本文主要是介绍pytorch学习day3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、模型创建(Module)
网络创建流程
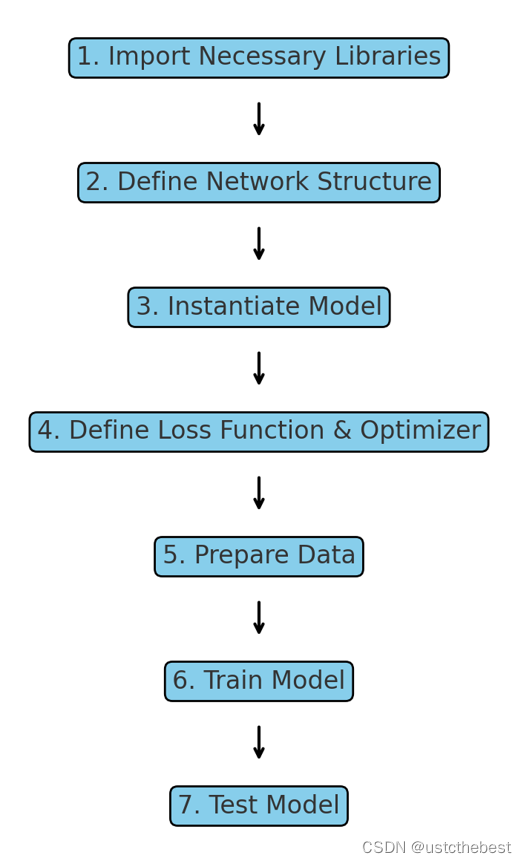
上面的图表展示了使用PyTorch创建神经网络模型的主要步骤。每个步骤按顺序连接,展示了从导入必要的库到最终测试模型的整个流程:
- 导入必要的库:首先导入PyTorch及其相关模块。
- 定义网络结构:通过继承
nn.Module类定义神经网络的层和前向传播过程。- 实例化模型:使用定义的结构实例化模型对象。
- 定义损失函数和优化器:选择并定义损失函数和优化器。
- 准备数据:加载并预处理数据,创建数据加载器。
- 训练模型:通过训练循环进行前向传播、计算误差和反向传播更新权重。
- 测试模型:在测试数据上评估模型的性能。
模型构建的两个要素
在PyTorch中,构建神经网络模型的关键在于两个要素:构建子模块和拼接子模块。这两个要素分别在模型类的
__init__()方法和forward()方法中实现。1. 构建子模块
在自定义模型中,通过继承
nn.Module类,并在__init__()方法中定义子模块。这些子模块通常是神经网络的各层,例如卷积层、全连接层、激活函数等。示例:
import torch.nn as nnclass CustomModel(nn.Module):def __init__(self):super(CustomModel, self).__init__()# 定义子模块self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)self.fc1 = nn.Linear(in_features=16*16*16, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=84)self.fc3 = nn.Linear(in_features=84, out_features=10)在上面的代码中,我们定义了一个卷积层
conv1,一个池化层pool,以及三个全连接层fc1、fc2和fc3。这些子模块是模型的基本组成部分。2. 拼接子模块
在
forward()方法中定义子模块的拼接方式。forward()方法描述了输入数据如何经过这些子模块的传递过程,最终输出结果。示例:
class CustomModel(nn.Module):def __init__(self):super(CustomModel, self).__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)self.fc1 = nn.Linear(in_features=16*16*16, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=84)self.fc3 = nn.Linear(in_features=84, out_features=10)def forward(self, x):x = self.pool(F.relu(self.conv1(x))) # 拼接卷积层和池化层x = x.view(-1, 16*16*16) # 展平张量x = F.relu(self.fc1(x)) # 拼接第一个全连接层x = F.relu(self.fc2(x)) # 拼接第二个全连接层x = self.fc3(x) # 拼接第三个全连接层return x在
forward()方法中,我们定义了输入数据的传递路径。数据首先通过卷积层conv1和池化层pool,然后展平为一维张量,依次通过三个全连接层fc1、fc2和fc3,最后输出结果。通过这两个步骤,我们可以构建出一个功能齐全的神经网络模型。以下是流程图,帮助理解这两个要素在模型构建中的位置和作用。
当然,以下是关于模型构建的两个要素的表格,可以直接复制使用:
| 模型构建的两个要素 | 描述 | |--------------------|----------------------------------------| | 构建子模块 | 在自定义模型(继承 nn.Module)的 `__init__()` 方法中定义各个层(卷积层、池化层、全连接层等)| | 拼接子模块 | 在自定义模型的 `forward()` 方法中定义层的连接方式,描述前向传播过程 |这个表格简明地展示了模型构建的两个关键步骤和它们分别在哪个方法中实现。希望这能帮助你更好地理解和使用PyTorch进行模型构建。
通过以上两个步骤,我们可以灵活地定义各种复杂的神经网络模型,并通过
forward()方法灵活地组合这些子模块,实现数据的前向传播过程。
二、nn.Mudule的属性
nn.Module是 PyTorch 中所有神经网络模块的基类。它提供了一些关键属性和方法,用于构建和管理神经网络模型。以下是nn.Module的一些重要属性和方法:1.
parameters()
- 描述:返回模型所有参数的迭代器。
- 用途:通常用于优化器来获取模型参数进行训练。
for param in model.parameters():print(param.size())2.
named_parameters()
- 描述:返回一个包含模型参数名字和参数本身的迭代器。
- 用途:当你需要获取特定层的参数时特别有用。
for param in model.parameters():print(param.size())3.
children()
- 描述:返回模型所有子模块的迭代器。
- 用途:用于递归遍历模型的各个子模块。
for child in model.children():print(child)4.
named_children()
- 描述:返回一个包含模型子模块名字和子模块本身的迭代器。
- 用途:用于详细查看每个子模块。
for name, child in model.named_children():print(name, child)5.
modules()
- 描述:返回模型所有模块(包括模型本身和其子模块)的迭代器。
- 用途:用于遍历所有模块。
for module in model.modules():print(module)6.
named_modules()
- 描述:返回一个包含模型模块名字和模块本身的迭代器。
- 用途:当你需要以层级结构查看所有模块时使用。
for name, module in model.named_modules():print(name, module)7.
add_module(name, module)
- 描述:将一个子模块添加到当前模块。
- 用途:动态地添加子模块。
model.add_module('extra_layer', nn.Linear(10, 10))8.
forward()
- 描述:定义前向传播逻辑。用户需要在自己的子类中重载这个方法。
- 用途:定义输入数据如何通过网络层进行传递。
def forward(self, x):x = self.layer1(x)x = self.layer2(x)return x9.
train(mode=True)
- 描述:将模块设置为训练模式。
- 用途:启用或禁用 Dropout 和 BatchNorm。
model.train() # 设置为训练模式 model.eval() # 设置为评估模式10.
zero_grad()
- 描述:将所有模型参数的梯度清零。
- 用途:在每次反向传播前清除旧的梯度。
model.zero_grad()这些属性和方法提供了强大的功能,使得
nn.Module能够灵活且高效地管理神经网络模型。通过这些接口,你可以构建、管理和训练复杂的神经网络。
三、模型容器Containers
模型容器(Containers)
在 PyTorch 中,模型容器(Containers)是用于组织和管理神经网络层的一种方式。通过使用模型容器,可以更方便地构建和管理复杂的神经网络结构。以下是 PyTorch 中常用的几种模型容器:
1.
nn.Sequential描述:
nn.Sequential是一个按顺序执行子模块的容器。它将子模块按定义顺序串联起来,适合用于简单的前向传播模型。用途:
用于快速构建按顺序堆叠的网络结构,例如多层感知机(MLP)和简单的卷积神经网络(CNN)。
示例:
import torch.nn as nnmodel = nn.Sequential(nn.Conv2d(1, 20, 5),nn.ReLU(),nn.Conv2d(20, 64, 5),nn.ReLU() )在这个例子中,输入数据依次通过两个卷积层和两个 ReLU 激活函数。
2.
nn.ModuleList描述:
nn.ModuleList是一个存储子模块的有序列表,但并没有定义前向传播的具体顺序。它主要用于需要灵活前向传播定义的模型。用途:
适用于需要在前向传播过程中动态选择层或者有条件执行层的情况。
示例:
import torch.nn as nnclass MyModule(nn.Module):def __init__(self):super(MyModule, self).__init__()self.layers = nn.ModuleList([nn.Conv2d(1, 20, 5), nn.Conv2d(20, 64, 5)])def forward(self, x):for layer in self.layers:x = layer(x)return x在这个例子中,
layers存储了两个卷积层,并在forward方法中以循环的方式应用它们。3.
nn.ModuleDict描述:
nn.ModuleDict是一个存储子模块的字典,可以使用键来访问子模块。它提供了灵活的模块管理方式,可以通过键值对的方式存取模块。用途:
适用于需要命名访问子模块,且不需要严格的前向传播顺序的情况,例如多分支的模型结构。
示例:
import torch.nn as nnclass MyModule(nn.Module):def __init__(self):super(MyModule, self).__init__()self.layers = nn.ModuleDict({'conv1': nn.Conv2d(1, 20, 5),'conv2': nn.Conv2d(20, 64, 5)})def forward(self, x):x = self.layers['conv1'](x)x = self.layers['conv2'](x)return x在这个例子中,
layers存储了两个卷积层,可以通过键名'conv1'和'conv2'进行访问。4.
nn.ParameterList和nn.ParameterDict描述:
这两个容器分别用于存储参数列表和参数字典,与
ModuleList和ModuleDict类似,但它们存储的是参数而不是模块。用途:
适用于需要灵活管理模型参数的情况。
示例:
import torch import torch.nn as nnclass MyModule(nn.Module):def __init__(self):super(MyModule, self).__init__()self.params = nn.ParameterList([nn.Parameter(torch.randn(10, 10)) for i in range(3)])self.param_dict = nn.ParameterDict({'param1': nn.Parameter(torch.randn(10, 10)),'param2': nn.Parameter(torch.randn(10, 10))})def forward(self, x):# 使用 self.params 和 self.param_dict 进行前向传播pass在这个例子中,
params存储了三个参数,而param_dict则存储了两个命名参数。
4 总结
通过使用这些模型容器,PyTorch 提供了灵活且高效的方式来组织和管理神经网络模型的层和参数。
nn.Sequential适用于简单的顺序结构,nn.ModuleList和nn.ModuleDict提供了更多的灵活性,适用于更复杂的网络结构。nn.ParameterList和nn.ParameterDict则用于更灵活的参数管理。利用这些容器,可以更方便地构建和管理复杂的神经网络模型。
5 实现一个简单VGG网络
创建一个简单的VGG网络
VGG网络是一种深度卷积神经网络,因其简单且具有良好的性能而广泛应用。下面我们利用PyTorch提供的模型容器,构建一个简化版的VGG网络。我们将主要使用
nn.Sequential来按顺序堆叠卷积层和全连接层。相关论文地址:https://arxiv.org/abs/1409.1556
1. 导入必要的库
import torch import torch.nn as nn import torch.nn.functional as F2. 定义VGG块
VGG块由多个卷积层和一个池化层组成。我们定义一个函数来创建这些块。
def vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU(inplace=True))in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2, stride=2))return nn.Sequential(*layers)3. 定义VGG网络
我们利用
nn.Sequential来堆叠多个VGG块,最后添加全连接层。class SimpleVGG(nn.Module):def __init__(self):super(SimpleVGG, self).__init__()self.features = nn.Sequential(vgg_block(2, 3, 64),vgg_block(2, 64, 128),vgg_block(3, 128, 256),vgg_block(3, 256, 512),vgg_block(3, 512, 512))self.classifier = nn.Sequential(nn.Linear(512*7*7, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 10))def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.classifier(x)return x4. 实例化和测试模型
我们创建模型实例并打印其结构,确保其正确性。
model = SimpleVGG() print(model)5. 测试模型结构
为了确保模型构建正确,我们可以打印模型结构或者传递一个随机张量进行测试。
if __name__ == "__main__":model = SimpleVGG()print(model)# 测试输入数据input_tensor = torch.randn(1, 3, 224, 224)output = model(input_tensor)print(output.shape) # 应输出 torch.Size([1, 10])通过这些步骤,我们利用PyTorch提供的模型容器创建了一个简化版的VGG网络。这个网络由五个VGG块和三个全连接层组成,适用于图像分类任务。根据需求可以进一步调整网络结构和参数。
这篇关于pytorch学习day3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






