本文主要是介绍一点点 cv 经验 1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一点点 cv 经验 1
- cv 方向
- Pytorch
- 数据集划分
- 误差=偏差+方差+噪声
- 输入尺寸
- 方法一:让数据适应模型
- 方法二:修改模型适应数据
- 方法三:划分Patch,分别处理
cv 方向
cv 各个方向:https://github.com/amusi/Computer-Vision-Tasks-Survey
CV的研究大致分为以下几个方向:
二维:
- 图像:图像分类、图像分割、目标检测、人脸识别、文字识别、姿态估计、异常检测、图像检索、图像增强、风格迁移、图像生成等等
- 视频:视频分类、目标跟踪、重识别、行为识别、视频目标分割、视频内容分析
三维:
- 三维目标检测、位姿估计
- 点云生成
- 深度估计
- 三维重建:物、场景、人
- 视觉重定位
- 视觉SLAM
Pytorch
数据集划分
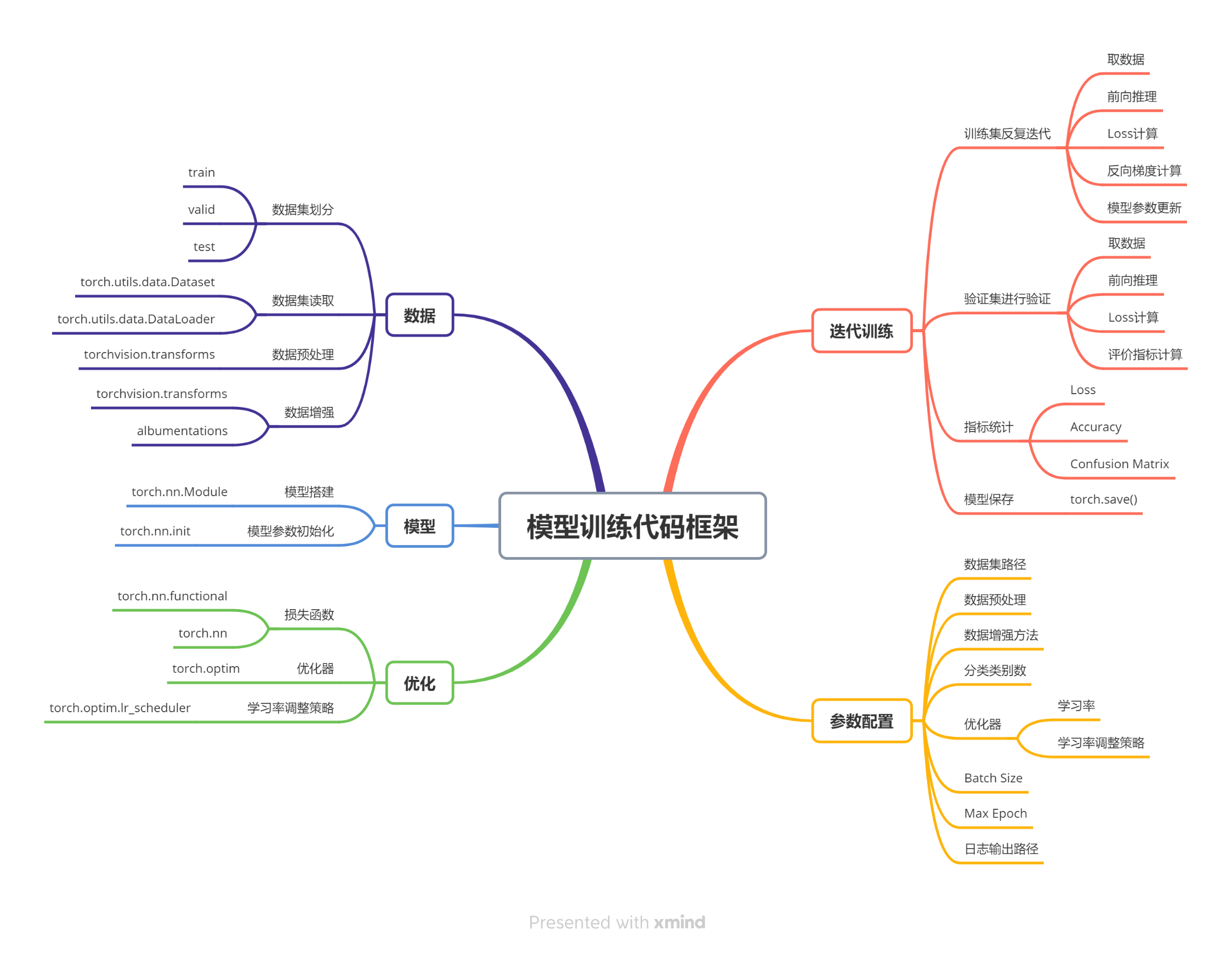
import os # 导入 os 模块,用于处理文件和目录路径
import random # 导入 random 模块,用于随机化数据
import shutil # 导入 shutil 模块,用于文件操作,例如复制文件# 定义函数:将图像列表复制到指定子目录下
def copy_file(img_list, target_dir, setname="train"): # 没有提供setname参数选择,那么函数将使用默认值“train”img_dir = os.path.join(target_dir, setname) # 目标子目录路径os.makedirs(img_dir, exist_ok=True) # 创建目标子目录for p in img_list: # 遍历图像列表shutil.copy(p, img_dir) # 复制图像到目标子目录print(f"{setname} dataset: copy {len(img_list)} images to {img_dir}") # 打印复制信息# 主程序入口
if __name__ == "__main__":# 指定花朵图像所在的目录img_dir = r"E:\data\flowers_data\jpg"# 获取指定目录下所有图像文件的路径列表img_list = [os.path.join(img_dir, name) for name in os.listdir(img_dir)]random.seed(10086) # 设置随机种子,以确保每次运行时随机结果的一致性random.shuffle(img_list) # 随机打乱图像路径列表# 定义训练集和验证集所占比例train_ratio = 0.8valid_ratio = 0.2# 计算总图像数量和训练集图像数量num_img = len(img_list)num_train = int(num_img * train_ratio)num_valid = num_img - num_train# 获取训练集和验证集图像路径列表train_list = img_list[: num_train]valid_list = img_list[num_train: ]# 获取花朵图像目录的父目录作为目标目录target_dir = os.path.abspath(os.path.dirname(img_dir))# 将训练集图像复制到新的 train 子目录下copy_file(train_list, target_dir, "train")# 将验证集图像复制到新的 valid 子目录下copy_file(valid_list, target_dir, "valid")
列表生成器作用:
这两行代码的作用是获取指定目录下所有图像文件的路径列表。
假设你有一个目录结构如下:
E:
└── data└── flowers_data└── jpg├── flower1.jpg├── flower2.jpg├── flower3.jpg└── ...
其中,E:\data\flowers_data\jpg 是存放花朵图像的目录,里面有很多花朵的图片文件,比如flower1.jpg、flower2.jpg等。
那么这两行代码做的事情就是:
img_dir = r"E:\data\flowers_data\jpg":将花朵图像所在的目录路径存储在变量img_dir中。img_list = [os.path.join(img_dir, name) for name in os.listdir(img_dir)]:os.listdir(img_dir):获取目录img_dir下的所有文件名列表,比如['flower1.jpg', 'flower2.jpg', 'flower3.jpg', ...]。os.path.join(img_dir, name):将目录路径img_dir与每个文件名name拼接起来,形成完整的文件路径,比如'E:\data\flowers_data\jpg\flower1.jpg'。- 最终,
img_list中存储的就是所有花朵图像的完整文件路径列表,例如['E:\data\flowers_data\jpg\flower1.jpg', 'E:\data\flowers_data\jpg\flower2.jpg', ...]。
这样,img_list就包含了目标目录下所有花朵图像的文件路径。
怎么调用:
这个代码的作用是将一个目录中的图像分成训练集和验证集,并将它们复制到新的目录中的子目录中。
你可以按照以下步骤来使用这个代码:
-
准备数据:
- 确保你有一组花朵图像,这些图像应该存储在一个目录中(在这个例子中是
E:\data\flowers_data\jpg)。
- 确保你有一组花朵图像,这些图像应该存储在一个目录中(在这个例子中是
-
保存代码:
- 将代码保存为一个Python文件,比如
split_data.py。
- 将代码保存为一个Python文件,比如
-
运行代码:
- 在命令行或终端中,进入到存放代码的目录。
- 执行代码:
python split_data.py。
-
查看结果:
- 运行完代码后,会在原始图像目录的父目录中生成两个子目录:
train和valid。 train目录中包含80%的训练集图像,valid目录中包含20%的验证集图像。
- 运行完代码后,会在原始图像目录的父目录中生成两个子目录:
确保在运行代码之前,你已经安装了Python,并且已经安装了用到的shutil、os和random模块。
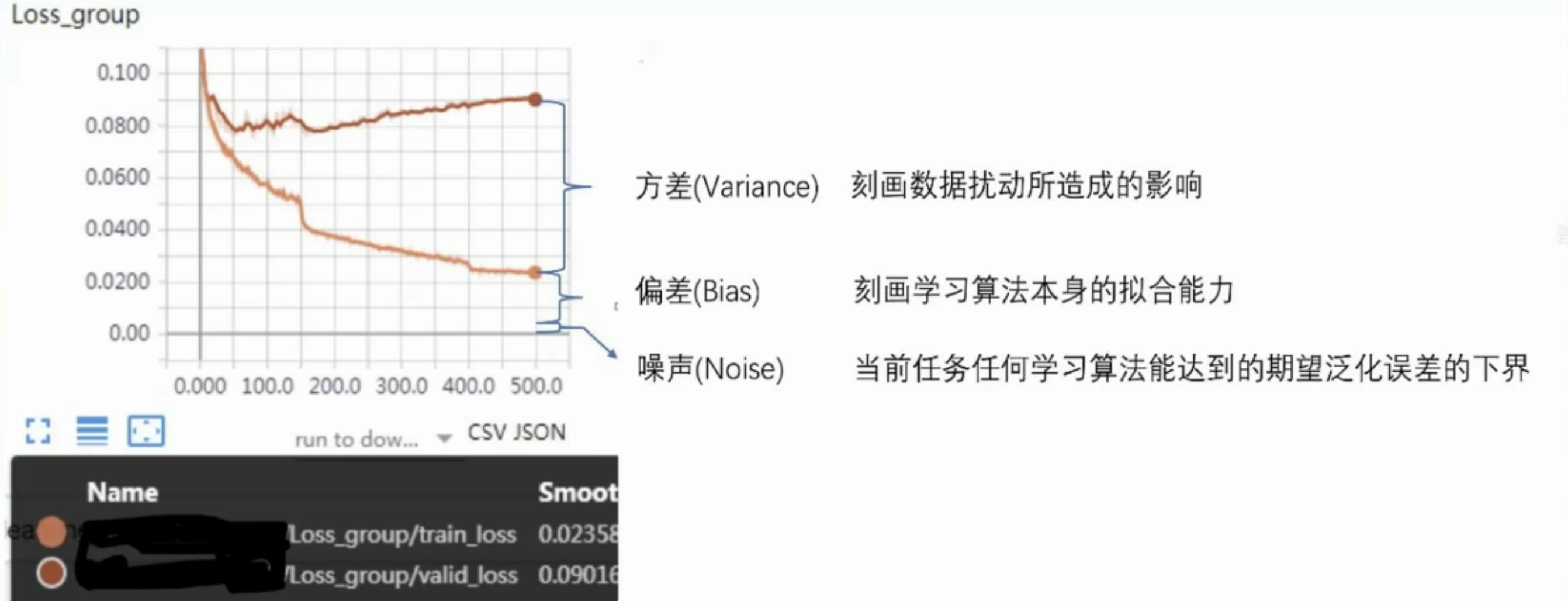
误差=偏差+方差+噪声
假设我们正在使用YOLO算法来检测图像中的交通标志。我们有一个包含交通标志及其位置标注的数据集。我们将误差分解为偏差、方差和噪声,来解释模型的表现。
-
偏差(Bias):
假设我们选择了一个简单的YOLO模型,它只有少量的卷积层和池化层,无法很好地捕捉交通标志的复杂形状和背景。由于模型过于简单,它可能会错过一些交通标志,导致在训练集和测试集上都无法很好地检测到交通标志。这种情况下,偏差会很高,表明模型的拟合能力不足。 -
方差(Variance):
假设我们选择了一个非常复杂的YOLO模型,它有很多卷积层和池化层,以及大量的参数。这个模型在训练集上表现非常好,可以准确地检测到交通标志。然而,由于模型过于复杂,它对训练集中的数据点非常敏感。如果我们稍微改变训练集中的一些图像,可能会导致模型产生很大的变化。因此,模型在训练集和测试集上的性能差异很大,方差会很高。 -
噪声(Noise):
假设我们的数据集中存在一些图像质量较差、光照不足或者遮挡的情况,这些因素会影响模型的检测性能。即使我们使用最好的模型,也无法完全消除这些影响。噪声表示模型在当前任务上任何学习算法所能达到的期望泛化误差的下界。
偏差表示模型的拟合能力,方差表示模型对数据的敏感性,噪声表示数据的不确定性。
通过误差分解,我们可以更好地理解模型在训练和测试过程中的表现,从而选择合适的模型和优化策略。
输入尺寸
在处理机器学习和特别是计算机视觉问题时,输入尺寸的管理是一个重要的方面,因为模型通常要求所有输入数据具有一致的尺寸。
方法一:让数据适应模型
这种方法涉及调整数据以匹配模型的预设输入要求。
例如,如果你使用的模型设计为接收 256x256 像素的图像,你需要将所有输入图像调整为这个尺寸。
这通常通过以下技术实现:
- 缩放:改变图像的尺寸以匹配模型的输入尺寸。
- 裁剪:从原始图像中裁剪出符合模型输入尺寸的部分。
- 填充:如果原始图像比需要的尺寸小,可以在图像周围添加像素(通常是黑色或白色)以达到所需的尺寸。
这种方法的优点是实现简单,可以直接使用预训练模型而无需修改模型架构。
缺点是可能会引入几何变形或丢失信息,特别是当原始图像的宽高比与模型所需的宽高比不一致时。
在实践中,有一些模型会固定输入尺寸,而一些模型则可以接受变化的输入尺寸。
模型固定输入尺寸的情况:
-
传统的卷积神经网络(例如VGG、ResNet):
- 这些经典的卷积神经网络通常在设计时会固定输入尺寸,例如224x224像素。这样做的好处是可以更轻松地设计网络结构,并且在训练和推理过程中的计算量是确定的。
-
一些定制的网络架构:
- 有些特定任务或特定领域的网络架构可能会要求固定的输入尺寸,这是因为网络的设计与输入尺寸有关。
模型灵活接受不同输入尺寸的情况:
-
YOLO(You Only Look Once)目标检测算法:
- YOLO算法是一种可以处理任意尺寸的图像的目标检测算法。它将输入图像分成网格,并在每个网格上预测目标的边界框和类别。因此,YOLO不需要固定的输入尺寸,可以处理各种尺寸的图像。
-
FCN(Fully Convolutional Network)语义分割网络:
- FCN是一种用于图像分割的网络,可以接受任意尺寸的输入图像,并输出相同尺寸的语义分割结果。这种网络通过使用卷积和反卷积操作来实现对变尺寸输入图像的处理。
-
深度变换器网络(Spatial Transformer Network,STN):
- STN是一种可以对输入图像进行空间变换的网络,可以处理不同尺寸和角度的输入图像,并生成相应的变换后图像。
总的来说,有些模型需要固定的输入尺寸,而有些模型则可以接受不同尺寸的输入。
对于需要固定输入尺寸的模型,需要在训练和推理过程中将所有输入图像调整为相同的尺寸;而对于可以接受不同尺寸的模型,可以灵活处理不同大小的输入图像。
方法二:修改模型适应数据
这种方法涉及修改模型的架构以适应不同尺寸的输入数据。
这通常意味着使用更灵活的网络结构,例如全卷积网络,它们能够处理任意尺寸的输入。例如:
- 调整网络层:修改模型的第一层或其他层,使其能够接受不同尺寸的输入。
- 使用自适应池化层:使用自适应池化(如自适应平均池化或自适应最大池化)来保证网络的输出尺寸独立于输入尺寸。
修改模型使之适应不同的输入尺寸可以使模型更加灵活,不再受限于特定的输入尺寸。然而,这可能需要较深的技术知识来调整网络结构,且有时候可能导致训练效率降低。
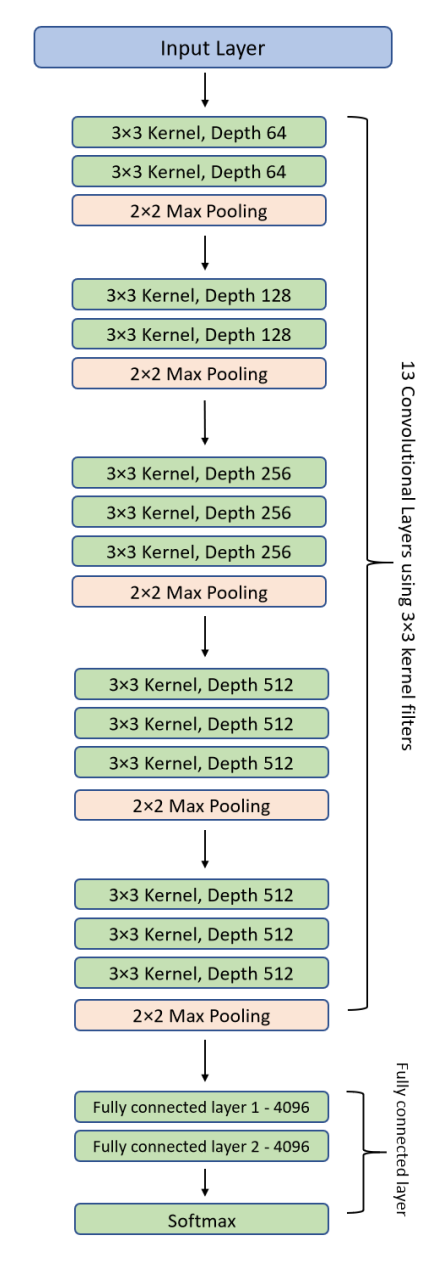
在提供的图像中,模型架构包括多个卷积层、池化层和全连接层。
这是一个经典的卷积神经网络,通常用于图像识别任务。
五种方法,我们可以对此模型进行修改,以适应不同的输入尺寸需求。这些修改分别影响模型的接受输入尺寸和特征提取的能力:
- 删除一个Pooling层,使224x224变为可接收112x112
- 删除一个Pooling层(比如2x2 Max Pooling),减少了图像尺寸下降的速度。这样模型可以在更小的输入尺寸(如112x112)上运行而不会太快减小特征图的维度,保留更多的特征信息。
- 增加一个Pooling层,使224x224变为可接收448x448
- 增加一个Pooling层可以使网络在处理更大尺寸的输入图像(如448x448)时,快速减小特征图的尺寸,以避免在网络深层中处理过大的数据量。
- 卷积步长stride=2 的,改为stride=1,使输入可变为112x112
- 当卷积层的步长从2改为1时,特征图的尺寸下降速度减慢。这样,较小的输入尺寸(如112x112)也能够在网络中保持足够的特征图尺寸,避免在深层中特征图尺寸过小。
- 卷积步长stride=1 的,改为stride=2,使输入可变为448x448
- 相反地,增加卷积层的步长可以加快特征图的尺寸下降。这样,在处理较大尺寸的输入(如448x448)时,可以避免特征图在网络深层中过大,有助于减少计算量和内存消耗。
- 使用全局平均池化(GAP)
- 引入全局平均池化层可以替换传统的全连接层,它会计算每个特征图的平均值形成一个固定大小的特征向量。这种方法的优势在于它使得网络可以处理任意尺寸的输入图像,因为无论输入图像的尺寸如何变化,全局平均池化输出的维度总是固定的。
这些修改使模型更加灵活,能够适应不同尺寸的输入,同时也影响模型的计算效率和特征提取能力。通过这样的调整,可以根据实际应用需求定制模型,优化其性能和资源使用效率。
方法三:划分Patch,分别处理
在某些应用中,尤其是图像尺寸非常大(如遥感影像或数字病理图像)时,可以将大图像划分为较小的片段(Patch),然后分别处理这些片段。例如:
- 图像分割:将大尺寸图像分割为多个较小的图像块,每个块符合模型的输入尺寸。
- 独立处理:对每个图像块独立应用模型,然后可能需要合并这些模型的输出以得到最终结果。
这种方法使得处理大尺寸图像变得可行,特别是当图像太大而无法直接输入到网络中时。这种方法的挑战在于如何有效地合并或解释这些独立处理块的结果,以确保整体结果的连贯性和准确性。
通过上述不同的方法,可以有效地管理和处理不同尺寸的输入数据,以满足特定模型的需求或优化模型性能。
这篇关于一点点 cv 经验 1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!