本文主要是介绍Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

梁栎鹏(立蓬)
蚂蚁集团技术工程师
云原生领域工程师
就职于蚂蚁集团中间件团队,参与维护与建设蚂蚁 SOFAArk 和 Koupleless 开源项目,参与内部 SOFAServerless 产品的研发和实践。
本文 4873 字,预计阅读 12 分钟
本篇文章属于 Koupleless 进阶系列文章第三篇,默认读者对 Koupleless 的基础概念、能力都已经了解,如果还未了解过的可以查看官网(https://koupleless.io/)。
进阶系列一:Koupleless 模块化的优势与挑战&我们是如何应对挑战的
进阶系列二:Koupleless 单进程多应用如何解决兼容问题
在前面进阶系列的文章里,我们介绍了 Koupleless 模块化适用的一些场景,这里大都涉及把多个应用合并在一个基座里。大家可能会有一个问题:一台机器最多能安装多少个模块应用呢?为了帮助大家更好的理解 Koupleless 模块化的价值、评估生产上部署的策略,这篇文章我们就尝试回答下这个问题,并分析一个模块应用需要消耗多少资源,在日常迭代时需要考虑哪些问题。
模块数量的上限在哪里?
这个问题也可以换一种方式来问,那就是——一台机器最多能安装多少个模块应用?
如果使用的是静态合并部署,一个基座能安装的模块数量上限,在计算能力允许的前提下,主要取决于模块消耗的内存。根据进阶系列第一篇文章里的数据,一个模块在强制 gc 后消耗 30M 内存,包括堆内存和非堆内存,假如一个 4C8G 的机器,JVM 配置 6G 内存,预留2G 内存给运行器创建的一些临时对象,那么可以用于安装模块的内存空间大小为 4G,那么总共可以安装的模块数量 = 4000M / 30M = 133 个模块。
如果是动态合并部署,即:模块升级时无需重启基座,直接安装模块到正运行的基座上,也称为热部署方式。热部署方式除了需要考虑基座启动后可提供模块消耗的内存,还需要考虑每次热部署新版本后,在卸载老版本时候,老版本占用内存的回收情况,老版本内存是否能全部回收给新版本模块使用。根据实际观察验证,我们发现老版本的内存回收需要考虑这两方面:
堆内存:从 JVM 资源视角中,堆内存中旧版本模块的实例不再可达,可以通过 GC 回收给其他模块应用/基座应用继续使用。
非堆内存:Metaspace 的回收要求较高,需要满足三个条件“该类的所有的实例对象都已被 GC”、“该类没有在其他任何地方被引用”、“且该类的类加载器的实例已被GC”。在 koupleless 中,模块的每次安装都会产生一个模块实例,每个模块实例都由一个新的 ClassLoader 加载,由于该 ClassLoader 被 Spring ApplicationContext 等运行环境持有,无法彻底回收,导致整个模块实例的非堆内存基本无法回收。
所以这就导致了模块热部署后 Metaspace 的使用只增不减,每次部署需要消耗 Metaspace 资源,成为热部署模块数量上限的主要因素。
🌰举个例子:模块安装了版本 1.0 到基座,接着用户修改了模块代码,热部署版本 2.0 到基座,然后用户又修改了模块代码,热部署版本 3.0 到基座。从用户和框架视角看,现在该基座中只有模块应用 3.0,模块应用 1.0 和 2.0 已经被卸载;但从 Metaspace 视角看,模块 1.0 和 2.0 占用的空间不会被释放,仍旧占用 Metaspace 资源,如下图:
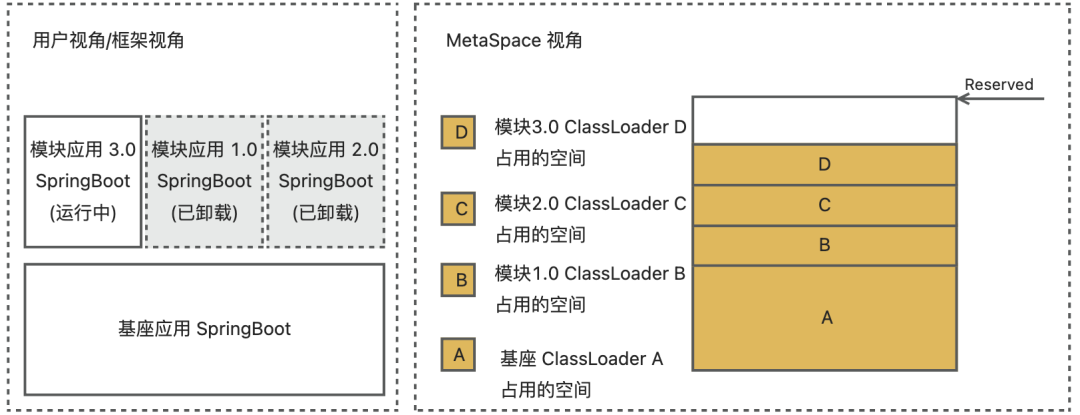
因此在热部署场景下,初始时不应该安装过多模块把 Metaspace 用完,而应该留有一定的 Metaspace Buffer 给模块热部署,所以对于 4C8G 的机器,我们可以在静态合并部署的基础上,减少模块数量,从而提高可以热部署的次数。由实际经验,采用动态合并部署的模块数量建议为静态合并部署的模块数量理论值上限的 1/2,也就是 133/2 = 66 个模块,从而给热部署模块预留出一部分的空间。
既然模块安装的数量存在上限,且上限主要取决于 Metaspace 的内存消耗,那么到达上限时会出现什么情况?一般是会触发 Metaspace 的 OOM 从而导致 FullGC,但是 FullGC 又无法清理 Metaspace 的内存消耗,这就会导致不断地 FullGC,从而可能对请求的 RT 产生影响。在这种情况下,我们一般只需要设置好 Metaspace 消耗的阈值然后重启即可,但是为了严谨考虑,我们需要从整个研发到上线的完整过程中分析这个问题。
如何应对模块数量或安装次数的上限?
为了避免模块在安装或运行时达到 Metaspace 上限影响多应用的正常运行,我们可以在应用的研发时 → 运维时 → 运行时的全链路上做全链路的防御、检测和自动处理。
研发时

降低单个模块占用 Metaspace
首先我们可以尽可能地降低单个模块占用的 Metaspace 消耗,从而让一个机器能安装或热部署的模块数量尽可能高。同时,由于基座升级或者机器自身重启都会清理掉 Metaspace,模块迭代过程可以很少触发上限问题。
由于 Metaspace 主要用于存储类的元数据、方法的元数据以及常量池,因此 Metaspace 使用大小取决于不同 ClassLoader 的数量以及 ClassLoader 加载的类信息的总量大小,那么可以通过减少模块 ClassLoader 加载的类数量和减少模块中创建的 ClassLoader 总量来降低 Metaspace 使用。
减少模块 ClassLoader 加载的类数量:在 Koupleless 中,建议用户把模块与基座相同依赖包的依赖范围配置为 provided,这些类可以由模块委托给基座加载,模块打包不会包含这些被复用的类,模块 ClassLoader 运行时也只加载模块特有的类,从而降低运行期间 Metaspace 的内存占用。
减少模块创建的 ClassLoader 总量:在开发时,避免写出会造成大量 ClassLoader 只加载一个类的代码😯(例如在 fastjson 等为了提高性能会动态创建类缓存,存在可能大量创建只加载很少类的 ClassLoader,通过调整 fastjson 的使用可以避免该问题发生)。
运维时
主动检测、防御与处理模块的 Metaspace 消耗
模块发布不可避免地会带来 Metaspace 使用增长,此时我们需要考虑的是如何让模块发布给原本正常运行的基座带来的影响最小,即:拒绝安装会导致 Metaspace OOM 的模块,并自动化处理预期外的 Metaspace OOM。
我们从模块发布流程来看。模块发布有两个阶段:模块安装和模块挂流对外提供服务,这两个阶段都可能会引起 Metaspace 增长,因此需要关注模块安装前后和模块对外提供服务时 Metaspace 的使用率,当使用率超出设定阈值时在不同阶段做不同处理:
模块安装前:平台侧统计该模块每次安装对 Metaspace 的内存消耗,在安装前获取此时 JVM 的 Metaspace 使用情况,以此预估该模块本次安装后该机器的 Metaspace 使用率是否会超过阈值,如果超过阈值则拒绝该次发布,提示用户重启/替换该机器。将机器记录在重启列表中,后续重启。
模块安装后:平台侧计算此时 Metaspace 内存使用率,如果超过阈值则机器记录在重启列表中,后续重启。
模块挂流对外提供服务一定时长后:平台侧计算此时 Metaspace 使用率,如果超过阈值则卡住发布单,由用户决定是否需要重启或替换该机器。
那么怎么定义 Metaspace 使用率更合理呢?
定义 Metaspace 的使用率
在 Koupleless 中使用内存分配比例(commited / MaxMetaspaceSize)作为使用率,而不是实际使用比例(used / MaxMetaspaceSize)。
在一般情况下,应用会把 Metaspace 的实际使用比例作为 Metaspace 的使用率,当使用率超出设定阈值时做一些处理避免 Metaspace OOM。但在一些特殊场景下仍会出现 Metaspace 使用率低但还是 Metaspace OOM 的情况,如:上万个不同 ClassLoader 只加载了一个类。举个例子,开发者使用 fastjson 在每次序列化时都 new ParserConfig(),使得每次序列化都会创建新 ClassLoader,该新 ClassLoader 只加载了被序列化的这个类,当有上万次序列化时,JVM 中会存在上万个不同 ClassLoader 只加载了一个类。
我们从 Metaspace 的内存分配及使用上来看该情况的成因:Metaspace 已分配的空间与实际使用的空间大小不同,如果实际使用空间较少,但已分配的空间已达到上限,Metaspace 也会 OOM。Metaspace 每次给 ClassLoader 分配内存时的基本单位是 Chunk(1K、4K、64K等),一个 Chunk 只能被一个 ClassLoader 独享,而一个 ClassLoader 能占用多个 Chunk。那么如果一个 Chunk 没有被该类加载器用完,且该类加载器不再加载新的类,那么剩余空间就被浪费掉了。比如:Metaspace 给某类加载器只分配少量 Chunk(共 6 KB),该类加载器只加载一个类使用 3 KB,那么另外 3KB 就被浪费了;当 JVM 配置了 MaxMetaspaceSize 为 128 MB,在运行时创建了 20000 个这种类加载器,共分配了 120MB 内存,虽然 Metaspace 使用率只有 50%,但已经不断触发 Metaspace OOM 了,如下图所示:
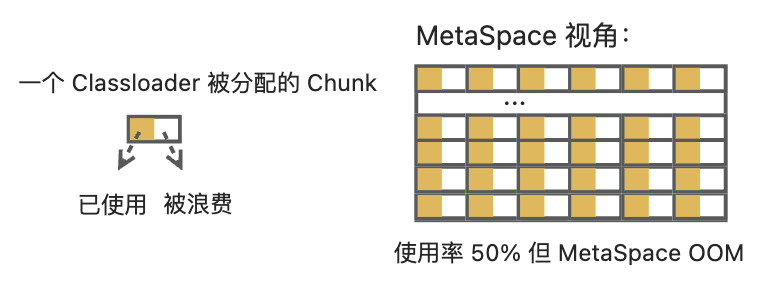
因此需要使用 Metaspace 内存分配比例作为使用率。
运行时
持续观测与自动处理 Metaspace 消耗
运行时框架 sdk 里会以时间窗口主动获取 Metaspace 的内存分配比例(Commited / MaxMetaspaceSize)作为使用率,上报至平台侧。如果线上机器长时间超过阈值,可以通过短信或其他方式告知到用户;如果线下机器一段时间内超出阈值,则平台侧主动在触发定时重启。
在蚂蚁集团内部,Koupleless 使用该方式在应用的研发、运维和运行的全链路上做了 Metaspace 的防御、检测和恢复,机器在达到 Metaspace 上限前基本通过主动和被动的自愈重启方式完成 Metaspace 清理,有效地防止模块安装数量与次数上限带来的影响。
总结与展望
我们当前通过检测、防御和自动恢复等方式,基本解决了模块数量上限的影响。但这里可能会有人提出新的问题:“模块的资源消耗是否可以强隔离?如果模块的资源消耗是强制隔离的,是不是也就没有 Metaspace 消耗的上限问题呢?”
实际上资源的强制隔离是可以避免 Metaspace 的消耗上限带来的 fullgc 问题,但资源的强隔离会导致模块无法复用基座的内存,导致模块资源的占用量变大,使得一个机器上能安装的模块或者安装次数只能在 10 个左右,带来的数量的下降是非常明显的。从实际出发,是否需要资源的强隔离,需要综合考虑成本和获得的收益:
cost
资源强隔离成本
1. 用户编程界面有侵入,参考 alijdk 的多租户隔离文档(https://github.com/dragonwell-project/dragonwell8/wiki/%E4%BD%BF%E7%94%A8Alibaba-Draognwell%E5%A4%9A%E7%A7%9F%E6%88%B7%E7%89%B9%E6%80%A7%E7%AE%A1%E6%8E%A7%E8%BF%90%E8%A1%8C%E6%97%B6%E8%B5%84%E6%BA%90)
2. 目前没有成熟的同进程的隔离方案。如果使用进程隔离,那么也完全背离了模块化的初衷。
benefit
资源强隔离收益
1. 资源的可靠性保障:在公有云情况下,资源的强隔离可以避免部分恶意用户的模块资源过大抢占其他模块的资源,但在私有企业内部极少会发生恶意抢占,该收益并不明显。
2. 避免极端情况的模块数量上限带来的影响:该收益也不明显,因为这些极端情况也可以通过检测和自动恢复解决。
综合考虑,资源的强隔离成本明显大于收益,目前也没有成熟的实现方案,收益也并不明显。所以对于当前这类问题只需做好配到的检测和自动恢复手段即可,不必作为企业内部是否采用模块化技术的评判标准。
未来,随着技术的不断发展,我们也一定会与整个社区和行业共同努力,持续探讨新的隔离与共享技术,在确保获得共享的收益情况下,解决掉当前共享带来的这些问题,让模块化的技术能给更多的业务带来收益。
最后,再次欢迎大家使用 Koupleless,我们期待您宝贵的意见!
「阅读原文」 Koupleless star 一下
https://github.com/koupleless/koupleless
相关推荐阅读

Koupleless 单进程多应用如何解决兼容问题

Koupleless 模块化隔离与共享带来的收益与挑战

Koupleless 带来拆分插件,帮你提高协作开发效率!

大象转身:支付宝资金技术 Serverless 提效总结

这篇关于Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






