本文主要是介绍最全!最新!最细!Redis数据库从入门到应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
#前言:
该博客会详细介绍关于Redis数据库的内容,代码多有注释,最后会讲解如何将Redis应用(以Python与Django为例)。各位的点赞与关注将是小编变强的最大动力。
一、Redis数据库简介:
Redis是一个开源的内存数据库,它属于非关系型数据库。它被设计用来提供高性能的数据存储和检索服务。作为一个键值存储系统,Redis支持各种数据结构,包括字符串、列表、集合、哈希表等,使其成为一个多用途、灵活的工具。它常被用作缓存、消息队列、实时分析等应用场景下的数据存储引擎,因为其快速、可扩展和可靠的特性,使其成为许多互联网公司的首选之一。Redis还提供了丰富的功能,如事务、发布与订阅、持久化等,使其在处理实时数据和应用中起到了重要作用。
二、Redis安装:
1、下载安装包:
Redis安装很简单,安装包可以直接到我的网盘免费取:
链接:https://pan.baidu.com/s/1CItkqMYnW9P6Ih4zWhu8sg
提取码:ammd
2、环境变量配置:
当下载好安装包后,除了下述这一步需要勾选选项,其余全部next。

3、环境变量检查:
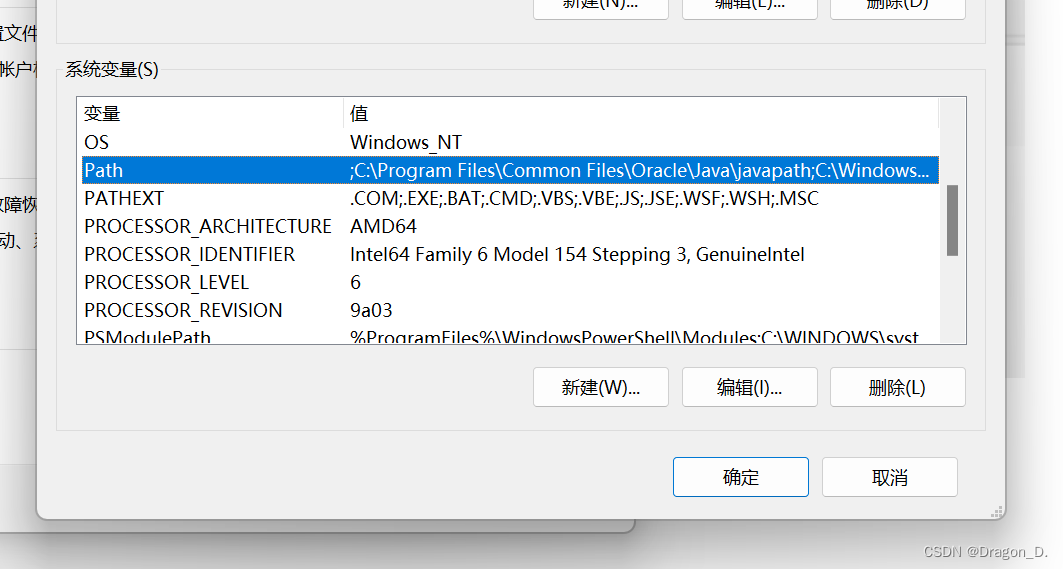
右击我的电脑,点击属性->高级系统设置->环境变量->path,若是有刚刚安装的redis路径则证明安装完成:(图片指导见下)

4、在 cmd 中启动进入 Redis:
win+R进入cmd,输入:redis-cli
若是出现下述情况,则证明已经启动Redis数据库:

其中6379表示Redis的端口号。
注意:redis 在存数据的时候是以二进制的方式存储的 , 获取中文的数据是以十六进制显示的
要获取中文:
redis-cli --raw三、Redis通用命令:
注意:Redis数据库语句不属于SQL语句,但是为了代码辨识度高一些我下面的代码会在SQL中注释。
1、SELECT:
select:切换 Redis 数据库
Redis 中默认设置了 16 个数据库,数据库的名称就是对应的编码,编码:0-15,直接进入默认是 0 号数据库。
127.0.0.1:6379> select 6
OK
127.0.0.1:6379[6]> select 1
OK
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379>显示ok则表示切换数据库成功。
2、DEL:
del:根据 key 删除对应的数据。
127.0.0.1:6379> set age 19
OK
127.0.0.1:6379> del age
(integer) 1
127.0.0.1:6379>3、EXISTS:
exists:根据 key 检查键值对是否存在。
127.0.0.1:6379> exists age
1 # 返回1:表示数据存在
127.0.0.1:6379> del age
1
127.0.0.1:6379> exists age
0 # 返回0:表示数据不存在4、KEYS:
keys:查询当前数据库中所有的 key。
127.0.0.1:6379> keys *注意,有个*号。
5、EXPIRE:
expire:设置键值对的有效时间,单位为:秒。当键值对过了有效时间之后,就会自动删除。、
127.0.0.1:6379> expire name 10
1pexpire:设置键值对的有效时间,单位为:毫秒。
127.0.0.1:6379> pexpire A 5000
16、TTL:
ttl:根据 key 查询键值对剩余的有效时间,返回的时间单位:秒。
127.0.0.1:6379> ttl A
-2 # 返回-2:表示当前的键值对已经过期 , 不存在
127.0.0.1:6379> ttl B
-1 # 返回-1:表示当前的键值对不会过期 , 永久存在
127.0.0.1:6379> expire B 10
1
127.0.0.1:6379> ttl B
8 # 返回整数:就是键值对的剩余有效时间7、RENAME:
rename:对 key 进行重命名。
127.0.0.1:6379> rename num number
OK
127.0.0.1:6379> get num127.0.0.1:6379> get number
-188、RANDOMKEY:
randomkey:随机返回当前数据库中一个 key。
9、FLUSHDB:
flushdb:清空当前数据库中所有的键值对。
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> keys *127.0.0.1:6379>10、FLUSHALL:
flushall:清空所有的数据库中的数据。
四、String类型:
1、STRLEN:
strlen:获取字符串的数据长度
127.0.0.1:6379> set name 123456
OK
127.0.0.1:6379> strlen name
6
2、APPEND:
append:在已经存在的键值对中进行拼接字符串,在原有的字符串的末尾添加
127.0.0.1:6379> append name 369
9 # 返回的数据是字符串修改之后的长度
127.0.0.1:6379> get name
123456369
3、INCR:
incr:当键值对的值为数字的时候,可以使用该命令对值 增加 1。如果键值对不存在,会初始化这个键值对,然后在执行该命令。
127.0.0.1:6379> incr num
2
127.0.0.1:6379> incr num
3
127.0.0.1:6379> incr number
1
4、INCRBY:
incrby:可以增加指定的数据值。
127.0.0.1:6379> incrby number 27
28
5、INCRBYFLOAT:
incrbyfloat:可以增加指定的数据值(浮点型)。
127.0.0.1:6379> incrbyfloat number 1.5
29.5
127.0.0.1:6379> incrbyfloat number 1
30.5
6、DECR:
decr:当键值对的值为数字的时候,可以使用该命令对值 减少 1。如果键值对不存在,会初始化这个键值对,然后在执行该命令。
127.0.0.1:6379> decr num
2
127.0.0.1:6379> decr num1
-1
127.0.0.1:6379> decrby num 20
-18
7、GETRANGE:
getrange:获取 key 对应值的子集。
127.0.0.1:6379> get name
123456369
127.0.0.1:6379> getrange name 1 5
23456
8、SETRANGE:
setrange:设置某个位置开始创建值,如果指定的位置上有数据,就会把对应位置上的数据覆盖。
127.0.0.1:6379> get name
123456369
127.0.0.1:6379> setrange name 6 ac
9
127.0.0.1:6379> get name
123456ac9
9、SETEX:
setex:在创建键值对的时候同时设置这个键值对的有效时间,单位:秒。
127.0.0.1:6379> setex age 5000 30
OK
127.0.0.1:6379> ttl age
4995
127.0.0.1:6379> ttl age
4989
127.0.0.1:6379> psetex a 60000 123 # psetex:设置时间单位为毫秒
OK
127.0.0.1:6379> ttl a
56
10、GETSET:
getset:重新设置值,会返回原有的数据值。
127.0.0.1:6379> get name
123456ac9
127.0.0.1:6379> getset name ac
123456ac9
127.0.0.1:6379> get name
ac
11、MSET:
mset:批量设置键值对。
127.0.0.1:6379> mset height 1.82 weight 76.8
OK
12、MGET:
mget:批量获取键值对数据。
127.0.0.1:6379> mget height weight age
五、List列表:
1、LPUSH:
lpush:从列表左边开始插入数据,当执行键值对列表存在的时候是进行添加列表数据,如果不存在则会新建一个新的列表并添加数据。
127.0.0.1:6379> lpush list 1 2 3 4 5 6 7 8 9
9
127.0.0.1:6379> lpush list ac ql
11
2、LRANGE:
lrange:从列表左边获取指定区间的数据。
127.0.0.1:6379> lrange list 0 -1
ql
ac
9
8
7
6
5
4
3
2
1
127.0.0.1:6379> lrange list 4 9
7
6
5
4
3
2
3、RPUSH:
rpush:从列表右边添加数据。
127.0.0.1:6379> rpush ll 1 2 3 4 5 6 7 8 9
9
127.0.0.1:6379> lrange ll 0 -1
1
2
3
4
5
6
7
8
9
4、LLEN:
llen:获取列表的长度。
127.0.0.1:6379> llen ll
9
127.0.0.1:6379> llen list
11
5、LINDEX:
lindex:通过列表的下标获取对应位置上的数据。
127.0.0.1:6379> lindex list -1
1
127.0.0.1:6379> lindex list 5
6
127.0.0.1:6379> lindex list 1
ac
6、LSET:
lset:重新设置列表指定位置上的数据。
127.0.0.1:6379> lset ll 0 aa
OK
127.0.0.1:6379> lindex ll 0
aa
7、LPOP、RPOP:
lpop:从列表的左边开始移除数据
rpop:从列表的右边开始移除数据
会返回被移除的数据
127.0.0.1:6379> lpop ll
aa
127.0.0.1:6379> rpop ll
9
8、LTRIM:
ltrim:截取指定列表的某一个区间的数据,重新保存,不在区间范围内的数据会删除。
127.0.0.1:6379> ltrim list 0 4
OK
127.0.0.1:6379> lrange list 0 4
ql
ac
9
8
7
127.0.0.1:6379> lrange list 0 -1
ql
ac
9
8
7六、Set 类型:
Set 类型:无序集合,数据唯一。
1、SADD:
sadd:添加集合中的元素。
127.0.0.1:6379> sadd jihe 1 11 21 31
(integer) 4
2、SMEMBERS:
smembers:获取集合中的所有元素。
127.0.0.1:6379> smembers jihe
1) "1"
2) "11"
3) "21"
4) "31"
3、SCARD:
scard:查询集合中的元素个数。
127.0.0.1:6379> scard jihe
(integer) 4
4、SISMEMBER:
sismember:判断指定的元素是否在集合中。
127.0.0.1:6379> sismember jihe 51
(integer) 0 # 元素不存在
127.0.0.1:6379> sismember jihe 11
(integer) 1 # 元素存在
5、SREM:
srem:删除集合中指定的元素。
127.0.0.1:6379> srem jihe 1
(integer) 1
127.0.0.1:6379> srem jihe 11 31
(integer) 2
6、SPOP:
spop:随机删除集合中的元素 , 可以指定删除元素的个数,不写默认删除一个
127.0.0.1:6379> spop jihe
"41"
127.0.0.1:6379> spop jihe 2
1) "11"
2) "1"
7、SRANDMEMBER:
srandmember:随机返回集合中的某个元素 , 可以指定返回元素的个数,不写默认返回一个。
127.0.0.1:6379> srandmember jihe
"91"
127.0.0.1:6379> srandmember jihe 3
1) "81"
2) "21"
3) "71"
8、SMOVE:
smove:将集合 A 中的元素移动到集合 B 中。
127.0.0.1:6379> smembers jihe
1) "21"
2) "31"
3) "51"
4) "61"
5) "71"
6) "81"
7) "91"
127.0.0.1:6379> smove jihe B 91
(integer) 1
127.0.0.1:6379> smembers B
1) "91"
127.0.0.1:6379> smembers jihe
1) "21"
2) "31"
3) "51"
4) "61"
5) "71"
6) "81"
9、SDIFF:
sdiff:返回集合的差集。
127.0.0.1:6379> sdiff jihe B # 计算 集合 jihe 独有的元素
1) "31"
2) "51"
3) "61"
4) "71"
5) "81"
127.0.0.1:6379> sdiff B jihe # 计算 集合 B 独有的元素
1) "1"
2) "22"
3) "32"
4) "60"
5) "72"
6) "91"
sdiffstore:计算集合的差集 , 会计算得到的差集结果保存为一个新的集合。
127.0.0.1:6379> sdiffstore AB B jihe
(integer) 6
127.0.0.1:6379> smembers AB
1) "1"
2) "22"
3) "32"
4) "60"
5) "72"
6) "91"
10、SINTER:
sinter:计算两个集合的交集。
127.0.0.1:6379> sinter B jihe
1) "21"
sinterstore:计算集合的交集, 会计算得到的交集结果保存为一个新的集合。
127.0.0.1:6379> sinterstore jab B jihe
(integer) 1
127.0.0.1:6379> smembers jab
1) "21"
11、SUNION:
sunion:计算两个集合的并集。
127.0.0.1:6379> sunion jihe B1) "1"2) "21"3) "22"4) "31"5) "32"6) "51"7) "60"8) "61"9) "71"
10) "72"
11) "81"
12) "91"
sunionstore:计算集合的并集, 会计算得到的并集结果保存为一个新的集合。
127.0.0.1:6379> sunionstore bab jihe B
(integer) 12
127.0.0.1:6379> smembers bab1) "1"2) "21"3) "22"4) "31"5) "32"6) "51"7) "60"8) "61"9) "71"
10) "72"
11) "81"
12) "91"
七、ZSet 类型
ZSet 类型:有序集合 , 和 Set 集合一样的是,数据不允许重复。
不同的是每个元素都会一个 double 类型的数据和集合中的元素进行对应,在 Redis 数据库中就是通过这个 double 类型的数据来对集合中的数据进行排序。
集合的元素必须是唯一的,但是这个元素关联的 double 类型数据可以重复。
1、ZADD:
zadd:向有序集合中添加数据。
127.0.0.1:6379> zadd stu 66 ac 77 ql
(integer) 2
2、ZRANGE:
zrange:获取集合中指定区间的元素。
在结果中要获取到定义的 double 类型数据则在命令最后添加 withscores。
127.0.0.1:6379> zrange stu 0 -1
1) "ac"
2) "ql"
127.0.0.1:6379> zrange stu 0 -1 withscores
1) "ac"
2) "66"
3) "ql"
4) "77"
127.0.0.1:6379> zadd stu 10 ac
(integer) 0 # 元素存在不会添加 , 但是会修改掉元素对应的关联的数据
127.0.0.1:6379> zrange stu 0 -1 withscores
1) "ac"
2) "10"
3) "ql"
4) "77"
3、ZCARD:
zcard:返回集合的元素个数。
127.0.0.1:6379> zcard stu
(integer) 2
4、ZCOUNT:
zcount:统计有序集合中关联数据在指定的范围内的元素个数。
127.0.0.1:6379> zcount stu 1 10
(integer) 4
127.0.0.1:6379> zcount stu 10 20 # 10 <= stu <= 20
(integer) 5
127.0.0.1:6379> zcount stu 10 (20 # 10 <= stu < 20
(integer) 4
127.0.0.1:6379> zcount stu (10 (20 # 10 < stu < 20
(integer) 3
5、ZRANGEBYSCORE:
zrangebyscore:获取有序集合中关联数据在指定范围内的元素。
127.0.0.1:6379> zrangebyscore stu 10 20
1) "ac"
2) "w"
3) "s"
4) "d"
5) "sd"
127.0.0.1:6379> zrangebyscore stu 10 20 withscores1) "ac"2) "10"3) "w"4) "11"5) "s"6) "14"7) "d"8) "18"9) "sd"
10) "20"
6、ZRANK:
zrank:获取元素在有序集合中的排序下标 , 关联数据从小到大的排序。
127.0.0.1:6379> zrank stu ac
(integer) 3
127.0.0.1:6379> zrank stu a
(integer) 0
zrevrank:获取元素在有序集合中的排序下标 , 关联数据从大到小的排序。
127.0.0.1:6379> zrevrank stu ac
(integer) 5
127.0.0.1:6379> zrevrank stu a
(integer) 8
八、Hash 类型
Hash 类型存储是一个 String 类型的 field 和 value 映射关系。
1、HSET:
hset:设置 hash 类型的数据。
# hls = {"name":'ac'}
127.0.0.1:6379> hset hls name ac
(integer) 1
2、HGET:
hget:获取 hash 类型中的数据。
127.0.0.1:6379> hget hls name
"ac"
3、HMSET 、 HMGET:
hmset:批量设置多个 hash 数据值。
hmget:批量获取多个 hash 数据值。
127.0.0.1:6379> hmset hls age 28 gender man adder China
OK
127.0.0.1:6379> hmget hls name age gender
1) "ac"
2) "28"
3) "man"
4、HDEL:
hdel: 删除指定的数据。
127.0.0.1:6379> hdel hls gender
(integer) 1
5、HVALS:
hvals:获取指定的 hash 数据中的所有数据。
127.0.0.1:6379> hvals hls
1) "ac"
2) "28"
3) "China"
6、HKEYS:
hkeys:获取指定的 hash 数据中的所有字段名。
127.0.0.1:6379> hkeys hls
1) "name"
2) "age"
3) "adder"
7、HEXISTS:
hexists:判断指定的 key 中的字段是否存在。
127.0.0.1:6379> hexists hls name
(integer) 1
127.0.0.1:6379> hexists hls gender
(integer) 0 # 返回 0 : 表示数据不存在
8、HSETNX:
hsetnx:在设置字段值的时候,如果字段存在则忽略这个命令 , 字段不存在则执行该命令。
127.0.0.1:6379> hsetnx hls age 50
(integer) 0
127.0.0.1:6379> hvals hls
1) "ac"
2) "28"
3) "China"
127.0.0.1:6379> hsetnx hls height 1.82
(integer) 1
127.0.0.1:6379> hvals hls
1) "ac"
2) "28"
3) "China"九、事务管理:
NOSQL 给 Redis 提供了事务机制。
Redis 的事务是一次性,顺序性的。和关系型数据库中的事务相比,在Redis 的事务中如果一条命令失败,那么其他命令不受影响会继续执行。
关系型数据库的事务:要么全部都执行 , 要么全部都不执行(原子性)。
Redis 不保证原子性 , Redis 中的事务是没有回滚。
Redis 的事务没有隔离级别的概念
批量操作发送 EXEC 命令之前被放入到一个队列中缓存,并不会被实际执行,也就是不存在不同事务之间的查询看到事务内更新的数据,事务外事查询不到的。
Redis 的事务通过 MULTI 命令开启事务 , 通过 EXEC 命令提交事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name acac
QUEUED
127.0.0.1:6379> set age 38
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
127.0.0.1:6379> mget name age
1) "acac"
2) "38"
Redis 事务中在操作命令进入队列前发送错误是不可以提交,队列中的所有操作都无效。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k k
QUEUED
127.0.0.1:6379> ste u u
(error) ERR unknown command `ste`, with args beginning with: `u`, `u`,
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k
(nil)
Redis 事务中的操作命令进入队列之后发生的错误,事务是可以提交的,但是不保证提交的命令都能执行成功。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k k
QUEUED
127.0.0.1:6379> set u u
QUEUED
127.0.0.1:6379> set k ac i
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) (error) ERR syntax error
127.0.0.1:6379> mget k u
1) "k"
2) "u"十、Python连接数据库:
1、安装第三方模块:
在cmd中:
pip install redis在pycharm中安装模块:redis就可以。
2、使用Redis:
import redis# 创建 Redis 连接池
pool = redis.ConnectionPool(decode_responses=True , max_connections=10)# 从 Redis 连接池中获取一个链接进行使用
conn = redis.Redis(connection_pool=pool)conn.set('name' , 'ql')
print(conn.get('name'))conn.lpush('ls' , 2 , 32 , 22)
print(conn.lrange('ls', 0, -1))十一、Django 连接 Redis:
1、安装第三方模块:
在cmd中:
pip install django_redis在Pycharm中:
下载django-redis安装就可以。
2、django 在配置文件中配置连接 Redis 数据库信息:
在setting.py文件底下:
注意可以配置多个Redis数据库,配置时候数据库名字是0-15,关于session会话的内容存储也是一样,只不过需要额外修改默认存储机制。
# 配置 Redis 缓存数据库信息
CACHES = {# 默认使用的 Redis 数据库"default" : {# 配置数据库引擎"BACKEND" : "django_redis.cache.RedisCache",# 配置使用 Redis 的数据库名称"LOCATION" : "redis://127.0.0.1:6379/0","OPTIONS" : {"CLIENT_CLASS" : "django_redis.client.DefaultClient"}},# 将 session 的数据保存位置修改到 Redis 中"session" : {# 配置数据库引擎"BACKEND" : "django_redis.cache.RedisCache",# 配置使用 Redis 的数据库名称"LOCATION" : "redis://127.0.0.1:6379/1","OPTIONS" : {"CLIENT_CLASS" : "django_redis.client.DefaultClient"}},
}
# 修改 session 默认的存储机制
SESSION_ENGINE = "django.contrib.sessions.backends.cache"
# 配置 session 要缓存的数据库引擎
SESSION_CACHE_ALIAS = "session"3、启动Django:
注意:
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'django_auth.settings')它在manage.py文件下查找。
在text.py文件下:
if __name__ == '__main__':import osos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'django_auth.settings')import djangodjango.setup()from django_redis import get_redis_connection# 获取要链接的数据库,没有写参数默认使用配置文件中的默认数据库# 参数:就是配置 Redis 的数据库引擎名称# conn = get_redis_connection()conn = get_redis_connection('session')conn.set('gender' , 'boy')print(conn.get('gender').decode())十二、总结:
该篇博客详细的介绍了Redis数据库的内容,从简介到语句,再到应用到Python与Django中。若是各位大佬发现需要补充的地方,欢迎各位指正,小编后续还会继续更新优质好文,您的关注和点赞将是我变强的最大动力。
这篇关于最全!最新!最细!Redis数据库从入门到应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









