本文主要是介绍数据库系统概论(超详解!!!)第十节 过程化SQL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
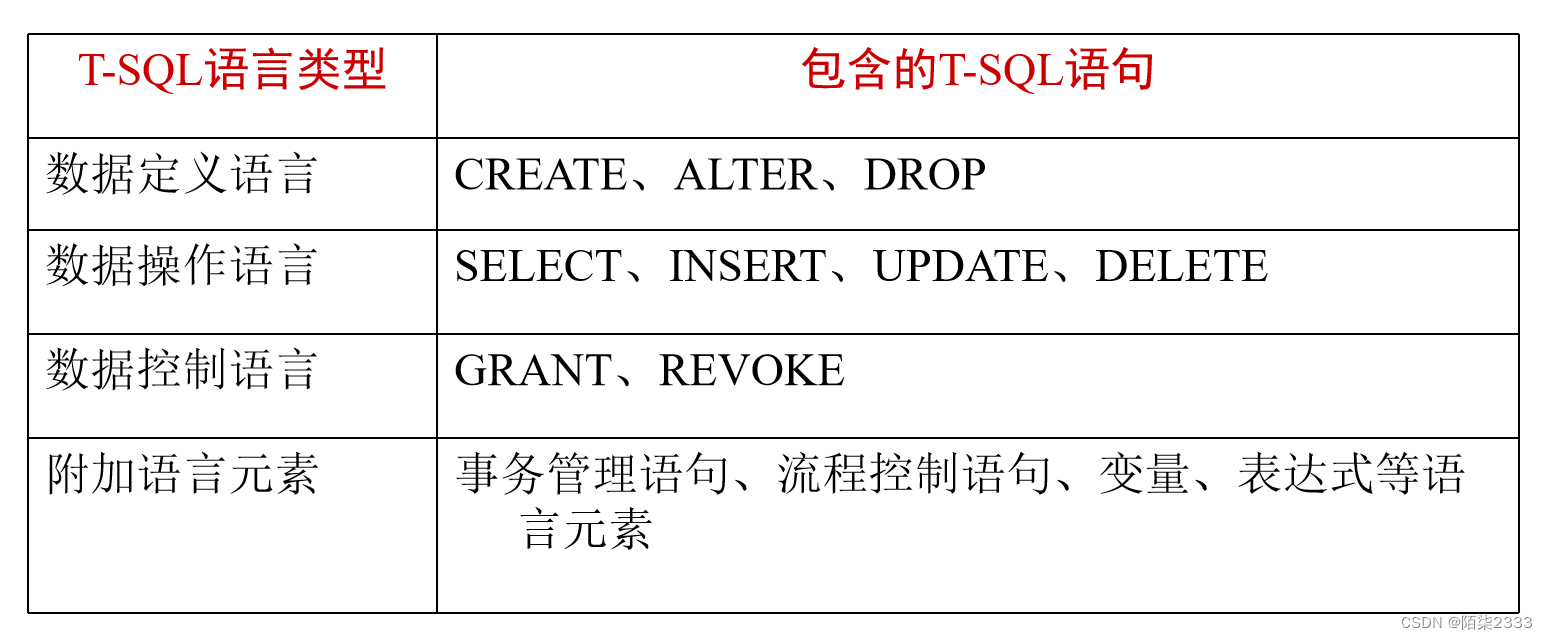
1.Transact-SQL概述
SQL(Structure Query Language的简称,即结构化查询语言) 是被国际标准化组织(ISO)采纳的标准数据库语言,目前所有关系数据库管理系统都以SQL作为核心,在JAVA、VC++、VB、Delphi等程序设计语言中也可使用SQL,它是一种真正跨平台、跨产品的语言。
2.Transact-SQL基础
1.标识符
标识符是指用户在Microsoft SQL Server 2005中定义的服务器、数据库、数据库对象(例如表、视图、列、索引、触发器、过程、约束及规则等)、变量和列等对象的名称。
标识符可以分为常规标识符和分隔标识符两类。
(1)常规标识符
符合标识符命名规则的,在Transact-SQL 语句中使用时不用将其分隔的标识符称为常规标识符。
标识符的命名规则:
① 标识符长度可以为1~128个字符。
② 标识符的首字符必须为Unicode 3.2标准所定义的字母、下划线(_)、at符号(@)、和数字符号(#)。
③ 后续字母可以为Unicode 3.2标准所定义的字符、0-9数字或下划线(_)、at符号(@)、数字符号(#)、美元符号($)。
④ 标识符内不能嵌入空格或其他特殊字符。 ⑤ 标识符不能与SQL Server中的保留关键字同名。
例如,下面SELECT语句中的表标识符StuInfo和列标识符SID均为常规标识符。
SELECT * FROM StuInfo WHERE SID ='05000004'
(2)分隔标识符
分隔标识符允许在标识符中使用SQL Server保留关键字或常规标识符中不允许使用的一些特殊字符,这时该标识符应包含在双引号(“”) 或者方括号 ([ ]) 内。
符合标识符命名规则的标识符可以分隔,也可以不分隔。
例如,下列语句由于所创建的表名My Table中包含空格,列名order与T-SQL保留字相同,因此均要用方括号来分隔。
SELECT *
FROM [My Table]
WHERE [order] = 10
说明: 分隔标识符的分隔符在默认情况下,只能使用方括号([ ])作为分隔符,当QUOTED_IDENTIFIER选项设置为ON时,才能使用引号("")作为分隔符。
2.变量
在SQL Server 中,变量由系统或用户定义并赋值,被用来在语句间传递数据的方式之一。 Transact-SQL可以两种变量,一种是局部变量,另一种是全局变量。它们的主要区别在于存储的数据作用范围不同。
(1)局部变量
局部变量是用户可以自定义的变量,它的作用范围仅限于定义该变量的程序中使用。
局部变量必须先定义后使用,变量名必须以“@”开头,且必须符合SQL Server标识符的命名规则。局部变量在程序中常用来存储从表中查询结果,或当作程序执行过程中暂存变量使用。
① 局部变量的声明
局部变量用DECLARE语句声明,其语法格式如下:
DECLARE @variable_name datatype [,…n]
参数说明:
@variable_name:是声明的变量名。
Datatype:变量的数据类型,可以是除text、ntext和image类型以外所有的系统数据类型或用户定义数据类型,如果没有特殊用途,建议尽量使用系统数据类型。
② 局部变量的赋值
在Transact-SQL语言中不能像在一般程序语言中一样直接使用“变量名=变量值”来给变量赋值,用户可在与定义变量的DECLARE语句同一批处理中用SET语句或SELECT语句为其赋值。
用SET语句给变量赋值:
格式: SET @variable_name =expression
参数说明:
expression:给变量赋值的有效表达式,与局部变量@variable_name的数据类型相匹配。
用SELECT语句给变量赋值:
格式:
SELECT @variable_name =expression [,…n]
[FROM table_name
Where condition]
③局部变量的输出
局部变量可以使用Print语句或SELECT语句输出。Print语句一次只能输出一个变量的值,而SELECT语句一次可以输出多个变量的值。
用PRINT语句输出变量的语法格式如下: PRINT @variable_name
用SELECT语句输出变量的语法格式如下: SELECT @variable_name [,…n]
定义两个变量@var1和@course_name,使用常量直接为其赋值,并输出。
--声明局部变量
DECLARE @var1 int, @course_name char(15)
--给局部变量赋值
SET @var1=100
SELECT @course_name = '数据库原理'
--输出局部变量
Print @var1
Print @course_name定义两个变量@Max_Score和@Min_Score,将SC表中的最高分和最低分分别赋给这两个变量。
--声明局部变量
DECLARE @Max_Score int, @Min_Score int
--为变量赋值
SELECT @Max_Score =MAX(grade),@Min_Score =MIN(grade)FROM SC
SELECT @Max_Score as 最高分,@Min_Score as 最低分
(2)全局变量
它是SQL Server内部事先定义好的变量,用户不能定义或赋值,对用户而言是只读的。
全局变量在任何程序中可随时调用。全局变量通常存储一些SQL Server的配置设定值和统计数据。使用全局变量来记录SQL Server 服务器的活动状态信息。用户可以在程序中调用全局变量来测试系统的设定值或者是Transact-SQL命令执行后的状态值。 全局变量的名字以“@@”开头。
SQL Server 提供的全局变量共33个,一部分是与当前的SQL Server连接或与当前的处理相关的全局变量,如@@rowcount表示最近一个语句影响的记录数;另一部分是与系统内部信息有关的全局变量,如@@version表示SQL Server的版本信息。
有关SQL Server中其它全局变量及其功能可参看系统帮助。
在UPDATA语句中使用@@rowcount变量来检测是否存在发生更改的记录。
USE SCC
GO
--将选修课程“1”的每个学生的成绩增加5分
UPDATE SC
SET grade= grade+5
WHERE cno ='1'
--如果没有发生记录更新,则发生警告信息
IF @@rowcount=0
Print '警告:没有发生记录更新!' /* Print语句将字符串返回给客户端*/
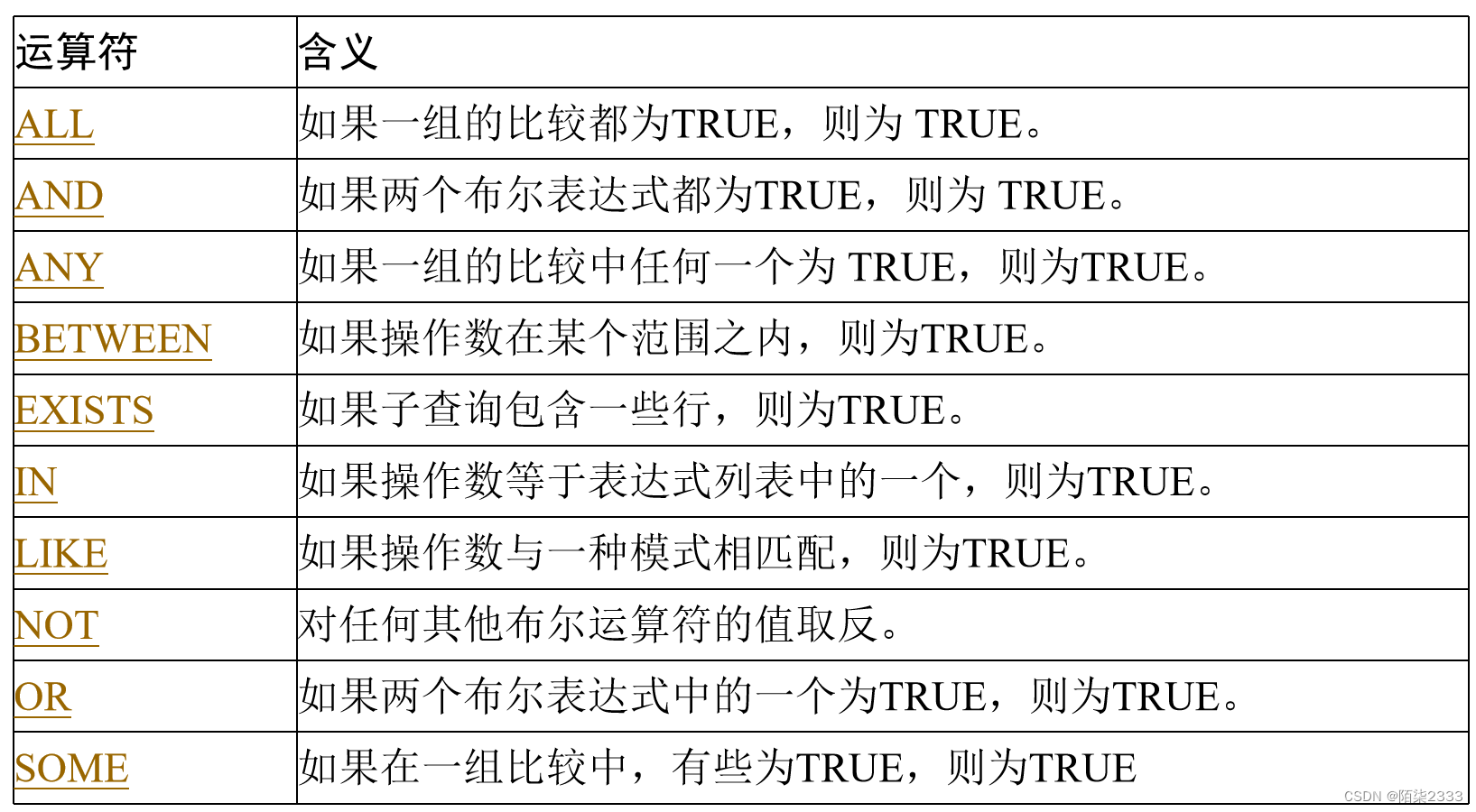
3.运算符
运算符是一种特殊符号,用来指定要在一个或多个表达式中执行的操作。
在SQL Server中的运算符: 算术运算符 、赋值运算符 、字符串连接运算符、 比较运算符 、逻辑运算符、 位运算符。
(1)算术运算符
Transact-SQL支持的算术运算符有:加(+)、减(-)、乘(*)、除(/)、取模(%)。
注意: 取模运算两边的表达式必须是整型数据。
(2)赋值运算符
赋值运算符(=)是将表达式的值赋给一个变量。它通常用于SET和SELECT语句中。
(3)字符串连接运算符
字符串连接运算符(+)用于将字符串或字符型变量串接起来。
说明: 默认情况下,对于varchar数据类型的数据,在连接VARCHAR、CHAR或TEXT类型的数据时,在默认设置情况下空的字符串被解释为空字符串,例如'abc'+''+'def'被存储为'abcdef'。但是,如果兼容级别设置为65,则空字符串将作为单个空白字符处理,'abc'+‘ '+'def'将被存储为'abc def'。
如果希望结果为‘abc def’,则可以使用space函数: ‘abc’+space(1)+‘def’
(4)比较运算符
Transact-SQL支持的比较运算符有:大于(>)、等于(=)、小于(<)、大于等于(>=)、小于等于(<=)、不等于(<>)、不等于(!=或<>)、不大于(!>)、不小于(!<)。
其中!=、!>、!<不是ANSI标准的运算符。
比较的结果是布尔数据类型,包括TRUE、FALSE和UNKNOWN。
(5)逻辑运算符
(6)位运算符
位运算符在两个表达式之间执行位操作,这两个表达式可以为整数数据类型或二进制数据类型(Image数据类型除外)。
位运算符包括:与(&)、或(|)、异或(^)、求反(~)等逻辑运算。
(7)在SQL Server中运算符的优先级
(1) ( )
(2) +(正)、-(负)、~(按位NOT)
(3) *(乘)、/(除)、%(模)
(4) +(加)、+(连接)、-(减)
(5) =、>、<、>=、<=、<>、!=、!>和!<(比较运算符)
(6) ^(位异或)、 &(位与)、|(位或)
(7) NOT
(8) AND
(9) OR、ALL、ANY、BETWEEN、IN、LIKE、SOME
(10) =(赋值)
4.函数
SQL Server提供了大量的内置系统函数,包括数学函数、字符串函数、数据类型转换函数和日期函数等几类。
SQL Server还支持用户定义函数,在系统函数不能满足需要的情况下,用户可以创建、修改和删除用户定义函数。
(1)内置系统函数
数学函数
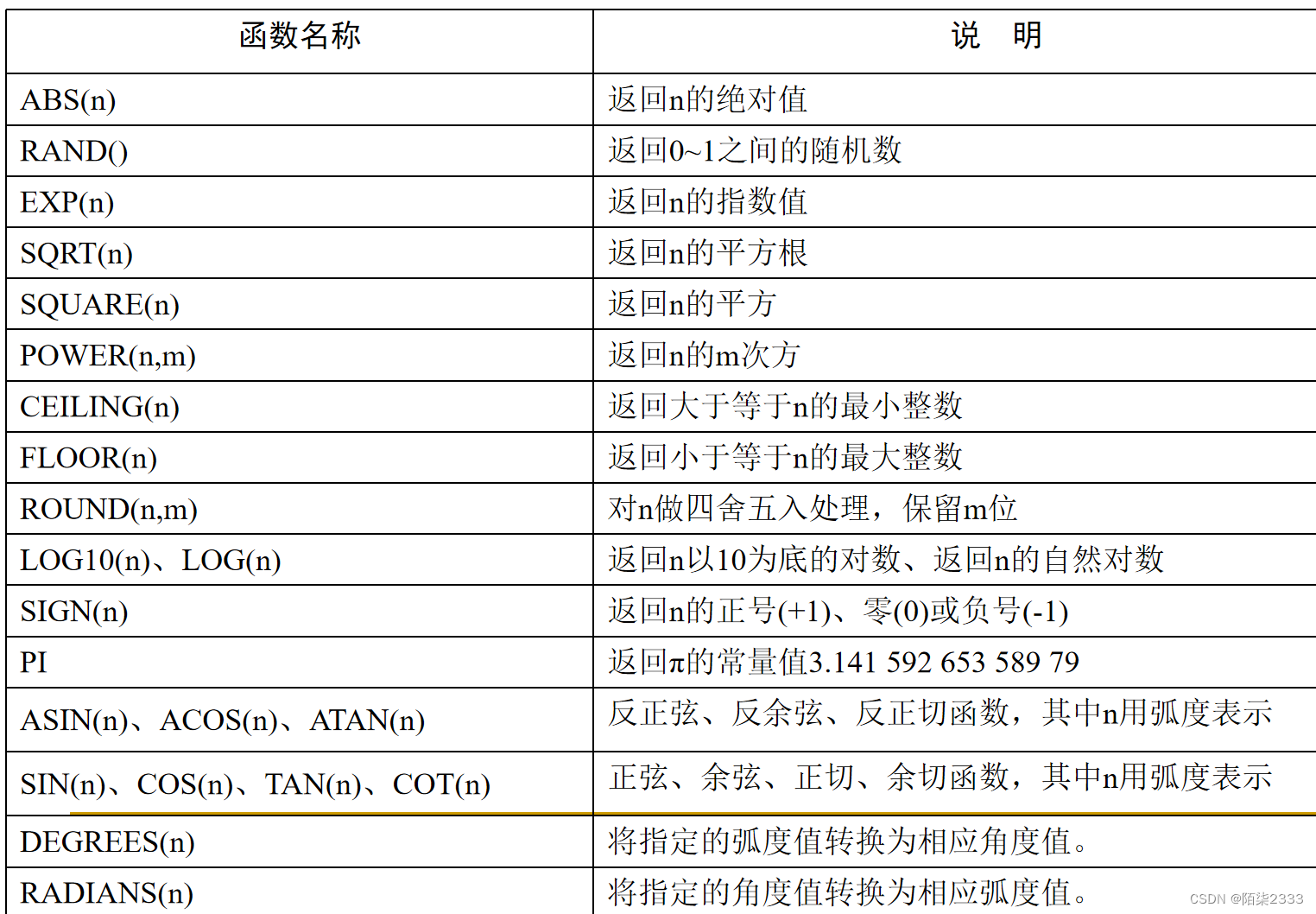
分析比较下列语句的执行结果,正确理解CEILING(n)、FLOOR(n)、ROUND(n,m)三个数学函数的功能。
在SQL的查询窗口中输入:
SELECT ‘Select1’,CEILING(8.4),FLOOR(8.4),ROUND(8.456,2)
SELECT ‘Select2’,CEILING(8.4),CEILING(-8.4)
SELECT ‘Select3’,FLOOR(8.6),FLOOR(-8.6)字符串函数
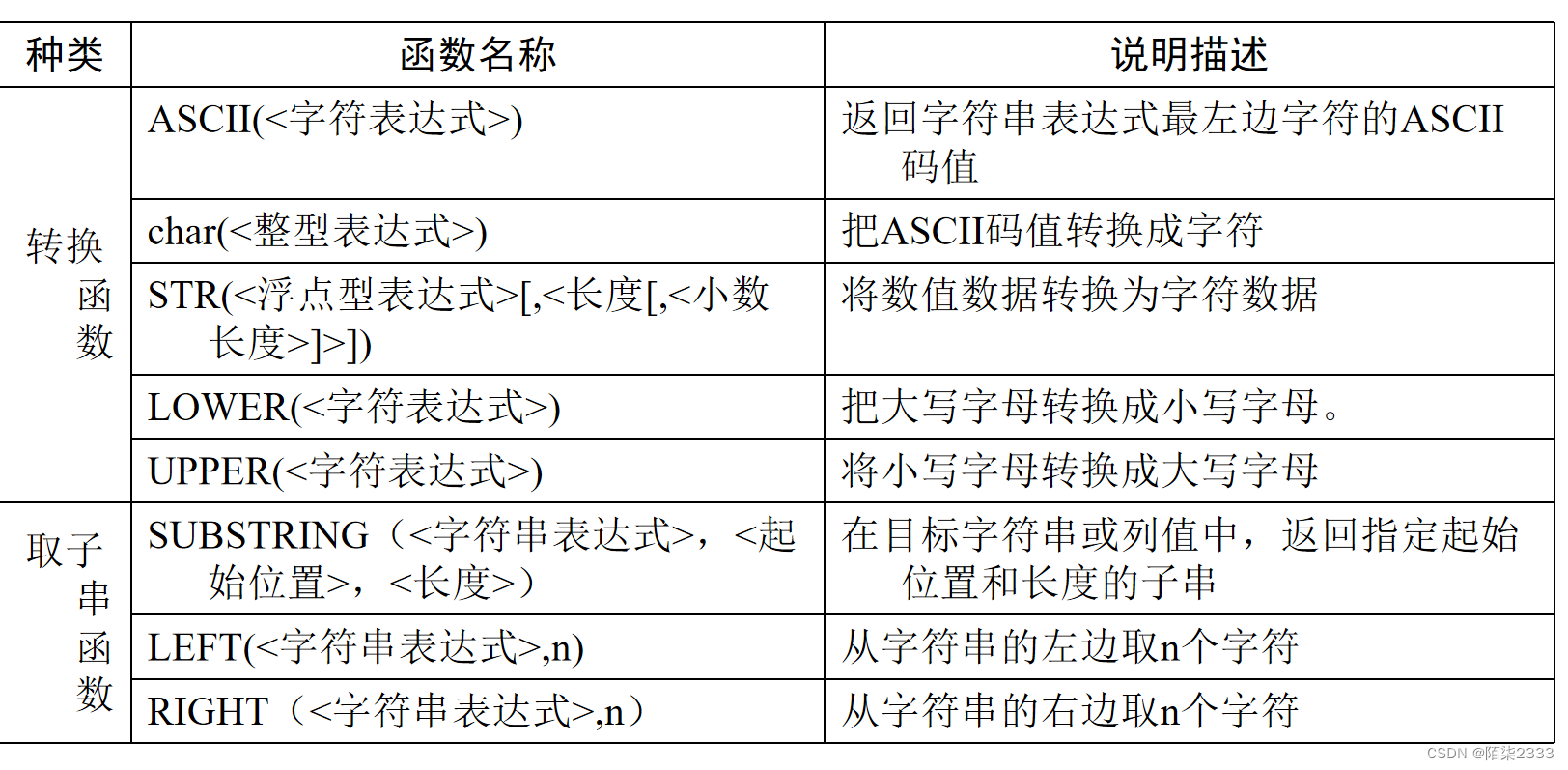

分析下列函数的执行结果,正确理解字符串函数的功能。
在SQL的查询窗口中输入:
SELECT REPLICATE('abc',3)
SELECT REPLACE('abcdefgbcd','bcd','12')
SELECT STUFF('abcdefgbcd',2,4,'12')
数据类型转换函数
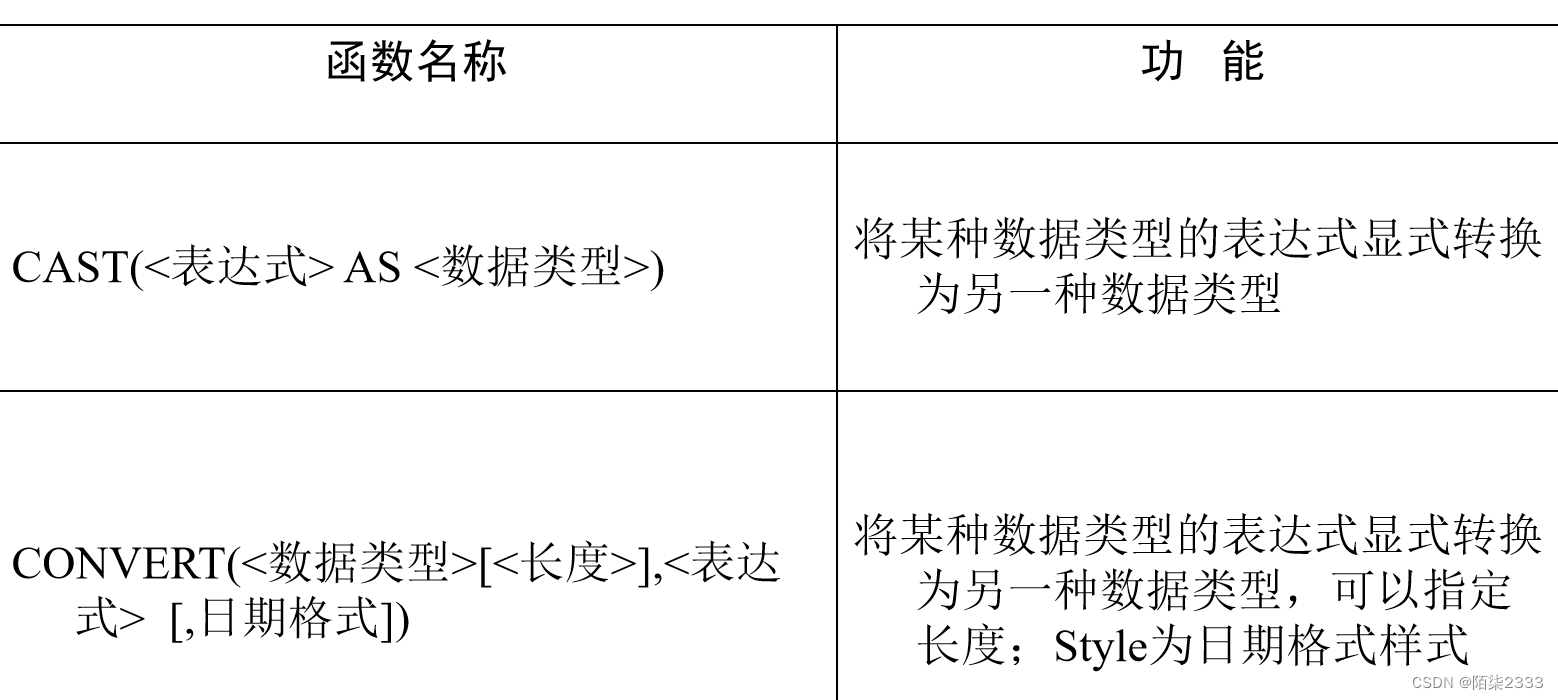
日期函数
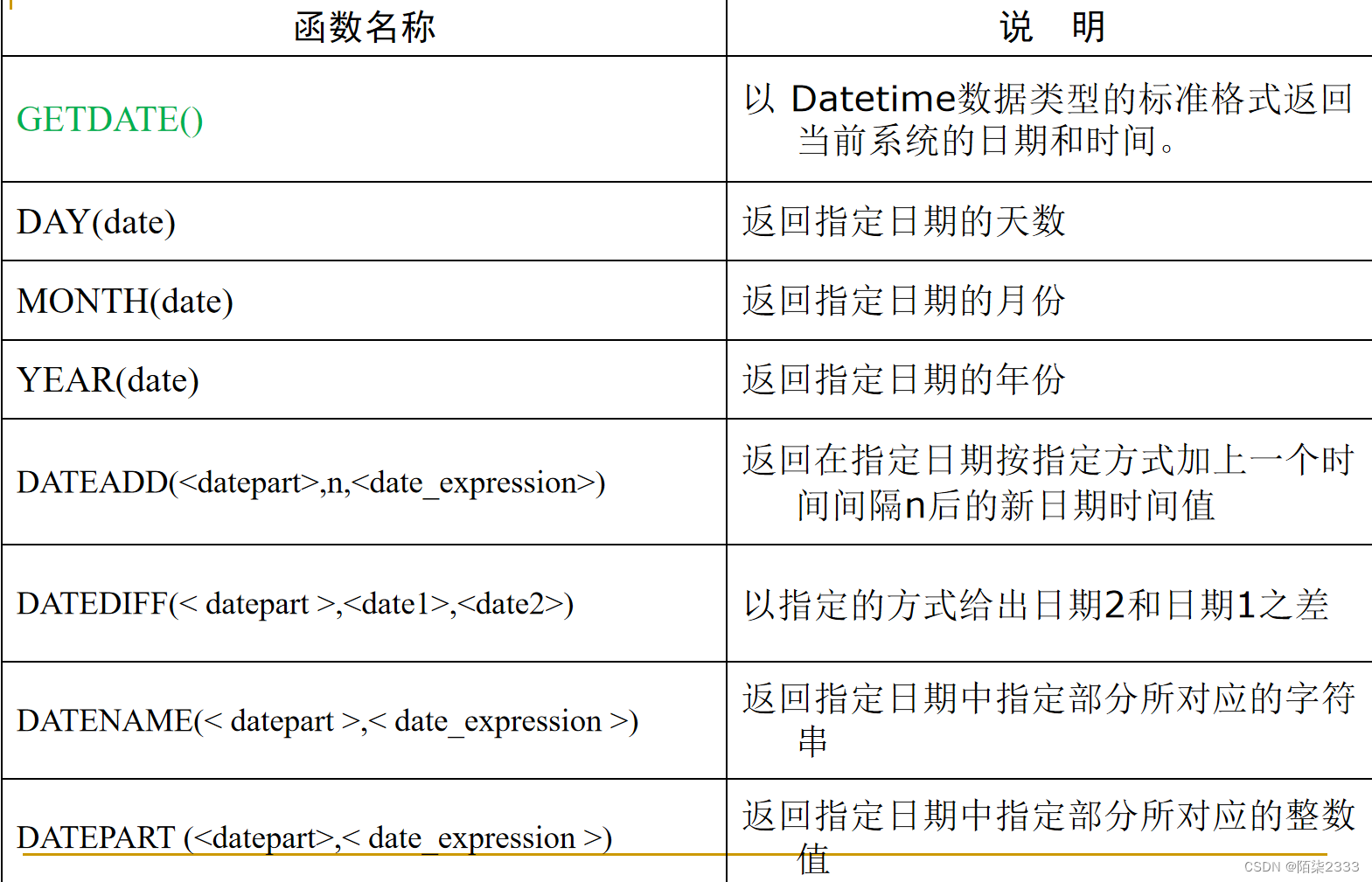

查看当前日期为本年中的第几天。
print datepart(dy,getdate())获取当前年份和当前月份。
SELECT YEAR(GETDATE() )
as 当前年份,MONTH(GETDATE()) as 月份在StuInfo表中,查询所有年满19岁的学生学号、姓名、性别、年龄和所在系部。
SELECT SID,Sname,Sex,DATEDIFF(yy,Birthday,GETDATE())
as Sge,Dept
FROM StuInfo
Where DATEDIFF(yy,Birthday,GETDATE())>19使用 CAST 数据类型转换函数Score转换为字符型,并实现字符串连接运算。
SELECT sno
as 学号,‘成绩是:’ + CAST(grade AS VARCHAR(3)) as 成绩
FROM sc
WHERE grade> 85
(2)用户自定义函数
用户在编写程序的过程中,除了可以调用系统函数外,还可以根据应用需要自定义函数,以便用在允许使用系统函数的任何地方。
用户自定义函数包括表值函数和标量值函数两类,其中表值函数又包括内联表值函数和多语句表值函数。
标量值函数:返回一个确定类型的标量值。其返回类型为除TEXT、NTEXT、IMAGE、CURSOR、TIMESTAMP和TABLE类型以外的其他数据类型。函数体语句定义在BEGIN—END语句内。 内联表值函数:返回值是一个表。
内联表值函数没有由BEGIN—END语句括起来的函数体,其返回的表由一个位于RETURN语句中的SELECT语句从数据库中筛选出来。内联表值函数的功能相当于一个参数化的视图。
多语句表值函数:返回值是一个表。函数体包括多个SELECT语句,并定义在BEGIN…END语句内。
① 标量函数
创建标量函数语法格式:
CREATE FUNCTION function_name
(@Parameter scalar_ parameter_data_type[=default],[…n])
RETURNS scalar_ return_data_type
AS
BEGINFunction bodyRETURN scalar _expresstion
END
参数说明:
function_name:指定要创建的函数名。
@Paramete:为函数指定一个或多个标量参数的名称。
scalar_ parameter_data_type:指定标量参数的数据类型。
default:指定标量参数的默认值。
scalar_ return_data_type:指定标量函数返回值的数据类型。
Function body:指定实现函数功能的函数体。
scalar _expresstion:指定标量函数返回的标量值表达式。
创建一个标量函数,该函数返回两个参数的最大值。
CREATE FUNCTION My_Max(@X REAL,@Y REAL)
RETURNS REAL
AS
BEGINDECLARE @Z REALIF @X>@YSET @Z=@XELSESET @Z=@YRETURN(@Z)
END
②内联表值函数
创建内联表值函数语法格式如下:
CREATE FUNCTION function_name
(@Parameter scalar_ parameter_data_type[=default],[…n])
RETURNS TABLE
AS
RETURN select_stmt
参数说明:
TABLE:指定返回值为一个表
select_stmt:单条SELECT语句,确定返回表的数据。
其余参数与标量函数相同。在TeachingData数据库中创建一个内联表值函数,该函数返回高于指定成绩的查询信息。
CREATE FUNCTION greaterScore (@cj FLOAT)
RETURNS TABLE
AS
RETURN SELECT *FROM ScWHERE grade>=@cj
③ 多语句表值函数
创建多语句表值函数语法格式如下:
CREATE FUNCTION function_name
(@Parameter scalar_ parameter_data_type[=default],[…n])
RETURNS table_varible_name TABLE
(<colume_definition>)
AS
BEGIN
function_body
RETURN
END
参数说明:
table_varible_name:指定返回的表变量名。
colume_definition :返回表中各个列的定义。
调用用户自定义函数
① 调用标量函数
当调用用户自定义的标量函数时,提供由两部分组成的函数名称,即所有者.函数名,自定义函数的默认所有者为dbo。 可以利用PRINT、SELECT和EXEC语句中调用标量函数。
②调用表值函数
表值函数只能通过SELECT语句调用,在调用时可以省略函数的所有者。 内联表值函数和多语句表值函数的调用方法相同。
使用不同的方式调用my_Max标量函数。
用Print语句调用标量函数
PRINT dbo.my_max(3,6)
用Select语句调用标量函数
SELECT dbo.my_max(3,6)
用EXEC语句调用标量函数
DECLARE @m REAL
EXEC @m=dbo.my_max 3,6
PRINT @m在使用EXEC调用自定义函数时,调用参数的次序与函数定义中的参数次序可以不同,此时必须用赋值号为函数的标量参数指定相应的实参。例如:
DECLARE @m REAL
EXEC @m=dbo.my_max @y=15,@x=2
PRINT @m
GO利用内联表值函数Score查询成绩大于90分的成绩信息。
SELECT *
FROM greaterScore(90)
3.T-SQL编程
1.批处理
批处理是指将一条或多条Transact-SQL语句归纳为一组,以便一起提交到SQL Server执行。
SQL Server将批处理语句编译成一个可执行单元,此单元称为执行计划。每次执行一条语句。批处理以GO语句作为结束符。
在批处理中,由于语法错误等问题而造成编译错误,将使执行计划无法编译,而且批处理中的所有语句不被执行。
INSERT INTO ScoreInfo (SID,CID,TID,Score)
VALUES('06010001','00000002','01000001',87)
INSERT INTO ScoreInfo (SID,CID, TID,Score)
Go
当上述批处理被执行时,首先进行批处理编译,第一条INSERT语句被编译,第二条INSERT语句由于缺少VALUES子句存在语法错误而不被编译。因此整个批处理的语句不被执行。如果是由于数据溢出或违反约束等原因造成的运行时错误,则处理方式如下:
大多数的运行时错误会停止执行发生错误的语句,而且当前批处理中该语句之后的所有语句也不执行。 少数的运行时错误(如违反约束)仅会停止执行发生错误的语句,而且当前批处理中该语句之后的所有语句仍会继续执行。
INSERT INTO ScoreInfo (SID,CID,TID,Score)
VALUES('06010001','00000002','01000001',87)
INSERT INTO ScoreInfo (SID,CID, TID,Score)
VALUES('05010002','00000001','01000001','男')
GO
当上述批处理被执行时,首先能成功进行编译,接下来由于第二条INSERT语句在执行时失败,则第一条语句的执行结果不受影响,因为它已经执行。
2.流程控制语句
BEGIN…END语句
BEGIN…END语句用于将多个Transact-SQL语句组合成一个语句块,以便将它们视为一个整体来处理。
在条件语句和循环语句等控制流程中,当符合特定条件便执行两条或两条以上的T-SQL语句时,需要使用BEGIN…END语句将它们组合成一个语句块。
语法格式:
BEGIN
{sql_statement | statement_block}
END
其中sql_statement | statement_block是指所包含的T-SQL语句或语句块。例如下面的代码中,由于符合IF表达式的条件需要执行两条语句,因此必须使用BEGIN…END语句将这两条语句组合成一个语句块:
DECLARE @ErrorNumber INT
IF (@@ERROR<>0)BEGINSET @ErrorNumber=@@ERRORPRINT '错误代码是:'+CAST(@ErrorNumber AS VARCHAR(10))END
BEGIN…END语句会经常在WHILE语句、CASE函数、IF…ELSE语句中被用到,而且BEGIN…END语句允许嵌套使用。
从SC表中查找学号为’201215121’的同学的各科成绩,如果选修课程全部及格,则输出各门课程全部及格,否则输出该同学不及格课程的门数。
DECLARE @n INT;
IF (SELECT min(grade) FROM SC
WHERE SNO='201215121' GROUP BY SNO)>=60print '该同学的各门课程全部及格!'
ELSEBEGINSELECT @n=COUNT(CNO) FROM SC
WHERE SNO='201215121' AND grade<60print '该同学有'+CAST(@n AS VARCHAR)+'门课程不及格!'END
IF…ELSE
IF…ELSE语句是条件判断语句。利用该语句使程序具有不同条件的分支,以完成执行各种不同条件下的操作功能操作。
其语法格式如下:
IF Boolean_expression
{ sql_statement1 | statement_block1 }
[ ELSE
{ sql_statement2| statement_block2 } ]
说明:
(1)ELSE子句可选,最简单的IF 语句没有ELSE 子句部分。
(2)如果不使用BEGIN…END语句,IF或ELSE只能执行一条语句。
(3)IF…ELSE 可以进行嵌套,可实现多重条件的选择。在Transact-SQL 中最多可嵌套32 级。
CASE
虽然使用IF语句嵌套可以实现多重条件的选择,但是比较繁琐。SQL Server提供了一个简单的方法,那就是CASE函数。
CASE函数按其使用形式的不同,可以分为简单CASE函数和搜索CASE函数。
简单CASE函数必须以CASE开头,以END结束。它能够将一个指定表达式与一系列简单表达式进行比较,并且返回符合条件的结果表达式。语法格式:
CASE input_expression
WHEN when_expression THEN result_expression
[ ...n ]
[ELSE else_result_expression ]
END
参数说明:
input_expression:指定计算表达式。
when_expression:指定比较表达式。input_expression的值依次与每个WHEN子句中的when_expression的值进行比较。
result_expression:指定结果表达式。当input_expression的值与when_expression的值相等时,返回的表达式。
else_result_expression:指定当input_expression的值与所有的when_expression的值比较结果均为假时,返回的表达式。
注意:
(1) CASE函数中的各个when_expression的数据类型必须与input_expression的数据类型相同,或者是可以隐式转换的数据类型。
(2) CASE函数中如果多个WHEN子句when_expression的值与input_expression的值相同,则只会返回第一个与input_expression值相同的when_expression对应的result_expression的值。
函数执行顺序:
① 首先计算input_expression,然后按指定顺序对每个WHEN子句中when_expression的值与input_expression的值进行比较;
② 如果比较结果为TRUE,则返回当前WHEN子句对应的result_expression,然后跳出CASE函数;
③ 如果没有任何一个WHEN子句when_expression的值与input_expression的值相同,SQL Server检查是否有ELSE子句,如果有便返回else_result_expression,否则返回NULL。
从Student表中,显示学生的学号(SNO)、姓名(Sname)和性别(SSex),如果性别为“男”显示“M”, 性别为“女”则显示“F”。
SELECT sno as 学号,Sname as 姓名,性别=
CASE SSexWHEN '男' THEN 'M'WHEN '女' THEN 'F'
END
FROM Student
搜索CASE函数:
搜索CASE函数的语法格式为:
CASE
WHEN Boolean_expression THEN result_expression
[ ...n ]
[ELSE else_result_expression ]
END
参数说明:
Boolean_expression:条件表达式,结果为逻辑值。搜索CASE函数的执行顺序:
① 首先按指定顺序依次计算每个WHEN子句的Boolean_expression的值。
② 返回第一个取值为TRUE的WHEN子句对应的result_expression,然后跳出CASE语句。
③ 如果所有WHEN子句后的Boolean_expression都为FALSE,SQL Server检查是否有ELSE子句,如果有则返回else_result_expression,否则返回NULL。
从Sc表中查询所有同学选课成绩情况,将百分制转换为五分制:凡成绩大于或等于90分时显示“优秀”;80分至90分显示“良好”;70分至80分显示“中等”;60分至70分显示“及格”; 小于60分显示“不及格”;为空者显示“未考”。
SELECT SNO, CNO,GRADE, 等级=
CASE WHEN GRADE >=90 THEN '优秀'WHEN GRADE >=80 THEN '良好'WHEN GRADE >=70 THEN '中等'WHEN GRADE >=60 THEN '及格'WHEN GRADE<60 THEN '不及格' WHEN GRADE IS NULL THEN '未考' END
FROM Sc
WHILE…CONTINUE…BREAK
WHILE语句用于设置重复执行SQL语句或语句块的条件。只要设定的条件为TRUE,就重复执行命令行或程序块。
其语法格式如下:
WHILE Boolean_expression
BEGIN
{ sql_statement | statement_block }
[ BREAK ]
[ CONTINUE ]
{ sql_statement | statement_block }
END
其中CONTINUE和BREAK语句可以控制WHILE循环中语句的执行。CONTINUE语句可以让程序跳过CONTINUE命令之后的所有语句,回到WHILE循环的第一行,继续进行下一次循环。BREAK语句则使程序跳出循环,结束WHILE语句的执行。
编写Transact-SQL程序,计算20~100的累加和,如果累加和大于等于2000则结束循环,并输出结果。
DECLARE @sum INT,@i int
SET @sum=0
SET @i=20
WHILE @i<=100BEGINSET @sum=@sum+@iIF @sum>=2000BREAKSET @i=@i+1END
PRINT '20~'+CAST(@i as VARCHAR(2))+'的累加和sum='+STR(@sum)
WAITFOR
WAITFOR语句又称为延迟语句,用于指定触发器、存储过程或事务执行的时间或时间间隔;还可以暂停程序的运行,直到所设定的等待时间已过或所设定的时间已到才继续往下执行。
其语法格式如下:
WAITFOR
{ DELAY 'time_to_pass' | TIME 'time_to_execute' }
参数说明:
DELAY:指定可以继续执行批处理、存储过程或事务之前必须经过的等待时间间隔。
time_to_pass:指定等待的时间间隔,最长设定为24小时。
TIME:指定运行批处理、存储过程或事务的时间点。
time_to_execute:指定WAITFOR语句的完成时间。
注意:time_to_pass 和time_to_execute 必须是DATETIME数据类型。如“1:10:00”,但不能包括日期。
等待5秒钟后执行SELECT语句。
WAITFOR DELAY '0:0:5'
SELECT * FROM Student
GOTO
GOTO 语句用来改变程序执行的流程,使程序流程跳到指定的标识符,跳过GOTO语句后面的语句,并从标签符位置继续进行。
GOTO语句和标识符可以用在语句块、批处理和存储过程中的任意位置使用。
作为跳转目标的标识符可以是数字与字符的组合。但必须以“:”结尾,在GOTO 语句行,标识符后不必跟“:”。
其语法格式如下: GOTO label
use teachingdata
declare @stuscore tinyint
declare @returnstr varchar(50)
select @stuscore=score
from scoreinfo
where sid='05000001' and cid='00100002'
if @stuscore<60
goto notpass
if @stuscore<86
goto pass
if @stuscore<=100
goto good
goto othernotpass:
print '很遗憾,未通过考试'
goto theend
pass:
print '恭喜你,已通过考试'
goto theend
good:
print '成绩优秀,你真棒'
goto theend
other:
print '成绩输入有误!'
goto theendtheend:RETURN
RETURN 语句用于从查询或过程中无条件退出。此时位于该语句后的语句将不再被执行,返回到上一个调用它的程序或其它程序。
其语法格式如下:
RETURN [ integer_expression ]
参数说明:
integer_expression:用于指定一个返回值,要求是整型表达式。integer_expression部分可选,如果省略,SQL Server 系统会根据程序执行的结果返回一个内定值。
内定含义:
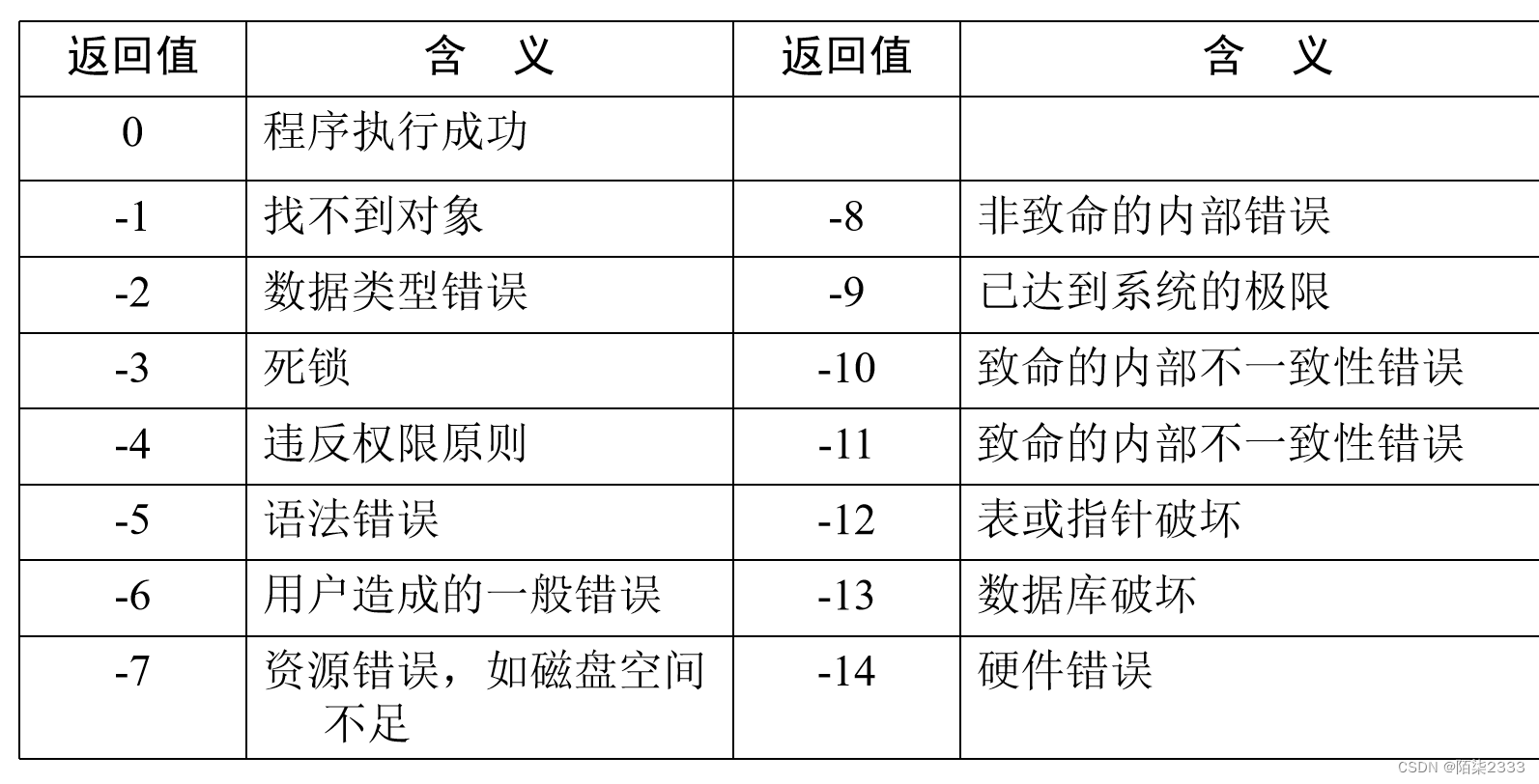
3.错误捕获语句
为了增强程序的健壮性,必须对程序中可能出现的错误进行及时的处理。
在T-SQL语句中,可以使用TRY…CATCH语句和@@ERROR函数两种方式处理发现的错误。
(1)TRY…CATCH
TRY…CATCH语句是SQL Server 2005新增的功能语句,它类似于C++中的异常处理。Transact-SQL 语句组可以包含在 TRY 块中,当执行TRY语句组中的语句出现错误时,系统将会把控制传递给CATCH块中包含的另一个语句组处理。
其语法格式如下:
BEGIN TRY
{ sql_statement | statement_block }
END TRY
BEGIN CATCH
{ sql_statement | statement_block }
END CATCH
参数说明:
sql_statement | statement_block:表示任何Transact -SQL语句、批处理,或包括于BEGIN…END块中的语句组。
说明:
(1) 必须在BEGIN TRY…END TRY语句块后紧跟着相关的BEGIN CATCH…END CATCH语句块。如果有位于这两个语句块之间的语句,将会产生错误;
(2) 每个BEGIN TRY…END TRY语句块只能与一个BEGIN CATCH…END CATCH语句块相关联。
向StuInfo表中插入两条记录,第二条记录学号SID已经存在,观察捕捉的错误信息。
BEGIN TRYINSERT StuInfo(SID,Sname)VALUES('09011101','汪洋')INSERT StuInfo(SID,Sname)VALUES(' 04000002','李少华')
END TRY
BEGIN CATCHSELECT ERROR_NUMBER() AS ErrorNumber, --返回错误号ERROR_SEVERITY() AS ErrorSeverity, --返回严重性ERROR_STATE() AS ErrorState, --返回错误状态号ERROR_LINE() AS ErrorLine, --返回导致错误的例程中的行号ERROR_MESSAGE() AS ErrorMessage; --返回错误消息的完整文本
END CATCH;
(2)@@ERROR函数
@@ERROR函数用于捕捉上一条T-SQL语句的错误号。由于@@ERROR在每一条语句执行后被清除并且重置,因此应在语句执行后立即查看它,或将其保存到一个局部变量中以备以后查看。
如果前一个Transact-SQL语句执行没有错误,则返回0。否则返回错误代号。
用@@ERROR在UPDATE语句中检测约束检查冲突(错误 #547)。
USE TeachingData
GO
UPDATE ScoreInfo
SET CID ='70000004'
WHERE SID='04000002'AND TID='01000003'
IF @@ERROR = 547
PRINT N'违反了约束冲突!'
GO
4.注释
注释是指程序中用来说明程序内容的语句,它不执行而且也不参与程序的编译。
通常是对代码功能给出简要解释或提示的一些说明性的文字,有时也用于暂时禁用的部分Transact -SQL语句或语句块。
在程序中使用注释一个程序员的良好编程习惯,它不但可以帮助他人了解自己编写程序的具体内容,而且还可以便于对程序总体结构的掌握。
SQL Server 2005支持两种语法形式表示注释内容:单行注释、块注释
1.单行注释
使用两个连字符“--”作为注释的开始标志,到本行行尾即最近的回车结束之间的所有内容为注释信息。该注释符可与要执行的代码处在同一行,也可另起一行。
USE TeachingData --打开TeachingData数据库
GO
--检索StuInfo表的数据
SELECT *
FROM StuInfo
GO
2.块注释
块注释的格式为/*……*/,其间的所有内容均为注释信息。块注释与单行注释不同的是它可以跨越多行,并且可以插入在程序代码中的任何地方。
USE TeachingData
DECLARE @Cname VARCHAR(8) /*定义变量@Cname */
/*定义变量
把查询的结果赋给变量*/
SELECT @Cname=Cname FROM CourseInfoWHERE CID='00000001'
GO
这篇关于数据库系统概论(超详解!!!)第十节 过程化SQL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







