本文主要是介绍RedoLog和Checkpointnotcomplete,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原 Redo Log 和Checkpoint not completehttps://blog.csdn.net/tianlesoftware/article/details/4908066版权声明: https://blog.csdn.net/tianlesoftware/article/details/4908066
首先我们来看下 alertSID.log 日志:
Mon Nov 30 17:31:54 2009
Thread 1 advanced to log sequence 14214 (LGWR switch)
Current log# 3 seq# 14214 mem# 0: /u03/oradata/newccs/redo03.log
Mon Nov 30 17:34:29 2009
Thread 1 advanced to log sequence 14215 (LGWR switch)
Current log# 1 seq# 14215 mem# 0: /u03/oradata/newccs/redo01.log
Mon Nov 30 17:35:54 2009
Thread 1 cannot allocate new log, sequence 14216
Checkpoint not complete
Current log# 1 seq# 14215 mem# 0: /u03/oradata/newccs/redo01.log
Mon Nov 30 17:35:55 2009
Thread 1 advanced to log sequence 14216 (LGWR switch)
Current log# 2 seq# 14216 mem# 0: /u03/oradata/newccs/redo02.log
Mon Nov 30 17:40:25 2009
Thread 1 advanced to log sequence 14217 (LGWR switch)
Current log# 3 seq# 14217 mem# 0: /u03/oradata/newccs/redo03.log
Mon Nov 30 17:44:22 2009
Thread 1 advanced to log sequence 14218 (LGWR switch)
Current log# 1 seq# 14218 mem# 0: /u03/oradata/newccs/redo01.log
我们先来分析下它的原因和后果:
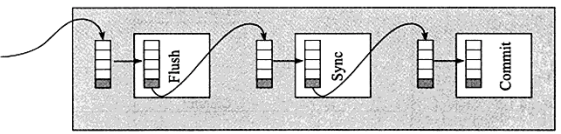
当我们进行redo 切换的时候,会触发checkpoint 事件。 触发该事件有5个条件。 下文有说明。 Checkpoint做的事情之一是触发DBWn把buffer cache中的Dirty cache磁盘。另外就是把最近的系统的SCN更新到datafile header和control file(每一个事务都有一个SCN),做第一件事的目的是为了减少由于系统突然宕机而需要的恢复时间,做第二件事实为了保证数据库的一致性。
Checkpoint will flush dirty block to datafile, 从而触发DBWn书写dirty buffer,等到redo log覆盖的dirty block全部被写入datafile后才能使用redo log(循环使用),如果DBWn写入过慢,LGWR必须等待DBWn完成,则这时会出现“checkpoint not completed!”。 所以当出现checkpoint not competed的时候,还会伴随cannot allocate new log的错误。
如果遇到这个问题,可以增加日志组和增大日志文件,当然也可以修改 checkpoint参数使得检查点变频繁一些。
在出现这个错误的时候,数据库是短暂hang住的,等待checkpoint的完成。 在hang住的时候,没有日志产生。
Tom 同学对这个问题的解释如下:
the infamous "checkpoint not complete, cannot allocate new log" message.
this occurrs when Oracle attempts to reuse a log file but the checkpoint that would flush
the blocks that may have redo in this log file has not yet completed -- we must wait
until that checkpoint completes before we can reuse that file -- thats when this message is printed. during this time (when we cannot allocate a new log) processing is suspended in the database while the checkpoint is made to complete ASAP.
-- 我们必须等待checkpoint 的完成, 在这个过程中, 数据库是短暂的hang住的。
The major way to relieve this is to have sufficient log to carry you through peak times. that way, we can complete the checkpoint while you are not busy. also make sure your checkpoints happen as fast as they can (eg: enable ASYNC IO or configure >1 DBWR if ansyc IO cannot be used, make sure disks are not contending with other apps and so on)
Another way is to make the log files smaller, hence increasing the frequency with which we checkpoint (log checkpoint interval and other init.ora parameters achieve the same effect btw).
这个主题使DBA能对checkpoint和checkpoint优化的参数有一个较好的理解:
- FAST_START_MTTR_TARGET
- LOG_CHECKPOINT_INTERVAL
- LOG_CHECKPOINT_TIMEOUT
- LOG_CHECKPOINTS_TO_ALERT
它也解释了怎样解释和处理出现在ALERT<sid>.LOG file中的checkpoint的错误"'Checkpoint not Complete' and 'Cannot Allocate New Log"。
什么是checkpoint
Checkpoint是为了内存中已经被修改的数据块与磁盘数据文件同步的一种数据库事件。它提供了一种保持事务提交以后数据一致的手段。往Oracle磁盘写脏数据的机制与事务提交不是同步的。
checkpoint有两个目的:
1、确保数据一致性。
2、使数据库能快速地恢复。
怎样快速恢复
因为数据库会把所有的改变都在数据文件上设置checkpoint并一直增加,它不需要请求checkpoint之前的重做日志,Checkpoint能保证所有在缓存区的数据写到相应的数据文件,防止因为意外的实例失败导致的数据丢失。
Oracle写这个脏数据只在一定的条件下:
1、DBWR 超时,大约3秒时间
2、系统中没有多的空缓冲区来存放数据
3、CKPT进程(产生新的checkpoint) 触发DBWR。
一个checkpoint有5中事件类型:
1、每次重做日志的切换;
2、LOG_CHECKPOINT_TIMEOUT 这个延迟参数的到达;
3、相应字节(LOG_CHECKPOINT_INTERVAL* size of IO OS blocks)被写到当前的重做日志;
4、ALTER SYSTEM SWITCH LOGFILE 这个命令会直接导致checkpoint发生
5、ALTER SYSTEM CHECKPOINT
Checkpoint期间会有下面进程发生:
1. DBWR写所有脏数据到数据文件;
2. LGWR更新控制文件和数据文件的SCN。
Checkpoints和优化:
Checkpoints是一个数据库优化的难点。频繁的Checkpoints可以实现快速的恢复,但也会使性能下降。怎样处理这个问题呢?
依赖于数据库数据文件的数量,一个Checkpoint可能是高速的运行。因为所有的数据文件在Checkpoint期间都会被冻结。更频繁的Checkpoints可以快速恢复数据库。这也客户对不按规定系统宕机的容忍的原因。然而,在一些特殊情况下,频繁的Checkpoints也不能保证可以快速恢复。我们假设数据库在95%的时间内是正常运行,5%由于实例失败导致不可用,要求恢复。对大多数客户而言,他们更希望调整95%的性能而不是5%的宕机时间。这个假设表明,性能是摆在第一位的,所以我门的目标就是在优化期间减少Checkpoints的频繁度。
优化Checkpoints包括4个关键的初始化参数:
- FAST_START_MTTR_TARGET
- LOG_CHECKPOINT_INTERVAL
- LOG_CHECKPOINT_TIMEOUT
- LOG_CHECKPOINTS_TO_ALERT
详细介绍每个参数:
FAST_START_MTTR_TARGET:
Oracle9i以来FAST_START_MTTR_TARGET 参数是调整checkpoint的首选的方法。FAST_START_MTTR_TARGET 可以指定单实例恢复需要的秒数。基于内部的统计,增长的checkpoint会自动调整的checkpint的目标以满足FAST_START_MTTR_TARGET 的需求。
V$INSTANCE_RECOVERY.ESTIMATED_MTTR 显示当前估计需要恢复的秒数。这个值会被显示即使FAST_START_MTTR_TARGET 没有被指定。
V$INSTANCE_RECOVERY.TARGET_MTTR 表明在短时间内MTTR的目标。
V$MTTR_TARGET_ADVICE 显示这个当前MTTR设置的工作量产生的I/O数量和其他I/O。这个视图帮助用户评定这个在优化和恢复之前的平衡。
LOG_CHECKPOINT_INTERVAL:
LOG_CHECKPOINT_INTERVAL 参数指定这个最大的重做块的间隔数目。如果FAST_START_MTTR_TARGET被指定,LOG_CHECKPOINT_INTERVAL不能被设置为0。
在大多数Unix系统的OS块大小是512字节。设置LOG_CHECKPOINT_INTERVAL=10000意味着这个增长的checkpoint不能追加到当前日志,因为多于5M。如果你的重做日志是20M,你将发出4个checkpoint对每个重做日志。
LOG_CHECKPOINT_INTERVAL 会发生影响当一个checkpoint发生时,小心设置这个参数,保持它随着重做日志文件大小变化而变化。checkpoint频繁是这个影响数据库恢复的原因之一。短的checkpoint间隔意味数据库将快速恢复,也增加了资源的利用。这个参数也影响数据库向前回滚的时间。实际的恢复时间是基于这个时间,当然还有失败的类型和需要归档日志的数量。
LOG_CHECKPOINT_TIMEOUT:
这个参数指定checkpoint发出的时间间隔。换句话说,它指定一次脏数据多少时间写出一次。checkpoint频率会影响这个数据库恢复的时间。长时间的间隔会要求数据库恢复要求更久。Oracle建议用LOG_CHECKPOINT_interval去控制checkpoint而不用LOG_CHECKPOINT_TIMEOUT,LOG_CHECKPOINT_TIMEOUT每n秒发一次checkpoint,不顾事务提交的频率。这可能会导致一些没有必要的checkpoint在事务已经变化的情况下。不必要的checkpoint必须被避免。还有一个容易误解的地方:LOG_CHECKPOINT_TIMEOUT 会间隔性地发出log switch。而Log switch会触发一个checkpoint,但checkpoint不会导致一个log switch。唯一手工方式alter system switch logfile或者重新设置redo logs大小可以导致频繁switch。
SQL> alter system set log_checkpoint_timeout=300;[单位是秒]
log_checkpoint_to_alert:
设置为真,可以在告警日志中观察到增量检查点的触发。
SQL> alter system set log_checkpoints_to_alert=true;
对于优化和恢复, 在线重做日志的大小是关键的。
修改Redo log 大小的操作方法:
查看当前日志组状态:
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 14230 52428800 1 ACTIVE
2 14231 52428800 1 CURRENT
3 14229 52428800 1 INACTIVE
CURRENT: 表示是当前的日志。
INACTIVE:脏数据已经写入数据块。该状态可以drop。
ACTIVE: 脏数据还没有写入数据块。
查看当前日志组成员:
SQL> select member from v$logfile;
MEMBER
--------------------------------------------------------------------------------
/u03/oradata/newccs/redo03.log
/u03/oradata/newccs/redo02.log
/u03/oradata/newccs/redo01.log
添加online redo log组:
SQL> alter database add logfile group 4 ('/u03/oradata/newccs/redo04.log') size 100m reuse;
SQL> alter database add logfile group 5 ('/u03/oradata/newccs/redo05.log') size 100m reuse;
SQL> alter database add logfile group 6 ('/u03/oradata/newccs/redo06.log') size 100m reuse;
切换归档日志:
SQL> alter system switch logfile;
查看归档文件的状态,因为只有Inactive的我们才可以drop,它的数据块已经写入了数据块。如果是Active状态,表示这里的脏数据还没有写入写入数据库,手工加个全局检查点,督促CKPT马上唤醒DBWR写入脏数据
SQL>alter system checkpoint;
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 14230 52428800 1 ACTIVE
2 14231 52428800 1 ACTIVE
3 14229 52428800 1 INACTIVE
4 14229 52428800 1 CURRENT
5 14229 52428800 1 UNUSED
6 14229 52428800 1 UNUSED
因为5,6 我们还没有用,所以显示为UNUSED
删除redo log组:
SQL> alter database drop logfile group 1;
Database altered.
或者:
SQL> alter database drop logfile '/u03/oradata/newccs/redo01.log';
在添加redo log group 1.
SQL> alter database add logfile group 1 ('/u03/oradata/newccs/redo01.log') size 100m reuse;
通过删除在添加,达到对redo log group 的resize.
注意两点
1. 单纯加redo log group单个文件的大小没有作用,同一个group里,文件大小都是一致的。
2. 如果是归档模式的话,确保已经自动归档,如果手动归档的话,需要在alter system switch logfile锁死的时候,用alter system log current 来手动归档。或者通过alter system archive log start打开自动归档。否则的话,当redo log group切换完整个groups的时候,会一直等待状态(******).
3. 《Oracle DBA必备技能详解》(Robert G.Freeman),上面建议redo log 最好是15分钟切换一次
https://img-blog.csdnimg.cn/20190217105710569.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTEwNzgxNDE=,size_16,color_FFFFFF,t_70《算法导论 第三版英文版》_高清中文版.pdf
https://pan.baidu.com/s/17D1kXU6dLdU0YwHM2cvNMw
《深度学习入门:基于Python的理论与实现》_高清中文版.pdf
https://pan.baidu.com/s/1IeVs35f3gX5r6eAdiRQw4A
《深入浅出数据分析》_高清中文版.pdf
https://pan.baidu.com/s/1GV-QNbtmjZqumDkk8s7z5w
《Python编程:从入门到实践》_高清中文版.pdf
https://pan.baidu.com/s/1GUNSg4mdpeOf1LC_MjXunQ
《Python科学计算》_高清中文版.pdf
https://pan.baidu.com/s/1-hDKhK-7rDDFll_UFpKmpw
这篇关于RedoLog和Checkpointnotcomplete的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!