本文主要是介绍MySQL之嵌套循环【Join原理】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
从事DBA工作两年多以来,经常会遇到开发上线的SQL中含有多表关联join的查询,我自己本身也是比较抗拒的,很多DBA一般会建议开发拆分SQL,避免join带来的性能问题。但是我始终认为,任何事物存在必然有它的理由,不能全盘否定它!在5.5版本之前,MySQL只支持一种表间关联方式,也就是嵌套循环(Nested Loop)。如果关联的表数据量很大,那么join关联的时间会很长。在5.5版本以后,MySQL引入了BNL算法来优化嵌套循环。
二、Nested Loop Join算法
NLJ算法:将外层表的结果集作为循环的基础数据,然后循环从该结果集每次一条获取数据作为下一个表的过滤条件去查询数据,然后合并结果。如果有多个表join,那么应该将前面的表的结果集作为循环数据,取结果集中的每一行再到下一个表中继续进行循环匹配,获取结果集并返回给客户端。该算法的伪代码为:
1for each row in t1 matching range {
2 for each row in t2 matching reference key {
3 for each row in t3 {
4 if row satisfies join conditions,
5 send to client
6 }
7 }
8 }
普通的Nested-Loop Join算法一次只能将一行数据传入内存循环,所以外层循环结果集有多少行,那么内存循环就要执行多少次。
三、Block Nested-Loop Join算法
BNL算法原理:将外层循环的行/结果集存入join buffer,内存循环的每一行数据与整个buffer中的记录做比较,可以减少内层循环的扫描次数
举个简单的例子:外层循环结果集有1000行数据,使用NLJ算法需要扫描内层表1000次,但如果使用BNL算法,则先取出外层表结果集的100行存放到join buffer, 然后用内层表的每一行数据去和这100行结果集做比较,可以一次性与100行数据进行比较,这样内层表其实只需要循环1000/100=10次,减少了9/10。
伪代码如下:
1for each row in t1 matching range {
2 for each row in t2 matching reference key {
3 store used columns from t1, t2 in join buffer
4 if buffer is full {
5 for each row in t3 {
6 for each t1, t2 combination in join buffer {
7 if row satisfies join conditions,
8 send to client
9 }
10 }
11 empty buffer
12 }
13 }
14}
15
16
17if buffer is not empty {
18 for each row in t3 {
19 for each t1, t2 combination in join buffer {
20 if row satisfies join conditions,
21 send to client
22 }
23 }
24}
我们用一个示意图来简明阐述一下:
我们从这个图可以看到,BNL算法把t1和t2的结果集存放到join buffer中(t1表和t2表的关联,仍然是取出t1表的每一行记录和t2表的每一行记录进行匹配,t1表仍然是full scan全表扫描),而不是每次从t1表取出一条记录和t2表进行能过匹配得出结果集,就马上和t3进行关联。
对于放入到join buffer的列,是指所有参与查询的列,而不是只有join的列。如下面的这个查询:
SELECT a.col3 FROM a,b
WHERE a.col1 = b.col2
AND a.col2 > …. AND b.col2 = …
上述SQL语句外表是a,内表是b,那么存放在join buffer的列是所有参与查询的列,这里是:(a.col1、a.col2、a.col3).
我们可以从explain的sql执行计划中看到Extra有“using join buffer”,则说明mysql使用了join buffer来对sql进行优化.
使用join buffer的要点:
1)、join buffer size变量大小决定了buffer的大小
2)、只有在join类型为all 或者index或者range的时候,才可以使用join buffer(也就是说explain执行计划中,type为all或者index或者range的时候,才会出现Using join buffer)。如:
id: 1
select_type: SIMPLE
table: c
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 96
Extra: Using where; Using join buffer
这里type: ALL,所以可以使用join buffer.
3)、在join之前就会分配join buffer,在query执行完毕之后,立即释放buffer
先看一下实验的两张表:
表comments,总行数28856
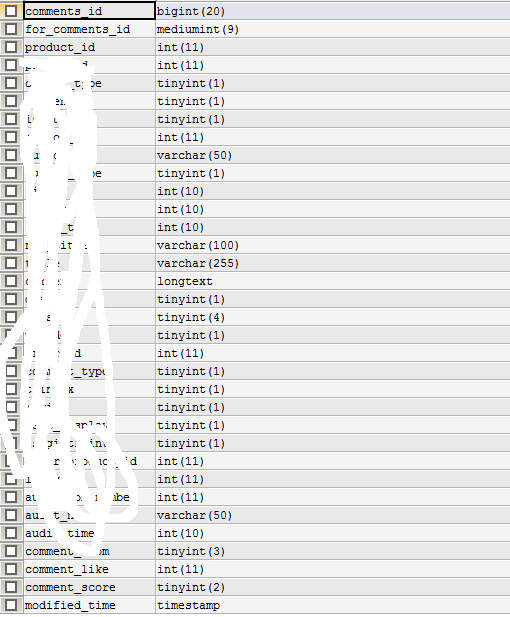
表comments_for,总行数57,comments_id是有索引的,ID列为主键。
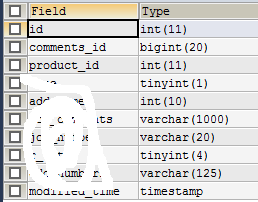
以上两张表是我们测试的基础,然后看一下索引,comments_for这个表comments_id是有索引的,ID为主键。
最近被公司某一开发问道JOIN了MySQL JOIN的问题,细数之下发下我对MySQL JOIN的理解并不是很深刻,所以也查看了很多文档,最后在InsideMySQL公众号看到了两篇关于JOIN的分析,感觉写的太好了,拿出来分享一下我对于JOIN的实际测试吧。下面先介绍一下MySQL关于JOIN的算法,总共分为三种(来源为InsideMySQL):
MySQL是只支持一种JOIN算法Nested-Loop Join(嵌套循环链接),不像其他商业数据库可以支持哈希链接和合并连接,不过MySQL的Nested-Loop Join(嵌套循环链接)也是有很多变种,能够帮助MySQL更高效的执行JOIN操作:
(1)Simple Nested-Loop Join(图片为InsideMySQL取来)
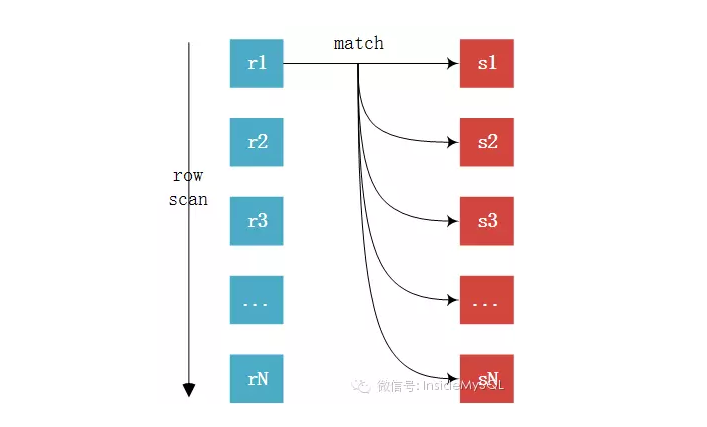
这个算法相对来说就是很简单了,从驱动表中取出R1匹配S表所有列,然后R2,R3,直到将R表中的所有数据匹配完,然后合并数据,可以看到这种算法要对S表进行RN次访问,虽然简单,但是相对来说开销还是太大了
(2)Index Nested-Loop Join,实现方式如下图:
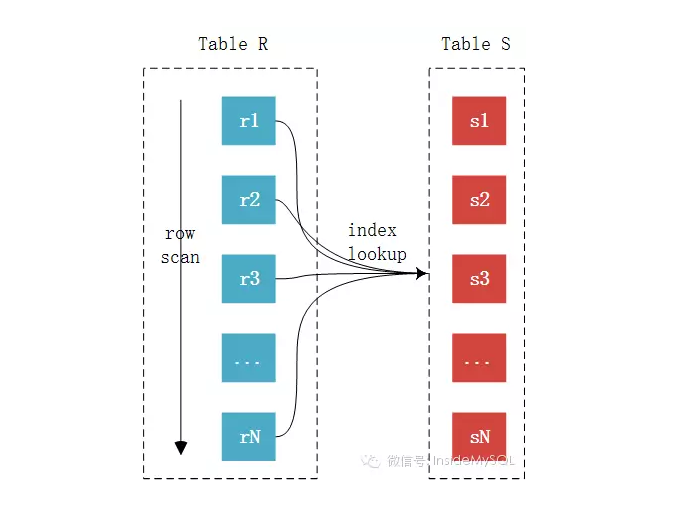
索引嵌套联系由于非驱动表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。这也就是平时我们在做关联查询的时候必须要求关联字段有索引的一个主要原因。
这种算法在链接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表。至于驱动表的选择,MySQL优化器一般情况下是会选择记录数少的作为驱动表,但是当SQL特别复杂的时候不排除会出现错误选择。
在索引嵌套链接的方式下,如果非驱动表的关联键是主键的话,这样来说性能就会非常的高,如果不是主键的话,关联起来如果返回的行数很多的话,效率就会特别的低,因为要多次的回表操作。先关联索引,然后根据二级索引的主键ID进行回表的操作。这样来说的话性能相对就会很差。
(3)Block Nested-Loop Join,实现如下:
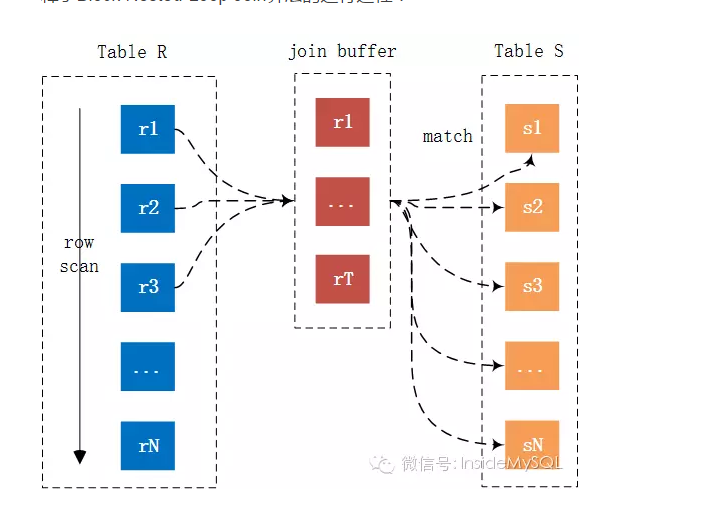
在有索引的情况下,MySQL会尝试去使用Index Nested-Loop Join算法,在有些情况下,可能Join的列就是没有索引,那么这时MySQL的选择绝对不会是最先介绍的Simple Nested-Loop Join算法,而是会优先使用Block Nested-Loop Join的算法。
Block Nested-Loop Join对比Simple Nested-Loop Join多了一个中间处理的过程,也就是join buffer,使用join buffer将驱动表的查询JOIN相关列都给缓冲到了JOIN BUFFER当中,然后批量与非驱动表进行比较,这也来实现的话,可以将多次比较合并到一次,降低了非驱动表的访问频率。也就是只需要访问一次S表。这样来说的话,就不会出现多次访问非驱动表的情况了,也只有这种情况下才会访问join buffer。
在MySQL当中,我们可以通过参数join_buffer_size来设置join buffer的值,然后再进行操作。默认情况下join_buffer_size=256K,在查找的时候MySQL会将所有的需要的列缓存到join buffer当中,包括select的列,而不是仅仅只缓存关联列。在一个有N个JOIN关联的SQL当中会在执行时候分配N-1个join buffer。
上面介绍完了,下面看一下具体的列子
(1)全表JOIN
EXPLAIN SELECT * FROM comments gc JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;
看一下输出信息:

可以看到在全表扫描的时候comments_for 作为了驱动表,此事因为关联字段是有索引的,所以对索引idx_commentsid进行了一个全索引扫描去匹配非驱动表comments ,每次能够匹配到一行。此时使用的就是Index Nested-Loop Join,通过索引进行了全表的匹配,我们可以看到因为comments_for 表的量级远小于comments ,所以说MySQL优先选择了小表comments_for 作为了驱动表。
(2)全表JOIN+筛选条件
SELECT * FROM comments gc JOIN comments_for gcf ON gc.comments_id=gcf.comments_id WHERE gc.comments_id =2056

此时使用的是Index Nested-Loop Join,先对驱动表comments 的主键进行筛选,符合一条,对非驱动表comments_for 的索引idx_commentsid进行seek匹配,最终匹配结果预计为影响一条,这样就是仅仅对非驱动表的idx_commentsid索引进行了一次访问操作,效率相对来说还是非常高的。
(3)看一下关联字段是没有索引的情况:
EXPLAIN SELECT * FROM comments gc JOIN comments_for gcf ON gc.order_id=gcf.product_id
我们看一下执行计划:

从执行计划我们就可以看出,这个表JOIN就是使用了Block Nested-Loop Join来进行表关联,先把comments_for (只有57行)这个小表作为驱动表,然后将comments_for 的需要的数据缓存到JOIN buffer当中,批量对comments 表进行扫描,也就是只进行一次匹配,前提是join buffer足够大能够存下comments_for的缓存数据。
而且我们看到执行计划当中已经很明确的提示:Using where; Using join buffer (Block Nested Loop)
一般情况出现这种情况就证明我们的SQL需要优化了。
要注意的是这种情况下,MySQL也会选择Simple Nested-Loop Join这种暴力的方法,我还没搞懂他这个优化器是怎么选择的,但是一般是使用Block Nested-Loop Join,因为CBO是基于开销的,Block Nested-Loop Join的性能相对于Simple Nested-Loop Join是要好很多的。
(4)看一下left join
EXPLAIN SELECT * FROM comments gc LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
看一下执行计划:

这种情况,由于我们的关联字段是有索引的,所以说Index Nested-Loop Join,只不过当没有筛选条件的时候会选择第一张表作为驱动表去进行JOIN,去关联非驱动表的索引进行Index Nested-Loop Join。
如果加上筛选条件gc.comments_id =2056的话,这样就会筛选出一条对非驱动表进行Index Nested-Loop Join,这样效率是很高的。
如果是下面这种:
EXPLAIN SELECT * FROM comments_for gcf LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id WHERE gcf.comments_id =2056
通过gcf表进行筛选的话,就会默认选择gcf表作为驱动表,因为很明显他进行过了筛选,匹配的条件会很少,具体可以看下执行计划:

这篇关于MySQL之嵌套循环【Join原理】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






