本文主要是介绍android watchdog(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
http://blog.csdn.net/yangwen123/article/details/11264461
在Android系统中,所有的系统服务都运行在SystemServer进程中,如果实时监测系统所有服务是否正常运行呢?Android软 Watchdog就是用来胜任这个工作的,WatchDog的作用:
1).接收系统内部reboot请求,重启系统。2).监护SystemServer进程,防止系统死锁。
Android watchdog类图:

Watchdog本身继承Thread,是一个线程类,监控任务运行在独立的线程中,但是Watchdog线程并没有自己的消息队列,该线程共用SystemServer主线程的消息队列。Watchdog有一个mMonitors成员变量,该变量是一个monitor类型的动态数组,用于保存所有Watchdog监测对象。Monitor定义为接口类型,需要加入Watchdog监控的服务必须实现Monitor接口。HeartbeatHandler类为WatchDog的核心,负责对各个监护对象进行监护。
Watchdog启动
WatchDog是在SystemServer进程中被初始化和启动的。在SystemServer 被Start时,各种Android服务被注册和启动,其中也包括了WatchDog的初始化和启动。
- Slog.i(TAG, "Init Watchdog");
- Watchdog.getInstance().init(context, battery, power, alarm,ActivityManagerService.self());
- Watchdog.getInstance().start();
- public static Watchdog getInstance() {
- if (sWatchdog == null) {
- sWatchdog = new Watchdog();
- }
- return sWatchdog;
- }
- private Watchdog() {
- super("watchdog");
- mHandler = new HeartbeatHandler();
- }
- public void init(Context context, BatteryService battery,
- PowerManagerService power, AlarmManagerService alarm,
- ActivityManagerService activity) {
- mResolver = context.getContentResolver();
- mBattery = battery;
- mPower = power;
- mAlarm = alarm;
- mActivity = activity;
- //注册重启广播接收器
- context.registerReceiver(new RebootReceiver(),new IntentFilter(REBOOT_ACTION));
- mRebootIntent = PendingIntent.getBroadcast(context,0, new Intent(REBOOT_ACTION), 0);
- //注册重启请求广播接收器
- context.registerReceiver(new RebootRequestReceiver(),
- new IntentFilter(Intent.ACTION_REBOOT),
- android.Manifest.permission.REBOOT, null);
- mBootTime = System.currentTimeMillis();
- }
RebootRequestReceiver负责接收系统内部发出的重启Intent消息,并进行系统重启。
添加监控对象
在启动Watchdog前,需要向其添加监测对象。在Android4.1中有7个服务实现了Watchdog.Monitor接口,即这些服务都可以被Watchdog监控。
ActivityManagerService
InputManagerService
MountService
NativeDaemonConnector
NetworkManagementService
PowerManagerService
WindowManagerService
Watchdog提供了addMonitor方法来添加监控对象
- public void addMonitor(Monitor monitor) {
- synchronized (this) {
- if (isAlive()) {
- throw new RuntimeException("Monitors can't be added while the Watchdog is running");
- }
- mMonitors.add(monitor);
- }
- }
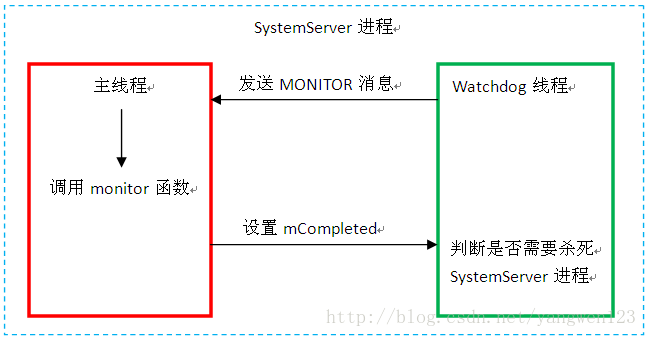
Watchdog监控过程
当调用Watchdog.getInstance().start()将启动Watchdog线程,Watchdog执行过程如下:
- public void run() {
- boolean waitedHalf = false;
- while (true) {
- /**
- * 反复设置mCompleted变量为false
- */
- mCompleted = false;
- /**
- * 发送一个MONITOR消息给心跳HeartbeatHandler处理,处理过程就是调用各个监控对象的monitor函数,
- * 如果各个被监控服务的monitor都顺利返回,心跳HeartbeatHandler会将mCompleted设置为true
- */
- if (mHandler.sendEmptyMessage(MONITOR)) {
- if (WATCHDOG_DEBUG) Slog.v(TAG,"**** -1-Watchdog MSG SENT! ****");
- }
- /**
- * Watchdog线程和SystemServer主线程共用同一个消息队列,为了在两个线程中改变mCompleted的值,这里必须使用线程同步机制
- */
- synchronized (this) {
- /**
- * TIME_TO_WAIT的默认时间为30s。此为第一次等待时间,WatchDog判断对象是否死锁的最长处理时间为1Min。
- */
- long timeout = TIME_TO_WAIT;
- /**
- * 获取当前时间
- */
- long start = SystemClock.uptimeMillis();
- /**
- * 等待30秒,等待HeartbeatHandler的处理结果。然后才会进行下一步动作。
- */
- while (timeout > 0 && !mForceKillSystem) {
- try {
- wait(timeout); // notifyAll() is called when mForceKillSystem is set
- } catch (InterruptedException e) {
- Log.wtf(TAG, e);
- }
- timeout = TIME_TO_WAIT - (SystemClock.uptimeMillis() - start);
- }
- /**
- * 如果所有监控对象在30s内能够顺利返回,则会得到mCompleted = true;
- */
- if (mCompleted && !mForceKillSystem) {
- /**
- * 设置waitedHalf的值为false,表示SystemServer中被监测的服务对象运行正常
- */
- waitedHalf = false;
- continue;//则本次监控结束,返回继续下一轮监护。
- }
- /**
- * waitedHalf在监测对象运行正常时,一直被设置为false,只有当Watchdog监测到服务对象运行异常时才
- * 会被设置为true,因此在上一个30s周期内监测到服务对象运行异常,同时在本次30s周期内,waitedHalf
- * 没有重新设置为false,说明本周期内服务运行依然异常,就直接杀死SystemServer进程
- */
- if (!waitedHalf) {
- ArrayList<Integer> pids = new ArrayList<Integer>();
- pids.add(Process.myPid());
- /**
- * dump进程堆栈信息,将堆栈信息保存到/data/anr/traces.txt文件,同时dump出mediaserver,
- * sdcard,surfaceflinger这三个native进程的堆栈信息,并发送进程退出信号
- */
- ActivityManagerService.dumpStackTraces(true, pids, null, null,NATIVE_STACKS_OF_INTEREST);
- SystemClock.sleep(3000);
- /**
- * RECORD_KERNEL_THREADS初始值为true,则dump出内核堆栈信息
- */
- if (RECORD_KERNEL_THREADS) {
- dumpKernelStackTraces();
- SystemClock.sleep(2000);
- }
- /**
- * 设置waitedHalf的值为true,表示心跳HeartbeatHandler在monitor监测对象时,30s内没有顺利完成
- */
- waitedHalf = true;
- /**
- * 则本次监控结束,返回继续下一轮监测.这就说明当第一个30s监测到服务对象运行异常时,只是打印进程堆栈信息,
- * 并不会杀死SystemServer进程
- */
- continue;
- }
- }
- /**
- * 若紧接着的下一轮监护,在30s内,monitor对象依旧未及时返回,直接运行到这里。这表示系统的监护对象有死锁现象发生,
- * SystemServer进程需要kill并重启。
- */
- final String name = (mCurrentMonitor != null) ?mCurrentMonitor.getClass().getName() : "null";
- Slog.w(TAG, "*** WATCHDOG IS GOING TO KILL SYSTEM PROCESS: " + name);
- EventLog.writeEvent(EventLogTags.WATCHDOG, name);
- ArrayList<Integer> pids = new ArrayList<Integer>();
- pids.add(Process.myPid());
- if (mPhonePid > 0) pids.add(mPhonePid);
- /**
- * 当Watchdog监测到服务对象运行异常时waitedHalf会被设置为true,这里传递的第一个参数为waitedHalf的取反,表示以追加的方式
- * 将进程堆栈信息保存到trace文件中
- */
- final File stack = ActivityManagerService.dumpStackTraces(
- !waitedHalf, pids, null, null, NATIVE_STACKS_OF_INTEREST);
- /**
- * 睡眠是为了等待完成进程堆栈信息的文件写操作
- */
- SystemClock.sleep(3000);
- if (RECORD_KERNEL_THREADS) {
- dumpKernelStackTraces();
- SystemClock.sleep(2000);
- }
- /**
- * 启动watchdogWriteToDropbox线程写dropbox错误日志
- */
- Thread dropboxThread = new Thread("watchdogWriteToDropbox") {
- public void run() {
- mActivity.addErrorToDropBox("watchdog", null, "system_server", null, null,
- name, null, stack, null);
- }
- };
- dropboxThread.start();
- try {
- dropboxThread.join(2000); // wait up to 2 seconds for it to return.
- } catch (InterruptedException ignored) {}
- /**
- * 杀死SystemServer进程,从而引发Zygote进程自杀,并触发init进程重新启动Zygote进程,以达到手机重启目的
- */
- if (!Debug.isDebuggerConnected()) {
- Slog.w(TAG, "*** WATCHDOG KILLING SYSTEM PROCESS: " + name);
- Process.killProcess(Process.myPid());
- System.exit(10);
- } else {
- Slog.w(TAG, "Debugger connected: Watchdog is *not* killing the system process");
- }
- waitedHalf = false;
- }
- }
- public void handleMessage(Message msg) {
- switch (msg.what) {
- /**
- * 接收到Watchdog线程发送过来的MONITOR消息
- */
- case MONITOR: {
- if (WATCHDOG_DEBUG) Slog.v(TAG, " **** 0-CHECK IF FORCE A REBOOT ! **** ");
- // See if we should force a reboot.
- int rebootInterval = mReqRebootInterval >= 0
- ? mReqRebootInterval : Settings.Secure.getInt(
- mResolver, Settings.Secure.REBOOT_INTERVAL,
- REBOOT_DEFAULT_INTERVAL);
- if (mRebootInterval != rebootInterval) {
- mRebootInterval = rebootInterval;
- // We have been running long enough that a reboot can
- // be considered...
- checkReboot(false);
- }
- if (WATCHDOG_DEBUG) Slog.v(TAG, " **** 1-CHECK ALL MONITORS BEGIN ! **** ");
- /**
- * 依次调用每个被监控的服务对象的monitor函数,以达到监控服务对象是否正常运行的目的
- */
- final int size = mMonitors.size();
- for (int i = 0 ; i < size ; i++) {
- mCurrentMonitor = mMonitors.get(i);
- mCurrentMonitor.monitor();
- }
- if (WATCHDOG_DEBUG) Slog.v(TAG, " **** 2-CHECK ALL MONITORS FINISHED ! **** "); //如果监护的对象都正常,则会很快运行到这里,并对mCompleted赋值为true,表示对象正常返回。mCompleted值初始为false。
- /**
- * 如果在30s内所有的服务对象的monitor函数都能顺利返回,说明服务运行正常,这时就修改mCompleted的值为true
- * 告知Watchdog线程服务的运行状态,由于Watchdog线程周期性地判断mCompleted的值以达到查询服务运行状态的目的,
- * 因此这里必须使用线程同步机制
- */
- synchronized (Watchdog.this) {
- mCompleted = true;
- mCurrentMonitor = null;
- }
- if (WATCHDOG_DEBUG) Slog.v(TAG, " **** 3-SYNC Watchdog.THIS FINISHED ! ****");
- if (WATCHDOG_DEBUG) Slog.v(TAG, " ");
- } break;
- }
- }
- public void monitor() {
- synchronized (this) { }
- }
这篇关于android watchdog(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



