本文主要是介绍Mybatis03-ResultMap及分页,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、属性名和字段名不一致问题
1.问题
数据库中的字段
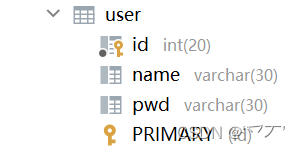
新建一个项目Mybatis-04,拷贝之前,测试实体类字段不一致的情况
public class User {private int id;private String name;private String password;
}
select * from mybatis.user where id =#{id}
-- 等效于 类型映射器
select id,name,pwd from mybatis.user where id =#{id}
-- 此时已经没有pwd
测试结果:password字段为空
问题原因:实体类的属性名和数据库的字段名不同
解决方法1:起别名
<select id="getUserById" parameterType="int" resultType="com.qjd.pojo.User">select id,name,pwd as password from mybatis.user where id =#{id}
</select>
解决方法2:使用结果集映射->ResultMap 【推荐】
<resultMap id="UserMap" type="User"><!-- id为主键 --><id column="id" property="id"/><!-- column是数据库表的列名 , property是对应实体类的属性名 --><result column="name" property="name"/><result column="pwd" property="password"/>
</resultMap>
<select id="selectUserById" resultMap="UserMap">select id , name , pwd from user where id = #{id}
</select>
2、ResultMap ——结果(集)映射(xml映射文件中配置)
在UserMapper.xml的元素中添加
<!--结果集映射-->
<resultMap id="UserMap" type="com.kuang.pojo.User"><!--column:数据库中的字段;property:实体类中的属性--><!-- <result column="id" property="id"/>--><!-- <result column="name" property="name"/>--><result column="pwd" property="password"/>
</resultMap><!--修改resultType为resultMap(两者不能同时使用)-->
<select id="getUserById" parameterType="int" resultMap="UserMap">select * from user where id=#{id}
</select>-
resultMap 元素是 MyBatis 中最重要最强大的元素
-
ResultMap 的设计思想是,对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了
-
MyBatis 会在幕后自动创建一个 ResultMap,再根据属性名来映射列到 JavaBean 的属性上。
-
在之前的学习中resultMap都是被隐式创建的,因此需保证实体类的属性名和数据库的列名或列别名对应相同
-
select、update、insert、delete中的属性可以使用 resultType 或 resultMap,但不能同时使用。
回顾方法:
-
新建一个mybatis-04模块:
-
在src/main/resources路径下建立mybatis-config.xml文件建立核心配置文件
-
在src/main/java/com/qjd/utils路径下编写工具类MybatisUtils.java读取配置文件获取sqlsessionfactory
-
在src/main/java/com/qjd/pojo路径下编写实体类User.java
-
在src/main/java/com/qjd/dao路径下编写接口UserMapper.java和UserMapper.xml
-
编写测试类
3、日志Log
<setting name="logImpl" value=""/>(核心配置文件的<settings>中配置)
日志工厂
- 如果一个数据库操作出现了异常,我们需要排错。日志就是最好的助手!
- 曾经:debug、sout
- 现在:日志工厂
value属性只能为以下值:
- SLF4J
- LOG4J 【掌握】
- LOG4J2
- JDK_LOGGING
- COMMONS_LOGGING
- STDOUT_LOGGING【掌握】
- NO_LOGGING
1.STDOUT_LOGGING——标准的日志工厂实现
在核心配置文件中配置日志实现
<settings><!--标准的日志工厂实现--><setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
2.Log4j
什么是LOG4J
-
Log4j是Apache的一个开源项目
-
通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件
-
我们可以控制每一条日志的输出格式;
-
通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
-
通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
1.导入log4j的maven依赖
<!-- https://mvnrepository.com/artifact/log4j/log4j --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency>
2.在CLAASSPATH下新建log4j.properties文件(resource目录下),编写log4j.properties文件
### 配置根 ###
log4j.rootLogger = debug,console,file### 配置输出到控制台 ###
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold = debug
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern = %d{ABSOLUTE} %5p %c{1}:%L - %m%n### 配置输出到文件 ###
log4j.appender.file = org.apache.log4j.FileAppender
log4j.appender.file.File = ./log/qjd.loglog4j.appender.file.Append = true
log4j.appender.file.Threshold = debuglog4j.appender.file.layout = org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n### 配置输出到文件,并且每天都创建一个文件 ###
log4j.appender.dailyRollingFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.dailyRollingFile.File = logs/log.log
log4j.appender.dailyRollingFile.Append = true
log4j.appender.dailyRollingFile.Threshold = debug
log4j.appender.dailyRollingFile.layout = org.apache.log4j.PatternLayout
log4j.appender.dailyRollingFile.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n### 设置输出sql的级别,其中logger后面的内容全部为jar包中所包含的包名 ###
log4j.logger.org.mybatis=debug
log4j.logger.java.sql=debug
log4j.logger.java.sql.Connection=debug
log4j.logger.java.sql.Statement=debug
log4j.logger.java.sql.PreparedStatement=debug
log4j.logger.java.sql.ResultSet=debug
3.在核心配置文件中配置日志实现
<settings><setting name="logImpl" value="LOG4J"/></settings>
4.运行刚才的测试
Log4j的简单使用
1.在要使用log4j的类中导入Apache的包
import org.apache.log4j.Logger;
2.日志对象,参数为当前类的class
static Logger logger = Logger.getLogger(UserDaoTest.class);
3.使用日志级别
@Test
public void testLog4j(){//相当与sout,但输出的日志级别不同logger.info("info:进入testLog4j");logger.debug("debug:进入了testLog4j");logger.error("error:进入了testLog4j");
}控制台输出:(日志文件中也会添加以下输出)
21:07:25,697 INFO UserDaoTest:63 - info:进入testLog4j
21:07:25,702 DEBUG UserDaoTest:64 - debug:进入了testLog4j
21:07:25,702 ERROR UserDaoTest:65 - error:进入了testLog4j5、测试,
-
看控制台输出!
-
使用Log4j 输出日志 可以看到还生成了一个日志的文件 【需要修改file的日志级别】
4、分页查询
limit实现分页
思考:为什么需要分页?
- 在学习mybatis等持久层框架的时候,会经常对数据进行增删改查操作,使用最多的是对数据库进行查询操 作,如果查询大量数据的时候,我们往往使用分页进行查询,也就是每次处理小部分数据,这样对数据库压 力就在可控范围内。
使用Limit实现分页
#语法
SELECT * FROM table LIMIT stratIndex,pageSize
SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
#为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
#如果只给定一个参数,它表示返回最大的记录行数目:
SELECT * FROM table LIMIT 5; //检索前 5 个记录行
#换句话说,LIMIT n 等价于 LIMIT 0,n。
-
UserMapper接口(方法的参数为Map)
/*** 分页查询用户* @param map* @return*/ List<User> getUserByLimit(Map<String,Object> map); -
xml映射文件
<select id="getUserByLimit" resultMap="UserMap" parameterType="map">select * from users limit #{startIndex},#{pageSize} </select> -
测试
@Testpublic void getUserByLimit(){SqlSession sqlSession = MybatisUtils.getSqlSession();UserMapper mapper = sqlSession.getMapper(UserMapper.class);HashMap<String,Integer> hashMap=new HashMap<>();hashMap.put("startIndex",1);hashMap.put("pageSize",2);List<User> userList = mapper.getUserByLimit(hashMap);for (User user : userList) {System.out.println(user);}sqlSession.close();}输出: User{id=2, name='张三', password='892457'} User{id=3, name='李四', password='784728'}
RowBounds分页
我们除了使用Limit在SQL层面实现分页,也可以使用RowBounds在Java代码层面实现分页,当然此种方式 作为了解即可。我们来看下如何实现的
步骤:
1、mapper接口
//选择全部用户RowBounds实现分页
List<User> getUserByRowBounds();
2、mapper文件
<select id="getUserByRowBounds" resultType="user">select * from user
</select>
3、测试类
在这里,我们需要使用RowBounds类
@Test
public void getUserByRowRounds(){SqlSession sqlSession = MybatisUtils.getSqlSession();//RowBounds实现分页RowBounds rowBounds = new RowBounds(1, 2);List<User> userList=sqlSession.selectList("com.kuang.dao.UserMapper.getUserByRowBounds",null,rowBounds);for (User user : userList) {System.out.println(user);}sqlSession.close();
}输出:
User{id=2, name='张三', password='892457'}
User{id=3, name='李四', password='784728'}分页插件【了解】
MyBatis 分页插件 PageHelper
如何使用----PageHelper
ist(“com.kuang.dao.UserMapper.getUserByRowBounds”,null,rowBounds);
for (User user : userList) {
System.out.println(user);
}
sqlSession.close();
}
输出:
User{id=2, name=‘张三’, password=‘892457’}
User{id=3, name=‘李四’, password=‘784728’}
##### 分页插件【了解】MyBatis 分页插件 PageHelper如何使用----[PageHelper](https://pagehelper.github.io/docs/howtouse/)
这篇关于Mybatis03-ResultMap及分页的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




