本文主要是介绍(面试官问我微服务与naocs的使用我回答了如下,面试官让我回去等通知)微服务拆分与nacos的配置使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
微服务架构
正常的小项目就是所有的功能集成在一个模块中,这样代码之间不仅非常耦合,而且修改处理的时候也非常的麻烦,应对高并发时也不好处理,所以 我们可以使用微服务架构,对项目进行模块之间的拆分,每一个微服务负责一部分的业务功能,处理也比较方便。
springcolud 集成了微服务的很多组件,可以达到我们对微服务的使用
微服务拆分原则
我们对项目拆分是有原则的,比如一个小项目,我们前期可以先写出来,然后后期慢慢拆分,但是如果是大项目刚开始就设计好了微服务,那么我们就可以在项目开始进行微服务的拆分
微服务拆分的时候各个模块需要 高内聚,低耦合
拆分方法
拆分的时候 可以 使用完全解耦的拆分,就是每个微服务项目都是一个独立的工程,项目完全解耦,但是管理比较麻烦
还可以使用maven聚合的拆分,维护方便,但是服务之间耦合,编译比较耗时
maven聚合形式如何拆分 就是把不同功能模块的代码抽取到一个新模块中去 例如如下情况

服务之间调用
假如说 我们现在有一个购物车接口,访问路径是 /cart/search ,那么我们微服务之间进行调用,就可以 在调用方配置resttemplate 配置,然后进行远程调用
具体代码实现如下
package com.hmall.cart.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;@Configuration
public class RemoteCallConfig {@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}private void handleCartItems(List<CartVO> vos) {// TODO 1.获取商品idSet<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());// 2.查询商品// List<ItemDTO> items = itemService.queryItemByIds(itemIds);// 2.1.利用RestTemplate发起http请求,得到http的响应ResponseEntity<List<ItemDTO>> response = restTemplate.exchange("http://localhost:8081/items?ids={ids}",HttpMethod.GET,null,new ParameterizedTypeReference<List<ItemDTO>>() {},Map.of("ids", CollUtil.join(itemIds, ",")));// 2.2.解析响应if(!response.getStatusCode().is2xxSuccessful()){// 查询失败,直接结束return;}List<ItemDTO> items = response.getBody();if (CollUtils.isEmpty(items)) {return;}// 3.转为 id 到 item的mapMap<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));// 4.写入vofor (CartVO v : vos) {ItemDTO item = itemMap.get(v.getItemId());if (item == null) {continue;}v.setNewPrice(item.getPrice());v.setStatus(item.getStatus());v.setStock(item.getStock());}
}但是你每次这样调用 都要写一遍,这是不是显的太过冗余,太过麻烦,所以我们引用了接下来的组件 nacos
nacos
nacos是alibaba的一个组件,具体的下载配置流程就不再赘述,
下面我们进行一个场景的分析,现在有一个购物车服务 cartservice ,然后还有一个商品服务 itemservice,我们是查看购物车的时候需要访问商品服务,当我们的用户一多,并发量上来的时候商品服务这个 模块有可能就会承受不住崩溃,所以我们可以多开几个启动实例,进行负载均衡的配置,可是当我们访问的这几个不同的实例的时候,我们该怎么访问这些实例呢?
于是就有了nacos
nacos注册中心原理
当我们配置好nacos之后,我们的实例的端口号 就会发送给nacos注册中心 ,当我们服务的调用者进行调用的时候,具体的服务端口号就从nacos中进行拉取。但是当我们注册到几个实例到nacos中,假如有一些实例变更了,上传错误怎么办,nacos会有一个心跳检测,服务会定期像nacos中发送自己状态也就是心跳请求证明自己健康,当nacos长时间收不到服务提供者的心跳的时候,会认为该实例宕机,从实例列表中剔除,而服务列表变更,nacos主动通知服务调用着,更新本地服务列表

nacos使用
我们下载好nacos之后,在数据库配置好nacos的对应数据表,在nacos的custom.env文件中配置好自己ip地址,然后访问http://xxxxxx:8848/nacos/ 这个xxx如果是虚拟机填虚拟机的ip如果是本机就填本机ip就可以。
然后就会有如下页面
然后我们在商品服务 itemservice中引入pom依赖
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>在商品服务的yml文件中配置
spring:application:name: item-service # 服务名称cloud:nacos:server-addr:xxxxx:8848 # nacos地址xxxx为IP地址,
然后我们拷贝多个实例
点击复制,然后
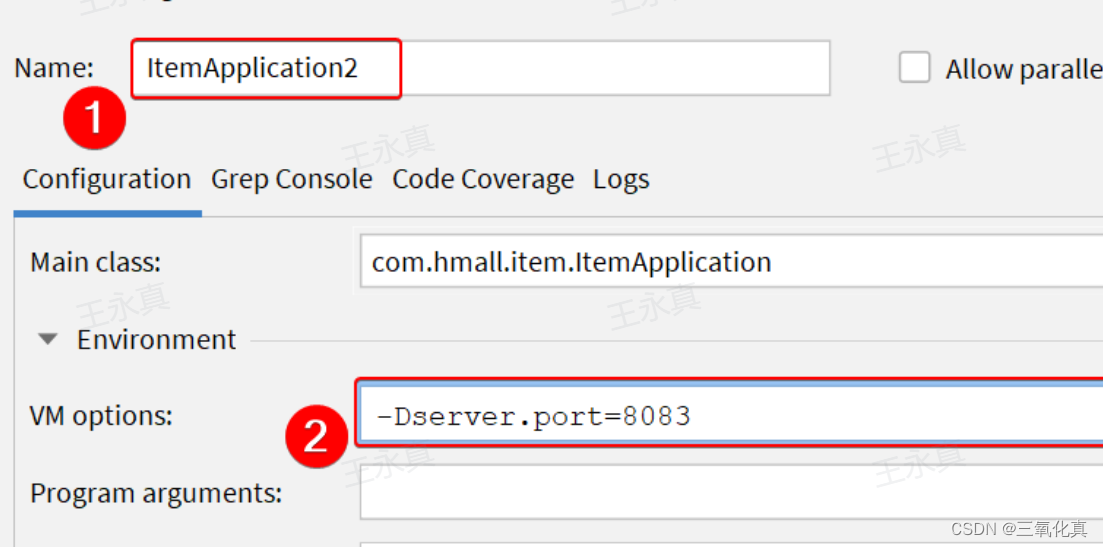 配置好不同的端口,启动实例,就可以在nacos中看到服务上传的实例
配置好不同的端口,启动实例,就可以在nacos中看到服务上传的实例
服务发现
而我们想调用上传的服务,也就是说购物车服务调用商品服务上传的实例
我们需要在购物车服务配置服务发现在购物车服务中yml文件中添加
spring:cloud:nacos:server-addr: xxx:8848引入依赖
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>这个配置好,也就是说购物车服务也会被注册为nacos服务,既可以被调用,也可以被调用
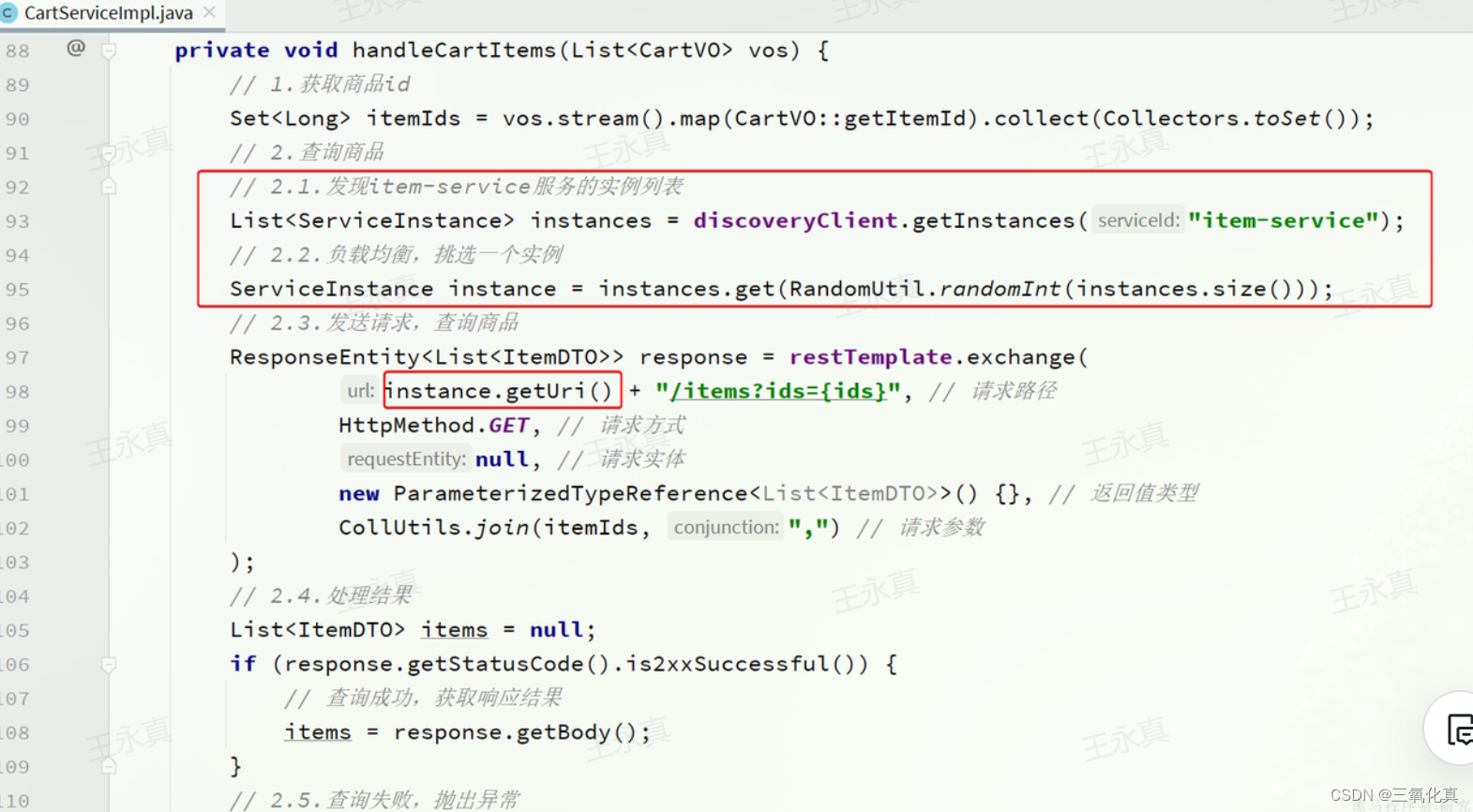
 我们在service注册该bean ,然后使用如下方法调用
我们在service注册该bean ,然后使用如下方法调用
这篇关于(面试官问我微服务与naocs的使用我回答了如下,面试官让我回去等通知)微服务拆分与nacos的配置使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








