本文主要是介绍ZIPKIN 调用链,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用背景
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
举几个例子:
1、在微服务系统中,一个来自用户的请求,请求先达到前端A(如前端界面),然后通过远程调用,达到系统的中间件B、C(如负载均衡、网关等),最后达到后端服务D、E,后端经过一系列的业务逻辑计算最后将数据返回给用户。对于这样一个请求,经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?这就需要用到服务链路追踪。
2、分析微服务系统在大压力下的可用性和性能。
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂。

随着服务的越来越多,对调用链的分析会越来越复杂。它们之间的调用关系也许如下:

服务间的依赖关系越来越复杂,怎么分析它们之间的调用关系及相互的影响?
zipkin可以使得所有RequestMapping匹配到的endpoints得到监控,以及强化了RestTemplate,对其加了一层拦截器,使得由它发起的http请求也同样被监控。
Zipkin简介
Zipkin分布式跟踪系统:它可以帮助收集时间数据,解决在microservice架构下的延迟问题;它管理这些数据的收集和查找;Zipkin的设计是基于谷歌的Google Dapper论文。
每个应用程序向Zipkin报告定时数据,Zipkin UI呈现了一个依赖图表来展示多少跟踪请求经过了每个应用程序;如果想解决延迟问题,可以过滤或者排序所有的跟踪请求,并且可以查看每个跟踪请求占总跟踪时间的百分比。
为何使用Zipkin
随着业务越来越复杂,系统也随之进行各种拆分,特别是随着微服务架构和容器技术的兴起,看似简单的一个应用,后台可能有几十个甚至几百个服务在支撑;一个前端的请求可能需要多次的服务调用最后才能完成;当请求变慢或者不可用时,我们无法得知是哪个后台服务引起的,这时就需要解决如何快速定位服务故障点,Zipkin分布式跟踪系统就能很好的解决这样的问题。
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
Zipkin原理
针对服务化应用全链路追踪的问题,Google发表了Dapper论文,介绍了他们如何进行服务追踪分析。其基本思路是在服务调用的请求和响应中加入ID,标明上下游请求的关系。利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
对应Dpper的开源实现是Zipkin,支持多种语言包括JavaScript,Python,Java, Scala, Ruby, C#, Go等。其中Java由多种不同的库来支持。
Spring Cloud Sleuth是对Zipkin的一个封装,对于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server发送采集信息等全部自动完成。
Zipkin基础架构
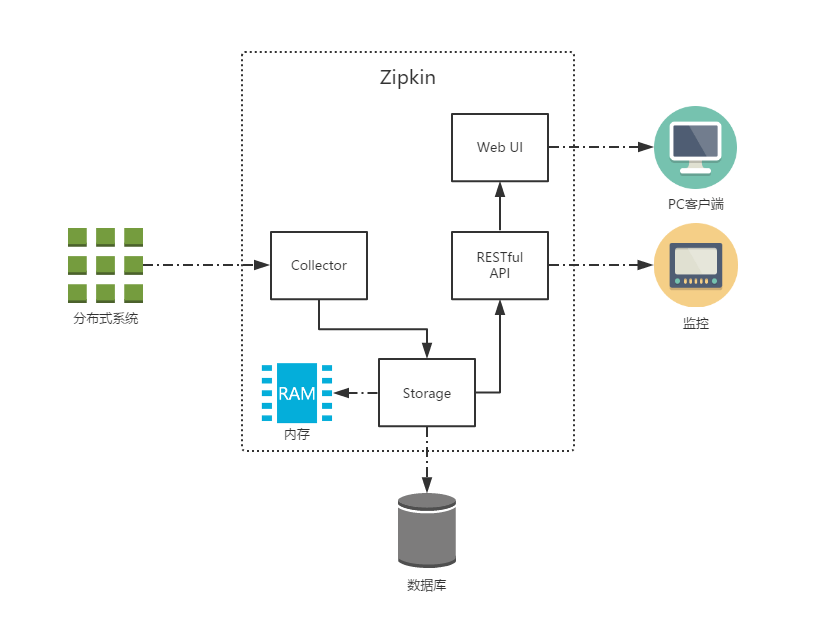
上图展示了Zipkin的基础架构,它主要有4个核心组件构成:
- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin内部处理的Span格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
- RESTful API:API组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
- Web UI:UI组件,基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分析跟踪信息。
Zipkin涉及的几个常用概念
Span:基本工作单元,一次链路调用创建一个span,通俗的理解span就是一次请求信息。
{"traceId": "bd7a977555f6b982","name": "get-traces","id": "ebf33e1a81dc6f71","parentId": "bd7a977555f6b982","timestamp": 1458702548478000,"duration": 354374,"annotations": [{"endpoint": {"serviceName": "zipkin-query","ipv4": "192.168.1.2","port": 9411},"timestamp": 1458702548786000,"value": "cs"}],"binaryAnnotations": [{"key": "lc","value": "JDBCSpanStore","endpoint": {"serviceName": "zipkin-query","ipv4": "192.168.1.2","port": 9411}}]
} |
traceId:标记一次请求的跟踪,相关的Spans都有相同的traceId;
id:span id;
name:span的名称,一般是接口方法的名称;
parentId:可选的id,当前Span的父Span id,通过parentId来保证Span之间的依赖关系,如果没有parentId,表示当前Span为根Span;
timestamp:Span创建时的时间戳,使用的单位是微秒(而不是毫秒),所有时间戳都有错误,包括主机之间的时钟偏差以及时间服务重新设置时钟的可能性,出于这个原因,Span应尽可能记录其duration;
duration:持续时间使用的单位是微秒(而不是毫秒);
annotations:注释用于及时记录事件;有一组核心注释用于定义RPC请求的开始和结束;
Trace:Trace就是树结构的Span集合,表示一条调用链路,Zipkin使用Trace结构表示对一次请求的跟踪,一次请求可能由后台的若干服务负责处理,每个服务的处理是一个Span,Span之间有依赖关系。
Annotation: 注解,用来记录请求特定事件相关信息(例如时间),通常包含四个注解信息。
cs - Client Start,表示客户端发起请求
sr - Server Receive,表示服务端收到请求
ss - Server Send,表示服务端完成处理,并将结果发送给客户端
cr - Client Received,表示客户端获取到服务端返回信息
Zipkin调用链路
一条链路中,一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来

整个链路的依赖关系如下:

一个复杂系统中的调用链路过程图形化如下:

利用Annotation信息来计算调用的延迟

sr-cs 得到请求发出延迟
ss-sr 得到服务端处理延迟
cr-cs 得到真个链路完成延迟
Zipkin Server搭建(MQ异步方式)
引入依赖
<dependency><groupId>io.zipkin.java</groupId><artifactId>zipkin-autoconfigure-ui</artifactId> </dependency> <dependency><groupId>io.zipkin.java</groupId><artifactId>zipkin-server</artifactId> </dependency> <!-- 使用消息的方式收集数据(使用rabbitmq) --> <dependency><groupId>io.zipkin.java</groupId><artifactId>zipkin-autoconfigure-collector-rabbitmq</artifactId><version>2.3.1</version> </dependency> <dependency><groupId>io.zipkin.java</groupId><artifactId>zipkin-autoconfigure-storage-mysql</artifactId> </dependency> <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> </dependency> |
在启动类加入注解@EnableZipkinServer
@EnableDiscoveryClient
@SpringBootApplication
@EnableZipkinServer
public class CollectionZipkinDbApplication {public static void main(String[] args) {SpringApplication.run(CollectionZipkinDbApplication.class, args);}
} |
配置消息中间件,存储方式等信息
zipkin:collector:rabbitmq:addresses: 127.0.0.1:5672password: guestusername: guestqueue: zipkinstorage:type: mysql |
配置mysql数据库
# datasoure默认使用JDBC spring:datasource:driver-class-name: com.mysql.jdbc.Driverusername: rootpassword: 123456url: jdbc:mysql://127.0.0.1:3306/demo?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false |
创建mysql数据库存储表,sql脚本如下
-- ---------------------------- -- Table structure for zipkin_annotations -- ---------------------------- DROP TABLE IF EXISTS `zipkin_annotations`; CREATE TABLE `zipkin_annotations` (`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',`span_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.id',`a_key` varchar(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',`a_value` blob COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',`a_type` int(11) NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',`a_timestamp` bigint(20) DEFAULT NULL COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',`endpoint_ipv4` int(11) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_ipv6` binary(16) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',`endpoint_port` smallint(6) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_service_name` varchar(255) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate',UNIQUE KEY `trace_id_high_4` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate',KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans',KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds',KEY `endpoint_service_name` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames',KEY `a_type` (`a_type`) COMMENT 'for getTraces',KEY `a_key` (`a_key`) COMMENT 'for getTraces',KEY `trace_id` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job',KEY `trace_id_high_5` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans',KEY `trace_id_high_6` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds',KEY `endpoint_service_name_2` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames',KEY `a_type_2` (`a_type`) COMMENT 'for getTraces',KEY `a_key_2` (`a_key`) COMMENT 'for getTraces',KEY `trace_id_2` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;-- ---------------------------- -- Table structure for zipkin_dependencies -- ---------------------------- DROP TABLE IF EXISTS `zipkin_dependencies`; CREATE TABLE `zipkin_dependencies` (`day` date NOT NULL,`parent` varchar(255) NOT NULL,`child` varchar(255) NOT NULL,`call_count` bigint(20) DEFAULT NULL,UNIQUE KEY `day` (`day`,`parent`,`child`),UNIQUE KEY `day_2` (`day`,`parent`,`child`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;-- ---------------------------- -- Table structure for zipkin_spans -- ---------------------------- DROP TABLE IF EXISTS `zipkin_spans`; CREATE TABLE `zipkin_spans` (`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` bigint(20) NOT NULL,`id` bigint(20) NOT NULL,`name` varchar(255) NOT NULL,`parent_id` bigint(20) DEFAULT NULL,`debug` bit(1) DEFAULT NULL,`start_ts` bigint(20) DEFAULT NULL COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',`duration` bigint(20) DEFAULT NULL COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`id`) COMMENT 'ignore insert on duplicate',UNIQUE KEY `trace_id_high_4` (`trace_id_high`,`trace_id`,`id`) COMMENT 'ignore insert on duplicate',KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`id`) COMMENT 'for joining with zipkin_annotations',KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds',KEY `name` (`name`) COMMENT 'for getTraces and getSpanNames',KEY `start_ts` (`start_ts`) COMMENT 'for getTraces ordering and range',KEY `trace_id_high_5` (`trace_id_high`,`trace_id`,`id`) COMMENT 'for joining with zipkin_annotations',KEY `trace_id_high_6` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds',KEY `name_2` (`name`) COMMENT 'for getTraces and getSpanNames',KEY `start_ts_2` (`start_ts`) COMMENT 'for getTraces ordering and range' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; SET FOREIGN_KEY_CHECKS=1; |
使用Zipkin
引入依赖
<!--zipkin--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> |
配置MQ和zipkin
# sleuth配置 spring:rabbitmq:host: 127.0.0.1port: 5672username: guestpassword: guestzipkin:rabbitmq:queue: zipkinsleuth:sampler:percentage: 0.2 |
之后方可自动发送追踪信息到MQ。
这篇关于ZIPKIN 调用链的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





