本文主要是介绍Redisson 分布式锁 - RLock、RReadWriteLock、RSemaphore、RCountDownLatch(配置、使用、原理),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
Redisson 分布式锁
环境配置
1)版本说明
2)依赖如下
3)配置文件如下
4)项目配置
RLock
1)使用方式
2)加锁解释
3)加锁时手动设置时间
4)加锁时,到底要不要手动设置过期时间?(最佳实践)
RReadWriteLock
1)使用方式
2)加锁原理
RSemaphore
1)使用方式
2)信号原理
RCountDownLatch
1)使用方式
2)原理解释
前言
前面讲过一篇 Redisson 分布式锁的底层原理,而这篇文章着重实战,因此对原理不清楚的,可以看看我之前的文章:http://t.csdnimg.cn/LU5ED
Redisson 分布式锁
环境配置
1)版本说明
- SpringBoot:3.2.5
- Redisson:3.25.0
2)依赖如下
<!-- <dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-data-redis</artifactId>-->
<!-- </dependency>--><!--redisson 依赖整合了 StringRedisTemplate,因此 data redis 依赖就可以删除了--><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.25.0</version></dependency>
3)配置文件如下
spring: data:redis:host: env-baseport: 6379
Ps:实际上还有一种配置方式就是自己配置 RedissonClient 的 Bean,注入给容器
4)项目配置
分布式锁带来的效果演示,会通过 jmeter 来进行测试. 服务这边会先通过 网关,在负载均衡到集群的实例上. 因此这里我们来配置一下集群的每个实例信息.

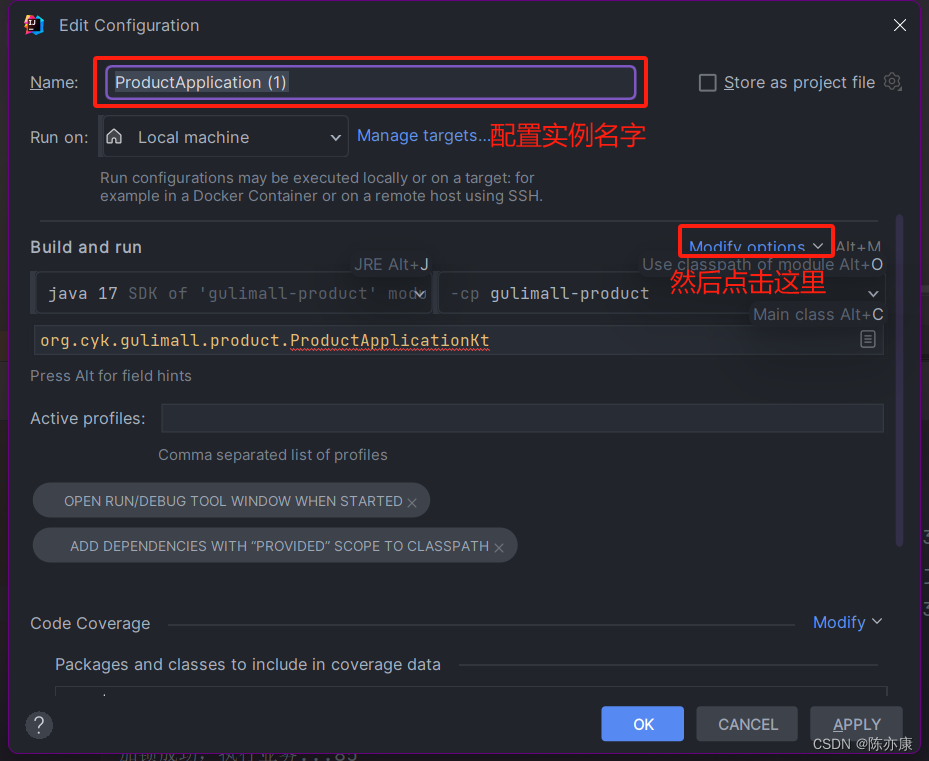
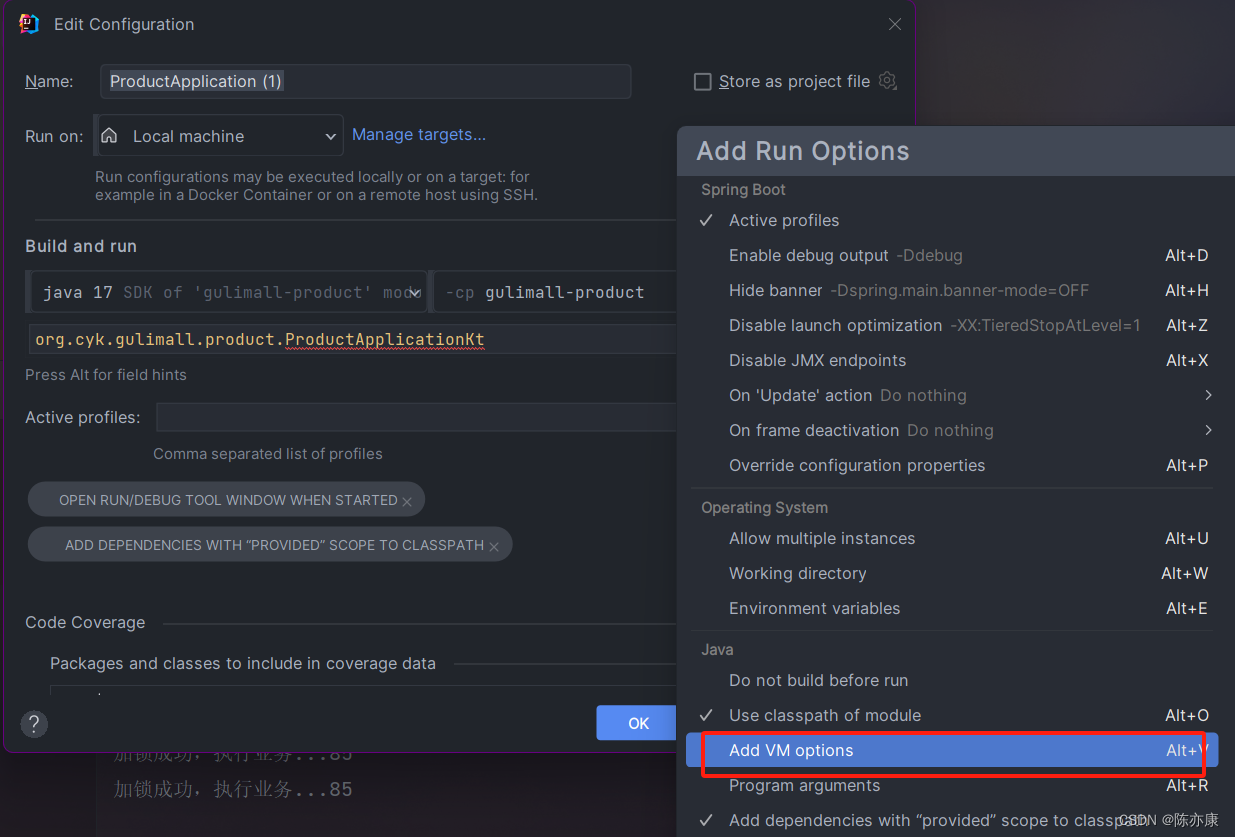

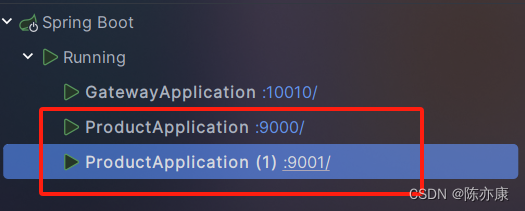
这里为了方便观察,准备了两个实例:
RLock
1)使用方式
如果使用的 Redisson 的 Boot Starter 依赖的话,只需要在 yml 按照本文配置,然后在需要的地方注入 RedissionClient 即可使用(非 Boot Starter 依赖需要自己配置 RedissonClient).
@RestController
@RequestMapping("/product/lock")
class Test(private val redisson: RedissonClient
) {@GetMapping("/test1")fun test1(): String {//1.获取一把锁,只要名字一样,就是同一把锁val lock: RLock = redisson.getLock("my-lock")//2.加锁lock.lock()try {println("加锁成功,执行业务..." + Thread.currentThread().id)Thread.sleep(10000) //模拟耗时任务} catch (e: Exception) {e.printStackTrace()} finally {//3.解锁lock.unlock()println("解锁成功!" + Thread.currentThread().id)}return "ok!"}}
Ps:除此之外,还有 redisson 的 ReentrantLock 中还提供了 tryLock() 方法有以下两种重载方式
- boolean tryLock():尝试加锁,如果当前锁被占用,则直接放弃并返回 false.
- boolean tryLock(long time, TimeUnit unit):如果当前锁被占用,则会等待,知道到达我们设置的过期时间 time 还没拿到锁,就放弃并返回 false.
2)加锁解释
a)RLock 就类似于 JUC 中的 ReentrantLock,是一个可重入锁(同一个线程对同一个资源连续加锁两次不会死锁).
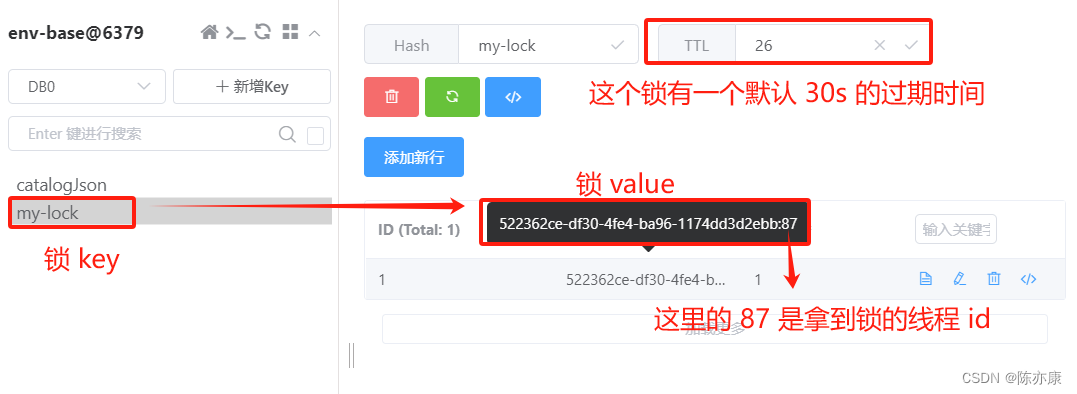
b)加锁实际上就是在 redis 上添加了一个 key-value,并且默认加锁的过期时间为 30s,如下图:
c)如果业务处理实践比默认加锁时间长怎么办?这里会有一个看门狗机制,只要拿到锁,就会开启一个定时任务,每隔 10s 就会自动续约. 因此不用担心业务时间长的问题.
d)如果代码还没有执行到解锁,程序就挂了,会不会死锁?不会的,锁是有默认的过期时间,即使没有执行到解锁逻辑,锁也会自动删除.(这里我自己测试了一下,貌似新版的 Redisson 中会检测程序是否挂了,如果挂了,就会把这个锁立即删除掉)
3)加锁时手动设置时间
a)使用如下:
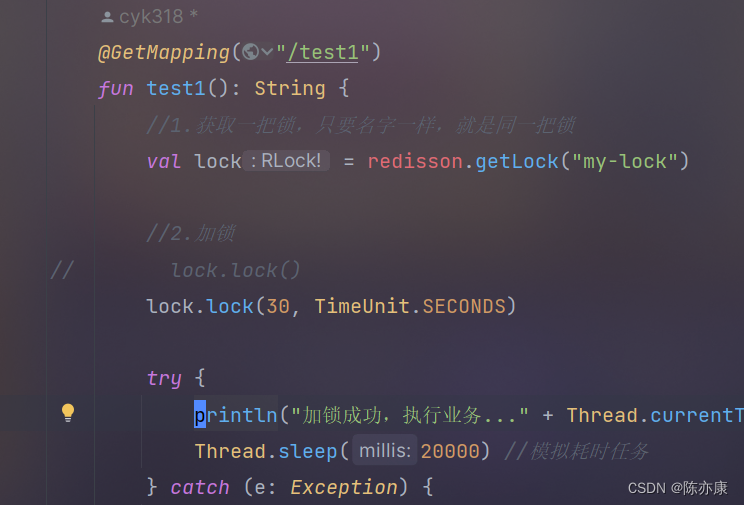
b)注意:
如果我们手动指定了过期时间,那么即使业务没有执行完,也不会自动续约. 也就是说,无论如何,到期自动解锁.
4)加锁时,到底要不要手动设置过期时间?(最佳实践)
a)最佳实践:
使用 lock.lock(30, TimeUnit.SECONDS) 手动设置 30s 过期时间.
b)原因:
如果我们手动设置过期时间,就省掉了续约的操作(有一定的开销).
再者,真的会有某一个业务逻辑需要执行 30s 的时间么?如果真的有,这个程序大概率是出问题了. 到了 30s 后解锁,反而还避免了 “死等” 问题.
RReadWriteLock
1)使用方式
a)写操作(写锁)
@GetMapping("/write")fun write(): String {val rwLock: RReadWriteLock = redisson.getReadWriteLock("rw-lock")var result = ""//1.获取写锁val wLock = rwLock.writeLock()//2.写操作用写锁,读操作用读锁wLock.lock()try {Thread.sleep(10000)result = UUID.randomUUID().toString()redisTemplate.opsForValue().set("uuid", result)} catch (e: Exception) {e.printStackTrace()} finally {wLock.unlock()}return "ok! uuid: $result"}
b)读操作(读锁)
@GetMapping("/read")fun read(): String {val rwLock: RReadWriteLock = redisson.getReadWriteLock("rw-lock")var result: String? = ""//1.获取读锁val rLock = rwLock.writeLock()//2.写操作用写锁,读操作用读锁rLock.lock()try {result = redisTemplate.opsForValue().get("uuid")} catch (e: Exception) {e.printStackTrace()} finally {rLock.unlock()}return "ok! uuid: $result"}
Ps:读锁,写锁 这里也额外提供了 tryLock() 方法,来尝试加锁(原理上面讲过)
2)加锁原理
读写锁保证了读操作和读操作之间不会加锁,而读操作和其他任何操作都会加锁. 使得在读多写少的业务场景中,效率大大提升.
Redission 提供的 ReadWriteLock 也是这个原理:
- 读 + 读: 读操作和读操作之间不会出现脏数据问题,因此相当于无锁,只会在 redis 中记录当前读锁,他们都会同时加锁成功.
- 写 + 读:如果先写,此时紧接着又进行读操作,可能出现脏数据的问题,因此会阻塞等待写锁释放.
- 写 + 写:写操作和写操作之间可能出现脏数据问题,因此也是阻塞等待.
- 读 + 写:由于你读的时候,另一个线程又来写,也会出现脏数据的问题,因此也必须要阻塞等待读锁释放.
RSemaphore
1)使用方式
@GetMapping("/park")fun park(): String {//这里的 RSemaphore 就相当于是一个停车场,刚开始的没有车位(初始信号量为 0)val park: RSemaphore = redisson.getSemaphore("park")//1.获取一个信号,相当于占了一个停车位,车位 - 1park.acquire()//2.执行业务//...return "park ok!"}@GetMapping("/go")fun go(): String {val park = redisson.getSemaphore("park")//1.释放一个信号,相当于让出了一个车位,车位 + 1park.release()return "go ok!"}
Ps:这里也有一个额外的方法 tryAcquire(),尝试申请资源
2)信号原理
a)redisson.getSemaphore("park") 这里实际上就是在 redis 上添加一个 key-value,key 就是我们自定义的 "park" 字符串,value 就是信号量,初始情况下为 0.
b)情况分析:
情况一:刚开始的时候如果 线程A 进行 acquire(),由于信号量为 0,只能阻塞等待. 接着如果有 线程B 进行 release(),就会释放一个信号量,也就是信号量 + 1,此时 线程A 发现有一个信号来了,他就直接消费掉了
情况二:刚开始的时候如果 线程A 进行 release(),此时信号量 + 1,总共信号量为 1,接着如果有线程B 来进行 acquire() ,就会直接消费掉这个信号,此时信号量 - 1,总共信号量为 0.
Ps:信号量也可以做分布式限流
RCountDownLatch
1)使用方式
例如有 5 个选手比赛,要求所有选手到达终点之后才可以宣布比赛结束.
@GetMapping("/match")fun match(): String {val match = redisson.getCountDownLatch("match")//1.设置计数器的初始值为 5 (想象成有 5 名选手赛跑)match.trySetCount(5)//2.等待所有资源全被消费 (等待 5 名选手全部跑完)match.await()return "比赛结束!"}@GetMapping("/gogogo/{id}")fun gogogo(@PathVariable("id") id: Long): String {val match = redisson.getCountDownLatch("match")//1.计数器 - 1 (一名选手到达终点)match.countDown()return "选手 $id 号到达终点!"}
2)原理解释
a)redisson.getCountDownLatch("match") 这里实际上就是给 redis 存了一个 key-value,key 就是我们自定义的 "match" 字符串,value 就是计数器.
b)match.trySetCount(5) 就是给这个计数器设置了一个初始值为 5.
c)match.await() 会一直阻塞住,直到计数器的值减为 0.
d)match.countDown() 让计数器 - 1.

这篇关于Redisson 分布式锁 - RLock、RReadWriteLock、RSemaphore、RCountDownLatch(配置、使用、原理)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







