本文主要是介绍Prometheus + Grafana + Alertmanager 系统监控,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Prometheus+Grafana 系统监控
- 1. 简介
- 1.1 Prometheus 普罗 米修斯
- 1.2 Grafana
- 2. 快速试用
- 2.1 Prometheus 普罗 米修斯
- 2.2 Prometheus 配置文件
- 2.3 Grafana
- 2. 使用 Docker-Compose脚本部署监控服务
- 3. Grafana 配置
- 3.1 配置数据源 Prometheus
- 3.2 使用模板ID 配置监控模板
- 3.3 使用JSON文件 配置监控模板
- 3.3.1 导出自定义模板配置
- 3.3.2 导入JSON模板配置
- 3.4 系统服务嵌入 Grafana 面板页面
1. 简介
1.1 Prometheus 普罗 米修斯
Prometheus 是云原生计算基金会的一个项目,是一个系统和服务监控系统。它收集指标 从配置的目标以给定的时间间隔计算规则表达式, 显示结果,并在观察到指定条件时触发警报。
将 Prometheus 与其他指标和监控系统区分开来的功能包括:
- 多维数据模型(由指标名称和键/值维度集定义的时间序列)
- PromQL,一种强大而灵活的查询语言,可利用这种维度
- 不依赖分布式存储;单个服务器节点是自治的
- 用于时序集合的 HTTP 拉取模型
- 通过中间网关支持推送时间序列以进行批处理作业
- 通过服务发现或静态配置发现目标
- 支持多种图形和仪表板模式
- 支持分层和水平联合
1.2 Grafana
Grafana 开源软件使您能够查询、可视化、警报和探索您的指标、日志和跟踪,无论它们存储在何处。Grafana OSS 为您提供了将时间序列数据库 (TSDB) 数据转换为富有洞察力的图形和可视化的工具。Grafana OSS 插件框架还允许您连接其他数据源,如 NoSQL/SQL 数据库、工单工具(如 Jira 或 ServiceNow)以及 CI/CD 工具(如 GitLab)。
2. 快速试用
2.1 Prometheus 普罗 米修斯
[root@localhost prometheus]# docker run --name prometheus -d -p 19090:9090 prom/prometheus
46eb10d70553966c138d34c3d23f6720667187ad9e5ed51544fc7667bc349c99
[root@localhost prometheus]#
启动完成后,可以在浏览器中访问:IP:19090
可以看到prometheus服务已经可以正常访问。
2.2 Prometheus 配置文件
试用上面启动的 prometheus 服务,拷贝出默认的配置文件:
[root@localhost prometheus]# docker cp prometheus:/etc/prometheus/prometheus.yml .
[root@localhost prometheus]#
[root@localhost prometheus]# ll
总用量 4
-rw-r--r--. 1 root root 934 5月 9 06:11 prometheus.yml
[root@localhost prometheus]#
[root@localhost prometheus]# cat prometheus.yml
# my global config
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["localhost:9090"]
[root@localhost prometheus]#
可以看到,配置文件prometheus.yml 中包含了四部分,用于定义Prometheus如何收集指标数据、评估告警规则以及与Alertmanager交互等行为。
-
Global Configuration (全局配置):
scrape_interval: 15s: 设置抓取目标(如各类服务暴露的metrics端点)数据的时间间隔为每15秒一次。默认通常是每1分钟。evaluation_interval: 15s: 设置评估告警规则的时间间隔也为每15秒一次。这意味着Prometheus会每15秒检查一次是否满足告警条件。默认也是每1分钟。scrape_timeout is set to the global default (10s): 抓取超时时间,默认为10秒,意味着如果一个目标在10秒内没有响应,此次抓取将被视为失败。
-
Alertmanager Configuration (Alertmanager配置):
- 这部分配置告诉Prometheus如何连接到
Alertmanager,Alertmanager负责处理告警的去重、分组、路由和通知。这里配置了一个静态配置,但实际目标地址被注释掉了(# - alertmanager:9093),需要去掉注释并填写正确的Alertmanager地址以启用。
- 这部分配置告诉Prometheus如何连接到
-
Rule Files (规则文件):
rule_files: 列出了一组YAML文件,这些文件包含了Prometheus的记录规则和告警规则。这些规则会按照global部分设定的evaluation_interval周期性地进行评估。- 示例中虽然列出了文件名,但都被注释了,需要根据实际情况取消注释或添加实际规则文件路径。
-
Scrape Configurations (抓取配置):
定义了Prometheus
如何抓取目标数据。在这个例子中,有一个抓取配置:job_name: "prometheus": 给这个抓取任务命名,方便在指标上打标签。static_configs:: 定义了静态配置的目标列表,这里是直接抓取 Prometheus 自身暴露在localhost:9090/metrics上的指标数据。
这里先对配置文件有个简单的说明,后面来自定义一下这个配置文件。
如果对配置文件足够了解,可以自定义配置文件或者自定义 Prometheus 镜像,自定义镜像的 Dockerfile 可参考:
FROM prom/prometheus
ADD prometheus.yml /etc/prometheus/
构建、运行自定义镜像:
docker build -t my-prometheus .
docker run -p 9090:9090 my-prometheus
如果想持久化 Prometheus 的数据,可以调整部署的命令,新增挂载目录:
docker run \-p 9090:9090 \-v /opt/prometheus/conf/prometheus.yml:/etc/prometheus/prometheus.yml \-v /opt/prometheus/data:/prometheus \prom/prometheus
这里需要修改下挂载目录的权限,否则无法正常启动 Prometheus,提示没有权限:
ts=2024-05-27T08:31:16.295Z caller=query_logger.go:93 level=error component=activeQueryTracker msg="Error opening query log file" file=/prometheus/queries.active err="open /prometheus/queries.active: permission denied"
panic: Unable to create mmap-ed active query loggoroutine 1 [running]:
github.com/prometheus/prometheus/promql.NewActiveQueryTracker({0x7ffef95ceeab, 0xb}, 0x14, {0x44aa9e0, 0xc0000d7e00})/app/promql/query_logger.go:123 +0x425
main.main()/app/cmd/prometheus/main.go:748 +0x82fe
[root@localhost prometheus]#
由于 Prometheus 容器内使用的用户是 nobody,且uid为 65534,所以需要修改持久化的目录的权限:chown -R 65534.65534 prometheus/data
可以先在没有挂载的时候进入容器瞅一眼,这个目录下文件的权限:
/prometheus $ ls -l
total 4
drwxr-xr-x 2 nobody nobody 6 May 27 08:31 chunks_head
-rw-r--r-- 1 nobody nobody 0 May 27 08:31 lock
-rw-r--r-- 1 nobody nobody 20001 May 27 08:32 queries.active
drwxr-xr-x 2 nobody nobody 22 May 27 08:31 wal
/prometheus $
/prometheus $ id nobody
uid=65534(nobody) gid=65534(nobody) groups=65534(nobody)
2.3 Grafana
docker run -d --name=grafana -p 13000:3000 grafana/grafana
[root@localhost prometheus]# docker run -d --name=grafana -p 13000:3000 grafana/grafana
1a3cf336e0a866bc0af37ab500309c4d66350eabdbc67dc6a2115eb1f697907a
[root@localhost prometheus]#
部署成功后,浏览器中访问 Grafana 页面:IP+13000

默认密码是 admin/admin , 首次登录成功后,会提示修改登录密码:
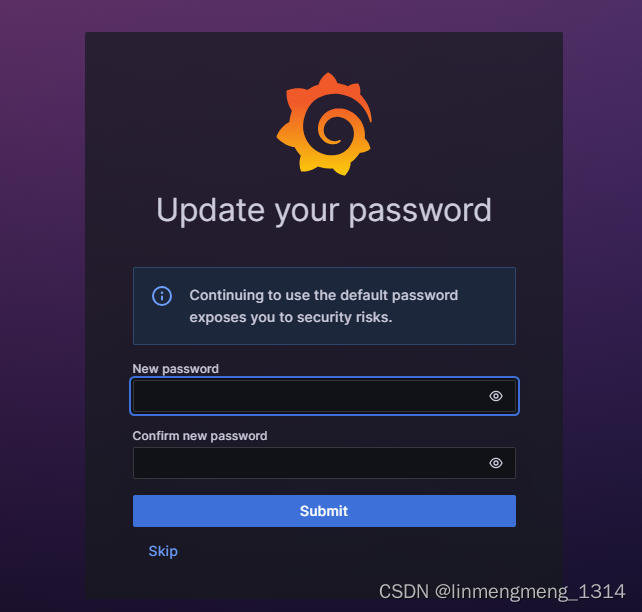
如果选择了 Skip,则下次登录的时候还是会提示修改密码,这里还是修改下自定义的密码。
修改密码后,自动进入欢迎页:
在左侧的菜单树,可以看到以下几项配置:
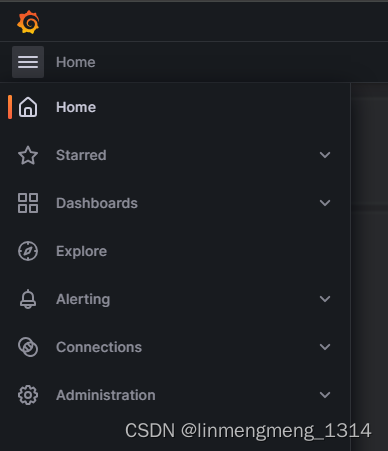
这里使用监控服务,主要使用的就是这个 Dashboards 和 Connections 下配置的 Prometheus 数据源;
关于 Grafana 的数据源,这里可以选择的组件有很多:

比如监控服务,我们这里用的 Prometheus,日志服务我们常用的有 Loki;
2. 使用 Docker-Compose脚本部署监控服务
这里给出监控主机资源和Docker容器的情况,需要借助其他两个组件:node-exporter 和 cadvisor;
-
Node Exporter
-
用途:
Node Exporter是 Prometheus 生态系统中的一个组件,主要用于从运行在类 UNIX 系统(包括 Linux 和 macOS 等)上的主机收集硬件和系统指标。它通过各种内置的收集器(collectors)来提取关于系统状态的数据,如CPU使用率、内存使用情况、磁盘I/O、网络统计、文件系统使用情况、系统负载等,并将这些数据通过 HTTP 服务的形式暴露给 Prometheus 服务器抓取。这使得 Prometheus 能够监控服务器级别的指标,而不仅仅是应用程序级别的指标。 -
工作方式:
Node Exporter 运行时监听一个 HTTP 端口(默认为9100),Prometheus 服务器会定期访问这个端点来抓取数据。用户可以根据需要启用或禁用某些 collectors,以适应特定的监控需求。
-
-
cAdvisor
-
用途:
cAdvisor(Container Advisor)是由 Google 开发的一个容器资源使用的实时分析工具,主要设计用于监控 Docker 容器。cAdvisor 自动检测正在运行的容器,并收集包括 CPU、内存、网络、文件系统 I/O 和存储使用情况等在内的详细性能和资源使用数据。它能够提供每秒更新的容器资源使用统计数据,非常适合于在 Kubernetes 或其他容器环境中进行细粒度的容器监控。 -
工作方式:
cAdvisor 通常以守护进程形式运行,可以作为一个独立服务或者集成到 Docker 守护进程中。当集成到 Kubernetes 集群中时,每个节点上的 kubelet 组件默认就包含了 cAdvisor,自动监控该节点上的所有容器。cAdvisor 也通过 HTTP 端点(默认为8080)公开这些监控数据,供 Prometheus 等监控系统抓取。
-
node-exporter 和 cadvisor 分别关注宿主机的系统级监控和容器级监控,共同为 Prometheus 提供全面的基础设施监控能力。在实际部署中,两者通常会一起使用,以实现从宿主机到容器的全方位监控覆盖。
新建一个 docker-compose.yml 文件,内容如下:
version: "3.1"
services:node-exporter:privileged: trueimage: prom/node-exporter:latestcontainer_name: node-exporterrestart: unless-stoppedvolumes:- /proc:/host/proc:ro- /sys:/host/sys:ro- /:/rootfs:rocommand:- '--path.procfs=/host/proc'- '--path.rootfs=/rootfs'- '--path.sysfs=/host/sys'- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'ports:- "39100:9100"cadvisor:privileged: truecontainer_name: cadvisorimage: google/cadvisor:latestrestart: unless-stoppedports:- '39080:8080'volumes:- /:/rootfs:ro- /var/run:/var/run:rw- /sys:/sys:ro- /var/lib/docker/:/var/lib/docker:rocommand:- '--housekeeping_interval=55s'- '--docker_only'prometheus:container_name: prometheusimage: prom/prometheusdeploy:resources:limits:cpus: '1'memory: 1Gvolumes:- ./prometheus/:/etc/prometheus/- ./prometheus/data:/prometheus/command:- '--config.file=/etc/prometheus/prometheus.yml'- '--storage.tsdb.path=/prometheus'- '--web.console.libraries=/usr/share/prometheus/console_libraries'- '--web.console.templates=/usr/share/prometheus/consoles'- '--web.enable-lifecycle'- '--web.enable-remote-write-receiver'- '--storage.tsdb.retention=15d'ports:- 39090:9090restart: alwaysalertmanager:container_name: alertmanagerimage: prom/alertmanager:latesthostname: alertmanagerdeploy:resources:limits:cpus: '1'memory: 1Gports:- 39093:9093volumes:- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.ymlrestart: alwaysgrafana:user: '0'container_name: grafanaimage: grafana/grafana:latesthostname: grafanarestart: alwaysdeploy:resources:limits:cpus: '1'memory: 1Gports:- 33000:3000volumes:- ./grafana/grafana/:/var/lib/grafana/# - ./grafana/conf/defaults.ini:/usr/share/grafana/conf/defaults.ininetworks:default:external: truename: monitor-net
这里node-exporter 和 cadvisor 两个服务,挂载的是系统的文件,用于读取系统资源状态;
./prometheus/data 目录用来 持久化 Prometheus 的数据,注意需要修改文件夹的权限,否则无法正常启动;
Prometheus 的配置文件 prometheus.yml 内容:
[root@localhost monitor]# cat prometheus/prometheus.yml
#全局配置
global:scrape_interval: 15sevaluation_interval: 15s# scrape_timeout is set to the global default (10s).
#告警配置
alerting:alertmanagers:- static_configs:- targets: ['alertmanager:9093']
#加载一次规则,并根据全局“评估间隔”定期评估它们。
rule_files:- "/etc/prometheus/conf/rules.yml"
#控制Prometheus监视哪些资源
#默认配置中,有一个名为prometheus的作业,它会收集Prometheus服务器公开的时间序列数据。
scrape_configs:# 作业名称将作为标签“job=<job_name>`添加到此配置中获取的任何数据。- job_name: '主机监控'static_configs:- targets: ['node-exporter:9100']- job_name: '告警'static_configs:- targets: ['alertmanager:9093']- job_name: 'Docker监控'static_configs:- targets: ['cadvisor:8080']
其中:scrape_configs 下定义了 Prometheus 的任务,这里根据需要可以添加不同的任务,每个任务对应一个服务和目标端口,这里使用服务名来访问的,所以使用的是容器内服务的端口,如果配置了IP来访问目标服务,则需要使用宿主机的端口;
配置文件中定义了规则配置文件 rules.yaml 的目录为:/etc/prometheus/conf/rules.yml,配置文件内容如下:
groups:- name: system_alertsrules:- alert: HighCpuUsageexpr: 100 * (1 - avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) BY (instance)) > 10for: 1mlabels:severity: warningannotations:summary: "High CPU Usage Detected"description: "CPU usage is above 80% on instance {{ $labels.instance }}"- alert: HighMemoryUsageexpr: 100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) > 10for: 1mlabels:severity: warningannotations:summary: "High Memory Usage Detected"description: "Memory usage is above 70% on instance {{ $labels.instance }}"- alert: CriticalMemoryUsageexpr: 100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) > 10for: 1mlabels:severity: criticalannotations:summary: "Critical Memory Usage Detected"description: "Memory usage is above 90% on instance {{ $labels.instance }}"- alert: ConnectivityIssueexpr: up == 0for: 1mlabels:severity: criticalannotations:summary: "Connectivity Issue Detected"description: "Instance {{ $labels.instance }} is not reachable"
这里配置的规则可以根据自己的需求来自定义;
执行 docker-compose up -d 来启动定义的服务;
3. Grafana 配置
启动成功后,登录 grafana 的面板,来配置Grafana:
3.1 配置数据源 Prometheus
登录 grafana 成功后,进入 Home > Connections 来新增一个数据源,
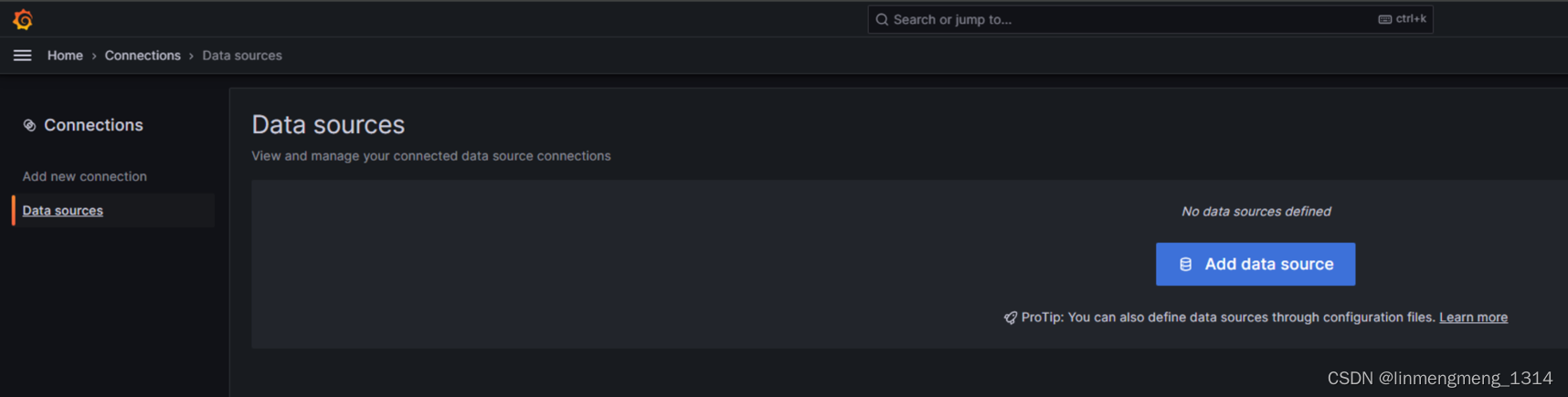
可以看到当前没有数据源,点击 Add Data source 添加数据源
这里配置 Prometheus 作为数据源,选择 Prometheus
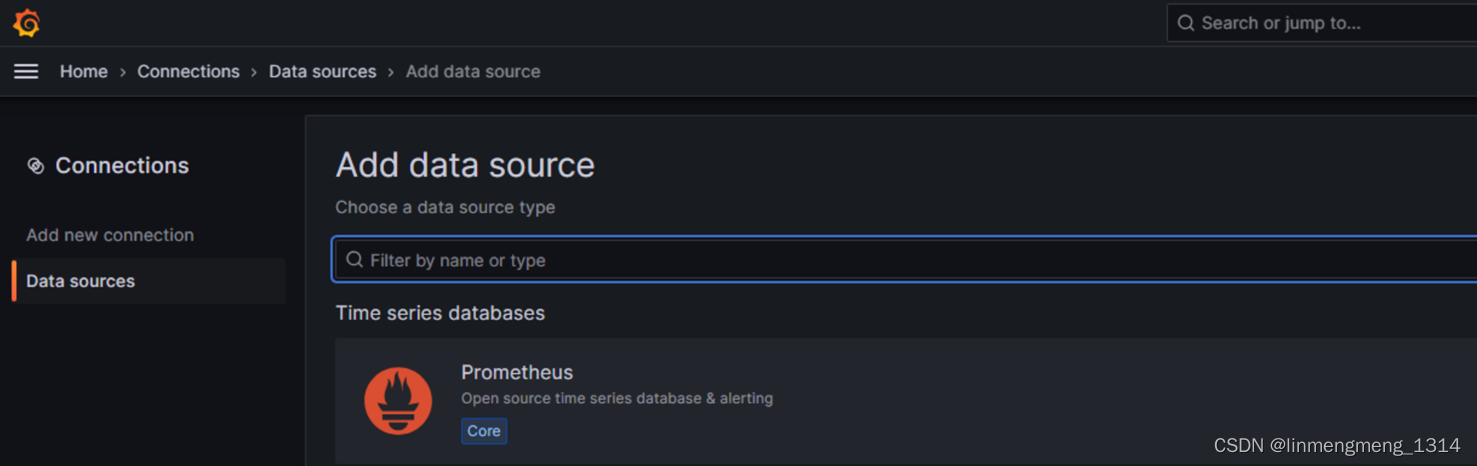
点进去,进入配置页面:
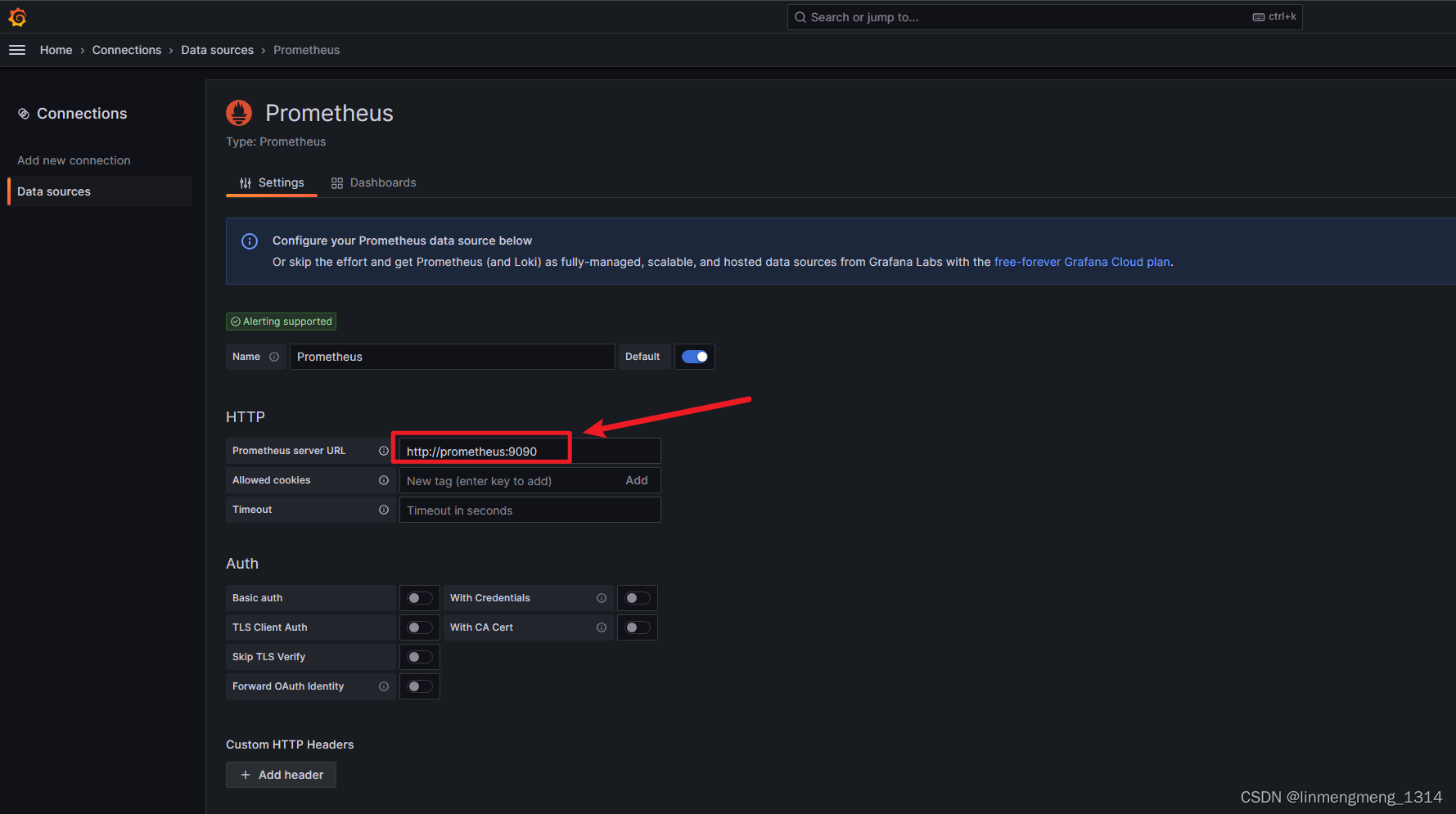
这里的配置根据自己的环境,来配置对应的连接,确保已部署 prometheus,并且可以正常访问该服务,我这里直接使用服务名来访问了,由于上面 Prometheus 并没有配置访问验证,所以这里直接配置下访问的URL就好了,如果 Prometheus 配置了验证,则在这个连接配置页面需要进行相应的配置;
直接拉到下面的Save & Test,点击保存按钮,保存成功后就可以配置模板了。
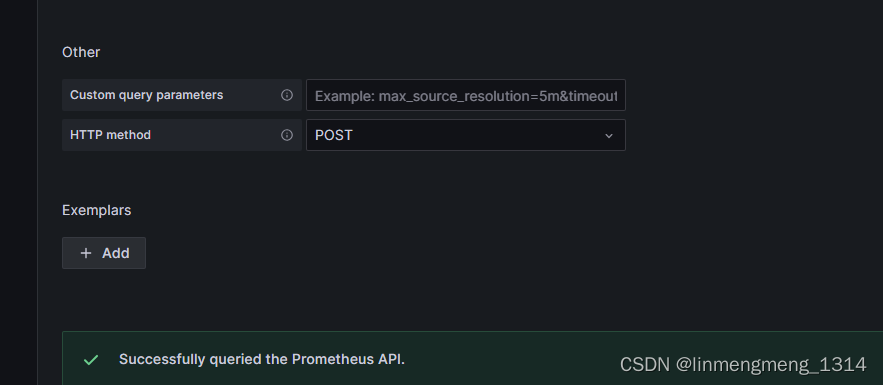
3.2 使用模板ID 配置监控模板
进入 Home > Dashboards 来配置监控模板,点击 building a dashboard
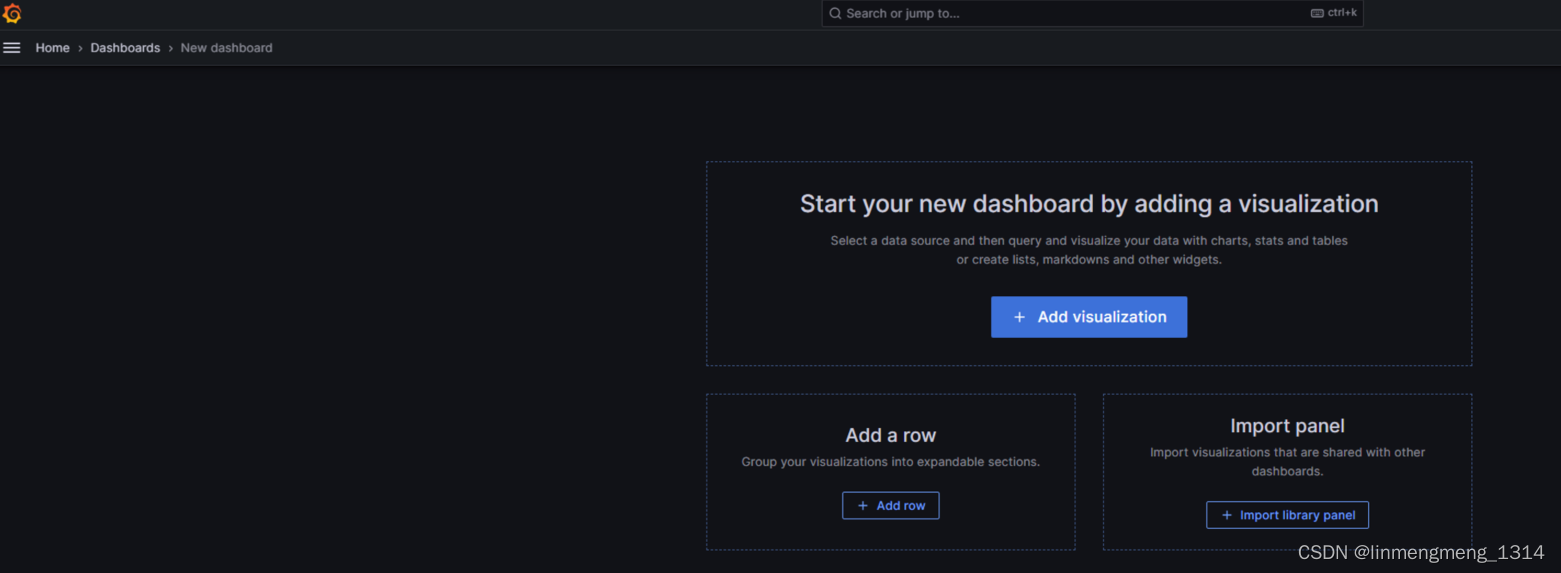

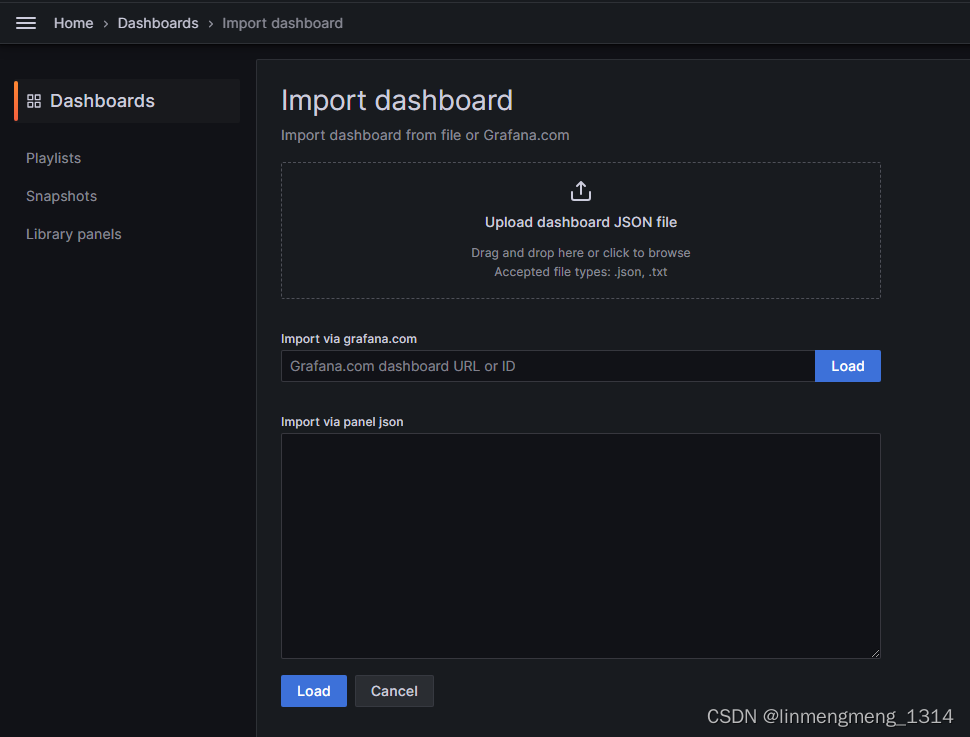
可以访问 https://grafana.com/grafana/dashboards/?search=docker 选择一个自己喜欢的样式,然后可以使用模板的ID或者JSON配置来导入模板;
我这里需要监控主机资源情况,使用的模板ID是:9276 ,输入模板ID,点击后面的 Load,会自动加载模板信息,不过这里需要联网才行,如果是在内网环境,则需要先找到模板的JSON文件,然后使用JSON导入的方式,粘贴到下面的 输入框,再点击 Load 按钮,载入模板信息;
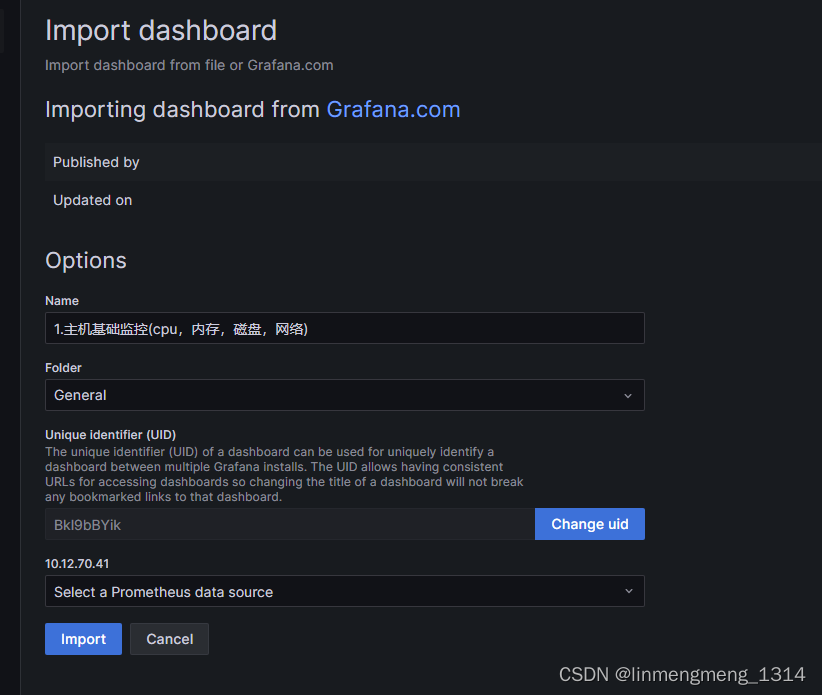
载入成功后,自动显示模板的名称和UID,其中这个UID是可以自定义的,点击右边的 Change uid ,模板的UID就可以编辑了,这个UID可以用来直接访问模板面板;
选择下面的数据源,点击下拉框,可以看到我们上面配置的 Prometheus,选中即可;
点击 Import 来导入模板;
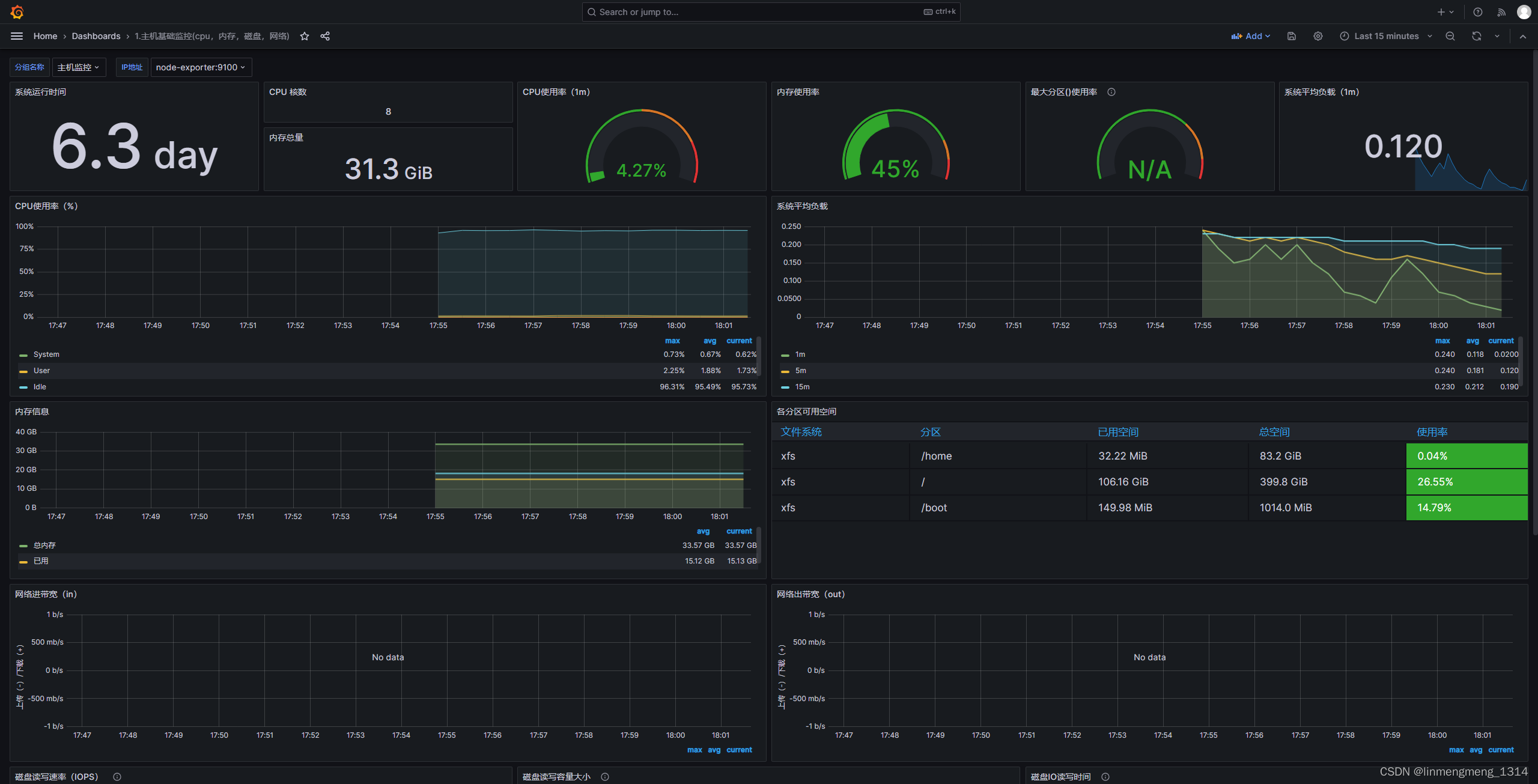
选择左上角的分组名称,选择 主机监控,这时候后面的IP地址直接就是我们配置文件里面配置的node-exporter:9100了,这里支持监控多个环境,如果配置了多个分组和环境的IP和端口,可以监控不同的分组和环境;
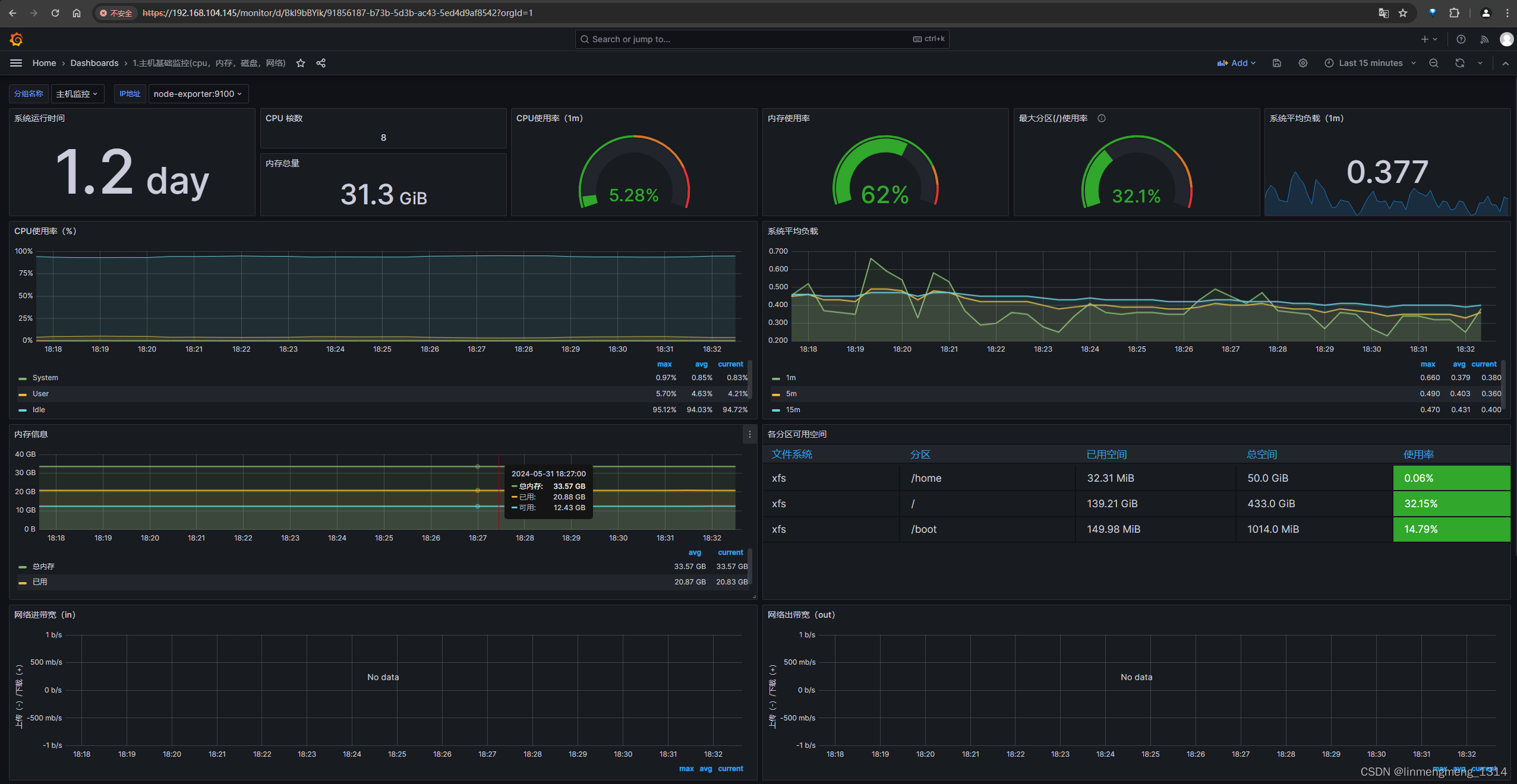
可以看到监控面板正常展示数据了,如果 node-exporter 服务没起来,或者异常了,这里面板里面的统计图的数据就可能是空的。
点击页面右上角的保存按钮,可以保存当前面板的配置;
直接访问 node-exporter 服务,访问宿主机映射的端口:http://IP:39100/
访问cadvisor服务:http://IP:39080/containers/
3.3 使用JSON文件 配置监控模板
如果我们对模板进行自定义修改了,想备份或者迁移 Grafana 配置到其他环境,则可以使用 JSON配置文件来导入导出我们的模板配置;
3.3.1 导出自定义模板配置
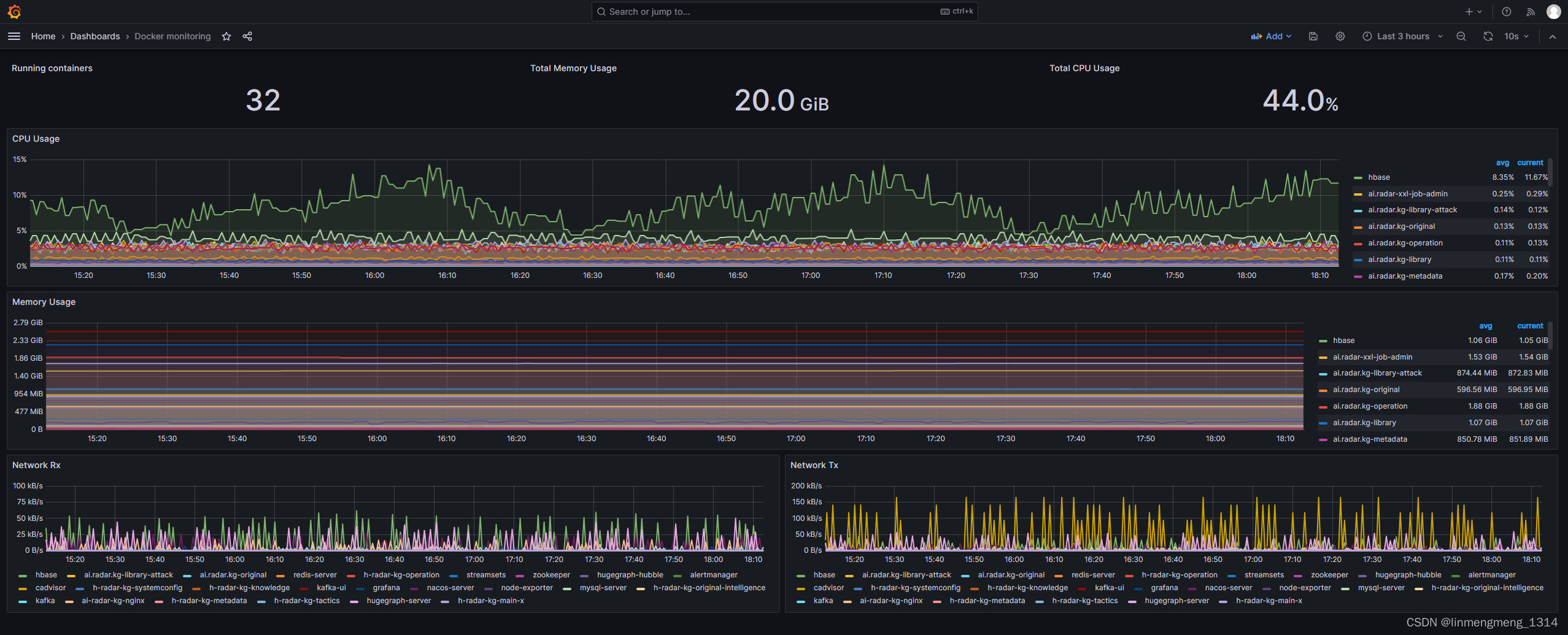
我的另一个环境,配置了监控 Docker 容器的面板,如下图
点击面板名称后面的分享按钮,然后选择导出:
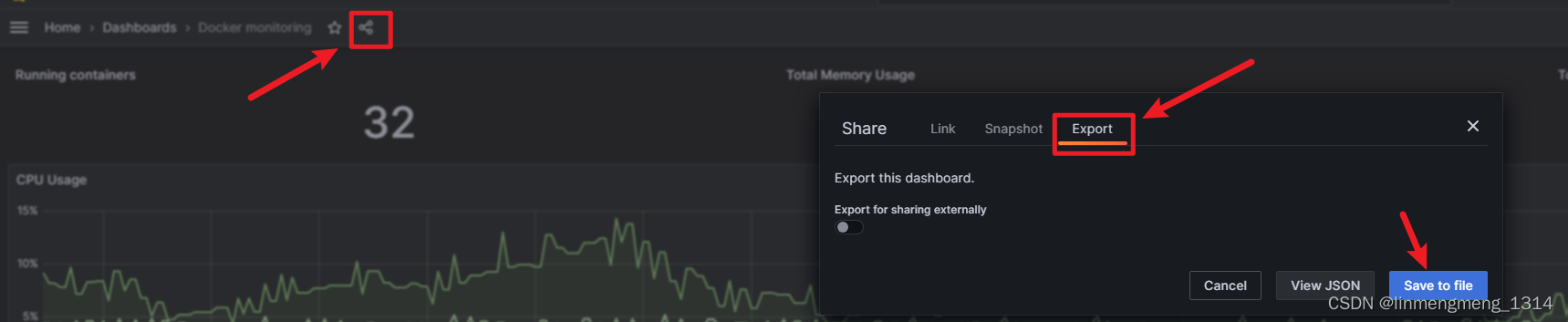
然后就会自动下载一个JSON文件,这个JSON文件就可以用来后续的备份还原和数据迁移;
3.3.2 导入JSON模板配置
首先有一个离线版本的JSON模板文件,如果是导入到其他环境,则需要修改下JSON文件中的 datasource.uid
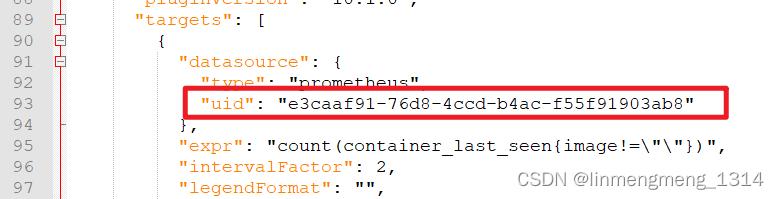
这个数据源ID是导出模板的那个环境的数据源ID,到了新的环境,配置的数据源ID就可能不是这个了,数据源ID获取可以进入数据源配置页面,从URL里面获取,如 查看 Prometheus 的数据源ID :
选中上面的 Prometheus,进入配置页面:
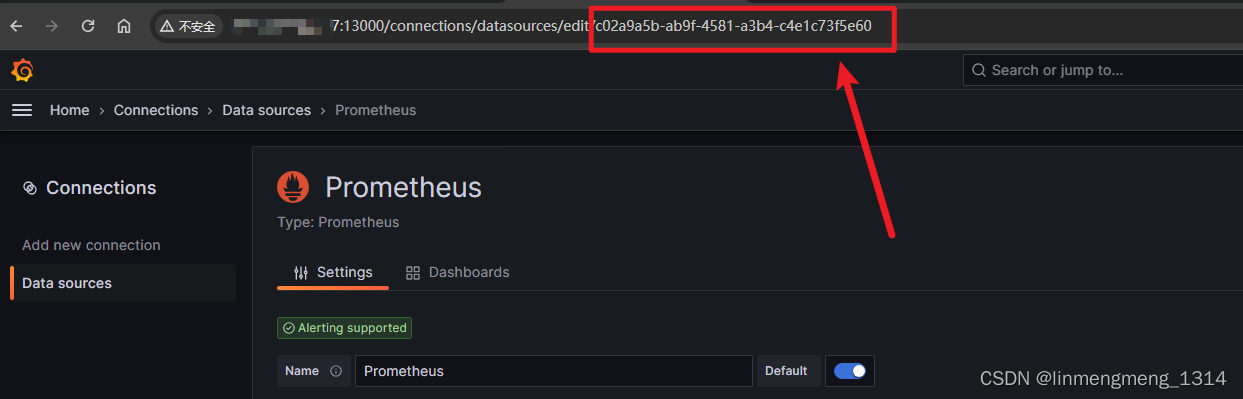
这个 就是数据源的ID了。
全局替换导出的 JSON模板里面的数据源uid后,保存;
进入面板导入页面,选择上传JSON文件
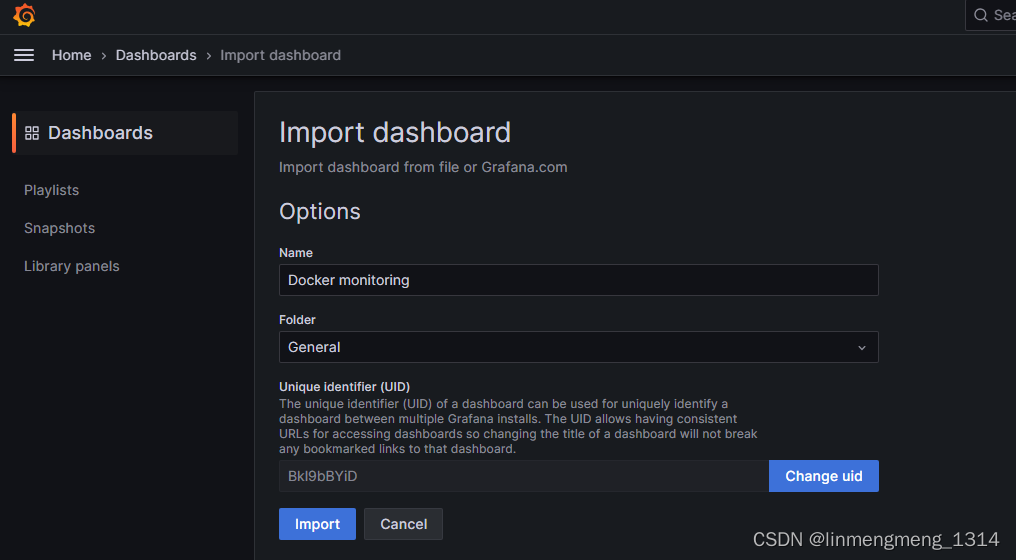
可以看到已经识别到模板的名称了,如果没有修改模板uid的需求,可以直接点击 Import 进行导入模板;
导入成功后,就可以看到模板统计的数据信息了。
3.4 系统服务嵌入 Grafana 面板页面
如果我们希望在某个系统里面直接访问监控页面,这时候可以前端直接嵌入一个页面,而这个页面的路由则为:http://IP:13000/d/Bkl9bBYiD
虽然 Grafana 默认不支持跨域访问,但是它又支持自定义访问URL,也就是 Grafana 的 /usr/share/grafana/conf/defaults.ini 配置文件中的 root_url,而这个 url 又支持环境变量注入;
完整的配置文件说明可以参考:https://grafana.com/docs/grafana/latest/setup-grafana/configure-grafana/
默认配置文件是 defaults.ini,自定义配置文件custom.ini 自定义配置文件会覆盖默认配置文件中的值;
当然也可以直接配置环境变量,来配置某些配置,比如配置一个代理 root_url 的配置:
version: "3"
services:grafana:user: '0'container_name: grafanaimage: harbor.huaun.com:11443/ai.radar/grafana:latesthostname: grafanarestart: alwaysdeploy:resources:limits:cpus: '1'memory: 1Gports:- 13000:3000volumes:- ./grafana/data/:/var/lib/grafana/#- ./grafana/conf/defaults.ini:/usr/share/grafana/conf/defaults.inienvironment:# 设置 Grafana 的 Root URLGF_SERVER_ROOT_URL: "https://192.168.104.147/monitor"
配置环境变量:GF_SERVER_ROOT_URL
改完再次访问原来的 Grafana 地址,就会提示:
If you're seeing this Grafana has failed to load its application files1. This could be caused by your reverse proxy settings.2. If you host grafana under subpath make sure your grafana.ini root_url setting includes subpath. If not using a reverse proxy make sure to set serve_from_sub_path to true.3. If you have a local dev build make sure you build frontend using: yarn start, or yarn build4. Sometimes restarting grafana-server can help5. Check if you are using a non-supported browser. For more information, refer to the list of supported browsers.
发现挂载环境变量不好使,还是改默认配置吧,配置文件内容过多,这里只贴出来前后对比要改动的内容:
# The public facing domain name used to access grafana from a browser
domain = localhost
# The full public facing url
root_url = %(protocol)s://%(domain)s:%(http_port)s/# Serve Grafana from subpath specified in `root_url` setting. By default it is set to `false` for compatibility reasons.
serve_from_sub_path = false# set to true if you want to allow browsers to render Grafana in a <frame>, <iframe>, <embed> or <object>. default is false.
allow_embedding = false
改成
# The public facing domain name used to access grafana from a browser
domain = 192.168.104.145# Redirect to correct domain if host header does not match domain
# Prevents DNS rebinding attacks
enforce_domain = false# The full public facing url
#root_url = %(protocol)s://%(domain)s:%(http_port)s/
root_url = https://192.168.104.145:443/monitor/# Serve Grafana from subpath specified in `root_url` setting. By default it is set to `false` for compatibility reasons.
serve_from_sub_path = true# set to true if you want to allow browsers to render Grafana in a <frame>, <iframe>, <embed> or <object>. default is false.
allow_embedding = true
这里 192.168.104.145 为本机IP地址,https://192.168.104.145:443/monitor/ 这个地址配置成 grafana 默认访问的地址,然后再 nginx 里面配置一个代理,代理此地址,映射到 Grafana 的访问页面上,就可以实现自定义配置访问路径了。
Nginx 配置文件,添加代理路径:
location /monitor {add_header 'Access-Control-Allow-Origin' '*';proxy_pass http://192.168.104.145:33000;}
这里是直接转发到 Grafana 的对应端口上的,如果Grafana的端口改了,这里需要对应上;
另外这里还需要注意一点,这里在使用 Nginx 代理的时候,IP地址不能写成服务名,就很奇怪;
配置完代理,就可以直接通过代理的路径来访问 Grafana 的页面了,比如:https://192.168.104.145/monitor/d/Bkl9bBYik/91856187-b73b-5d3b-ac43-5ed4d9af8542?orgId=1
这篇关于Prometheus + Grafana + Alertmanager 系统监控的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





