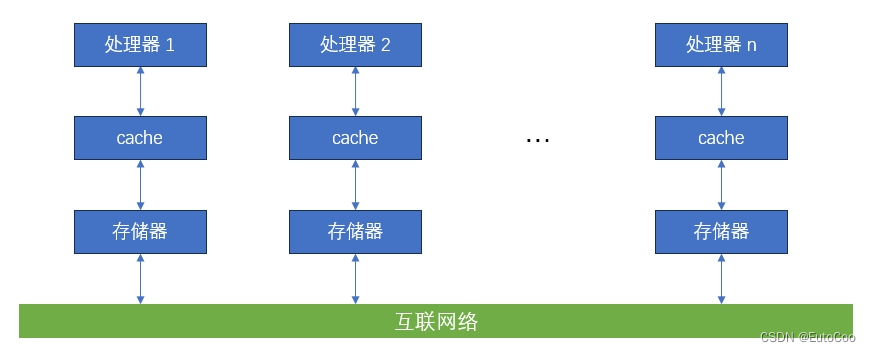
采用 MPP 架构的多处理器,必须通过显式的 消息传递 进行通信,因此传统上也把这种类型的计算机称为 显式消息传递计算机。
更进一步,我们可以通过标准网络交换机上的 I/O 接口进行连接,用一组计算机的集合来构建出消息传递多处理器,这种形式就被称为 集群(Cluster)。集群是一种分布式系统,已经成为如今并行处理计算机最典型的架构,也是大数据领域的技术基础。
这篇关于计算机组成结构—多处理器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







