本文主要是介绍Linux服务器扩容及磁盘分区(LVM和非LVM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Linux扩容及磁盘分区(LVM和非LVM)
本文主要介绍了阿里云服务器centos的扩容方法:非LVM分区扩容方法(系统盘),以及磁盘改LVM并分区(数据盘)。主要是ext4文件系统及xfs磁盘scsi MBR分区。
根目录为系统盘分区。
由于系统盘分区方式为非LVM, 难以跨磁盘或跨分区扩容,只能扩容原有分区。
但可以拆分根目录下的子目录,挂载到数据盘,将数据盘进行LVM分区,便于后续跨磁盘、跨分区扩容。
一、系统盘(非LVM),直接扩容
set -eu# 1. 安装growpart工具type growpart || yum install -y cloud-utils-growpart## 2. 扩容分区:运行命令 growpart /dev/vda 1LC_ALL=en_US.UTF-8 growpart /dev/vda 1# 扩容文件系统:文件系统为ext4,因此运行resize2fs命令resize2fs /dev/vda1
Df -Th可见根目录有扩大
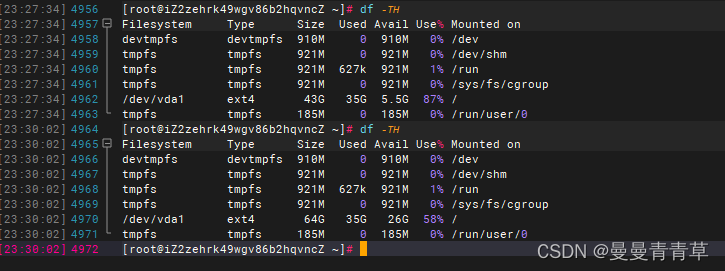 二、数据盘(LVM分区)准备工作:查看挂载和磁盘使用情况
二、数据盘(LVM分区)准备工作:查看挂载和磁盘使用情况
1、安装lvm工具
sudo yum install lvm2 2、查看磁盘挂载情况
2、查看磁盘挂载情况
lsblk
3、查看磁盘容量和挂载情况
df -TH 4、查看磁盘数据盘
4、查看磁盘数据盘
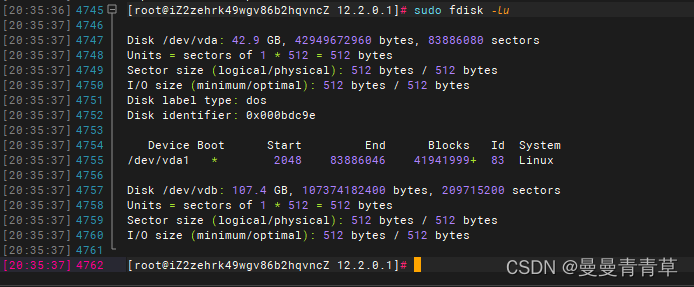
sudo fdisk -lu获取数据盘的设备名称。
运行结果如下所示,表示当前ECS实例有两块云盘,/dev/vda是系统盘,/dev/vdb是新增数据盘,有100G,微分区
 5、查找大文件目录,确定要分区挂载的目录
5、查找大文件目录,确定要分区挂载的目录
du -h --max-depth=1 /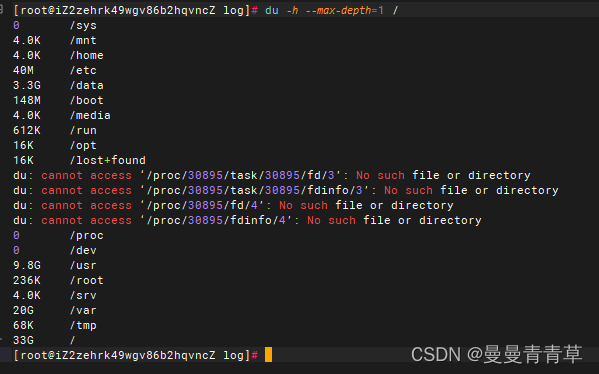
打算预计:
/usr 扩容至20G
/var 扩容至 50G
/data 扩容至 15G
三、LVM扩容
数据盘/dev/vdb
改为lvm
1、分区
sudo fdisk -u /dev/vdbn #创建分区p #主分区p;扩展分区e2 #分区号 2-4起止扇区起止扇区P #检测是否分区完成W # 如分区正常w保存;否正q退出不保存查看分区fdisk -lu /dev/vdb创建成功
/dev/vdb1 15G
/dev/vdb2 20G
/dev/vdb3 50G
#将磁盘分区表变化信息通知内核,请求操作系统重新加载分区表partprobe /dev/vdb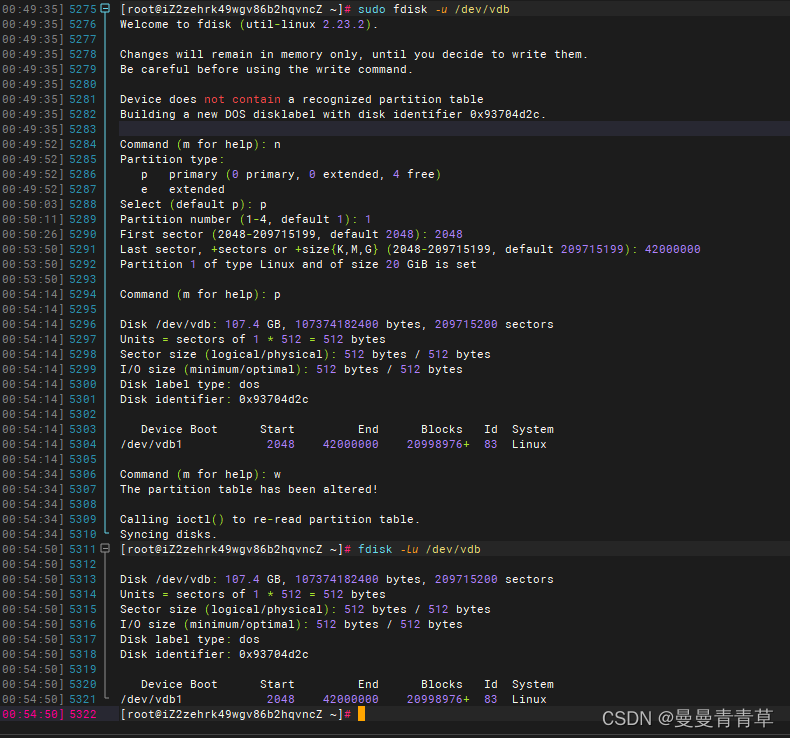

2、初始化分区和文件系统
sudo mkfs -t ext4 /dev/vdb1sudo mkfs -t ext4 /dev/vdb2sudo mkfs -t ext4 /dev/vdb3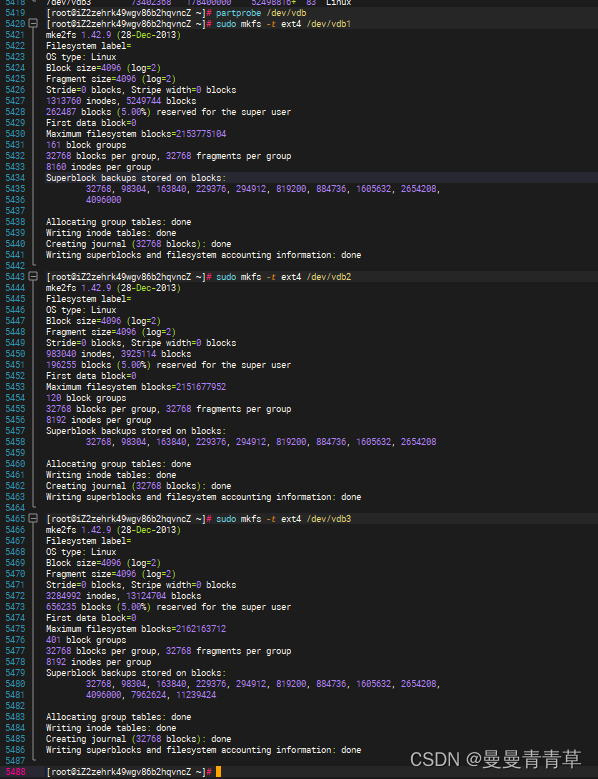
3、创建物理卷并查看
# 查看可以使用的物理设备(分区/磁盘)parted -l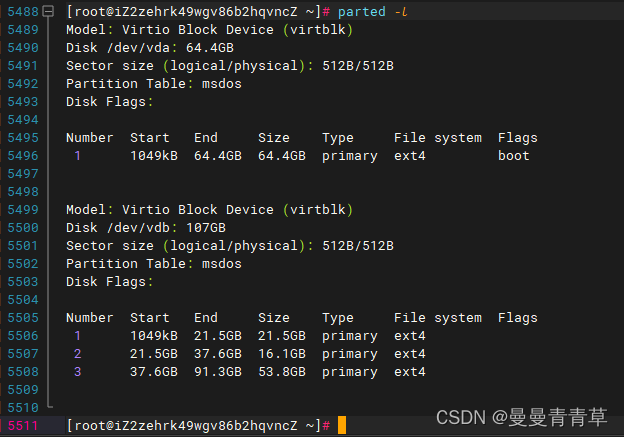
# 将物理设备 创建物理卷pvcreate /dev/vdb1 /dev/vdb2 /dev/vdb3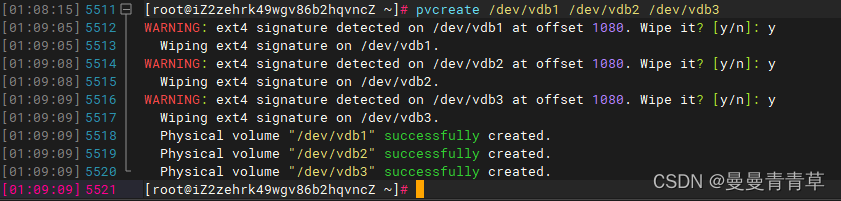
(
如果你要擦除现有的文件系统以创建新的 ext4 文件系统,并且确定分区上没有重要数据或者已经备份,可以按 'y' 键。
如果分区上有重要数据,或者你不确定是否要擦除,应该选择 'n' 并考虑备份数据,或者先进行数据恢复工作。
)
# partprobe #如果创建时报错磁盘不存在,执行partprobecat /proc/partitions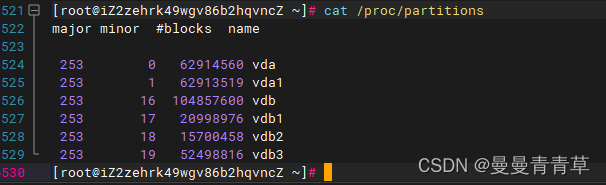
# 查看物理卷pvdisplay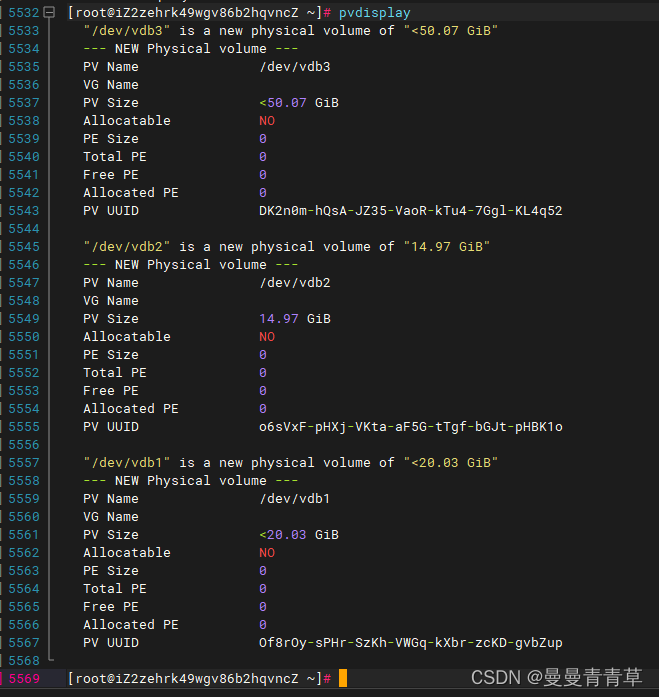
4、创建物理卷组
# 创建物理卷组vgcreate vgdata /dev/vdb1 vgcreate vgusr /dev/vdb2vgcreate vgvar /dev/vdb3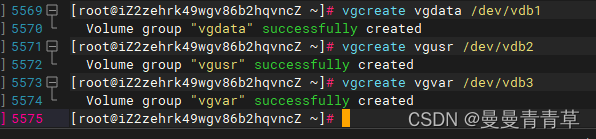
5、创建逻辑卷
也可以物理卷合并成一个逻辑卷
lvcreate -n lvdata -l 5119 vgdata lvcreate -n lvusr -l 5119 vgusrlvcreate -n lvvar -l 5119 vgvar  查看逻辑卷
查看逻辑卷
lvdisplay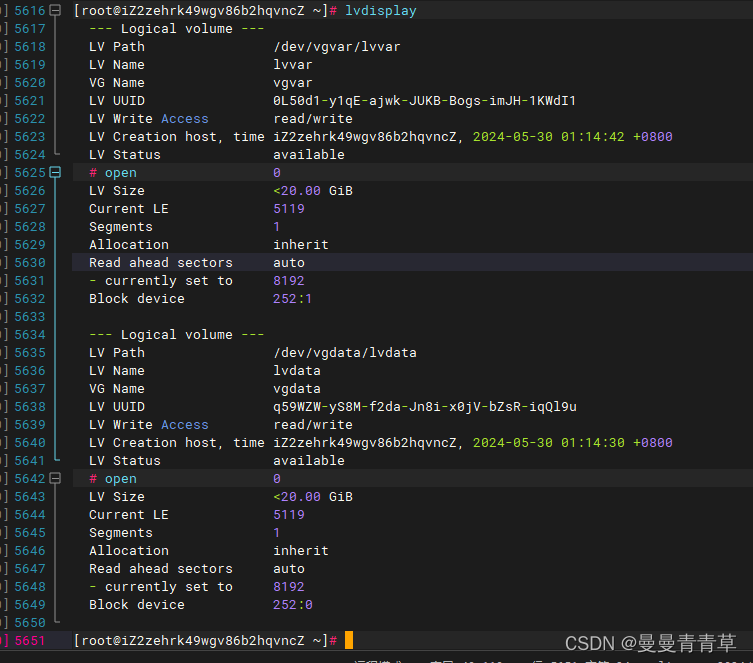 6、格式化逻辑卷
6、格式化逻辑卷
sudo mkfs -t ext4 /dev/mapper/vgdata-lvdata sudo mkfs -t ext4 /dev/mapper/vgvar-lvvar sudo mkfs -t ext4 /dev/mapper/vgusr-lvusr 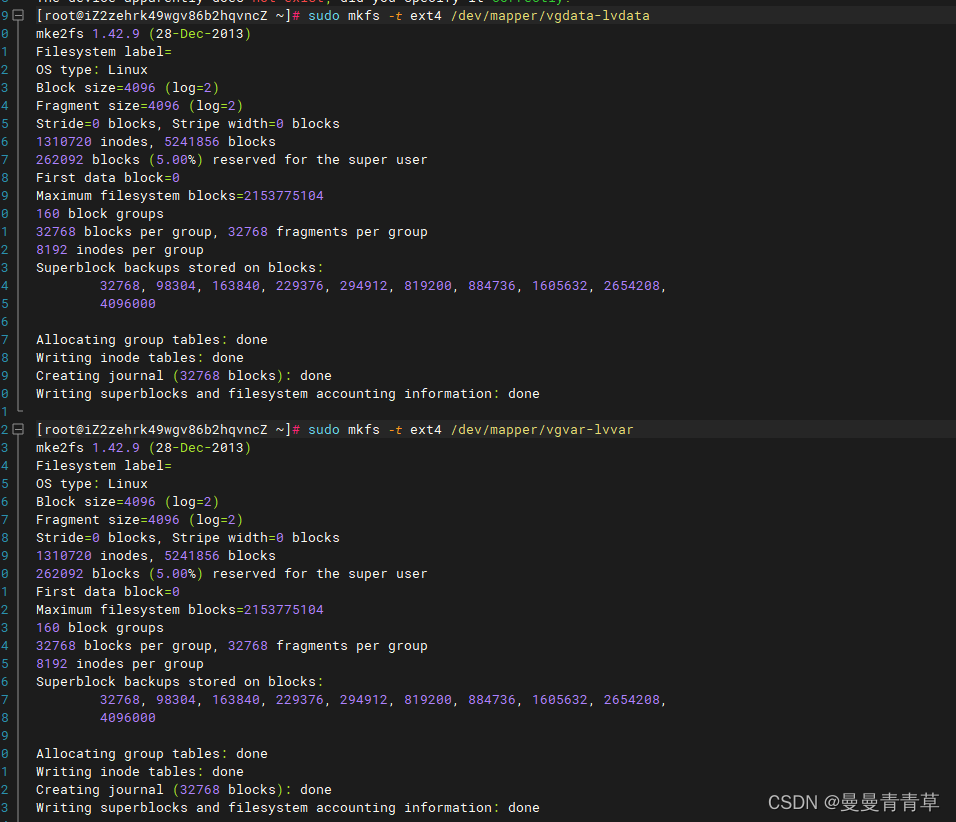 7、挂载逻辑卷到目录
7、挂载逻辑卷到目录
mount /dev/vgdata/lvdata /data/mount /dev/vgvar/lvvar /var/mount /dev/vgusr/lvusr /usr/
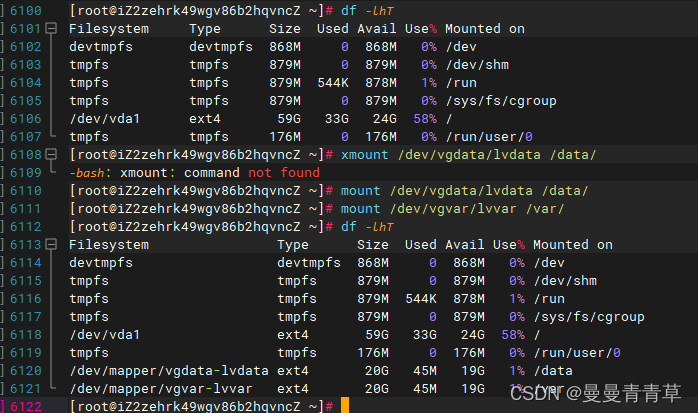
四、后续逻辑卷扩容
Eg:/data目录扩容 ==>对应逻辑卷:/dev/mapper/vgdata-lvdata
对vdb进行分区(同第三步)/dev/vdb4
1、查看是否有空闲的物理卷或逻辑卷
# 查看是否有空闲的物理卷或逻辑卷vgspvs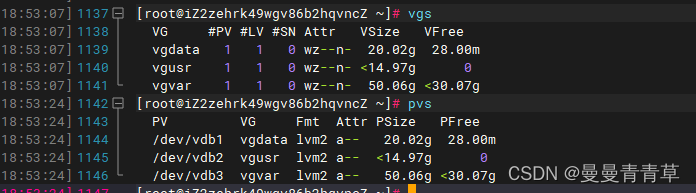
2、扩展物理卷组
#扩展物理卷组:将空闲物理卷加入/data对应卷组
vgextend vgdata /dev/vdb4
# 是否加入成功
vgdisplay
3、扩展逻辑卷组
# 扩展逻辑卷组
lvextend -l +5119 /dev/vgdata/lvdata
4、更新文件系统
# 更新文件系统
resize2fs /dev/mapper/vgdata-lvdata
5、查看验证
# 查看验证
lvs
vgs
df -lh
五、收缩大小
对于ext4文件系统可以收缩大小
1、卸载逻辑卷
#卸载逻辑卷
unmount /dev/vdb1
2、更新文件系统
#更新文件系统
resize2fs /dev/mapper/vgdata-lvdata 10G
3、收缩逻辑卷
#收缩逻辑卷
lvreduce /dev/vgdata/lvdata
4、重新挂载逻辑卷
#重新挂载逻辑卷
mount /dev/vgdata/lvdata /data/
六、小结
1、LVM分区概念:
物理卷PV==>物理卷组PG==>逻辑卷LV==>逻辑卷组VG==>文件系统
2、LVM常用命令
| 序号 | 功能 | PV 物理卷命令 | VG 卷组命令 | LV 逻辑卷命令 |
|---|---|---|---|---|
| 01 | 扫描功能 | pvscan | vgscan | lvscan |
| 02 | 建⽴功能 | pvcreate | vgcreate | lvcreate |
| 03 | 查询功能 | pvdisplay | vgdisplay | lvdisplay |
| 04 | 删除功能 | pvremove | vgremove | lvremove |
| 05 | 扩容功能 | vgextend | lvextend | |
| 06 | 缩容功能 | vgreduce | lvreduce |
主要参考文件:
Linux磁盘分区与LVM详解_linux标准分区和lvm分区-CSDN博客
这篇关于Linux服务器扩容及磁盘分区(LVM和非LVM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









