本文主要是介绍MySQL MVCC机制深入,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MySQL MVCC机制
什么是MVCC
MVCC (Multiversion Concurrency Control) 中文全程叫多版本并发控制,是现代数据库(包括 MySQL、Oracle、PostgreSQL 等)引擎实现中常用的处理读写冲突的手段,目的在于提高数据库高并发场景下的吞吐性能。
如此一来不同的事务在并发过程中,SELECT 操作可以不加锁而是通过 MVCC 机制读取指定的版本历史记录,并通过一些手段保证保证读取的记录值符合事务所处的隔离级别,从而解决并发场景下的读写冲突。
InnoDB 中的 MVCC
MySQL中InnoDB引擎支持MVCC- 应对高并发事务,
MVCC比单纯的加行锁更有效, 开销更小 MVCC在读已提交(Read Committed)和可重复读(Repeatable Read)隔离级别下起作用MVCC既可以基于乐观锁又可以基于悲观锁来实现
InnoDB MVCC 实现原理
begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第 一个操作InnoDB表的语句,事务才真正启动,才会向mysql申请事务ID,mysql内部是严格照事务的启动顺序来分配事务ID的事务ID依次递增
InnoDB 中 MVCC 的实现方式为:每一行记录都有两个隐藏列:DATA_TRX_ID、DATA_ROLL_PTR(如果没有主键,则还会多一个隐藏的主键列)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-51oF0K3l-1588519526486)(https://i.loli.net/2020/05/03/zj6l4avrf9VCNsI.png)]
-
DATA_TRX_ID
记录最近更新这条行记录的
事务 ID,大小为6个字节 -
DATA_ROLL_PTR
表示指向该行回滚段
(rollback segment)的指针,大小为7个字节,InnoDB便是通过这个指针找到之前版本的数据。该行记录上所有旧版本,在undo中都通过链表的形式组织。 -
DB_ROW_ID
行标识(隐藏单调自增
ID),大小为6字节,如果表没有主键,InnoDB会自动生成一个隐藏主键,因此会出现这个列。另外,每条记录的头信息(record header)里都有一个专门的bit(deleted_flag)来表示当前记录是否已经被删除。
举例说明
有一张表:user字段有id,name
事务执行表:
| #Transaction 100 | #Transaction 200 | #Transaction 300 | #select | RR-ReadView | RC-ReadView |
|---|---|---|---|---|---|
| begin; | begin; | begin; | begin; | ||
| update user set name=‘zxl300’ where id=1; | |||||
| commit; | |||||
| select name from user where id=1; | [100,200],300 rs:zxl300 | [100,200],300 rs:zxl300 | |||
| update user set name=‘zxl1’ where id=1; | |||||
| update user set name=‘zxl2’ where id=1; | |||||
| select name from user where id=1; | [100,200],300 rs:zxl300 | [100,200],300 rs:zxl300 | |||
| commit; | update user set name=‘zxl3’ where id=1; | ||||
| update user set name=‘zxl4’ where id=1; | |||||
| select name from user where id=1; | [100,200],300 rs:zxl300 | [200],300 rs:zxl2 | |||
| commit; |
如何组织 Undo Log 链
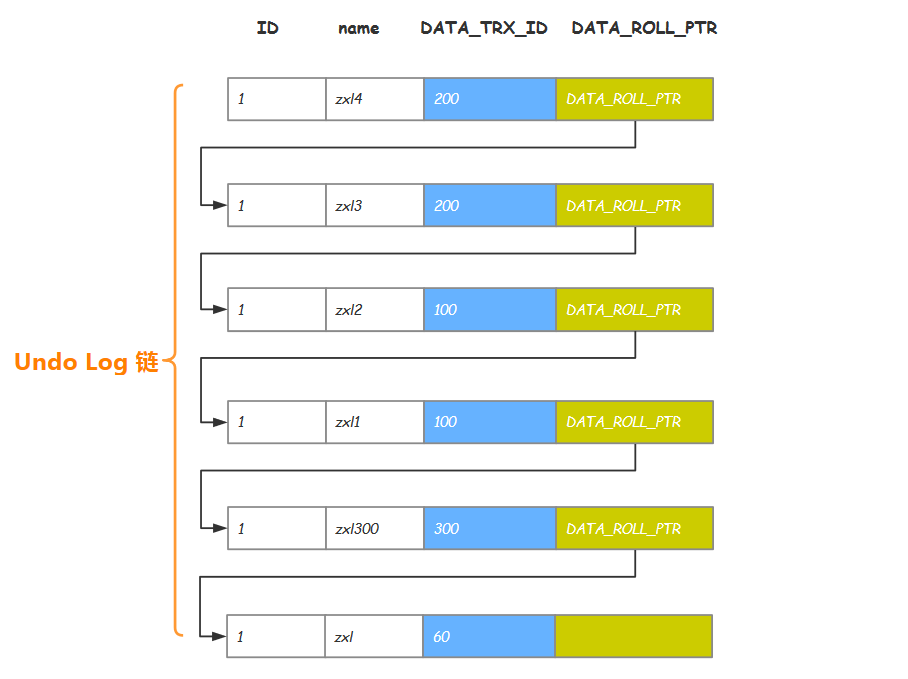
- 对
user表id=1的这行记录加排他锁。- 把该行原本的值拷贝到
undo log中,DB_TRX_ID和DB_ROLL_PTR都不动- 修改该行的值这时产生一个新版本,更新
DATA_TRX_ID为修改记录的事务ID,将DATA_ROLL_PTR指向刚刚拷贝到undo log链中的旧版本记录,这样就能通过DB_ROLL_PTR找到这条记录的历史版本。如果对同一行记录执行连续的UPDATE,Undo Log会组成一个链表,遍历这个链表可以看到这条记录的变迁- 记录
redo log,包括undo log中的修改
那么
INSERT和DELETE会怎么做呢?其实相比UPDATE这二者很简单,INSERT会产生一条新纪录,它的DATA_TRX_ID为当前插入记录的事务ID;DELETE某条记录时可看成是一种特殊的UPDATE,其实是软删,真正执行删除操作会在commit时,DATA_TRX_ID则记录下删除该记录的事务ID。
DB_TRX_ID 只有
insert/update/delete时创建
ReadView 生成规则
当执行查询SQL时会生成一致性视图ReadView,它由执行查询时所有未提交的事务ID数组(数组中最小的id为mid_id)和已创建的最大事务ID(max_id)组成,查询的数据结果需要跟ReadView做比对从而得到快照结果。
RU 下的 ReadView 生成
在 RU 隔离级别下,直接读取版本的最新记录就 OK,对于 SERIALIZABLE 隔离级别,则是通过加锁互斥来访问数据,因此不需要 MVCC 的帮助。因此 MVCC 运行在 RC 和 RR 这两个隔离级别下,当 InnoDB 隔离级别设置为二者其一时,在 SELECT 数据时就会用到版本链
核心问题是版本链中哪些版本对当前事务可见?
InnoDB 为了解决这个问题,设计了 ReadView(可读视图)的概念。
RR 下的 ReadView 生成
在 RR 隔离级别下,每个事务 touch first read 时(本质上就是执行第一个 SELECT 语句时,后续所有的 SELECT 都是复用这个 ReadView,其它 update, delete, insert 语句和一致性读 snapshot 的建立没有关系),会将当前系统中的所有的活跃事务拷贝到一个列表生成ReadView。
RC 下的 ReadView 生成
在 RC 隔离级别下,每个 SELECT 语句开始时,都会重新将当前系统中的所有的活跃事务拷贝到一个列表生成 ReadView。二者的区别就在于生成 ReadView 的时间点不同,一个是事务之后第一个 SELECT 语句开始、一个是事务中每条 SELECT 语句开始。
MVCC 判断流程
根据ReadView生成规则可以将数据分为三个区域,小于最小未提交事务Id的称为已提交事务大于未提交事务最小ID小于已创建最大事务ID称为未提交与已提交事务,大于已创建最大事务ID称为未开始事务
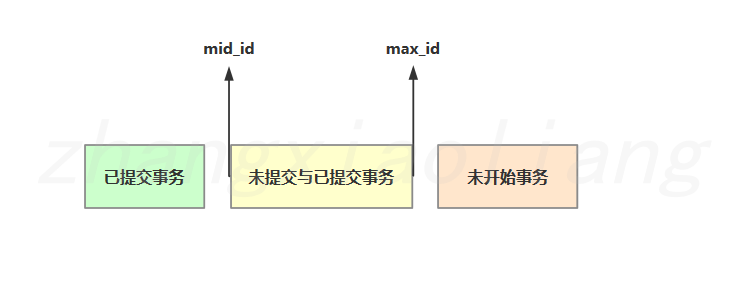
- 如果ROW的ID(DB_TRX_ID)落在绿色部分(DB_TRX_ID<mid_id),表示这个版本是已提交的事务生成的,这个数据是可见的。
- 如果ROW的ID(DB_TRX_ID)落在红色部分(DB_TRX_ID>max_id),表示这个版本是由将来启动事务生成的,是肯定不可见的。
- 如果ROW的ID(DB_TRX_ID)落在黄色部分(mid_id<=DB_TRX_ID<=max_id),则分为两种情况:
- 若
DB_TRX_ID在未提交的事务ID数组,表示这个版本是由还没有提交的事务生成的,不可见,当前自己的事物是可见的。 - 若
DB_TRX_ID不在未提交的事务ID数组,表示这个版本是已提交的事务生成的,可见。
- 若
对于删除的情况可以认为是update的特殊情况,会将版本链是最新的数据复制一份,然后将
DB_TRX_ID修改成删除操作的DB_TRX_ID,同时在该条记录的头信息(record header)里(deleted flag)标记位写上ture,来表示当前记录已被删除,在查询时按照上而的规则查询到对应的记录如果deleted flag标记位为ture,意味着记录已被删除,则不返回数据。
例RR MVCC 判断流程
-
user 表中存在一条用户信息,id:1 name:zxl.
-
首先#Transaction 100,#Transaction 200, #Transaction 300及#select同时开启事务。
-
#Transaction 300更新name为zxl300并提交。
-
#select进行查询操作,首次查询会创建ReadView,创建ReadView为[100,200],300,根据MVCC判断流程进行判断,当前记录链路DB_TRX_ID为300,300的区间应该在未提交及已提交范围,300不在未提交数组范围,所以本条记录是可见的,即返回
zxl300. -
而后#Transaction 100,进行了两次更新
update user set name='zxl1' where id=1;,update user set name='zxl2' where id=1;。 -
#select再次进行查询
select name from user where id=1;,因为事务隔离级别为RR所以ReadView依然为[100,200],300,当前记录链路DB_TRX_ID为 100 ,100的区间应该在未提交及已提交范围,100在未提交数组范围,因此本条记录不可见,根据链路继续查询,发现还是100,则继续链路查询发现为300发现不在未提交范围内则返回zxl300。
这篇关于MySQL MVCC机制深入的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



