本文主要是介绍16 zset 相关操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
相关介绍主要围绕着如下的一些常用的命令, 来看看 zset 相关操作的具体 api
如下常用的命令来自于我们常见的教程 : https://www.runoob.com/redis/redis-sorted-sets.html
本文的相关代码 拷贝自 redis-6.2.0
代码来自于 https://redis.io/
数据结构
当 zset 中的元素数量小于等于 zset_max_ziplist_entries(默认为 128), 并且每一个元素长度都小于等于 zset_max_ziplist_value(默认为 64) 的时候, 是基于 ziplist 来存储数据
否则是基于 skiplist 来存储数据
ZADD key score1 member1 [score2 member2]

这里可以看出的是 参数的数量要求大于等于 4 个, 可以传递 多个 score, member 对
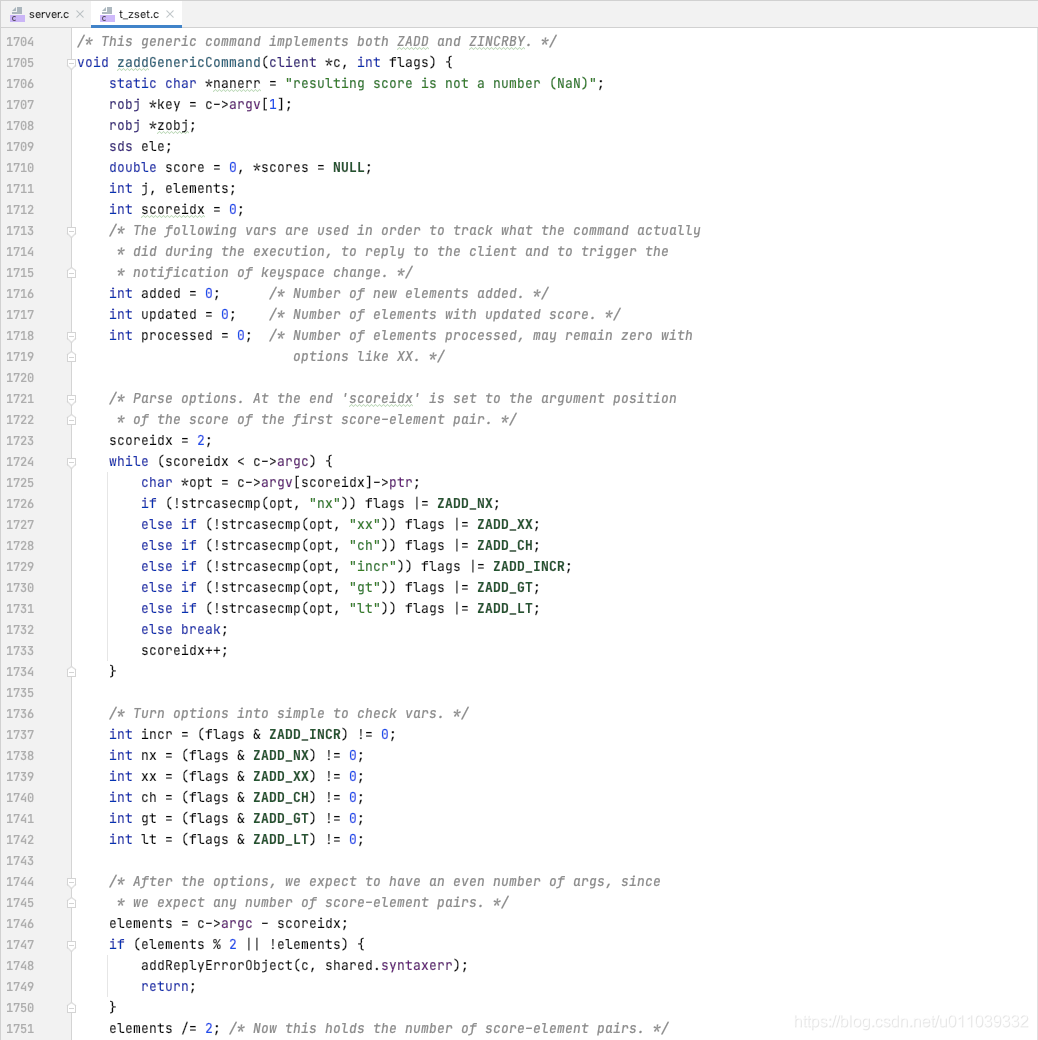
我们来看一下 zaddCommand
搜显示 校验客户端输入的 options, 存储到 flags 里面, 接着 从 flags 中提取上下文所需要的标记到标记变量
校验 score, member 是否是成对出现, 各个 flag 是否存在冲突的标记
解析各个 score 数组, 确保格式正确
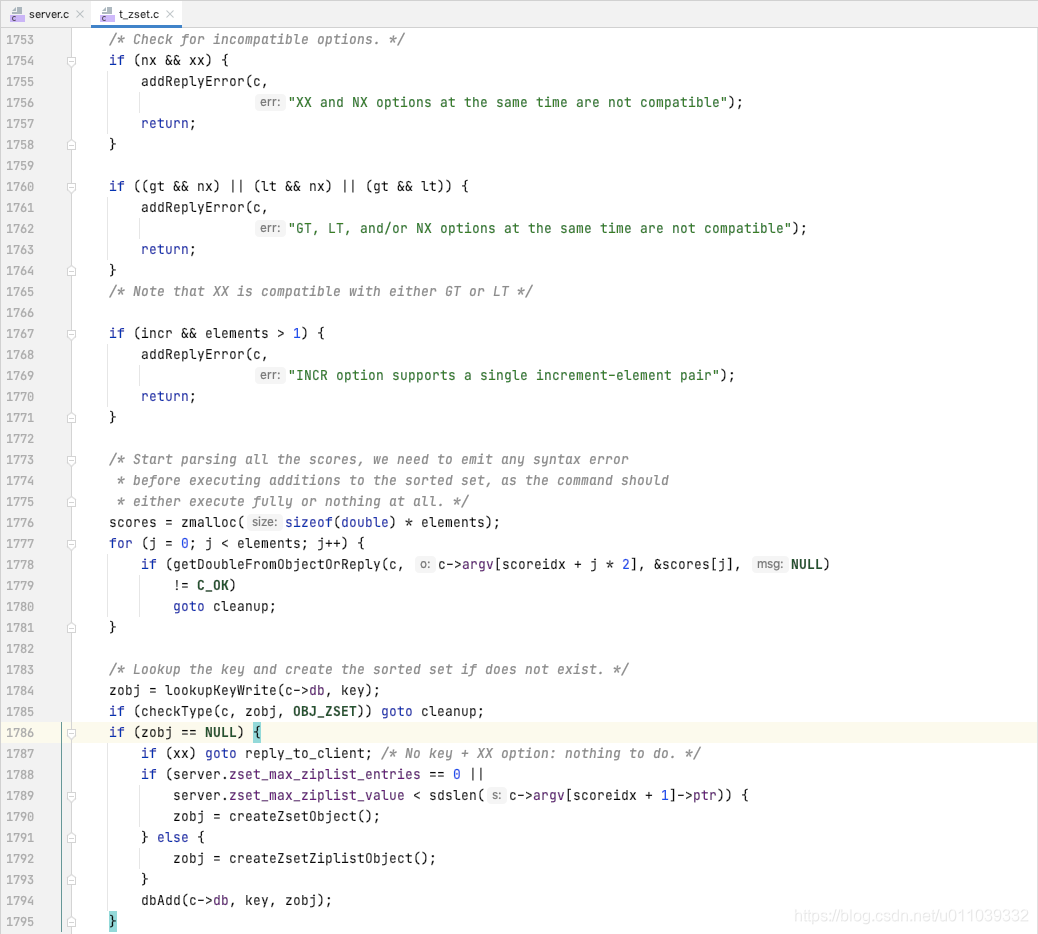
如果 zset 不存在, 则创建给定的 zset, 并初始化到 db->dict 里面
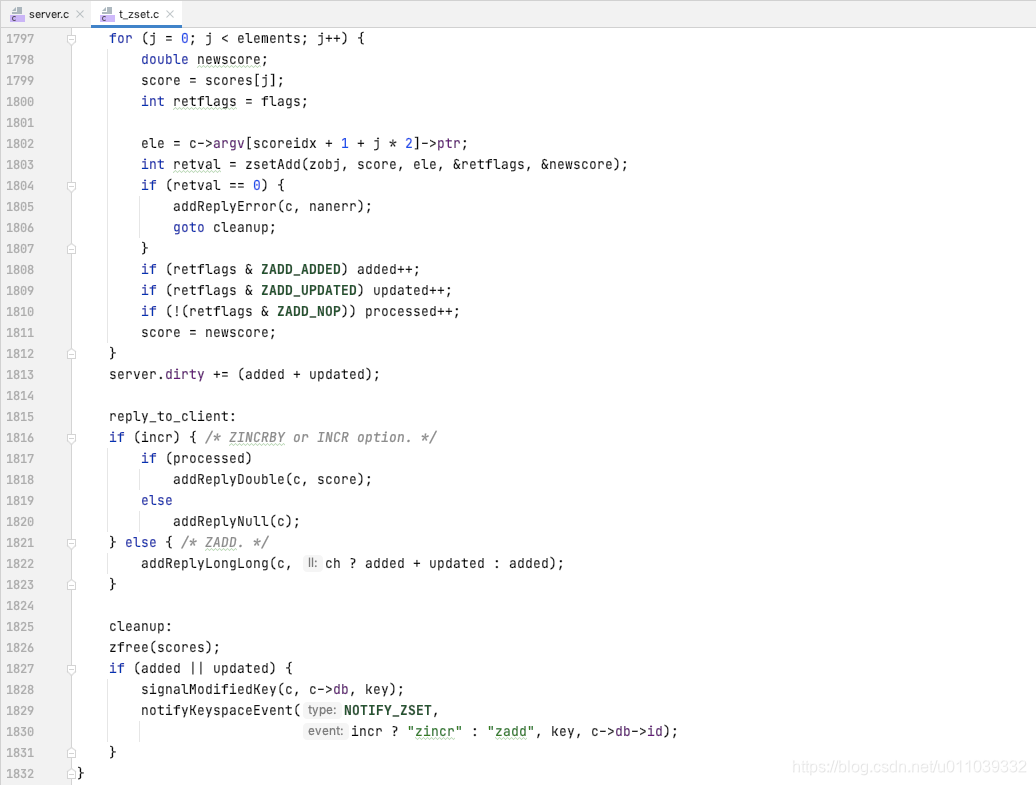
然后循环 score, member 对, 循环添加 score -> member
返回给客户端 添加的元素的数量
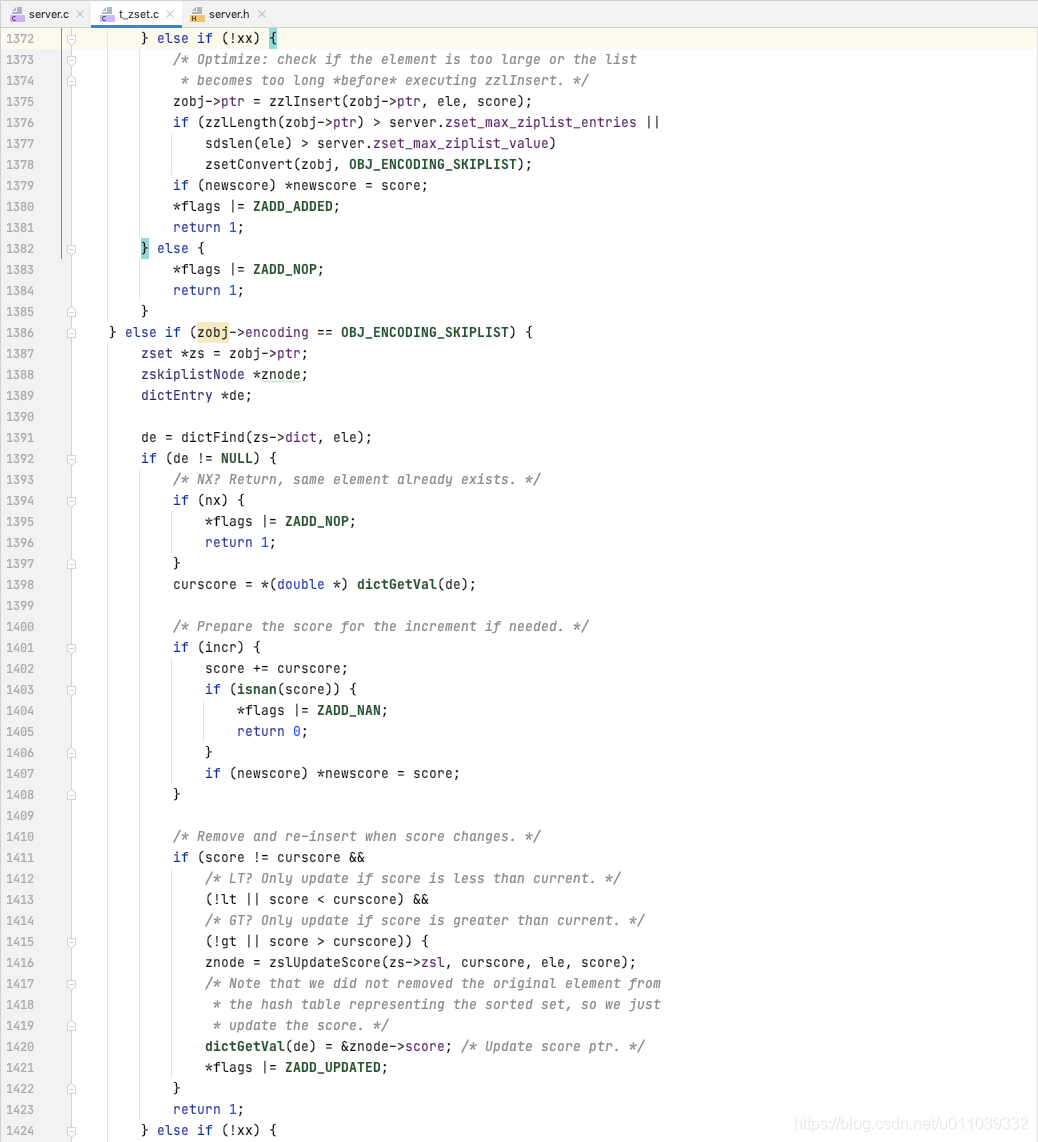
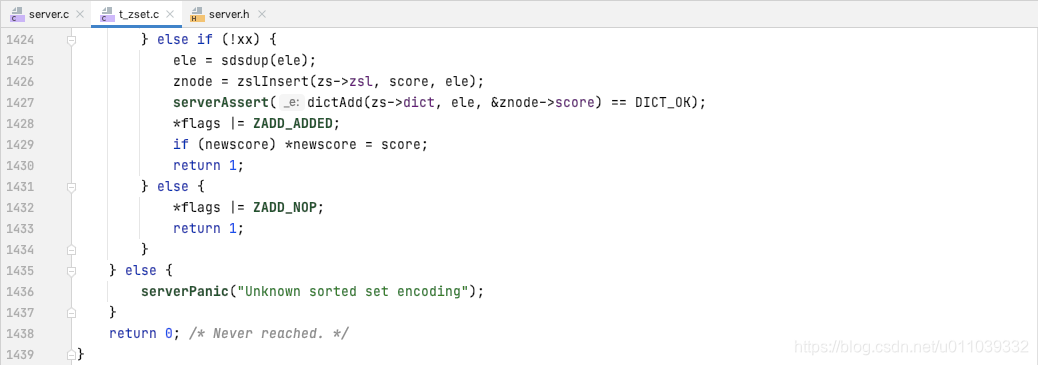
zset 中添加元素的具体的方式
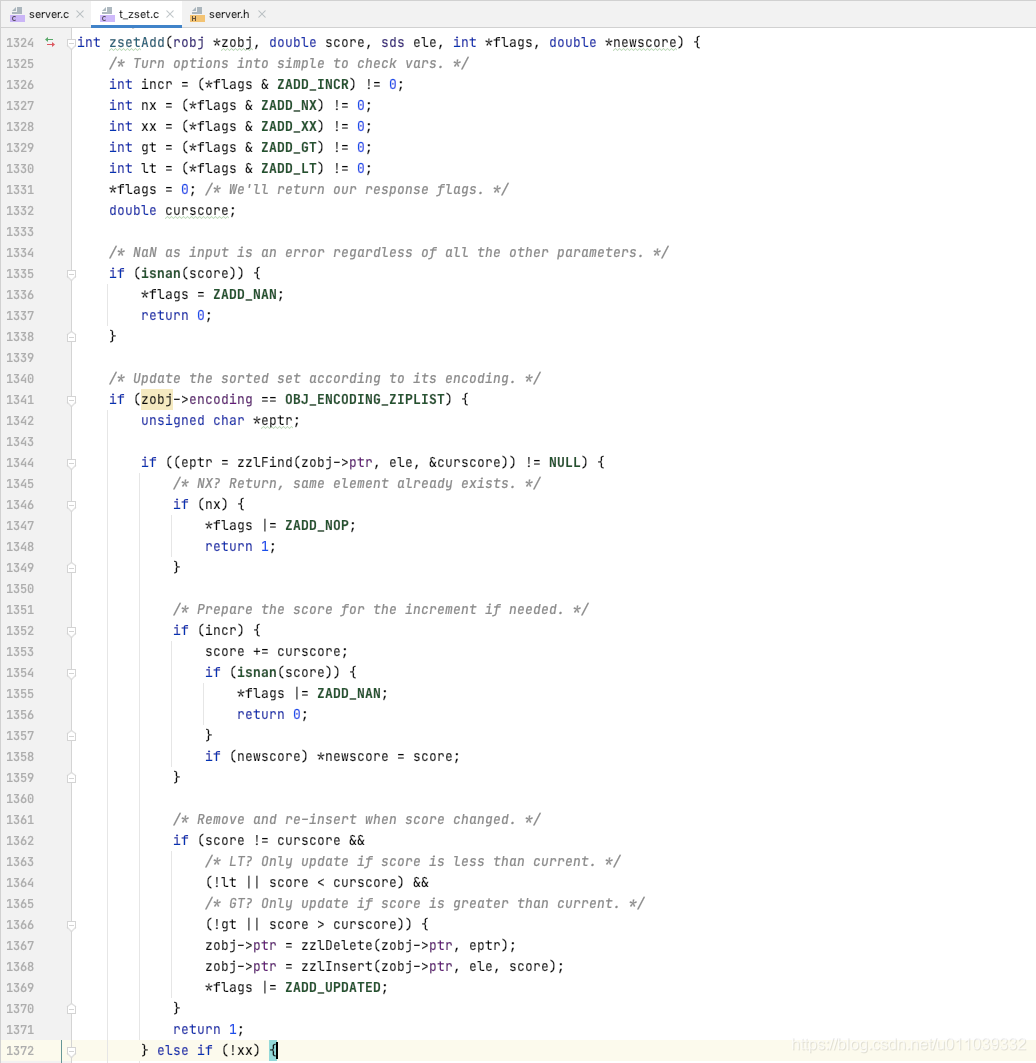
如果是 ziplist 的编码方式, 查询 ele 在 zset 中是否存在, 如果存在, 判断当前 score 和 newscore 是否满足 lt/gt 约束[确保 newscore 小于/大于 score], 先从 ziplist 中删除已有的 ele, score, 在新增 ele, newscore[新增元素按照score排序]
如果 zset 中不存在 ele, 则新增 ele, newscore 到 zset 里面 [新增元素按照score排序]
如果是 skiplist 的编码方式, 直接基于 skiplist 的 api 来进行操作
最终客户端这边展示的结果如下, zset 不存在, 符合 ziplist 的条件, 创建了基于一个 ziplist 的 zset, 最终添加了 三个元素
![]()
ZCARD key - 执行 zcard zset

这里可以看出的是 参数的数量要求等于 2 个
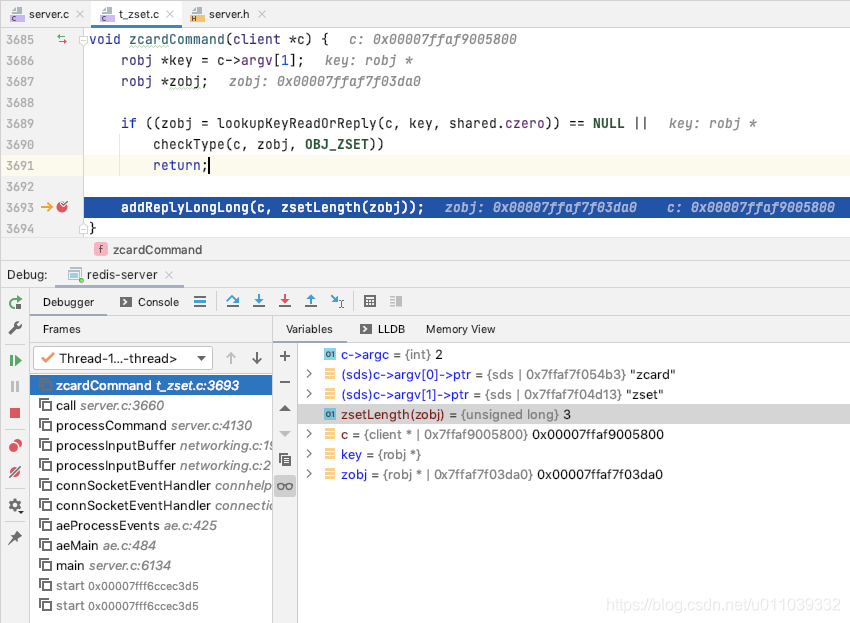
我们来看一下 zcardCommand
获取 key 对应的 entry, 确保类型为 zset
返回 value 中存储的元素的数量
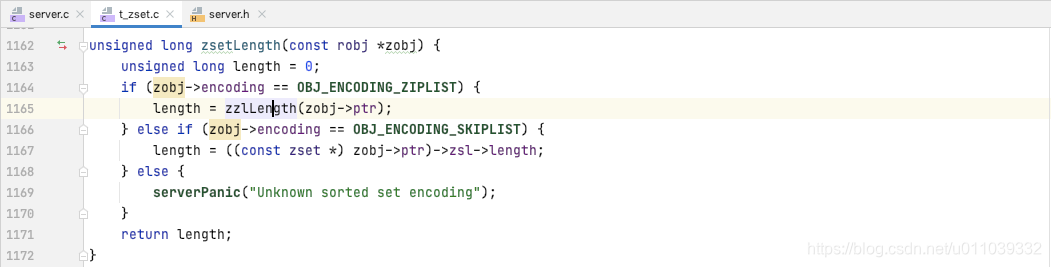
zsetLength 的具体实现如下, 获取的是 zset 里面的 score, member对 的数量
最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (70 -> match), (80 -> english)], 总共是三个元素
ZCOUNT key min max - 执行 zcount zset 60 70

这里可以看出的是 参数的数量要求等于 4 个
我们来看一下 zcountCommand
获取 key 对应的 entry, 确保类型为 zset
获取 min, max, 并确保类型正确
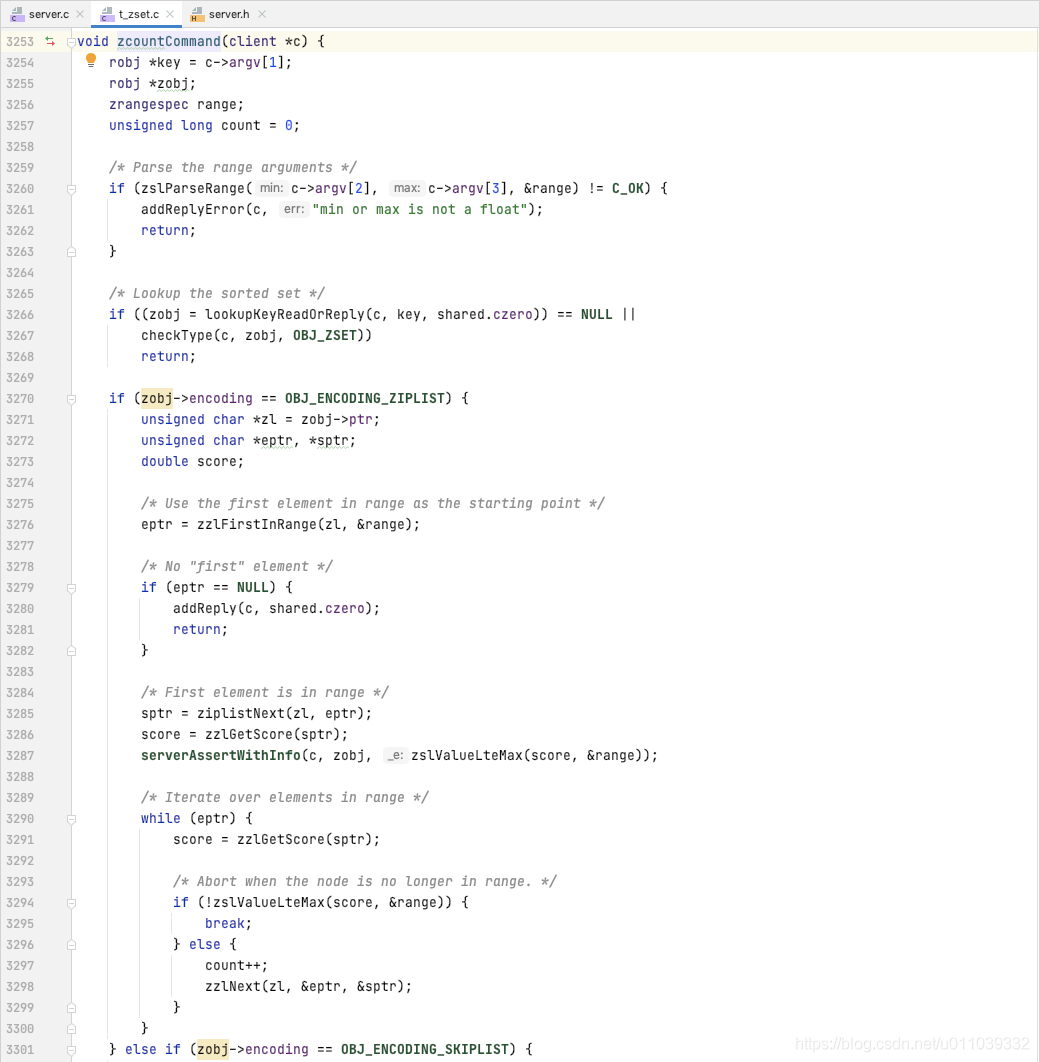
如果是以 ziplist 编码, 找到第一个在 range 的元素, 如果没有 返回 0, 否则迭代元素 直到不再 range, 返回元素的数量
如果是以 skiplist 编码, 找到第一个在 range 的元素, 如果没有 返回 0, 否则迭代元素 直到不再 range, 返回元素的数量
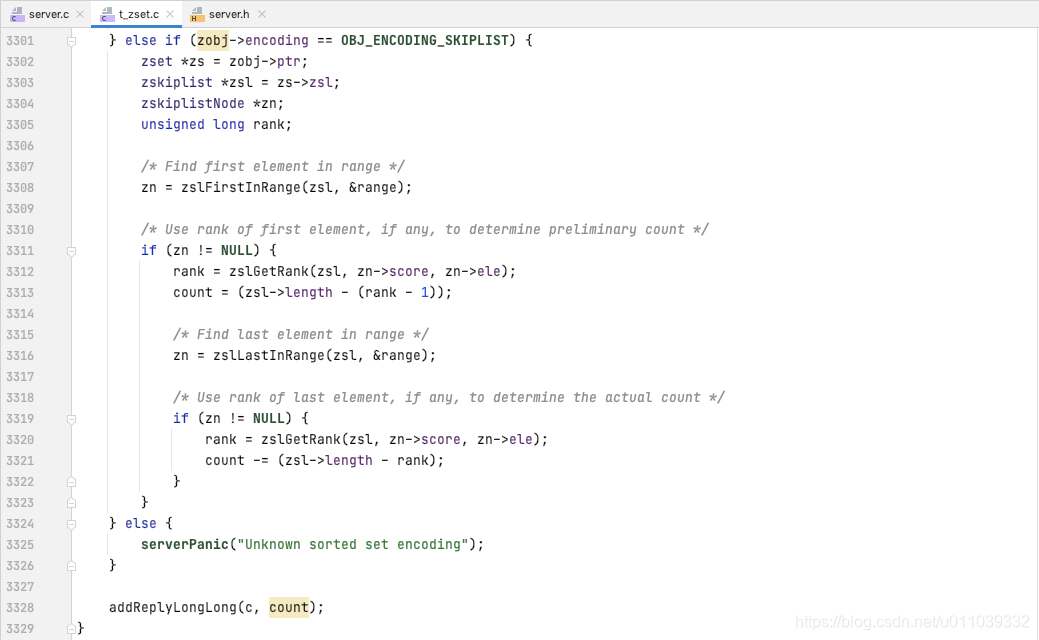
最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (70 -> match), (80 -> english)], score 在 [60, 70] 区间的元素总共有两个
![]()
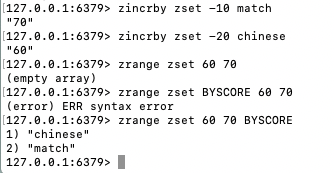
ZINCRBY key increment member - 执行 zincry zset 20 chinese

这里可以看出的是 参数的数量要求等于 4 个
zincrbyCommand 的实现是基于 zaddGenericCommand 来实现的, 请参见上面的 zadd

最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (70 -> match), (80 -> english)], 我们给 chinese 增加了 20, chinese 的 score 为 80, 这里返回的即为 newscore
![]()
ZINTERSTORE destination numkyes key [key]
暂时先放在这里
ZUNIONSTORE destinations numkeys key [key]
暂时先放在这里
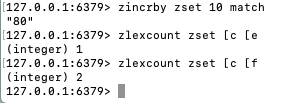
ZLEXCOUNT key min max - 执行 zlexcount zset [c [e

这里可以看出的是 参数的数量要求等于 4 个
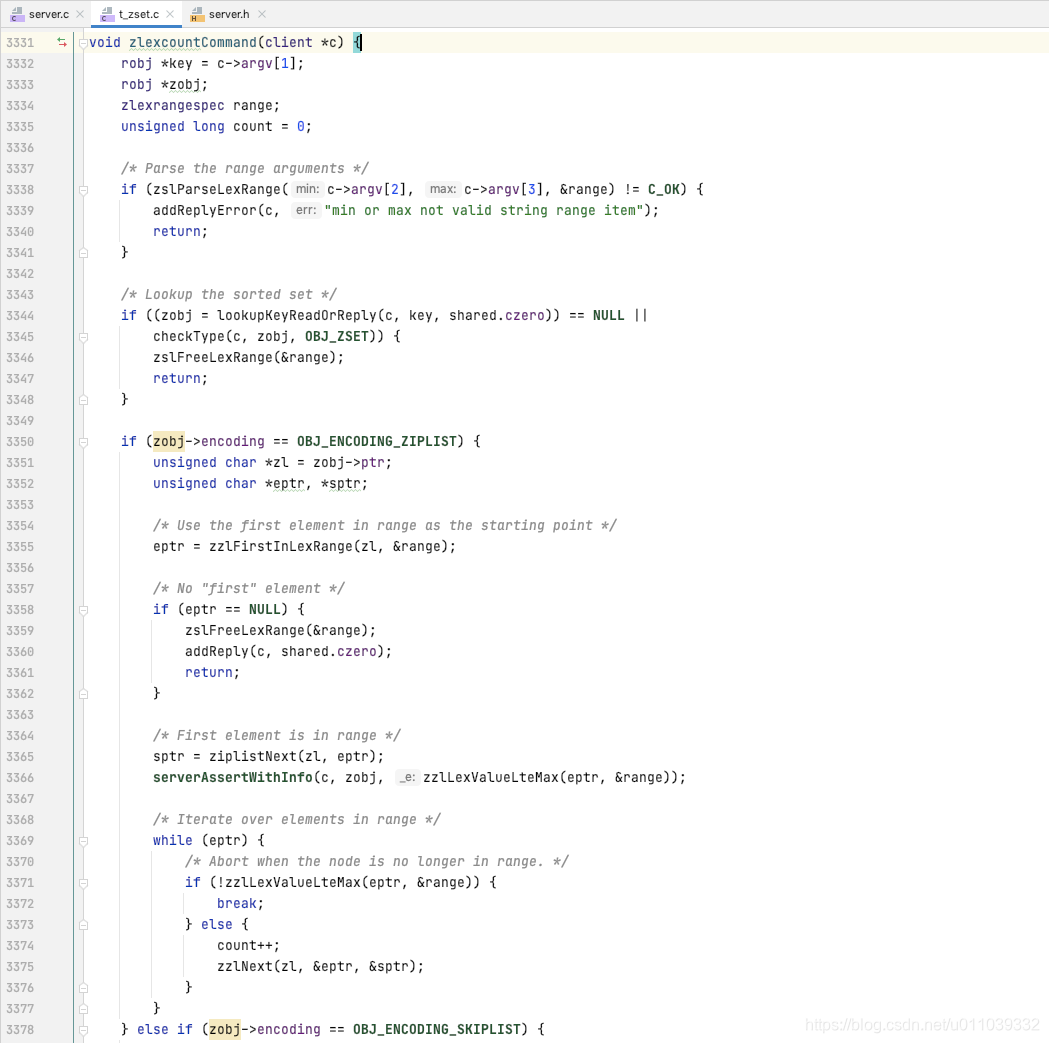
我们来看一下 zlexcountCommand
获取 key 对应的 entry, 确保类型为 zset
获取 min, max, 并确保类型正确
不管编码是 ziplist, skiplist 找到 min 所在的元素, 然后向后迭代 直到走出 (min, max) 区间[闭, 包取决于客户输入], 统计元素的数量
注意 : 所有的 member 正序的情况下才有意义[规范上面限定的是 所有的 score 都相同的场景]

zlexcount 文档上面的限定, 在所有的元素的 score 都相同的情况下使用, 查询语义上 在 min, max 区间的元素数量

最终客户端这边展示的结果如下, zset 中存在 [(80 -> chinese), (70 -> match), (80 -> english)]
我们给 match 增加了 10, match 的 score 为 80
此时 我们的几个元素 score 均相同, (socre, memeber) 默认是按照 member 字典序来进行的排序
此时统计 大于等于 'c', 小于等于 'e' 的元素只有 "chinese" 一个
此时统计 大于等于 'c', 小于等于 'f' 的元素只有 "chinese", "english" 两个
ZRANGE key start stop [WITHSCORES] - 执行 zrange zset 60 70

这里可以看出的是 参数的数量要求大于等于 4 个
zrange, zrangeByLex, zrangeByScore, zRevRange, zRevRangeByLex, zRevRangeByScore 都是差不多, 这里只介绍一个
我们来看一下 zrangeCommand
解析参数 offset, limit, byScore, byLex, rev, withScores 等等
根据 byRank/byScore/byOffset 分别将 min, max 解析到 (opt_start, opt_end), range, lexRange 里面
获取 key 对应的 entry, 确保类型为 zset
根据 byRank/byScore/byOffset 各自不同的实现来不同的处理
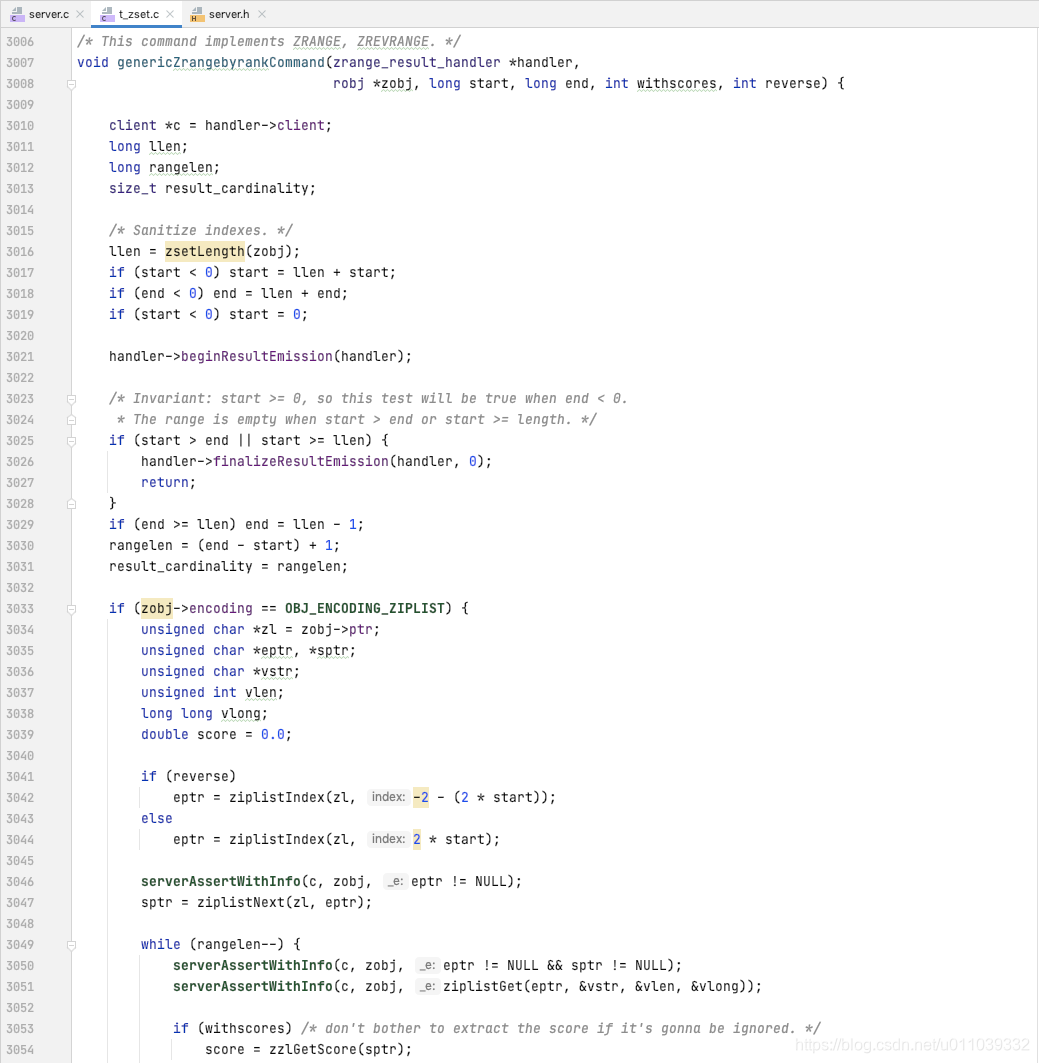
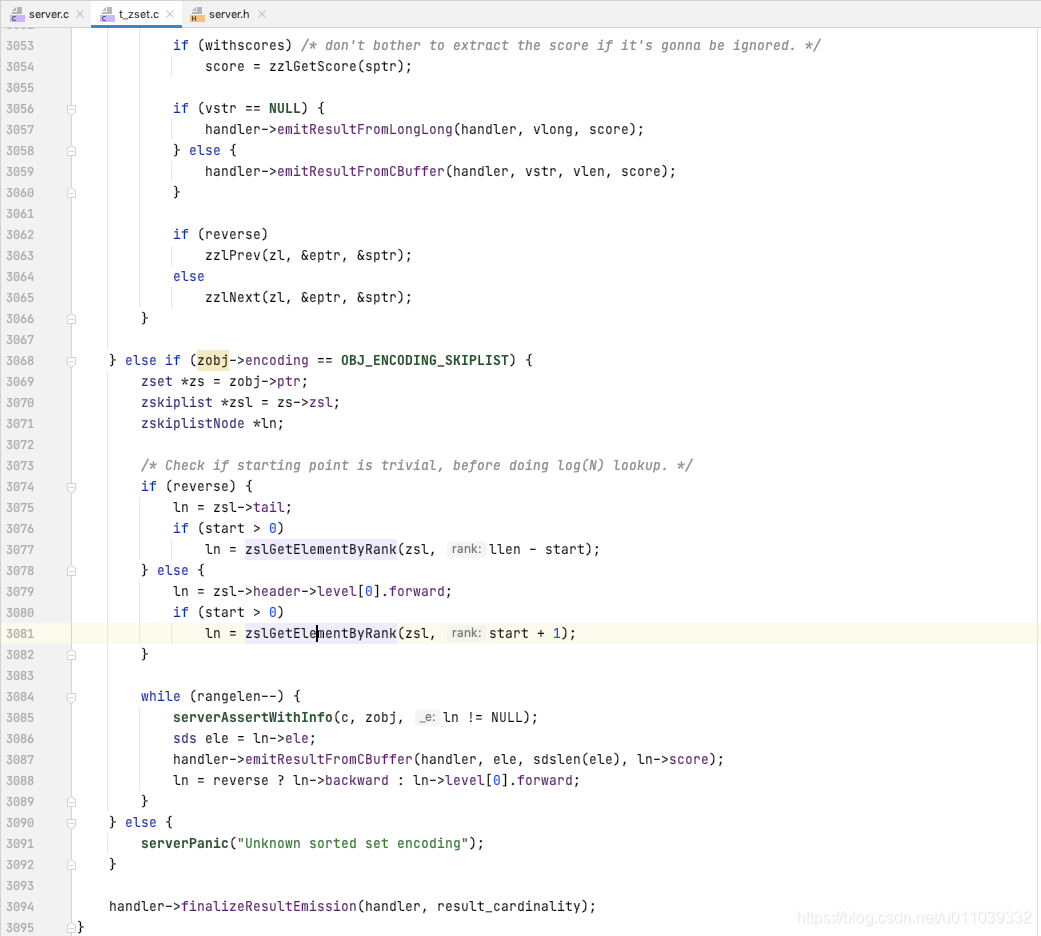
byRank 的处理方式如下
无论是 ziplist, 还是 skiplist, 其处理方式都是 现根据 start 获取第一个元素, 然后迭代 (end-start+1) 个元素
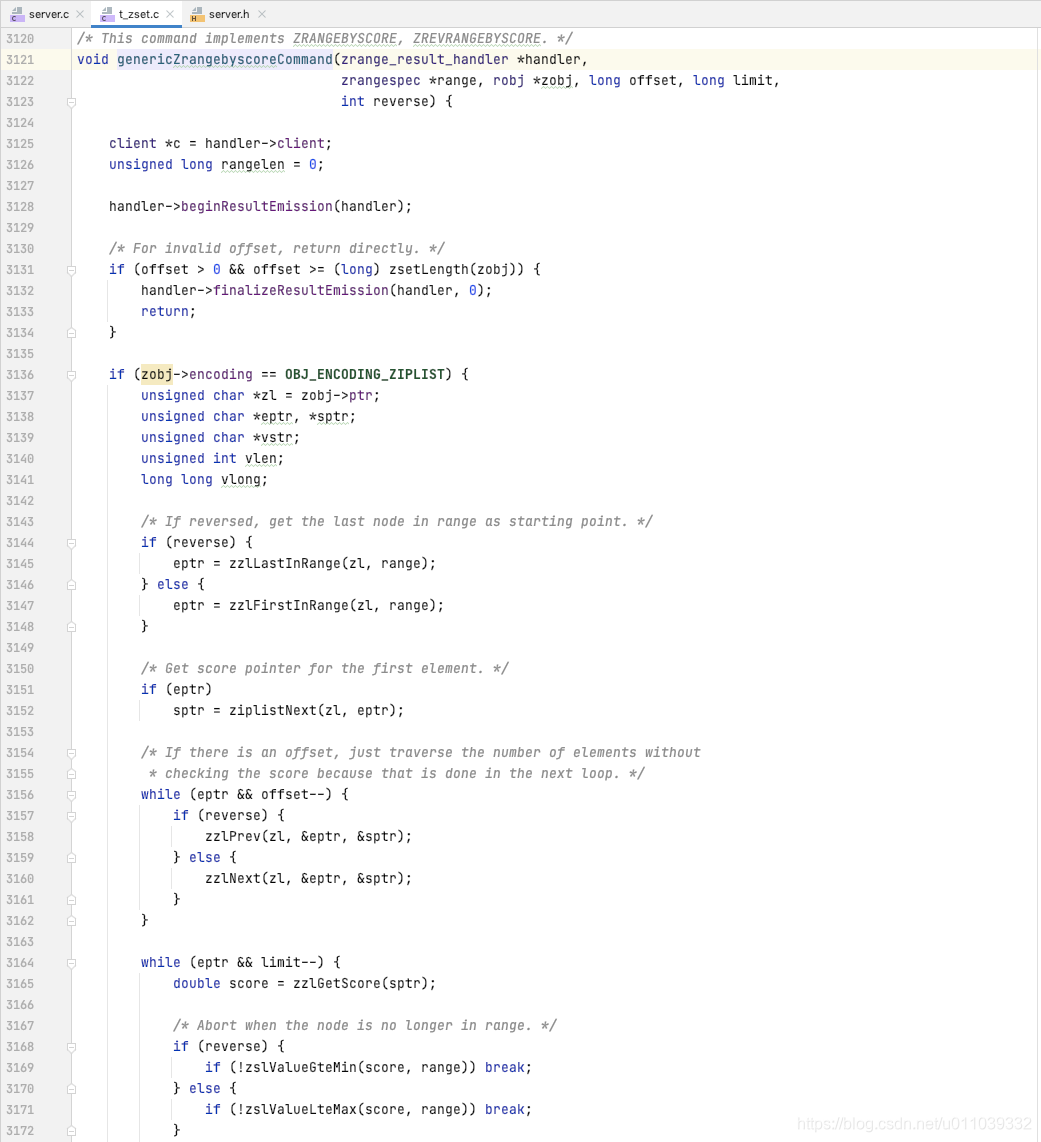
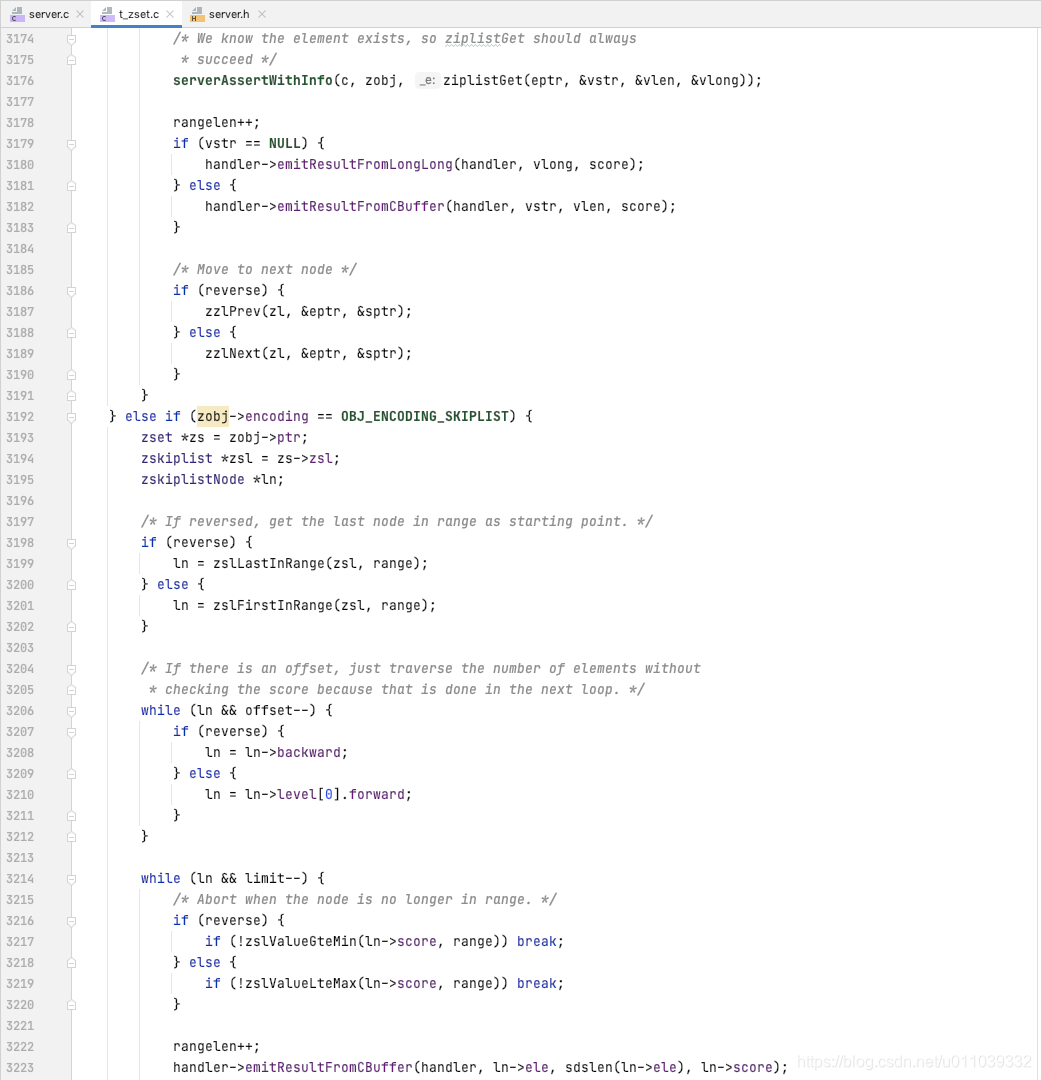
byScore 的处理方式如下
无论是 ziplist, 还是 skiplist, 其处理方式都是 找到区间的第一个元素, 然后向前/后迭代直到迭代出 range
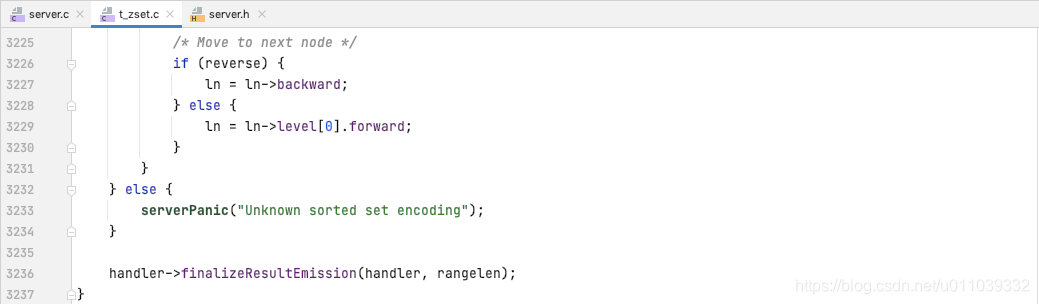
byLex 和 byScore 实现方式类似, 这里不再赘述
仅仅在 member 正序排列的时候有意义
最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (70 -> match), (80 -> english)]
然后 score 在 60, 70 区间的元素有 chinese, match 两个元素
ZRANK key member - 执行 zrank zset match

这里可以看出的是 参数的数量要求等于 3 个
zrank, zrevrank 都是差不多, 这里只介绍一个
我们来看一下 zrankCommand
获取给定的元素的 排名
无论是 ziplist 还是 quicklist, 来寻找 rank 都很简单
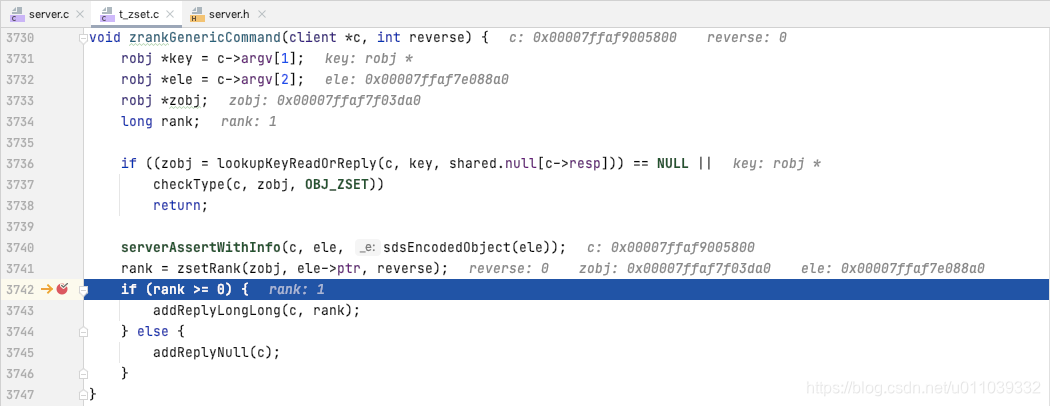
最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (70 -> match), (80 -> english)], 我们查询的 match 顺序上来说是 第二位
![]()
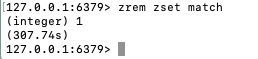
ZREM key member1 [member2] - 执行 zrem zset match

这里可以看出的是 参数的数量要求大于等于 3 个
我们来看一下 zremCommand
获取 key 对应的 entry, 确保类型为 zset
遍历 memberList 逐个删除 member, 如果最终集合元素删除光了, 移除 key 对应的 entry
如果删除了 member, 更新 dirty, 发送 更新通知
返回给客户端 删除的 member 的数量

最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (70 -> match), (80 -> english)], 我们删除了 match, 服务端返回的是删除元素的数量, 删除了一个元素
ZREMRANGEBYSCORE key min max - 执行 zremrangebyscore zset 0 30
这里可以看出的是 参数的数量要求等于 4 个
zremrangebyscore, zremrangebylex, zremrangebyrank 都是差不多, 这里只介绍一个
我们来看一下 zremRangeByScoreCommand
和上面 zcount 的实现差不多, 首先是确认类型, 解析参数, 根据 byRank/byScore/byOffset 分别将 min, max 解析到 (start, end), range, lexRange 里面
然后根据 range 来移除元素
如果删除了元素, 更新 dirty, 发送 更新通知
返回给客户端 删除的 member 的数量


最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (80 -> english)], 我们删除的区间是 [0, 30] 不会删除任何元素
![]()
ZSCORE key member - 执行 zscore zset chinese

这里可以看出的是 参数的数量要求等于 3 个
我们来看一下 zscoreCommand
获取 key 对应的 entry, 确保类型为 zset
根据元素 获取 score

根据元素获取 score
根据 ziplist, skiplist 不同的方式查询 member 对应的 entry
填充对应的 score 到接受的对象上

最终客户端这边展示的结果如下, zset 中存在 [(60 -> chinese), (80 -> english)], chinese 对应的 score 为 60
![]()
ZSCAN key cursor [MATCH pattern] [COUNT count] - 执行 zscan zset 0 COUNT 1

这里可以看出的是 参数的数量要求大于等于 3 个
zscan 这里同样是使用的 scanGenericCommand
这的迭代类似于 11 key 相关操作
不过对于这里编码为 ziplist 的情况 COUNT 这两个选项是没用的[这是一个很细的细节]
迭代的是 zset 里面的所有的元素
如果编码是 skiplist, zscan 是基于维护的一个额外的 dict 来进行 scan 的[这也是一个很细的细节]
完
这篇关于16 zset 相关操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



