本文主要是介绍插入排序以及希尔排序; 先学会插入,希尔会更简单喔,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

1.前言
- 首先肯定是要学会插入排序再学习希尔排序会更简单,因为代码部分有很多相似之处;如果你觉得你很强,可以直接看希尔排序的讲解。
- 哈哈哈!,每天进步一点点,和昨天的自己比
2.插入排序
- 让我们先来看看插入排序的动图,可能第一遍看不懂,最好结合解释一起看
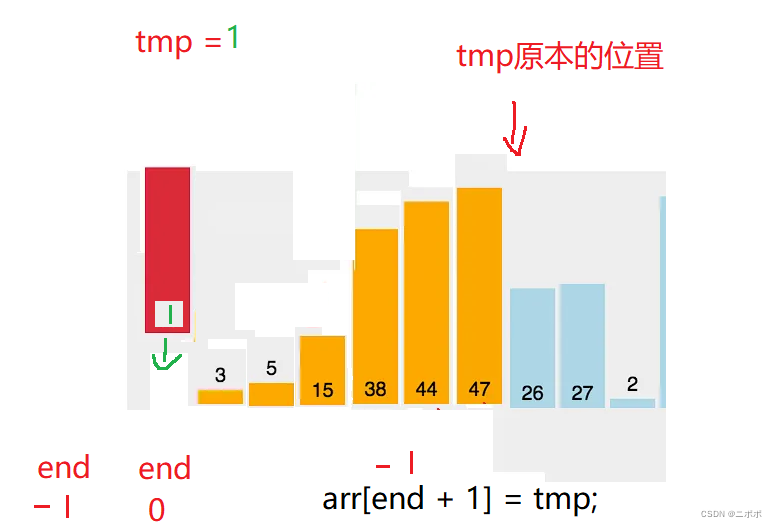
- 核心思想:end + 1;去0 到 end 之前去找,如果tmp(end+1)小于end位置,end位置往后挪到end + 1位置上
- 挪动后tmp要继续找0 到 end的其他位置,如果tmp 比end位置大,就插入在end + 1的位置
- 需要注意的是:假如tmp大于0到end之间的某一个数据,直接跳出循环,在while循环外面插入
- for循环的i < n - 1为什么是这样? 因为是拿end + 1的位置和前面的比较;
- 假设 i < n;那你执行代码的时候,最后一个是end是n - 1位置,那么你要取tmp位置的就会导致越界,这个tmp就会取到n位置上的数,不就越界了吗
- 0 到 end 之间的区间数据是逐渐增长的,最开始是 0 到 1,第二次范围就是0 到 2
//插入排序 核心思想:end + 1;去0 end 之前去找,如果tmp小于end位置,就往end位置往后挪
void InsertSort(int* arr, int n)
{//n的位置不可访问,所以要 < n; < n - 1为什么? 因为是拿end + 1的位置和前面的比较for (int i = 0; i < n - 1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0)//去查找出0 end范围的值{if (tmp < arr[end]){arr[end + 1] = arr[end];//如果tmp小于end位置的值,就向后挪,知道大于end位置的值就可以停下插入end--;}else{break;//此时说明tmp大于end位置,在end+1位置插入}}arr[end + 1] = tmp;//防止都比0 end之间要小,小于0跳出循环,-1 + 1;刚好是第一个位置}
}- 下面说一种常规思路的写法,这样写可以,不过上面的写法更好
- 而且最主要就是防止tmp比 0 到 end 区间内的值都要小
void InsertSort(int* arr, int n)
{//n的位置不可访问,所以要 < n; < n - 1为什么? 因为是拿end + 1的位置和前面的比较for (int i = 0; i < n - 1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0)//去查找出0 end范围的值{if (tmp < arr[end]){arr[end + 1] = arr[end];//如果tmp小于end位置的值,就向后挪,知道大于end位置的值就可以停下插入end--;}else{arr[end + 1] = tmp;break;//此时说明tmp大于end位置,在end+1位置插入}}if(end == -1) {arr[end + 1] = tmp;}2.1插入排序的时间复杂度
- 最坏情况:
- O(N^2);当排序为逆序时,你想想0 到 end位置的数,假设是升序;竟然是升序但是end + 1这个数据是比0 到 end位置的数还要小那么就会交换很多次
- 假如上述的情况每次都这样呢?,那不是最坏的情况了
- 但是逆序的概率很低,反而乱序的概率大些
- 最好情况:O(N),已经非常接近有序了
- 还有一点,主要是插入排序适应能力强,在查找的过程中可以直接插入数据,比冒泡排序省去很多查找
- 这里也顺便提一下冒泡排序吧,做个比较
2.2冒泡排序
- 最坏情况:O(N^2);
- 最好情况:O(N),已经有序了
- 虽然冒泡和插入排序时间复杂度都是一样的,但是在同一所学校,同一个公司;但是它两之间仍然有好坏之分
- 为啥呢? 因为冒泡排序的最坏情况很容易达成,几乎每次交换都是一个等差数列,最好情况的情况概率太低了
- 竟然这么菜,有啥用呢 ? 实践中没有意义;适合教学
//冒泡排序
void BubblSort(int* arr, int sz)
{for (int i = 0; i < sz - 1; i++){int flag = 0;//假设这一趟没有交换已经有序for (int j = 0; j < sz - i - 1; j++){if (arr[j] > arr[j + 1]){int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;flag = 1;//发生交换,无序}}if(flag == 0)//经过一趟发现有序,没有交换break;}
}3.希尔排序
- 希尔排序分为两步
- 预排序(让数组接近有序)
- 插入排序
- 插入排序思想不错,可不可以优化一下,变得更好,甚至更强呢?
- 插入排序就是怕逆序的情况,所以通过预排序让数组接近有序,让大的值跳gap步可以很快的到后面
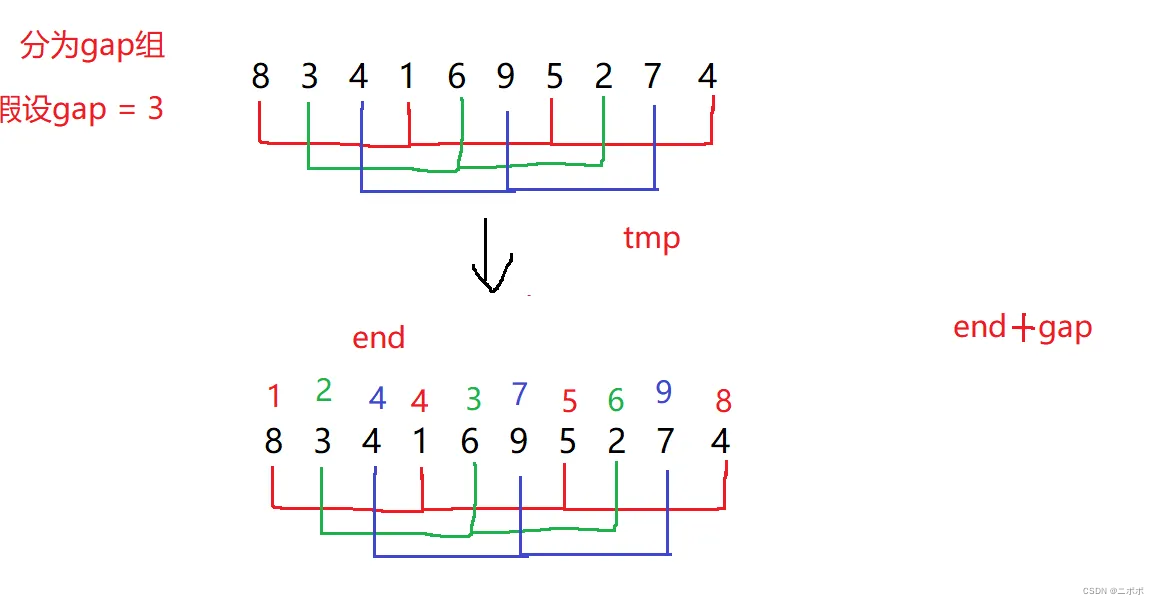
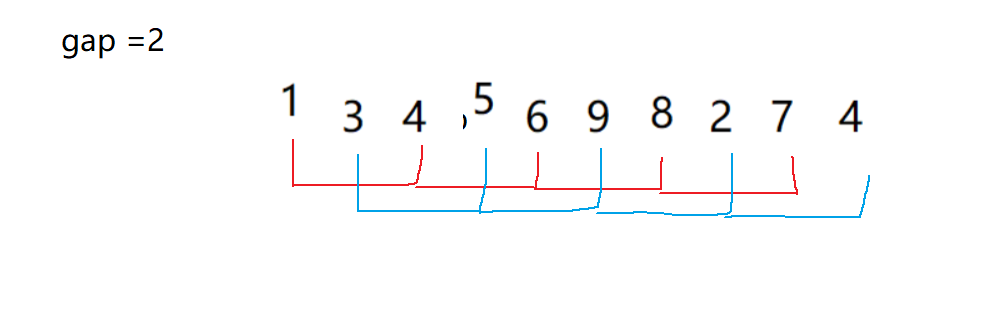
- 那么什么是gap,gap就是把数据分为gap组,每个数据间隔为gap的
3.1预排序
- 下面这样图,看不懂没关系细细给你分析。可以看到gap = 3,分成了红绿蓝三组数据
- 每组的每个数间隔为gap,假如说红色这一组它有4个数,其实你可以看成插入排序的一趟排序,只不过就是间隔为gap而已
- 而下面这样图就是,每组数据都进行一趟插入排序,可以自己画图试试看看,一不一样;当然下面也有动图的解释
3.2单趟排序
- 其实和插入排序思路差不多,只不过是end位置 和 tmp(end + gap)位置进行比较
- 如果tmp值小于end位置的值,就让end位置移动到 end + gap位置
- break跳出证明tmp大于 arr[end],此时tmp就放到end + gap位置即可
- 放在while循环外,和上面讲的插入排序的解决方法一样,当小于0 到 end时;防止越界
- 动图来解释一下,这个动图忘记设置循环了,所以要观看就重进一下
讲完单趟排序,再来说说应该注意的点:
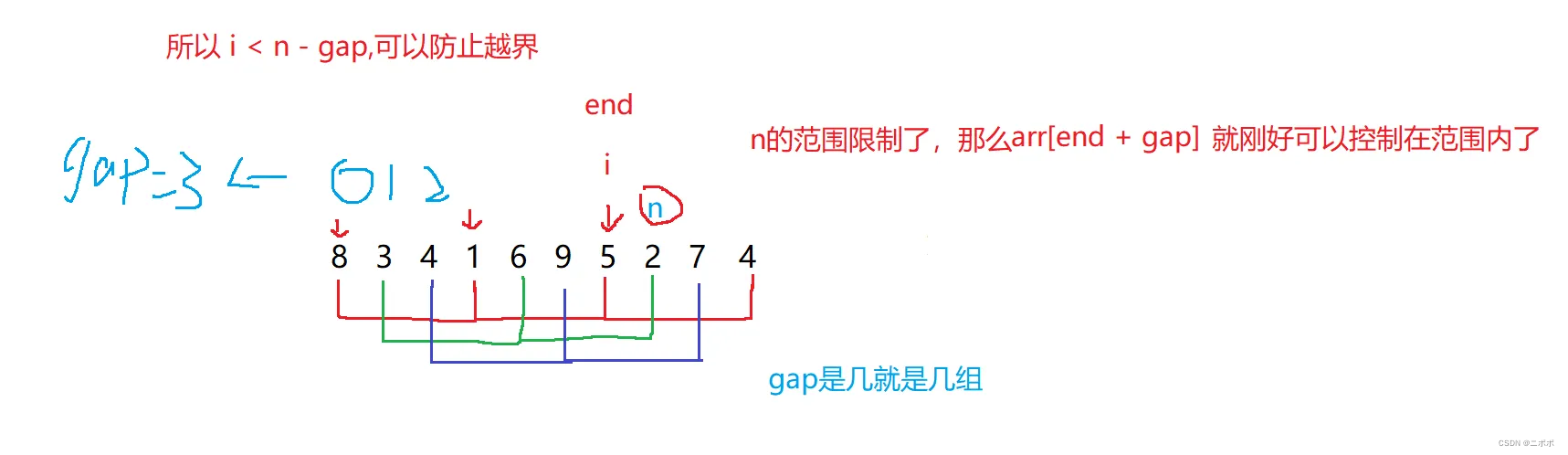
- 使用for来完成一趟排序的结束条件
- 红色这组举例:因为你每次跳gap步,如果 i 循环到了 数字为4的位置,此时进入循环,int tmp = arr[end + gap];这里面的 + gap会越界
最后是for循环是单趟的代码
for (int i = j; i < n - gap; i += gap){int end = i;//对应一趟排序的第几次int tmp = arr[end + gap];while (end >= 0)//比较交换{//如果小于arr[end]挪到arr[end + gap]if (tmp < arr[end]){arr[end + gap] = arr[end];}else{break;}}arr[end + gap] = tmp;}
3.3每组都进行预排序
- 外面再放一层for循环是什么意思呢?
- 意思是通过分组来排序,先是红色然后绿色和蓝色,当j = 0是就是红色这一组
//希尔排序的预排序
void ShellSort(int* arr, int n)
{//假设gap为3int gap = 3;for (int j = 0; j < gap; j++){for (int i = j; i < n - gap; i += gap){int end = i;//对应一趟排序的第几次int tmp = arr[end + gap];while (end >= 0)//比较交换{//如果小于arr[end]挪到arr[end + gap]if (tmp < arr[end]){arr[end + gap] = arr[end];}else{break;}}arr[end + gap] = tmp;}}
}- 当然上面那一种在外面再放一层for也可以
- 这里我们可以优化一下,变成两层循环;下面是优化后一小段过程
- 上面的是一组一组排序,而这里是多组一起排序
- 而通过整过程发现,红色会预排序3次,绿色2次,蓝色2次;和优化后的总次数一样 ,假设n = 10,10 - 3 = 7;刚好是7次了
- 这里并不能通过数循环来判断时间复杂,上面三层循环和这里的两次循环一样的
- 执行次数一样,排序的过程不一样
3.3.1优化后的代码
void ShellSort(int* arr, int n)
{//假设gap为3int gap = 3;for (int i = 0; i < n - gap; i++){int end = i;//对应一趟排序的第几次int tmp = arr[end + gap];while (end >= 0)//比较交换{//如果小于arr[end]挪到arr[end + gap]if (tmp < arr[end]){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;}
}3.4预排序要进行多次
- 这里不是直接预排序完,然后就直接排序;要进行多次预排序才行
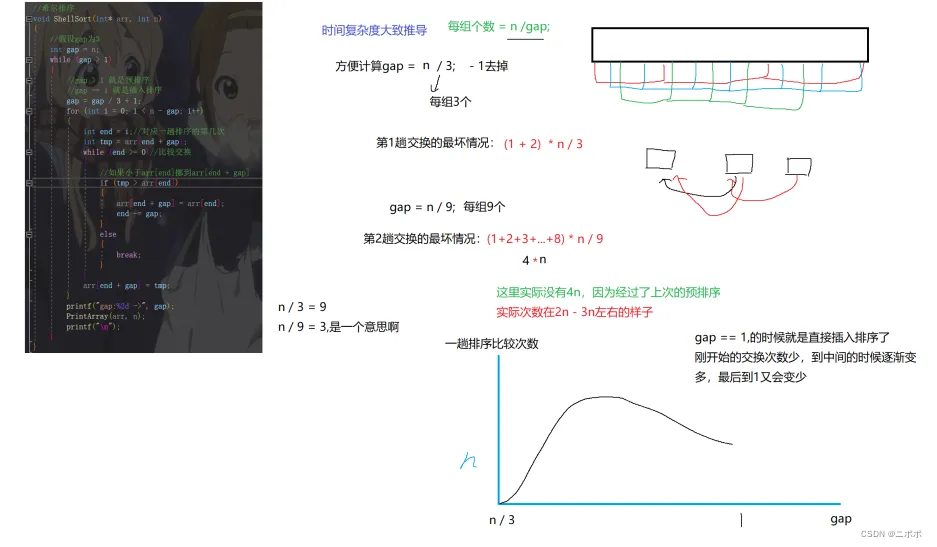
- 那么gap取多少才好呢?,最早有人研究 gap = gap / 2;但是这么最后每组只有两个,这么分不太好
- gap = gap / 3 + 1,更加合理一点
- 这为什么 + 1,因为刚好可以避免被3整除的时候等于了0,带入值可以想象一下8 / 3 = 2 + 1;3 / 3 = 0 + 1;
- 也就是说大于3的数除最后都会小于3,+ 1保证最后一个是 1
- 下面就是进行多次预排序,让大的数据更快到后面,小的数据更快到前面
- 弄完预排序,也就完成整个希尔排序,因为gap == 1的时候就是插入排序了
//希尔排序
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){//gap > 1 就是预排序//gap == 1 就是插入排序gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;//对应一趟排序的第几次int tmp = arr[end + gap];while (end >= 0)//比较交换{//如果小于arr[end]挪到arr[end + gap]if (tmp < arr[end]){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;}}
}3.5预排序总结
- gap越大,大的可以越快的跳到后面,小的可以更快跳到前面,但是就会不接近有序
- gap越小,跳的越慢,但是更加接近有序,gap == 1相当于插入排序了
- 所以为了结合两者优点,直接让gap慢慢变小
3.6希尔排序的时间复杂度
- 直接给出结论,希尔排序的时间复杂度是O(N^1.3);下面的分析仅供参考!!!
- 不过下面有稍微推了一下过程,可能不太好
- gap大 :数据量少,交换的次数少;
- gap小:数据量大,交换的次数多;
- gap表示多少组和数据之间的间隔(gap),gap大,组就多,每组数据就少,gap小 ,组就少,每组数据就多
4.总结
- 希尔排序的思想非常好,也非常奇妙,估计大部分普通人想不到这个方法;
- 当然可以学习到这么好的思路,也是很大的进步了;万一你以后也发明了一种很厉害的算法呢
- 如果你最近在苦恼要不要写博客,我的建议是一定写,个人感觉这个加分项还是很有必要握在手里的
这篇关于插入排序以及希尔排序; 先学会插入,希尔会更简单喔的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






