本文主要是介绍minos 1.2 内存虚拟化——guest,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首发公号:Rand_cs
该项目来自乐敏大佬:https://github.com/minosproject/minos
项目来自乐敏大佬:https://github.com/minosproject/minos
本文继续讲述 minos 中的内存虚拟化中关于 guest 的部分,主要弄清楚一个问题,minos 如何管理 guest vm 的内存。
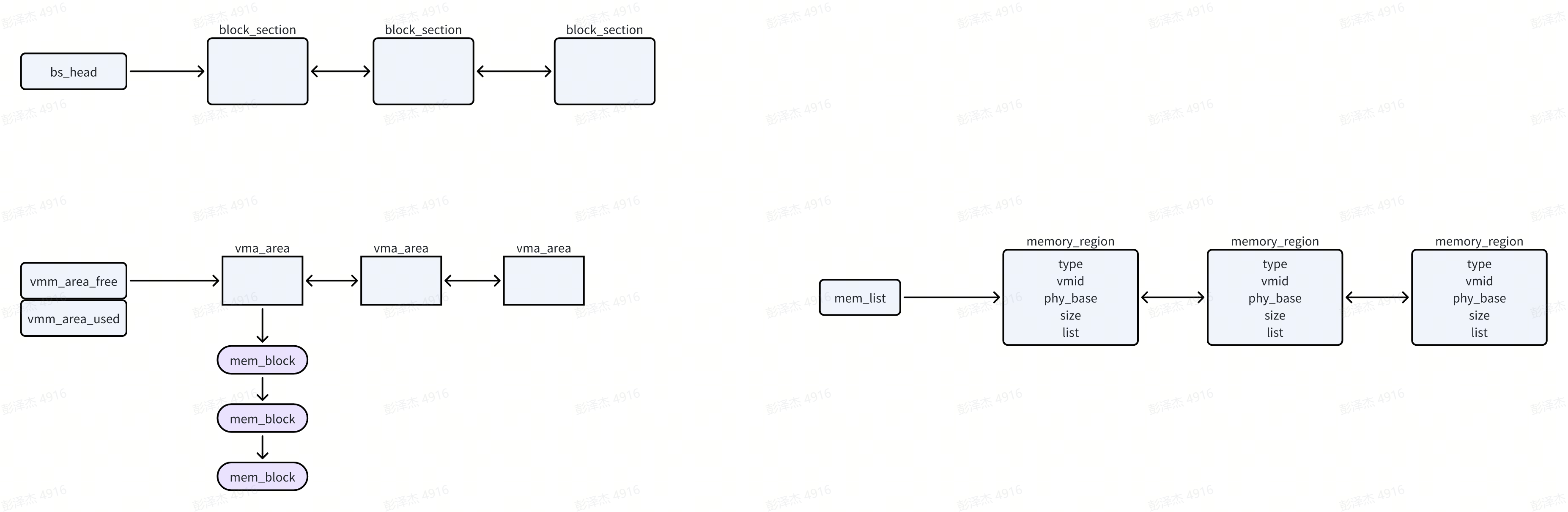
对于虚拟机的内存管理主要是 ipa 的管理,ipa 如何映射到 pa,先来看看虚拟机内存管理在 minos 中的结构体表示
struct vm {...struct mm_struct mm;...
}struct mm_struct {void *pgdp;spinlock_t lock;/** vmm_area_free : list to all the free vmm_area* vmm_area_used : list to all the used vmm_area* lock : spin lock for vmm_area allocate*/struct list_head vmm_area_free;struct list_head vmm_area_used;
};
每一个虚拟机都对应着一个 struct vm 结构体,每一个 vm 又有一个 mm_struct 结构体,我们可以看到 mm_struct 结构体的定义和前文提到的 struct vspace 结构体定义很像。
struct vspace 只有一个实例,host_vspace,里面存放着 hyp 的 pgd 页表地址,代表着 hyp 的虚拟地址空间,这张页表可以将 hyp 层次的虚拟地址转换为实际的物理地址。
而 mm_struct 中记录的 pgd 页表则是 vm stage2 转换需要用到的页表。在 guest os 中,每个进程都有自己的页表,这里我们称之为 stage1 页表,它负责将进程的 Virtual Address 转换为 Intermediate Physical Address(站在guest os 进程的角度这就是物理地址)。每个虚拟机又有一张 stage2 页表,存放在 vm->mm_struct->pgd 中,它负责将 Intermediate Physical Address 再转换为真实的物理地址。
对于虚拟机的内存管理相关图示如下:
minos 中的虚拟机可以分为两大类:
- 一类叫作 native vm(后面我称作 nvm),目前简单理解为由 minos 启动的 vm 就是 native vm(就是在设备树配置文件中设置了一个 vm 描述,minos 启动的时候分析设备树,发现有 vm 节点,就创建该 vm)。host vm (后面称作 hvm)也是 native vm,只不过它的权限更大,可以看作是服务型 vm,它会直接操作大多数物理设备。在 qemu 平台下,这个 vm 也是个 linux。
- 另一类叫做 guest vm(后面称作 gvm),它是由 host vm 通过命令创建的(就是我们登入 hvm,在 hvm 通过命令手动创建一个 vm)
对于 nvm,在物理内存初始化的阶段就已经为其分配了属于它那一份的物理内存。启动阶段,minos 会分析设备树节点,解析 memory 节点,知道了物理内存的始末,将这信息记录到第一个 mem_region 结构体中。随后分析 vm 节点,从中获取 vm.memory 节点信息,获取其始末,然后记录到另一个 mem_region 结构体中。
而对于 gvm,前文中我们提到过 0x4645 a000 ~ 0x4660 0000、0x8660 0000 ~ 0x1 4000 0000 两部分区域内存可以看作是空闲内存,这两部分内存会全部转换成 block 的形式,当创建普通 vm 的时候,就会从中分配内存。
IPA 地址空间
对于 hypervisor 中涉及的各种地址空间有很多,这里再来捋一下:
对于 vm 来说,内核运行在 EL1,运行在内核地址空间,由内核页表映射到物理地址空间。进程运行在 EL0,运行在自己的虚拟地址空间,由进程页表映射到物理地址空间。内核负责管理进程的虚拟地址空间,负责创建进程页表映射页表等操作,并将进程内存相关信息记录在了 task_struct->mm_struct。
对于 minos 来说,运行在 EL2,运行在 minos 的虚拟地址空间,minos 也有一张自己的页表,负责将 minos 自身的一些数据代码映射到物理地址空间。vm 运行在 EL0/EL1,运行在 ipa 地址空间,由 vm 的 stage2 页表映射到实际的物理地址空间。而 minos 负责 vm stage2 页表的创建,映射等操作,并将 vm 内存相关信息记录在了 vm->mm_struct 结构体中
这么一看,其实这种 type1 类型的虚拟机在内存管理方面跟内核极其相似,vm 内核对应 minos,进程对应 vm。
vm 的 ipa 地址空间大小为 1T(40bit),但当然不可能这么大的物理地址空间都有对应的物理内存。
struct mm_struct {void *pgdp;spinlock_t lock;/** vmm_area_free : list to all the free vmm_area* vmm_area_used : list to all the used vmm_area* lock : spin lock for vmm_area allocate*/struct list_head vmm_area_free;struct list_head vmm_area_used;
};
从上述 mm_struct 定义来看,有 free vmm_area 和 used vmm_area 之分,vmm_area 就是一段 ipa 地址空间,used vmm_area 可以看作是有真正物理内存对应的 ipa 地址空间,free vmm_area 反之。对于 vmm_area 的定义如下:
/** pstart - if this area is mapped as continous the pstart* is the phsical address of this vmm_area*/
struct vmm_area {unsigned long start; // ipa 地址——startunsigned long end; // ipa 地址——endunsigned long pstart;int flags;int vmid; /* 0 - for self other for VM */struct list_head list;// 如果分配的内存是 block 形式struct mem_block *b_head;/* if this vmm_area is belong to VDEV, this will link* to the next vmm_area of the VDEV */struct vmm_area *next;
};struct mem_block {uint32_t bfn; // 块号,可以直接转换为物理地址struct mem_block *next;
};
一个 vmm_area 就是一段 ipa 地址空间,对于 vm 来说,就是一段物理内存。start ~ end 就是该段 ipa 地址空间的始末,pstart 表示 start 这个 ipa 对应的 pa。如果分配的物理内存是 block 形式,那么这个 “pstart” 记录在 mem_block 中。
vmm_area 操作集
既然有多个 vmm_area,那必然也涉及到管理的一系列操作,来简单看一看 vmm_area 相关操作集
// 分配一个 vmm_area 结构体,记录 base、size 信息,只是记录信息,没有实际的内存分配
static struct vmm_area *__alloc_vmm_area_entry(unsigned long base, size_t size)
{struct vmm_area *va;va = zalloc(sizeof(struct vmm_area));if (!va)return NULL;va->start = base;// -1(0xfffffffffff),表示未分配映射实际的物理内存va->pstart = BAD_ADDRESS;va->end = base + size;va->flags = 0;return va;
}
这是 vmm_area 结构体分配函数,注意初始化的 pstart 字段,设置为 -1,表示未分配映射实际的物理内存。
// 从 mm->vmm_area_free 所有的 vmm_list 中,找一个合适的 vmm_area,
// 从中切出一个 vmm_area,此 vmm_area 的 start 为 base,end 为 start+size
struct vmm_area *split_vmm_area(struct mm_struct *mm,unsigned long base, size_t size, int flags)
{unsigned long end = base + size;struct vmm_area *va, *out = NULL;if ((flags & VM_NORMAL) && (!IS_PAGE_ALIGN(base) || !IS_PAGE_ALIGN(size))) {pr_err("vm_area is not PAGE align 0x%p 0x%x\n",base, size);return NULL;}spin_lock(&mm->lock);// 遍历 vmm_area_free 中所有 vma 结构体list_for_each_entry(va, &mm->vmm_area_free, list) {// 如果 [base,end] < [start, end],breakif ((base >= va->start) && (end <= va->end)) {out = va;break;}}if (!out)goto exit;// split 参数中的 vmm_area 结构体,建立新的 vmm_area 结构体,插入到 mm->vmm_area_used 链表// 被分割的 vmm_area,其用剩下的,重新插入到 mm->vmm_area_free 链表out = __split_vmm_area(mm, out, base, end, flags);
exit:spin_unlock(&mm->lock);if (!out)pr_err("split vma [0x%lx 0x%lx] failed\n", base, end);return out;
}
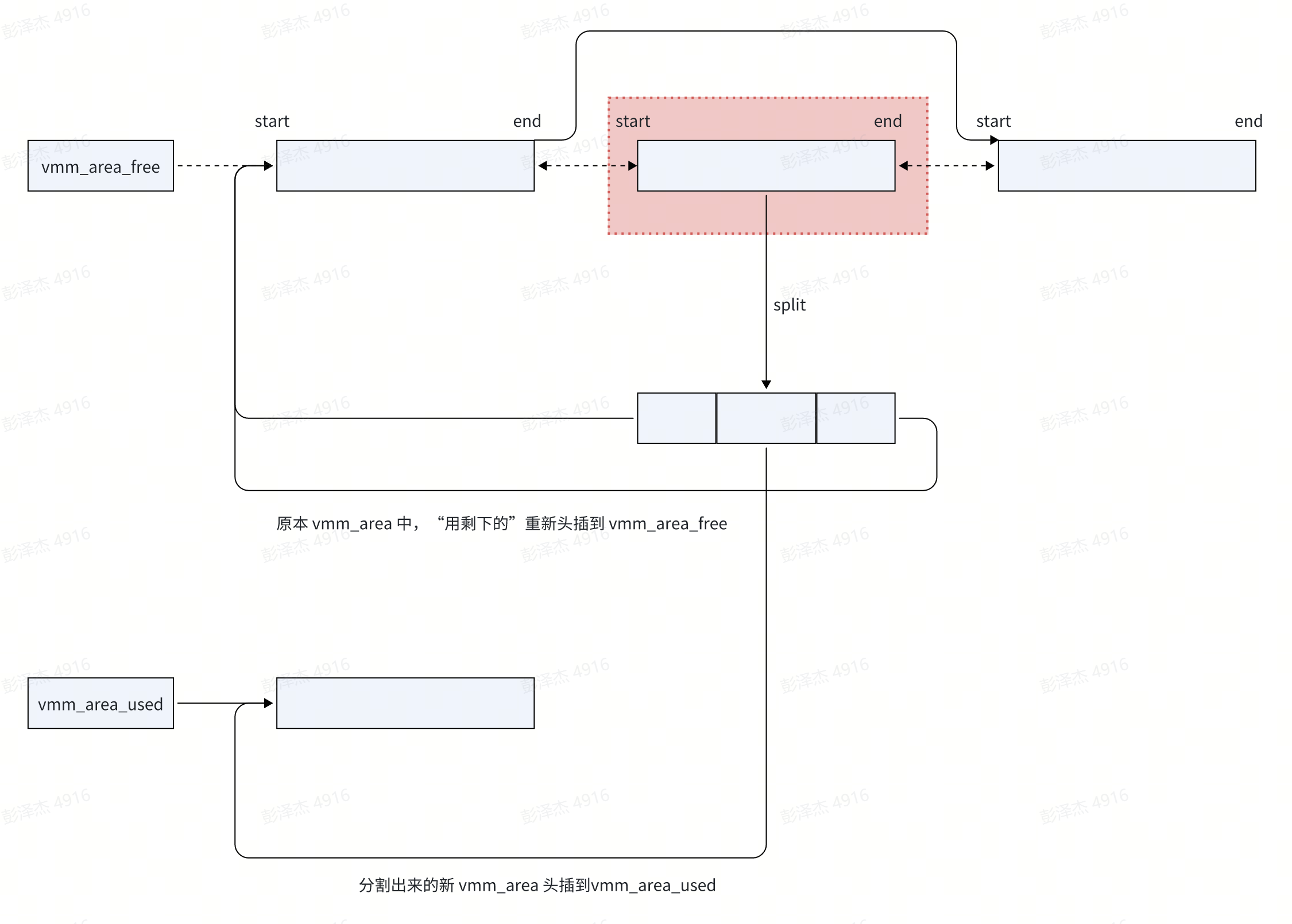
整个过程就是稍微复杂了那么一点的链表操作,仔细看代码图示应该能懂,不再详述
native vm ipa 管理
这一小节讲述 vm ipa 地址空间初始化
int vm_mm_struct_init(struct vm *vm)
{struct mm_struct *mm = &vm->mm;mm->pgdp = NULL;spin_lock_init(&mm->lock);init_list(&mm->vmm_area_free);init_list(&mm->vmm_area_used);// 分配该 vm 的 stage2 页表/pgdmm->pgdp = arch_alloc_guest_pgd();if (mm->pgdp == NULL) { pr_err("No memory for vm page table\n");return -ENOMEM;}// 分配和初始化该 vm 的 vma 结构体vmm_area_init(mm, !vm_is_32bit(vm));/** attch the memory region to the native vm.*/return vm_memory_init(vm);
}
vm_mm_struct_init 函数主要初始化 vm 最初的一些内存信息
// 创建 vm 的第一个 vmm_area
static void vmm_area_init(struct mm_struct *mm, int bit64)
{unsigned long base, size;struct vmm_area *va;/** the virtual memory space for a virtual machine:* 64bit - 40bit (1TB) IPA address space.* 32bit - 32bit (4GB) IPA address space. (Without LPAE)* 32bit - TBD (with LPAE)*/if (bit64) {base = 0x0;size = (1UL << 40);} else {
#ifdef CONFIG_VM_LPAEbase = 0x0;size = 0x100000000;
#elsebase = 0x0;size = 0x100000000;
#endif}// 分配一个初始的 vmm_areava = __alloc_vmm_area_entry(base, size);if (!va)pr_err("failed to alloc free vmm_area\n");// 将 vmm_area 插入到 vmm_area_free 链表elselist_add_tail(&mm->vmm_area_free, &va->list);
}
此函数创建 vm 的第一个 free vmm_area 结构体,起始地址为 0,大小为 1T
static int vm_memory_init(struct vm *vm)
{struct memory_region *region;struct vmm_area *va;int ret = 0;// mvm 创建的 vm 直接返回 0if (!vm_is_native(vm))return 0;/** find the memory region which belongs to this* VM and register to this VM.*/// 遍历 mem_regionfor_each_memory_region(region) {// 寻找为当前 vm 分配的 mem_region,如果不是 continueif (region->vmid != vm->vmid)continue;// 切割出一个 vmm_area,其 base、size 为 mem_region 大小va = split_vmm_area(&vm->mm, region->phy_base,region->size, VM_NATIVE_NORMAL);if (!va)return -EINVAL;}/** check whether the entry address, setup_data address and load* address are in the valid memory region.*/ret = check_vm_address(vm, (unsigned long)vm->load_address);ret += check_vm_address(vm, (unsigned long)vm->entry_point);ret += check_vm_address(vm, (unsigned long)vm->setup_data);return ret;
}
对于 native vm,前面说过,在解析设备树 memory 节点的时候就会为该 vm 分配一段内存,并记录到了 memory_region 当中,这里就是查找该 memory_region,获取其中的内存起始位置,大小等信息,然后从该 vm free vmm_area 中 split 出一个对应的 used vmm_area。(used vmm_area 简单理解为有物理内存对应的 ipa 地址空间,minos 为 native vm 划分了一段物理内存,信息记录在 memory_region,这里就是将信息取出来,记录到相应的 used vmm_area)
int vm_mm_init(struct vm *vm)
{int ret;unsigned long base, end, size;struct vmm_area *va, *n;struct mm_struct *mm = &vm->mm;if (test_and_set_bit(VM_FLAGS_BIT_SKIP_MM_INIT, &vm->flags))return 0;// dump 出目前所有的 vmm_area dump_vmm_areas(&vm->mm);/* just mapping the physical memory for native VM */// used vmm_area 都有分配实际的物理内存,这里建立映射关系list_for_each_entry(va, &mm->vmm_area_used, list) {if (!(va->flags & __VM_NORMAL))continue;// 建立映射,而且是直接映射, 即 [va->start, va->end) => [va->start, va->end)ret = map_vmm_area(mm, va, va->start);if (ret) {pr_err("map mem failed for vm-%d [0x%lx 0x%lx]\n",vm->vmid, va->start, va->end);return ret;}}/** make sure that all the free vmm_area are PAGE aligned* when caculated the end address need to plus 1.*/// 规整 free vmm_arealist_for_each_entry_safe(va, n, &mm->vmm_area_free, list) {base = BALIGN(va->start, PAGE_SIZE);end = ALIGN(va->end, PAGE_SIZE);size = end - base;if (size < PAGE_SIZE) {pr_debug("drop unused vmm_area [0x%lx 0x%lx]\n",va->start, va->end);list_del(&va->list);free(va);continue;}if (size != (va->end - va->start)) {pr_debug("adjust vma [0x%lx 0x%lx] to [0x%lx->0x%lx]\n",va->start, va->end, base, end);va->start = base;va->end = end;}}return 0;
}
前面虽然一直再说给 native vm 分配了内存,但是其实也只是记录了信息到 used vmm_area,并没有建立实际的映射关系(在我的观念中,只有建立了映射关系,才算是真正的分配了物理内存),但此函数中,遍历了所有的 uesd vmm_area,并建立了实际的映射关系,使得 vmm_area 代表的 ipa 空间映射到了 pa 空间。
guest vm ipa 管理
guest vm ipa 空间的初始化操作与 native vm 是一样的,都会调用 vm_mm_struct_init 函数来创建一张 stage2 页表,分配和初始化第一个 vmm_area 结构体,并注册到 vmm_area_free 链表。但是 mem_list 中没有一个 memory_region 代表将要创建的 guest vm,这是 native vm 的特权,在物理内存初始化的时候就为 native vm 划分了一块内存。
guest vm 的物理内存分配和映射是另外一条路子,所有的 guest vm 都是从块内存池中分配物理内存。所以在继续讲述 guest vm ipa 的管理时,先来看看这个块内存池。
块内存池
struct mem_block {uint32_t bfn;struct mem_block *next;
};struct block_section {unsigned long start; //该块区的起始地址unsigned long size; //该块区的大小unsigned long end; //该块区的结束地址unsigned long free_blocks; //该块区剩余的空闲块数unsigned long total_blocks; //该块区总共有多少块unsigned long current_index; //下一个空闲块号unsigned long *bitmap; //块区分配位图struct block_section *next; //下一个块区
};static struct block_section *bs_head; // 块区链表头结点
static DEFINE_SPIN_LOCK(bs_lock); // 分配所
static unsigned long free_blocks; // 目前所有块区空闲块数
一个块区其实是一片连续的内存,只是转换成了一个个块的形式。多个块区组成了用来给 guest vm 分配内存的块内存池。各个块区也是通过链表连接的,其头结点是 bs_head
// 遍历 mem_region,将空闲的 NORMAL 内存 转换为 block,作为 guest vm、
// [ 0.000000@00 000] NIC MEM: 0x000000004645a000 -> 0x0000000046600000 [0x00000000001a6000] Normal/Host
// 这部分内存小于 1 个 block size,舍弃掉
// [ 0.000000@00 000] NIC MEM: 0x0000000086600000 -> 0x00000000c0000000 [0x0000000039a00000] Normal/Host
// 这部分内存转换为 block
void vmm_init(void)
{struct memory_region *region;struct block_section *bs;unsigned long start, end;int size;ASSERT(!is_list_empty(&mem_list));/** all the free memory will used as the guest VM* memory. The guest memory will allocated as block.*/// 对于每一个 memory_regionlist_for_each_entry(region, &mem_list, list) {// 遍历所有的空闲内存,准备全部用作 guest vm,转换成 block 形式if (region->type != MEMORY_REGION_TYPE_NORMAL)continue;/** block section need BLOCK align.*/// 如果该段 mem_region 小于一个 block,放过它start = BALIGN(region->phy_base, BLOCK_SIZE);end = ALIGN(region->phy_base + region->size, BLOCK_SIZE);if (end - start <= 0) {pr_warn("VMM drop memory region [0x%lx 0x%lx]\n",region->phy_base,region->phy_base + region->size);continue;}pr_notice("VMM add memory region [0x%lx 0x%lx]\n", start, end);// 分配一个 block_section,记录信息bs = malloc(sizeof(struct block_section));ASSERT(bs != NULL);bs->start = start; //块区的起始地址就是该memory_region的起始地址bs->end = end; bs->size = bs->end - bs->start; //块区大小就是memory_region大小bs->total_blocks = bs->free_blocks = bs->size >> BLOCK_SHIFT; //计算该memory_region有多少块bs->current_index = 0;free_blocks += bs->total_blocks; //记录到总的空闲块数/** allocate the memory for block bitmap.*/// 分配对应的 bitmapsize = BITS_TO_LONGS(bs->free_blocks) * sizeof(long);bs->bitmap = malloc(size);ASSERT(bs->bitmap != NULL);memset(bs->bitmap, 0, size);bs->next = bs_head; // 将该块区头插到 bs_headbs_head = bs;}
}
上述函数就是将空闲的 memory_region 中的内存转换为块,可以看出当前系统有两个空闲 memory_region,有一个 memory_region 太小了,直接暴力的舍弃掉了,另外一个就转换成了块区
// 为 guest vm 分配和映射物理内存
int alloc_vm_memory(struct vm *vm)
{struct mm_struct *mm = &vm->mm;struct vmm_area *va;// 如果是刚创建 vm 时走到这里的话,// vmm_area_used 链表中应该只有一个 vma 结构,此结构是从整体的 ipa vma 中 split 下来的,见 guest_mm_init 函数流程list_for_each_entry(va, &mm->vmm_area_used, list) {if (!(va->flags & VM_NORMAL))continue;// 从 block 中分配内存if (__alloc_vm_memory(mm, va)) {pr_err("alloc memory for vm-%d failed\n", vm->vmid);goto out;}// 建立 stage2 映射if (map_vmm_area(mm, va, 0)) {pr_err("map memory for vm-%d failed\n", vm->vmid);goto out;}}return 0;
out:release_vm_memory(vm);return -ENOMEM;
}
此函数同样的也是要遍历该 vm 所有的 used vmm_area 结构体,然后调用 __alloc_vm_memory 函数分配物理内存,map_vmm_area 函数来映射物理内存
// 从 block_section 中分配一个 bock,返回其块号
static int get_memblock_from_section(struct block_section *bs, uint32_t *bfn)
{uint32_t id;// 遍历位图,寻找空闲块 idxid = find_next_zero_bit_loop(bs->bitmap,bs->total_blocks, bs->current_index);if (id >= bs->total_blocks)return -ENOSPC;set_bit(id, bs->bitmap);bs->current_index = id + 1;bs->free_blocks -= 1;free_blocks -= 1;// (bs->start >> MEM_BLOCK_SHIFT) 表示第一个块的块号// (bs->start >> MEM_BLOCK_SHIFT) + id 表示下一个空闲块的块号*bfn = (bs->start >> MEM_BLOCK_SHIFT) + id;return 0;
}// 分配一个 block,返回 mem_block 结构
struct mem_block *vmm_alloc_memblock(void)
{struct block_section *bs;struct mem_block *mb;int success = 0, ret;uint32_t bfn = 0;spin_lock(&bs_lock);bs = bs_head;while (bs) {if (bs->free_blocks != 0) {// 获取一个空闲块,返回其块号ret = get_memblock_from_section(bs, &bfn);if (ret == 0) {success = 1;break;} else { pr_err("memory block content wrong\n");}}bs = bs->next;}spin_unlock(&bs_lock);if (!success)return NULL;// 分配 mem_block 结构体mb = malloc(sizeof(struct mem_block));if (!mb) {spin_lock(&bs_lock);__vmm_free_memblock(bfn);spin_unlock(&bs_lock);return NULL;}// 记录块号mb->bfn = bfn;mb->next = NULL;return mb;
}// 为 guest vm 分配块内存
static int __alloc_vm_memory(struct mm_struct *mm, struct vmm_area *va)
{int i, count;unsigned long base;struct mem_block *block;base = ALIGN(va->start, MEM_BLOCK_SIZE);if (base != va->start) {pr_err("memory base is not mem_block align\n");return -EINVAL;}va->b_head = NULL;va->flags |= VM_MAP_BK;// 计算该 vmm_area 大小等于多少个 mem_blockcount = VMA_SIZE(va) >> MEM_BLOCK_SHIFT;/** here get all the memory block for the vm* TBD: get contiueous memory or not contiueous ?*/// 这里分配所有所有块for (i = 0; i < count; i++) {block = vmm_alloc_memblock();if (!block)return -ENOMEM;// 头插法到 va->b_head 链表block->next = va->b_head;va->b_head = block;}return 0;
}
上述函数从块内存池中分配内存给 guest vm
// 释放 block_section 中的 bfn 所在的 block
static int __vmm_free_memblock(uint32_t bfn)
{// format block 地址unsigned long base = bfn << MEM_BLOCK_SHIFT;struct block_section *bs = bs_head;// 遍历所有 block_sectionwhile (bs) {// 该 bfn 所在的 block_sectionif ((base >= bs->start) && (base < bs->end)) {// 获取该 bfn 所在 block 在对应的 block_seciton 的比特位bfn = (base - bs->start) >> MEM_BLOCK_SHIFT;// 清除该比特位clear_bit(bfn, bs->bitmap);// 更新信息bs->free_blocks += 1;free_blocks += 1;return 0;}bs = bs->next;}pr_err("wrong memory block 0x%x\n", bfn);return -EINVAL;
}// 释放掉 block mb
int vmm_free_memblock(struct mem_block *mb)
{uint32_t bfn = mb->bfn;int ret;free(mb);spin_lock(&bs_lock);ret = __vmm_free_memblock(bfn);spin_unlock(&bs_lock);return ret;
}
这是释放 block 内存到块内存池,都是位图链表的一些基本操作不赘述
stage2 映射
上述是给 vm 分配内存相关代码讲解,下面来说说 stage2 映射相关的
// 对 vma_area 中的内存建立映射
int map_vmm_area(struct mm_struct *mm,struct vmm_area *va, unsigned long pbase)
{int ret;switch (va->flags & VM_MAP_TYPE_MASK) {case VM_MAP_PT: // 建立直接映射va->pstart = va->start;ret = vmm_area_map_ln(mm, va);break;case VM_MAP_BK:ret = vmm_area_map_bk(mm, va);break;// create_hvm_shmem_map 的时候走 defaultdefault:va->pstart = pbase;ret = vmm_area_map_ln(mm, va);break;}return ret;
}// 创建 stage2 block 映射
static int vmm_area_map_bk(struct mm_struct *mm, struct vmm_area *va)
{struct mem_block *block = va->b_head;;unsigned long base = va->start;unsigned long size = VMA_SIZE(va);int ret;// 遍历 vma_area 中的所有 block,建立映射while (block) {ret = __create_guest_mapping(mm, base, BFN2PHY(block->bfn),MEM_BLOCK_SIZE, va->flags | VM_HUGE | VM_GUEST);if (ret)return ret;base += MEM_BLOCK_SIZE;size -= MEM_BLOCK_SIZE;block = block->next;}ASSERT(size == 0);return 0;
}
所有的 stage2 映射都是调用上述函数,映射方式也有几种,线性、passthrough 等等,先不管这些概念以及用途,反正这里最后都是调用到 __create_guest_mapping,而 __create_guest_mapping 又类似 __create_host_mapping,就是一系列的页表操作函数。可以看 stage2.c 文件中的函数和 stage1.c 文件中的函数差不了太多,都是对 pgd、pud、pmd、pte 的操作,所以这里就不细说了,可以自行查看源码
简要总结:无虚拟化的情况下,Linux 内核需要对进程的虚存进行管理,类似,有虚拟化情况下,hypervisor 负责对虚机内存管理。虚机里面的内存,比如说虚机中的进程内存呢?那是虚机 OS 内核如 Linux 干的事情,hypervisor 不管。而 minos 中对于虚机内存,抽象为 vmm_area,minos
首发公号:Rand_cs
这篇关于minos 1.2 内存虚拟化——guest的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




