本文主要是介绍MySQL使用Mycat实现读写分离,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一,Mycat下载
http://www.mycat.io/是Mycat的官方网站,到这个网站可以进行Mycat的下载,在官网还可以下载《Mycat权威指南》pdf的电子档,下载Mycat的源码。目前最新稳定的Mycat版本是Mycat1.6, Mycat有window,linux,unix,mac平台对应的版本,我这里也使用下载的是window下的1.6版本来实现读写分离。进行读写分离需要先进行主从复制,关于主从复制。二,Mycat的安装
Window下的安装:MyCAT使用Java开发,因为用到了JDK 7的部分功能,所以在使用前请确保安装了JDK 7.0,要求是JDK 7.0以 上,并设置了正确的Java环境变量。
我下载的是免安装版Mycat-server-1.6-RELEASE-20161028204710-win.tar.gz,解压到任意磁盘目录,注意目录不能有中文和空格。我的解压目录为:D:\programing,在mycat的目录中主要有bin,lib,conf,logs目录。
Linux环境下的安装:
1)在linux下环境下安装好jdk,jdk需要1.7以上。2) 下载Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz,这是linux的版本,在/usr/local目录下进行解压得到mycat目录。
3) 开放8066端口和9066端口
firewall-cmd --zone=public --add-port=8066/tcp --permanent
firewall-cmd --permanent --zone=public --add-port=8066/udp
firewall-cmd –reload
三,修改mycat的配置文件
1)修改配置conf/server.xml文件,该文件是Mycat的主配置文件。<user name="mycat">
<property name="password">mycat</property>
<property name="schemas">TESTDB</property>
</user>
user标签是给mycat添加一个用户,name是这个用户的名字,password是密码,schemas是这个用户下的逻辑数据库,多个逻辑数据库可以用“,”逗号隔开。可以通过navicat premium的客户端使用这个user配置的信息连接mycat。注意mycat默认的普通连接端口是8066,管理连接端口是9066。
2)修改schema.xml文件,代码如下:
- <?xml version="1.0"?>
- <!DOCTYPE mycat:schema SYSTEM "schema.dtd">
- <mycat:schema xmlns:mycat="http://io.mycat/">
- <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
- </schema>
- <dataNode name="dn1" dataHost="localhost1" database="first_db" />
- <!--<dataNode name="dn2" dataHost="localhost1" database="db2" />
- <dataNode name="dn3" dataHost="localhost1" database="db3" />
- <dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
- <dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
- <dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
- <dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
- <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
- writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
- <heartbeat>select user()</heartbeat>
- <!-- can have multi write hosts -->
- <writeHost host="hostM1" url="192.168.9.161:3306" user="root"
- password="root">
- <!-- can have multi read hosts -->
- <readHost host="hostS2" url="192.168.9.163:3306" user="root" password="root" />
- </writeHost>
- </dataHost>
- </mycat:schema>
schema:mycat的逻辑数据库
dataNode:节点
dataHost:节点对应的读库写库的地址和连接
balance="1" :实现读写分离
dbDriver="native" :表示使用什么方式连接mysql,这里采用mysql的协议进行连接,可以选择jdbc,这时候就需要把java的mysql驱动包放到mycat的lib目录下面,否则不能连接mysql
关于上面的参数的详细配置的意思可以参考mycat权威指南:下载地址:http://www.mycat.io/
3)修改 wrapper.conf文件
主要修改下面这一行代码:
# Java Application
wrapper.java.command=/usr/local/jdk1.8.0_131/bin/java
四,测试
1,我是在cenos7下面安装的解压配置的mycat,进行测试之前需要先启动mycat,
进入mycat的bin目录下:cd mycat/bin
linux下面使用./mycat start 命令启动mycat;使用 ./mycat stop停止mycat
mycat的日志在logs目录下面,包含了启动的信息和连接的信息
确保成功,启动mycat
2,在安装了mysql客户端的机器使用下面的命令通过mycat访问mysql:
mysql -umycat -p -h192.168.9.161 -P8066
ip是安装了mycat的机器的ip,端口是mycat的端口,用户是mycat的server.xml里面的配置,mycat用户,密码也是mycat密码
能够正确登入说明mycat安装成功了,是进行读写分离的前提。
3,第二步使用命令操作不方便使,现在我们用navicat premium登入mycat,输入ip,端口,用户名和密码,需要linux开启8066端口9066端口远程访问。
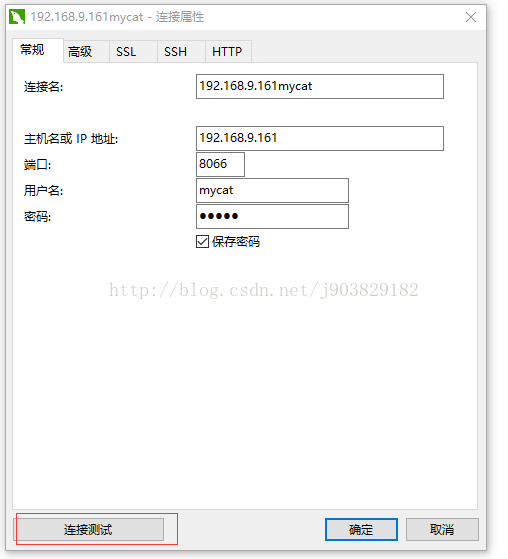
点击连接测试,成功以后在点击确定即连接mycat成功了。
4,测试步骤:
1)关闭主从同步stop slave;
2)往mycat插入一条数据,提交刷新
3)观察刚插入的数据,发现mycat并没查看到这条数据
4)观看主库,发现主库有这条通过mycat添加的数据
5)观看从库,发现从库没有通过mycat添加的数据
6)开启从数据库主从同步start slave;
7)通过从库查看发现有刚新添加的数据
8)通过mycat查看发现也有这条刚添加的数据
这篇关于MySQL使用Mycat实现读写分离的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




