本文主要是介绍Linux三剑客(grep、awk、sed)超详细版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0 引言
Linux的用户都知道,在Linux下一切皆文件,所以Linux下的操作就是对文件的操作。出于对文件更好的操作,下面给大家介绍一下常用的文本操作“三剑客”命令。
1 详细介绍
(1) grep
- 简介:文本过滤工具,用于查找文件里符合条件的字符串
- 语法:
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...] - 可选参数:
-a 或 --text : 不要忽略二进制的数据。 -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。 -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。 -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。 -c 或 --count : 计算符合样式的列数。 -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。 -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。 -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。 -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。 -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。 -F 或 --fixed-regexp : 将样式视为固定字符串的列表。 -G 或 --basic-regexp : 将样式视为普通的表示法来使用。 -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。 -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。 -i 或 --ignore-case : 忽略字符大小写的差别。 -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。 -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。 -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。 -o 或 --only-matching : 只显示匹配PATTERN 部分。 -q 或 --quiet或--silent : 不显示任何信息。 -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。 -s 或 --no-messages : 不显示错误信息。 -v 或 --invert-match : 显示不包含匹配文本的所有行。 -V 或 --version : 显示版本信息。 -w 或 --word-regexp : 只显示全字符合的列。 -x --line-regexp : 只显示全列符合的列。 -y : 此参数的效果和指定"-i"参数相同。 - 范例
测试文本,以/etc/passwd为例

-
匹配含有root的行

-
匹配以nobody开头的行

-
匹配以root或nobody开头的行

-
显示是输出行号

-
匹配非root开头的行,并显示行号

-
显示匹配到的内容的行数

-
多文件匹配,在匹配结果前面加上文件名

(2) awk
- 简介:强大的文本分析工具
- 语法:
awk [选项参数] 'script' var=value file(s) 或 awk [选项参数] -f scriptfile var=value file(s) - 可选参数:
-F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 -v var=value or --asign var=value 赋值一个用户定义变量。 -f scripfile or --file scriptfile 从脚本文件中读取awk命令。 -mf nnn and -mr nnn 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 -W compact or --compat, -W traditional or --traditional 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 -W copyleft or --copyleft, -W copyright or --copyright 打印简短的版权信息。 -W help or --help, -W usage or --usage 打印全部awk选项和每个选项的简短说明。 -W lint or --lint 打印不能向传统unix平台移植的结构的警告。 -W lint-old or --lint-old 打印关于不能向传统unix平台移植的结构的警告。 -W posix 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。 -W re-interval or --re-inerval 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 -W source program-text or --source program-text 使用program-text作为源代码,可与-f命令混用。 -W version or --version 打印bug报告信息的版本。 - 范例
- 显示/etc/passwd中包含root的行

- 以 : 分割,显示passwd的每行的第一个字段和第七个字段

- 以 : 分割,筛选以/root开头,显示结果每行的第一个字段和第七个字段

- 以 : 分割,显示passwd中第三个字段大于999的行的第一个和第七个字段

(3) sed
-
简介:利用脚本来处理文本文件
-
语法:
sed [-hnV][-e<script>][-f<script文件>][文本文件] -
可选参数:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。 -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。 -i直接修改文件内容(危险操作) -h或--help 显示帮助。 -n或--quiet或--silent 仅显示script处理后的结果。 -V或--version 显示版本信息。 -
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚; i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~ s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦! -
范例
- 参数p,打印显示匹配的行
-
打印第12行

-
打印12-18行

-
打印含总行数

- 参数a和i,插入文本或附加文本
- 在含有FTP的行后面添加一行,内容是123

- 在第五行前面添加一行,内容456

- 参数d,删除命令

- 删除data.ttx文件的第五行

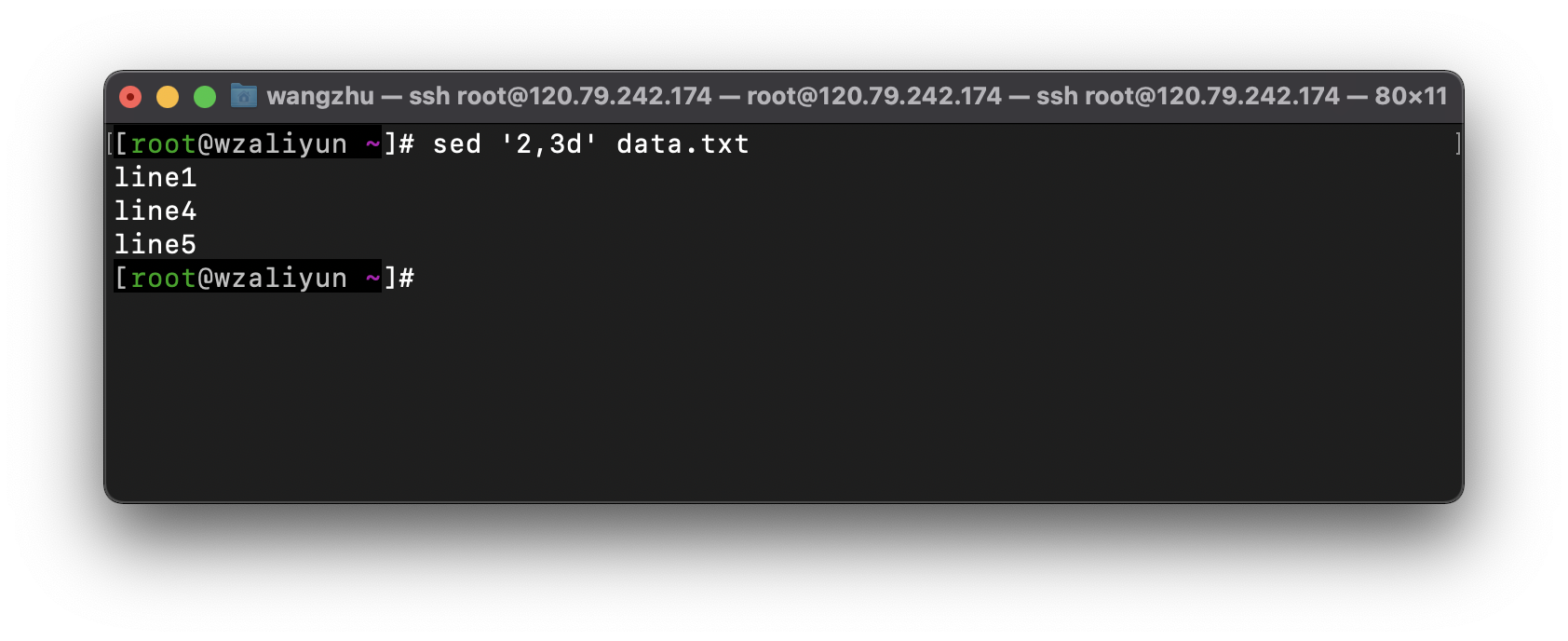
- 删除2-3行
-
参数p,打印命令
- 搜索passwd中含有root关键字的行

- 搜索passwd中含有root关键字的行
-
参数s,替换命令
- 显示本地ip地址

- 显示本地ip地址
2 总结
我们的目标:学好三剑客,走遍天下都不怕!
这篇关于Linux三剑客(grep、awk、sed)超详细版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






