本文主要是介绍SQL进阶day11——窗口函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1专用窗口函数
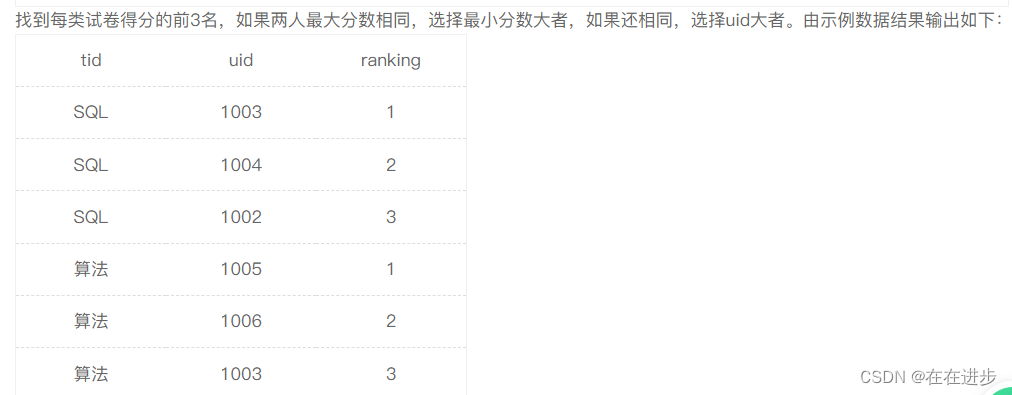
1.1 每类试卷得分前3名
1.2第二快/慢用时之差大于试卷时长一半的试卷
1.3连续两次作答试卷的最大时间窗
1.4近三个月未完成试卷数为0的用户完成情况
1.5未完成率较高的50%用户近三个月答卷情况
2聚合窗口函数
2.1 对试卷得分做min-max归一化
2.2每份试卷每月作答数和截止当月的作答总数。
2.3 每月及截止当月的答题情况
1专用窗口函数

1.1 每类试卷得分前3名
我的代码:筛选好难,不懂啥意思
select tag tid,uid,rank()over(partition by tag order by score desc ) ranking
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
limit 3正确代码:
select *
from (select tag tid,
uid,
rank()over(partition by tag order by max(score) desc,min(score) desc,max(uid) desc) ranking
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
group by tag,uid)t
where ranking<=3复盘:
(1)排序:如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者
ORDER BY MAX(score) desc ,MIN(score) desc,uid desc
(2)窗口函数
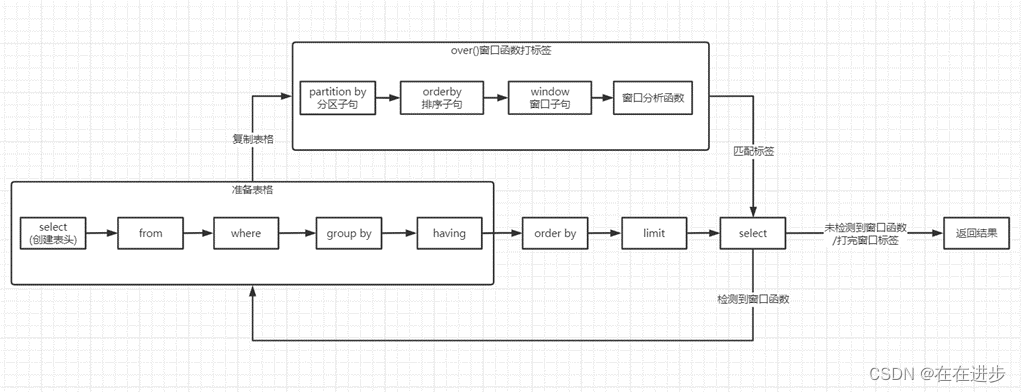
【排序窗口函数】
● rank()over()——1,1,3,4
● dense_rank()over()——1,1,2,3
● row_number()over()——1,2,3,4
1.2第二快/慢用时之差大于试卷时长一半的试卷

我的代码:没搞出来,好久没有弄窗口了,这个题好难
方法1:max(if)
select a.exam_id,b.duration,b.release_time
from
(select exam_id,
row_number() over(partition by exam_id order by timestampdiff(second,start_time,submit_time) desc) rn1,
row_number() over(partition by exam_id order by timestampdiff(second,start_time,submit_time) asc ) rn2,
timestampdiff(second,start_time,submit_time) timex
from exam_record
where score is not null) ainner join examination_info b on a.exam_id=b.exam_id
group by a.exam_id
#if(rn1=2,a.timex,0)后最大值肯定是第二位的a.timex了
having (max(if(rn1=2,a.timex,0))-max(if(rn2=2,a.timex,0)))/60>b.duration/2
order by a.exam_id desc方法2:分析(窗口)函数:NTH_VALUE
select distinct c.exam_id,duration,release_time from
(select a.exam_id,
nth_value(TIMESTAMPDIFF(minute,start_time,submit_time),2) over (partition by exam_id order by TIMESTAMPDIFF(minute,start_time,submit_time) desc ) as low_2,
nth_value(TIMESTAMPDIFF(minute,start_time,submit_time),2) over (partition by exam_id order by TIMESTAMPDIFF(minute,start_time,submit_time) asc) as fast_2,
duration,release_time
from exam_record a left join examination_info b on a.exam_id = b.exam_id) c
where low_2-fast_2>duration*0.5
order by exam_id desc;复盘:
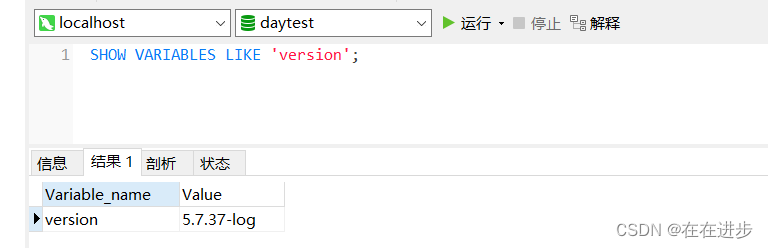
(1)时间差函数:timestampdiff,如计算差多少分钟,timestampdiff(minute,时间1,时间2),是时间2-时间1,单位是minute
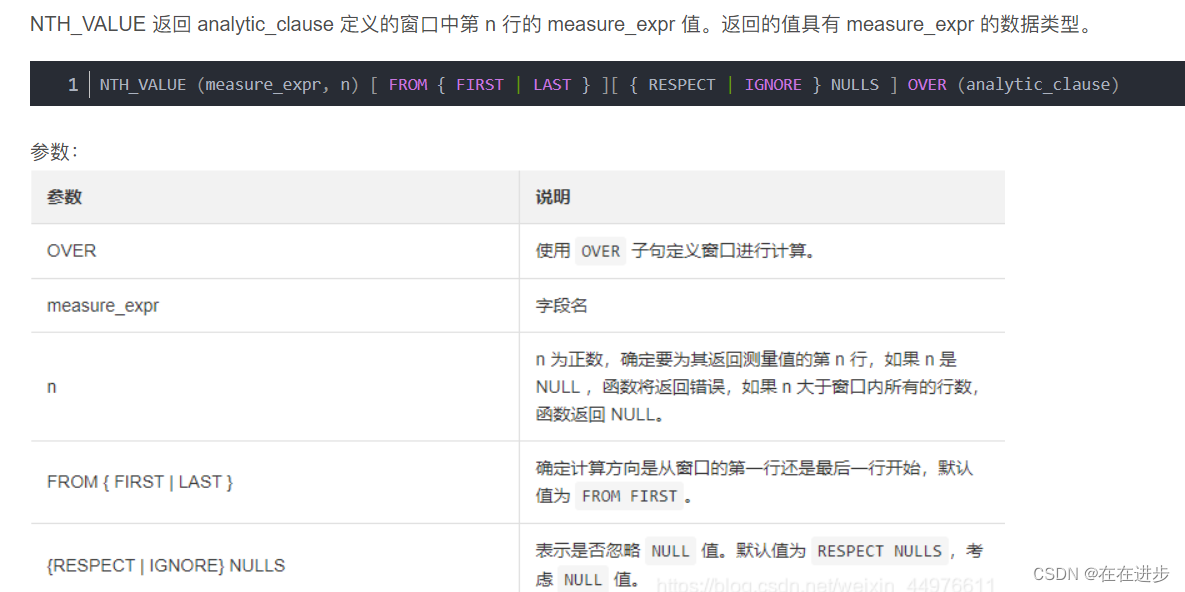
(2)如何取次最大和次最小呢:分析(窗口)函数:NTH_VALUE
NTH_VALUE (measure_expr, n) [ FROM { FIRST | LAST } ][ { RESPECT | IGNORE } NULLS ] OVER (analytic_clause)
(3)关于窗口函数,才发现我本地的数据库连接版本是5,只有MySQL8以上才能用窗口函数好像,所以不能在本地演练推导了。(我一点也不想升级,安装都很麻烦,升级的话肯定各种报错)
1.3连续两次作答试卷的最大时间窗

我的思路:(写不出来)
(1)先把每个用户作答时间用dateformat求出来
(2)在作差,应该可以用偏移分析函数:
【偏移分析函数】
● lag(字段名,偏移量[,默认值])over()——当前行向上取值“偏移量”行
● lead(字段名,偏移量[,默认值])over()——当前行向下取值“偏移量”行
例:
● ,confirmed 当天截至时间累计确诊人数
● ,lag(confirmed,1)over(partition by name order by whn) 昨天截至时间累计确诊人数
● ,(confirmed - lag(confirmed,1)over(partition by name order by whn)) 每天新增确诊人数
(3)然后选取最大的这个差值
正确代码:
select uid,max(datediff(next_time,start_time))+1 as days_window,round(count(start_time)/(datediff(max(start_time),min(start_time))+1)*(max(datediff(next_time,start_time))+1),2)as avg_exam_cnt
from(select uid,start_time,lead(start_time,1) over(partition by uid order by start_time) as next_timefrom exam_recordwhere year(start_time) = '2021')a
group by uid
having count(distinct date(start_time)) > 1
order by days_window desc,avg_exam_cnt desc
复盘:
(1)先找出uid, 开始时间,下次开始时间。条件是2021创建子表
下次开始时间用偏移分析函数:
● lead(字段名,偏移量[,默认值])over()——当前行向下取值“偏移量”行
select uid,start_time,lead(start_time,1) over(partition by uid order by start_time) as next_time
from exam_record
where year(start_time) = '2021'(2)最大时间窗口 = max(datediff(next_time,start_time))+1
(3)平均做答试卷套数=作答的试卷数 / 作答期间 *最大时间窗口
= 3/7*6
= count(start_time)/
(datediff(max(start_time),min(start_time))+1)
*(max(datediff(next_time,start_time))+1)
= round(count(start_time)/
(datediff(max(start_time),min(start_time))+1)
*(max(datediff(next_time,start_time))+1),2) #保留两位小数
(4)时间作差要用时间差函数datediff,不能直接相减:结果会是不一样的

(5)datediff()函数 与 timestampdiff()函数的区别
//语法
DATEDIFF(datepart,startdate,enddate)
SELECT DATEDIFF('2018-05-09 08:00:00','2018-05-09') AS DiffDate;//结果 0 ; 表示 2018-05-09 与 2018-05-09之间没有日期差。这里是不比较时分秒的。下面验证带上时分秒有没有差别。SELECT DATEDIFF('2018-05-09 00:00:00','2018-05-09 23:59:59') AS DiffDate;//结果 0 ;SELECT DATEDIFF('2018-05-08 23:59:59','2018-05-09 00:00:00') AS DiffDate;//结果 -1;SELECT DATEDIFF('2018-05-09 00:00:00','2018-05-08 23:59:59') AS DiffDate;
//结果 1; 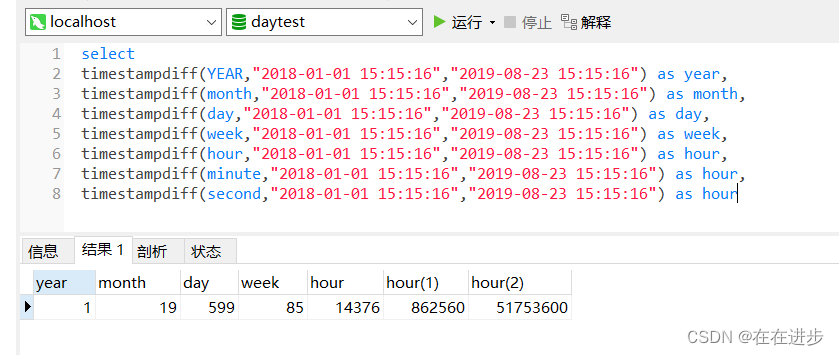
1.4近三个月未完成试卷数为0的用户完成情况

我的代码:思路是这样,报错是必然的
# 先按照uid划分,找出都完成了的,
select uid,
rank()over(partition by uid order by start_time) exam_complete
from exam_record
group by uid
having count(start_time) = count(submit_time) #不对,这样不是每个uid的count# 再按照时间划分,找出3个以上的
select uid,
count(exam_complete) exam_complete_cnt
from
(select uid,
rank()over(partition by uid order by start_time) exam_complete
from exam_record
group by uid
having count(start_time) = count(submit_time))a
where exam_complete_cnt>3大佬代码:发现这个答案和我的好像,我再改改
select uid,count(start_time) as exam_complete_cnt
from(select *,dense_rank() over(partition by uid order by date_format(start_time,'%Y%m') desc) as rankingfrom exam_record) a
where ranking <= 3 -- 这里也不能用where ranking <= 3 and submit_time is not null,而要将用户分组后,用having判断
group by uid
having count(score) = count(uid)
order by exam_complete_cnt desc, uid desc我的代码改正:
select uid,
count(start_time) as exam_complete_cnt
from
(select *, #后面要用到start_time和submit_time,select也要用到uid,用*全部返回吧
dense_rank()over(partition by uid order by date_format(start_time,"%Y%m") desc) ranking
from exam_record)a
where ranking <=3 #把前面3个月的都要进行计数
group by uid
having count(start_time) = count(submit_time)
order by exam_complete_cnt desc, uid desc复盘:
(1)这里不能用rank,加引号也不行,难道是和函数名重复了?改为ranking就好了
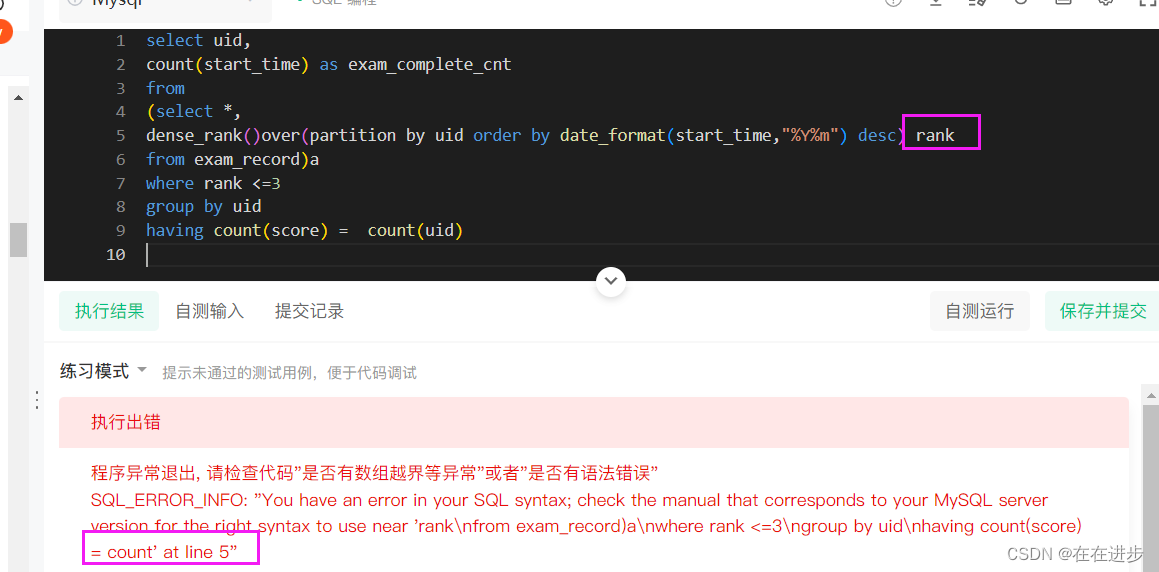
(2)窗口函数,等着二刷吧,有点小难
1.5未完成率较高的50%用户近三个月答卷情况
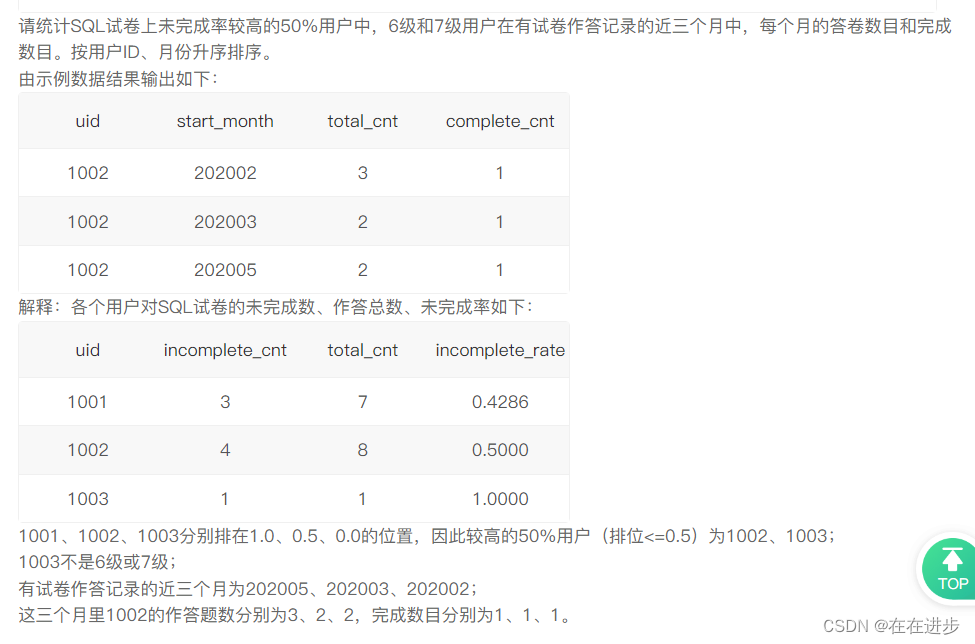
我的代码:思路是这样,报错是必然的
# 先筛选出SQL试卷上,未完成率较高的50%用户,6级和7级用户
select *,count(er.submit_time)/count(er.start_time) complete_rate,
rank()over(partition by u.uid order by complete_rate) ranking
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
join user_info u on u.uid = er.uid
group by u.uid
having ei.tag = 'SQL' and u.level in (6,7) and ranking<0.5
# 子表用户在有试卷作答记录的近三个月中,每个月的答卷数目和完成数目
# 完整代码:
select
uid,
start_month,
count(start_time) total_cnt,
count(submit_time) complete_cnt
from(select *,count(er.submit_time)/count(er.start_time) complete_rate,
rank()over(partition by u.uid order by complete_rate) ranking,
dense_rank()over(partition by uid order by date_format(submit_time,"%Y%m") desc) rankingmonth
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
join user_info u on u.uid = er.uid
group by u.uid
having ei.tag = 'SQL' and u.level in (6,7) and ranking<0.5)a
where rankingmonth <=3
group by date_format(submit_time,"%Y%m")大佬代码:好牛,我啥时候能这个水平
# 第一步,先找出未完成率前50%高的用户ID,注意这里需要的sql试卷
with rote_tab as
(select t.uid,t.f_rote,row_number()over(order by t.f_rote desc,uid) as rank2
,count(t.uid)over(partition by t.tag)as cnt
from (select er.uid,ef.tag,(sum(if(submit_time is null,1,0))/count(start_time)) as f_rote
from exam_record er left join examination_info ef
on ef.exam_id=er.exam_id
where tag='SQL'
group by uid ) t)select #第四步,分用户和月份进行数据统计;同时需要注意,统计的试卷数是所有类型的,不是之前仅有SQL类型uid,start_month,count(start_time) as total_cnt,count(submit_time) as complete_cnt
from
(
select # 第三步,利用窗口函数对每个用户的月份进行降序排序,以便找出最近的三个月;uid,start_time,submit_time,date_format(start_time,'%Y%m') as start_month,dense_rank()over(partition by uid order by date_format(start_time,'%Y%m') desc) as rank3
from exam_record
where uid in (select distinct er.uidfrom exam_record er left join user_info uf on uf.uid=er.uidwhere er.uid in (select uid from rote_tab #引用公用表 rote_tabwhere rank2<=round(cnt/2,0))and uf.level in (6,7)) # 第二步,进一步找出满足等级为6或7的用户ID
) t2
where rank3<=3
group by uid,start_month
order by uid,start_month
2聚合窗口函数
2.1 对试卷得分做min-max归一化
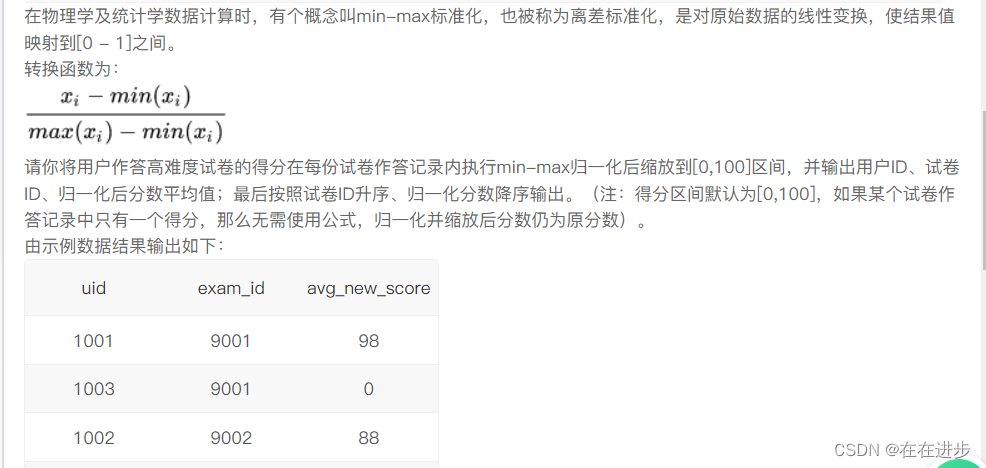
我的报错代码:(得分区间默认为[0,100],如果某个试卷作答记录中只有一个得分,那么无需使用公式,归一化并缩放后分数仍为原分数)这个怎么筛选出去呀
select er.uid,er.exam_id,
(score-min(score))/(max(score)-min(score)) avg_new_score
from examination_info ei join exam_record er
using(exam_id)
where difficulty = 'hard'
group by er.uid,er.exam_id
order by er.uid desc,avg_new_score desc大佬代码:
# 第一步先求出高难度试卷的最值max_min_tab
with max_min_tab as
(select er.uid,er.exam_id,er.score,max(er.score)over(partition by er.exam_id) as max_score,min(er.score)over(partition by er.exam_id) as min_score
from exam_record er
left join examination_info ef on er.exam_id=ef.exam_id
where score is not null and difficulty='hard')select uid,exam_id, #第三步进行取平均值和排序
round(avg(new_score)) as avg_new_score
from
(select uid,exam_id
,if(max_score!=min_score,(score-min_score)/(max_score-min_score)*100,score) as new_score
from max_min_tab) t # 第二步在max_min_tab中进行归一化计算,并用if排除只有一个分数的
group by exam_id,uid
order by exam_id,avg_new_score desc复盘:
(1)最值窗口函数:不是直接max,min再后面分组
max(er.score)over(partition by er.exam_id) as max_score,
min(er.score)over(partition by er.exam_id) as min_score
(2)用if来排除只有一个分数的情况
if(max_score!=min_score,(score-min_score)/(max_score-min_score)*100,score
2.2每份试卷每月作答数和截止当月的作答总数。
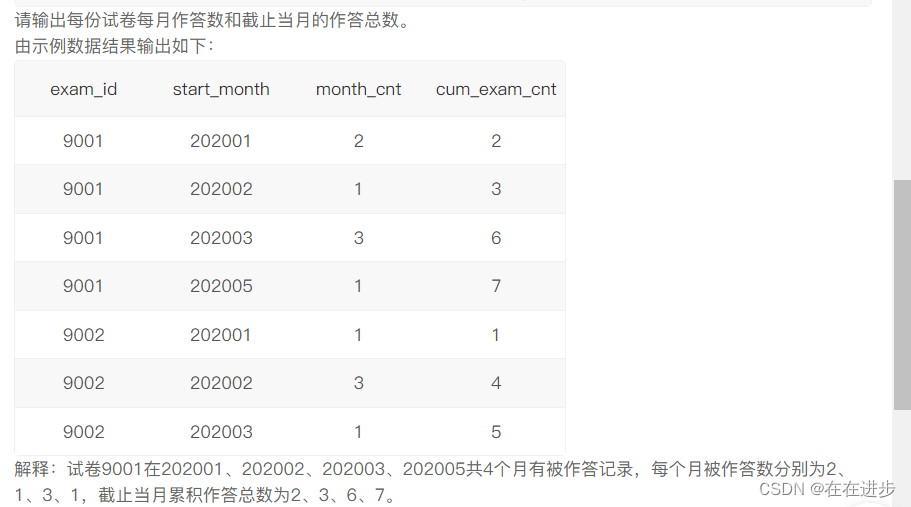
我的代码:
select exam_id,
date_format(submit_time,"%Y%m") start_month,
count(submit_time)over(partition by exam_id) month_cnt,
count(submit_time)over(partition by exam_id) cum_exam_cnt #应该要用偏移分析函数
from exam_record大佬代码:
select distinct exam_id,
date_format(start_time,'%Y%m') start_month,
count(start_time)over(partition by exam_id,date_format(start_time,"%Y%m")) month_cnt,
count(start_time)over(partition by exam_id order by date_format(start_time,'%Y%m')) cum_exam_cnt
from exam_record
order by exam_id,start_month复盘:
(1)要distinct exam_id,如果不去重 exam_id,那么同 exam_id和同月会被输出原文件中exam_id和同月配套出现那么多次。
如:
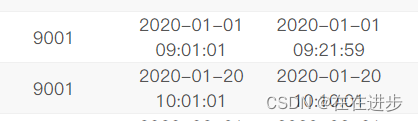
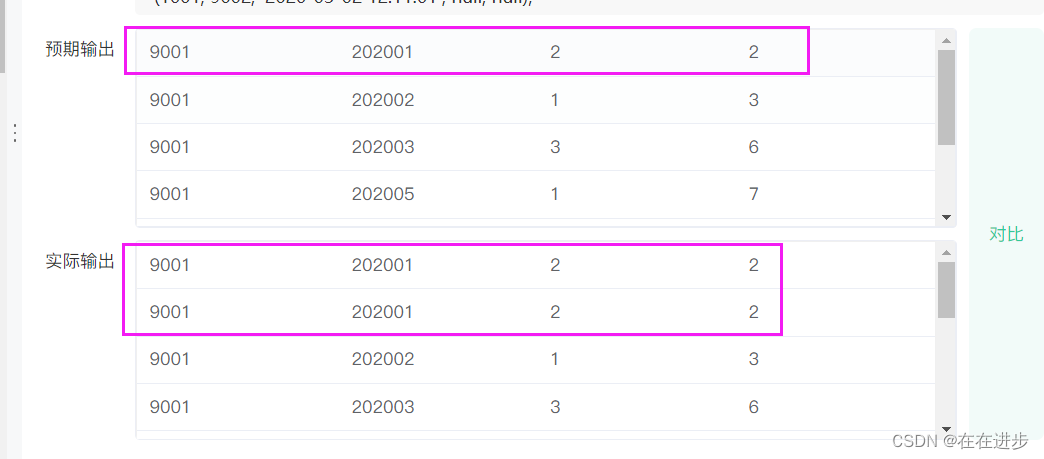
又如:
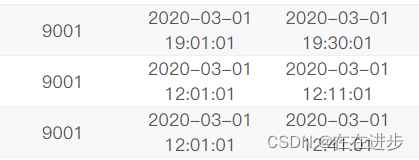
(2)是start_time而不是submit_time,start_time有记录才表明有作答
2.3 每月及截止当月的答题情况
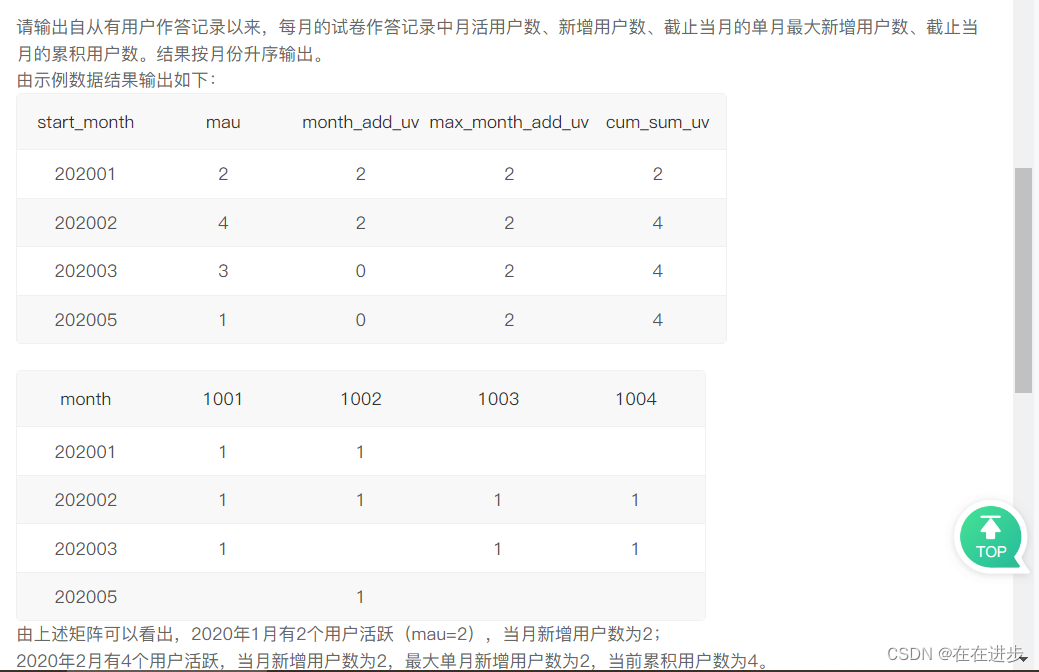
我的代码:后面三个没有整出来
select
distinct date_format(start_time,'%Y%m') start_month,
count(uid)over(partition by date_format(start_time,'%Y%m')) mau,
# if(count>0,count,0) month_add_uv,
# max(month_add_uv)over(partition by date_format(start_time,'%Y%m')) max_month_add_uv,
# max(mau)over() cum_sum_uv
from exam_record
group by uid,start_month
order by start_month
大佬代码:
select start_month
, count(distinct uid) as mau
, count(if(rn=1, uid, null)) as month_add_uv
, max(count(if(rn=1, uid, null))) over(order by start_month) as max_month_add_uv
, sum(count(if(rn=1, uid, null))) over(order by start_month) as cum_sum_uv
from (selectuid, date_format(start_time, '%Y%m') as start_month, row_number() over(partition by uid order by start_time) as rnfrom exam_record
) t
group by start_month
;复盘:
(1)【排序窗口函数】
● rank()over()——1,1,3,4
● dense_rank()over()——1,1,2,3
● row_number()over()——1,2,3,4
这里使用 row_number()over()就只有一个1,那么如果uid有排名为1的,就表示是这个月的新用户。
(2)
- SQL查询语句语法结构和运行顺序
- 运行顺序:from--where--group by--having--order by--limit--select
- 语法结构:select--from--where--group by--having--order by--limit
这篇关于SQL进阶day11——窗口函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



