本文主要是介绍编译原理——引论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语言处理器
编译器(compiler):阅读以某一种语言(源语言)编写的程序,并把该程序翻译成为一个等价的、用另一种语言(目标语言)编写的程序。编译器的重要任务之一是报告它在翻译过程中发现的源程序中的错误。
解释器(interpreter):另一种常见的语言处理器。它并不通过翻译的方式生成目标程序。从用户的角度看,解释器直接利用用户提供的输入执行源程序中指定的操作。
在把用户输入映射成输出的过程中,由一个编译器产生的机器语言目标程序通常比一个解释器快很多。然而,解释器的错误诊断效果通常比编译器好,因为它逐个语句地执行源程序。
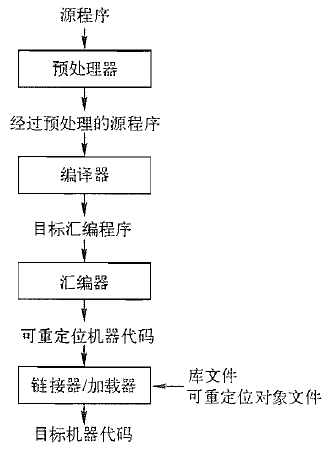
一个源程序可能被分割成多个模块,并存放在独立的文件中。把源程序聚合在一起的任务有时会由一个被称为预处理器(preprocessor)的程序独立完成。预处理器还负责把那些成为宏的缩写形式转换为源语言的语句。
然后,将经过预处理的源程序作为输入传递给一个编译器。编译器可能产生一个汇编语言程序作为其输出,因为汇编语言比较容易输出和调试。接着,这个汇编语言程序由称为汇编器(assembler)的程序进行处理,并生成可重定位的机器代码。
大型程序经常被分成多个部分进行编译,因此,可重定位的机器代码有必要和其他可重定位的目标文件以及库文件连接到一起,形成真正在机器上运行的代码。一个文件中的代码可能指向另一个文件中的位置,而链接器(linker)能够解决外部内存地址的问题。最后,加载器(loader)把所有的可执行目标文件放到内存中执行。
一个编译器的结构
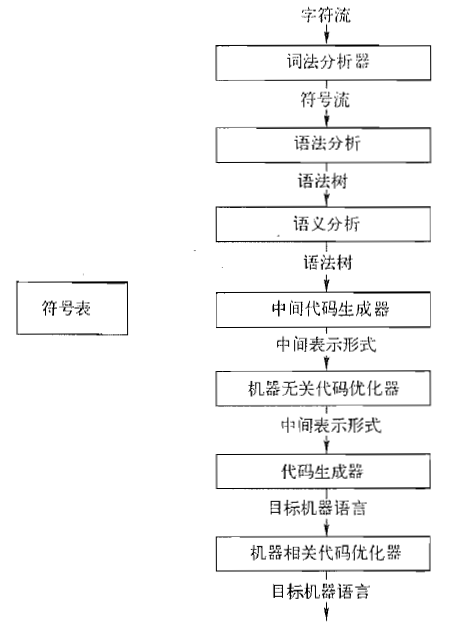
分析(analysis)部分部分把源程序分解成为多个组成要素,并在这些要素之上加上语法结构。然后它使用这个结构来创建该源程序的一个中间表示。分析部分会收集有关源程序的信息,并把信息存放在一个成为**符号表(symbol table)的数据结构中。符号表和中间表示形式一起传送给综合部分。
综合(synthesis)部分根据中间表示和符号表中的信息来构造用户期待的目标程序。分析部分经常被称为编译器的前端(front end),而综合部分被称为后端(back end)。
编译过程顺序执行了一组步骤(phase)。每个步骤把源程序的一种表示形式转换成另一种表示形式。一个典型的把编译程序分解成为多个步骤的方式如下图所示。在实践中,多个不走可能被组合在一起,而这些组合在一起的中间步骤之间的中间表示不需要明确地构造出来。存放整个源程序的信息的符号表可由编译器的各个步骤使用。
词法分析
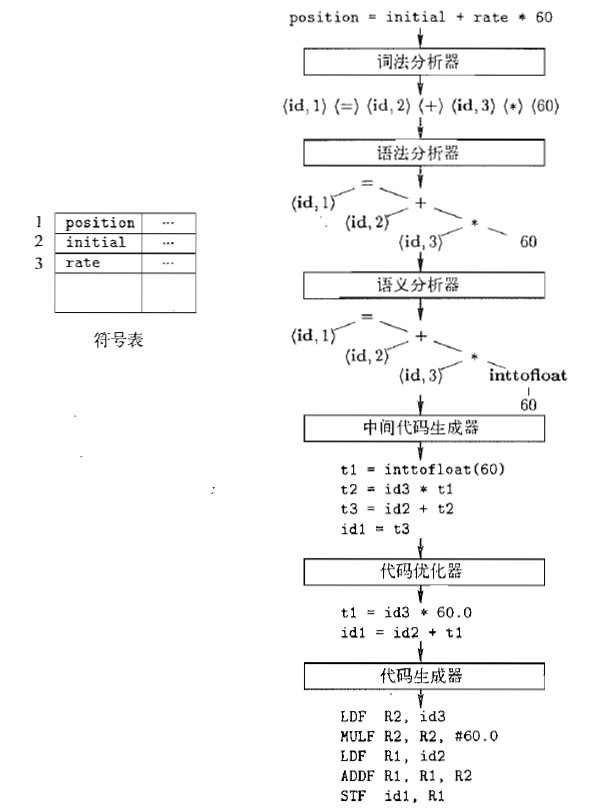
编译器的第一个步骤成为词法分析(lexical analysis)或扫描(scanning)。词法分析器读物组成源程序的字符流,并且将它们组织成为有意义的词素(lexeme)的序列。对于每个词素,词法分析器产生如下形式的词法单元(token)作为输出:
<token-name, attribute-value>
第一个分量token-name是一个由词法分析步骤使用的抽象符号,而二个分量attribute-value指向符号表中关于这个词法单元的条目。符号表条目的信息会被语义分析和代码生成步骤使用。
比如,赋值语句:
position = initial + rate * 60
经过词法分析之后被表示成如下的词法单元序列
<id, 1> < = > <id, 2> < + > <id, 3> < * > <60>
语法分析
编译器的第二个步骤称为语法分析(syntax analysis)或解析(parsing)。语法分析器使用由词法分析器生成的各个词法单元的第一个分量来创建树形的中间表示。该中间表示给出了词法分析产生的词法单元流的语法结构。一个常用的表示方法是语法树(syntax tree),树中的每个内部结点表示一个运算,而该结点的子节点表示该运算的分量。
语义分析
语义分析器(semantic analyzer)使用语法树和符号表中的信息来检查源程序是否和语言定义的语意一致。它同时也收集类型信息,并把这些信息存放在语法树或符号表中,以便在随后的中间代码生成过程中使用。
语意分析的一个重要部分是类型检查(type checking)。编译器检查每个运算符是否具有匹配的运算分量。
程序设计语言可能允许某些类型转换,这被称为自动类型转换(coercion)。
中间代码生成
在把一个源程序翻译成目标代码的过程中,一个编译器可能构造出一个或多个中间表示。这些中间表示可以有多种形式。语法树是一种中间表示形式,它们通常在语法分析和语义分析中使用。该中间表示应该具有两个重要的性质:它应该易于生成,且能够被轻松地翻译为目标机器上的语言。
代码优化
机器无关的代码优化步骤试图改进中间代码,以便更好的生成目标代码。“更好”通常意味着更快,但是也有可能会有其他目标,如更短的或能耗更低的目标代码。
代码生成
代码生成器以源程序的中间表示形式作为输入,并把它映射到目标语言。如果目标语言是机器代码,那么就必须为程序使用的每个变量选择寄存器或内存位置。然后,中间指令被翻译成为能够完成相同任务的机器指令序列。
符号表管理
编译器的重要功能之一是记录源程序中使用的变量的名字,并收集和每个名字的各种属性有关的信息。这些属性可以提供一个名字和存储分配、它的类型、作用域等信息。对于过程名字,这些信息还包括:它的参数数量和类型、每个参数的传递方法(比如传值或传引用)以及返回类型。
符号表数据结构为每个变量名字创建了一个记录条目。记录的字段就是名字的各个属性。这个数据结构应该允许编译器迅速查找到每个名字的记录,并向记录中快速存放和获取记录中的数据。
将多个步骤组合成趟
前面关于步骤的讨论讲的是一个编译器的逻辑组成方式。在一个特定的实现中,多个步骤的活动可以被组合成一趟(pass)。每趟读入一个输入文件并产生一个输出文件。
编译器构造工具
一些常用的编译器构造工具包括:
- 语法分析器的生成器:根据一个程序设计语言的语法描述自动生成语法分析器。
- 扫描器的生成器:可以根据一个语言的语法单元的正则表达式描述生成词法分析器。
- 语法制导的翻译引擎:可以生成一组用于遍历分析树并生成中间代码的例程。
- 代码生成器的生成器:依据一组关于如何把中间语言的每个运算翻译成为目标机上的机器语言的规则,生成一个代码生成器。
- 数据流分析引擎:可以帮助收集数据流信息,即程序中的值如何从程序的一个部分传递到另一部分。数据流分析是代码优化的一个重要部分。
- 编译器构造工具集:提供了可用于构造编译器的不同阶段的例程的完整集合。
总结
- 语言处理器:一个集成的的软件开发环境,其中包括很多种类的语言处理器,比如编译器、解释器、汇编器、连接器、加载器、调试器以及程序概要提取工具。
- 编译器的步骤:一个编译器的运作需要一系列的步骤,每个步骤把源程序从一个中间表示转换成为另一个中间表示。
- 机器语言和汇编语言:机器语言是第一代程序设计语言,然后是汇编语言。使用这些语言进行编程既费时,又容易出错。
- 编译器设计中的建模:编译器设计是理论对实践有很大影响的领域之一。已知在编译器设计中有用的模型包括自动机、文法、正则表达式、树形结构和很多其他理论概念。
- 代码优化:虽然代码不能真正达到最优化,但提高代码效率的科学既复杂又非常重要。它是编译技术研究的一个主要部分。
- 高级语言:随着时间的流逝,程序设计语言担负了越来越多的原先由程序员负责的任务,比如内存管理、类型一致性检查或代码的并发执行。
- 编译器和计算机体系结构:编译器技术影响了计算机的体系结构,同时也收到体系结构发展的影响。体系结构中的很多现代创新都依赖于编译器能够从源程序中抽取出有效利用硬件能力的机会。
- 软件生产率和软件安全性:使得编译器能够优化代码的技术同样能够用于多种不同的程序分析任务。这些任务既包括探测常见的程序错误,也包括发现程序可能会受到已被黑客们发现的多种入侵方式之一的伤害。
- 作用域规则:一个
x的声明的作用域是一段上下文,在此上下文中对x的使用指向声明。如果仅仅通过阅读某个语言的程序就可以确定其作用域,那么这个语言就使用了静态作用域,或者说词法作用域。否则这个语言就使用了动态作用域。 - 环境:名字和内存位置关联,然后再和值相关联。这个情况可以使用环境和状态来描述,其中环境把名字映射成为存储位置,而状态把位置映射到它的值。
- 块结构:允许语句块相互嵌套的语言成为块结构的语言,假设一个块中有一个
x的声明D,而嵌套于这个块中的块B中有一个对名字x的使用。如果这两个块之间没有其他声明了x的块,那么这个x的使用位于D的作用域内。 - 参数传递:参数可以通过值或引用的方式从调用过程传递给被调用过程。当通过值传递方式传递大型对象时,实际被传递的值是指向这些对象本身的引用。这样就变成了一个高效的引用调用。
- 别名:当参数被以引用传递方式(高效地)传递时,两个形式参数可能会指向同一个对象。这会造成一个变量的修改改变了另一个变量的值。
这篇关于编译原理——引论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









