本文主要是介绍C++使用ODBC链接MYSQL出现乱码问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
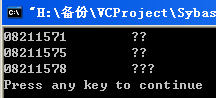
首先来看一看乱码问题:

首先需要保证 数据库字符集的问题:
修改mysql配置文件: 找到my.ini配置文件 在mysqld加入 character-set-server=utf8 重启mysql;
其次保证ODBC链接 字符集的问题
我这个问题出现的原因在ODBC数据源的设置上,首先在控制面板中找到管理工具,点击打开数据源(ODBC),找到为该操作配置的数据源,点击打开,然后对其进行配置:
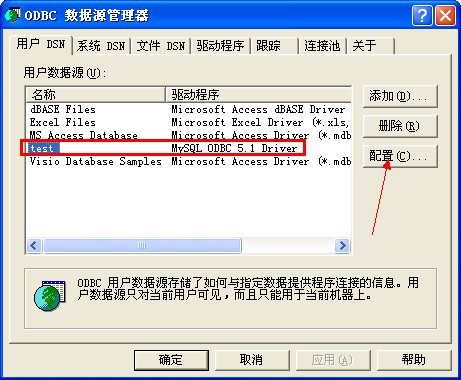
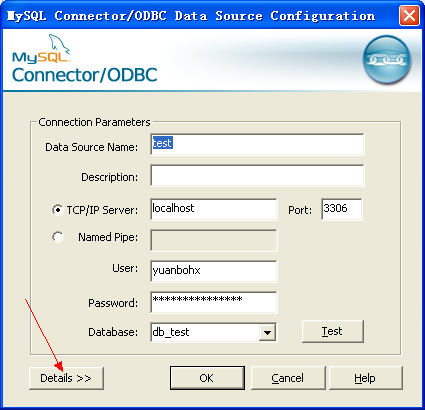
进入配置界面后点击左下方的Details按钮:
在connect菜单下的Character Set中选择gb2312(之所以选择gb2312是因为在用phpmyadmin对MySQL进行管理时,创建的表及其中表项的字符集均为:gb2312_chinese_si),点击OK。
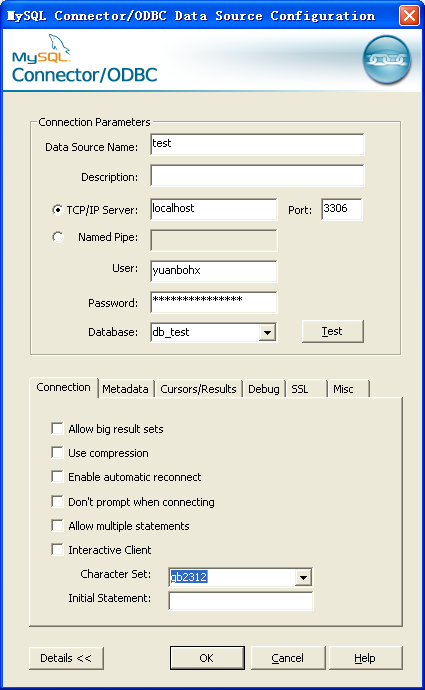
上图所示设置成GB2321或者GBK都可以,但是设置成UTF-8却不行,希望网友解答
再次运行VC程序,可以看到乱码的问题解决了:
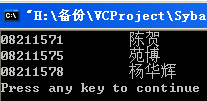
如果问题仍没有解决,可以尝试重启MySQL服务。如果仍不起作用,那就有可能是你遇到的问题和我不同,你可以在网上找寻其他的解决方案,祝你好运!
最后实在不行保证驱动的版本问题
困扰很长时间的mysql 中文乱码,一连接到其他数据就出现乱码,找到最终原因是因为mysql4.1以上都有字符集的功能,所以导致链接过程中存在乱码现象,查找ODBC发现,通过他可以缓解字符集问题。
到:http://www.mysql.com/downloads/connector/odbc/
下载最新的ODBC 安装程序,(这么多版本啊)。
我下载windows版本即可,下载后安装,到控制面板中找到管理工具,找到ODBC数据源,新建。
按照数据库连接新建即可,新建后记得点击:Details》
会出现具体连接编码设置(Character Set),这个是关键,做数据乱码处理的就是他。
然后单击OK即可。
这篇关于C++使用ODBC链接MYSQL出现乱码问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







