本文主要是介绍生命在于学习——Python人工智能原理(3.1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

三、深度学习

(一)深度学习的概念
1、深度学习的来源
深度学习的概念来源于人工神经网络,所以又称深度神经网络。
人工神经网络主要使用计算机的计算单元和存储单元模拟人类大脑神经系统中大量的神经细胞(神经元)通关神经纤维传导并相互协同工作的原理。深度学习在一定程度上等同于多层或者深层神经网络。
2、深度学习的定义
所谓深度是指原始数据进行非线性特征转换的次数,如果把一个表示学习系统看作一个有向图结构,深度也可以看作从输入节点到输出节点所经过的最长路径的长度。这样我们就需要一种学习方法可以从数据中学习一个深度模型,这就是深度学习。
深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示。
3、深度学习的分类
(1)监督学习
将训练样本的数据加入到神经网络的输入端,将期望答案和实际输出作差,可以得到误差信号,通过得到的误差信号调整权值大小,以此来优化模型输出。
(2)无监督学习
不给定数据标签,直接训练数据,模型根据数据特征进行自动学习。
无监督学习算法训练含有很多特征的数据集X,在该数据集上学习出有用的结构性质。在深度学习中,通常学习生成数据集的整个概率分布,显式的如概率估计,隐式的如合成或去噪。
(3)半监督学习
介于有监督和无监督之间,不需要给定具体的数据标签,但需要对神经网络的输出进行评价,以此来调整网络参数。
4、深度学习的常用模型举例
典型的深度学习模型有卷积神经网络、循环神经网络、长短时记忆网络、深度执行网络模型等。
5、深度学习的步骤
原始数据——底层特征——中层特征——高层特征——预测——结果
其中。底层特征-中层特征-高层特征为表示学习,底层特征-中层特征-高层特征-预测为深度学习。
和浅层学习不同,深度学习需要解决的关键问题是贡献度分配问题,即一个系统中不同的组件或其参数对最终系统输出结果的贡献或影响。
6、深度学习的训练过程
对深度学习的所有层同时进行训练,复杂度会很高,如果每次只训练一层,偏差就会逐层传递。
总体来说,训练过程分为两步:
(1)使用自下而上的非监督学习
采用无标签或有标签数据分层训练各层参数,这一步可以看成无监督训练过长,或者特征学习过程。
先用数据学习第一层,学习第一层的参数,在学习并得到N-1层后,将N-1的输出作为第N层的输入,训练第N层,从而得到各层的参数。
(2)自顶而下的监督学习
基于(1)中学到的各层参数进一步调整多层模型的参数,这是一个有监督的过程。
第一步类似神经网络的随机初始化初值过程,由于深度学习的第一步不是随机初始化,而是通过学习输入数据的结构得到,因而这个初值更接近全局最优,从而能够取得更好的效果,所以深度学习效果好在很大程度上归功于第一步的特征学习过程。
7、深度学习与浅层学习
相较于传统的浅层学习,深度学习的不同之处在于:
(1)强调了模型结构的深度
通常有5、6层,甚至十几层的隐层节点。
(2)明确了特征学习的重要性
8、深度学习与传统机器学习
端到端学习,也称端到端训练,是指在学习过程中不进行分模块或分阶段训练,直接优化任务的总体目标,目前大部分采用神经网络模型的深度学习也可以看作一种端到端的学习。
相比传统的机器学习,深度学习有更好的特征学习能力,在传统的机器学习算法中需要手工编码特征,相比之下深度学习对特征的识别由算法自动完成,机器学习的这个处理过程不仅耗时,而且还需要较高的专业知识和一定的人工参与才能完成。而深度学习通过大数据技术直接从数据中自动学习各种特征并进行分类或者识别,做到全自动数据分析。
9、深度学习的发展及重要人物介绍
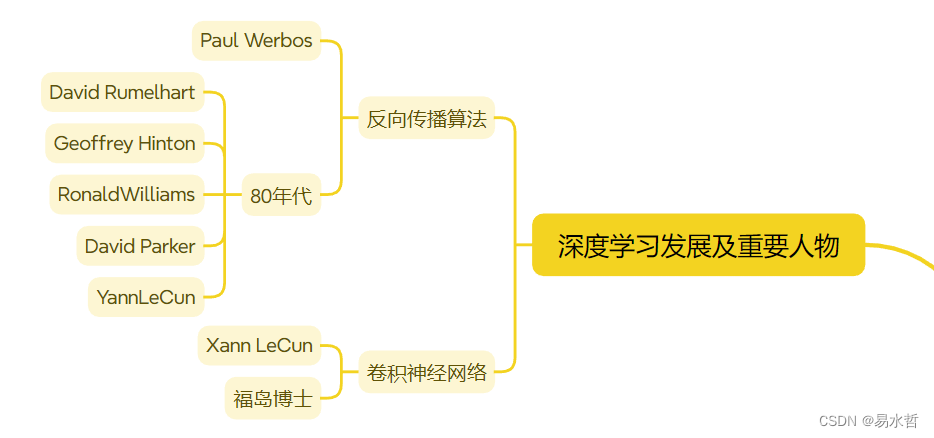
(1)反向传播算法
简称BP,是一种监督学习算法,常被用来训练多层感知机。
于1974年,Paul Werbos首次给出了如何训练一般网络的学习算法,而人工神经网络只是其中的特例,直到80年代中期,David Rumelhart、Geoffrey Hinton、RonaldWilliams、David Parker和YannLeCun提出多层网络中的反向传播算法,引起人工神经网络领域研究的第二次热潮。
(2)卷积神经网络
是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。
现代卷积神经网络的创始人是计算机科学家Xann LeCun,他是第一个通过卷积神经网络在MNIST数据集上解决手写数字问题的人。
严格意义上讲,LeCun是第一个使用误差反向传播训练卷积神经网络架构的人,但他不是第一个发明这个结构的人,福岛博士引入的Neocognitron,是第一个使用卷积和采样的神经网络,也是卷积神经网络的雏形。
这篇关于生命在于学习——Python人工智能原理(3.1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







