本文主要是介绍concurrency 并行编程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Goroutine
go语言的魅力所在,高并发。
线程是操作系统调度的一种执行路径,用于在处理器执行我们在函数中编写的代码。一个进程从一个线程开始,即主线程,当该线程终止时,进程终止。这是因为主线程是应用程序的原点。然后,主线程可以依次启动更多的线程,而这些线程可以启动更多的线程。

并发不是并行。并行是指两个或多个线程同时在不同的处理器执行代码。如果将运行时配置为使用多个逻辑处理器,则调度程序将在这些逻辑处理器之间分配 goroutine,这将导致 goroutine 在不同的操作系统线程上运行。但是,要获得真正的并行性,您需要在具有多个物理处理器的计算机上运行程序。否则,goroutine 将针对单个物理处理器并发运行,即使 Go 运行时使用多个逻辑处理器。
注意:① 空的 select{} 会永远进行 阻塞
② 如果当前的goroutine要执行但是需要等待另一个goroutine执行完毕才行,这时候就要把另一个goroutine的事情拿来自己做。
③ 使用goroutine考虑两个问题,一是它什么时候结束,二是你有没有一个方法让它结束
这里展示一个较好例子:
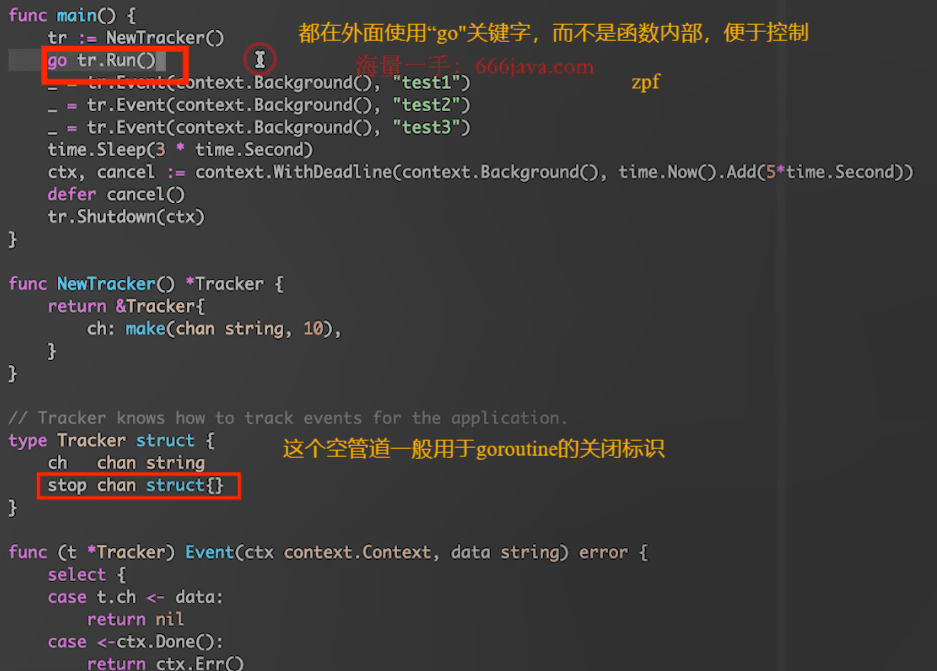
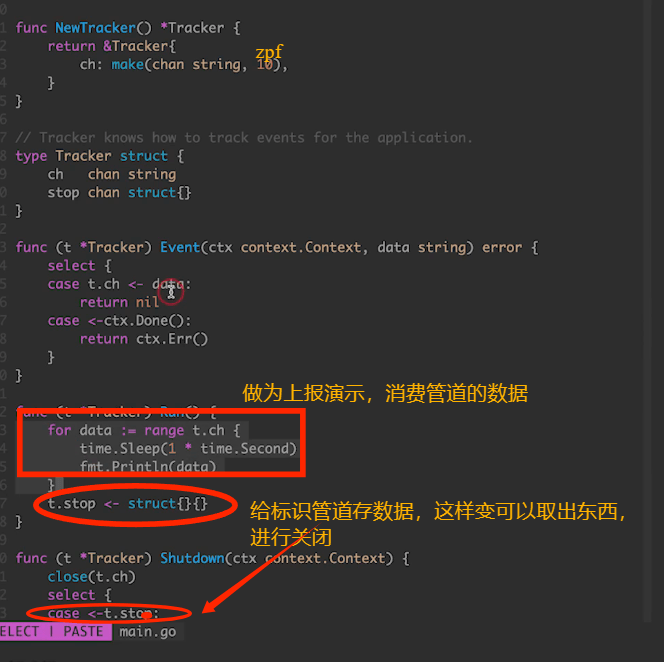
Memory model
go 的内存模型,个人总结:只要是多线程就不要觉得自己太聪明,使用”锁",确保操作事物的原子性,因为多线程之间的调度过程中,cpu,线程为了最大限度的性能,有可能改变不同线程之间关于整体事物的逻辑执行顺序,导致结果出现不可测性。指针copy的方法,指针是一个原子性,但是并不满足 single machine. 当然如果你只是单线程,那么这些忧虑不用考虑
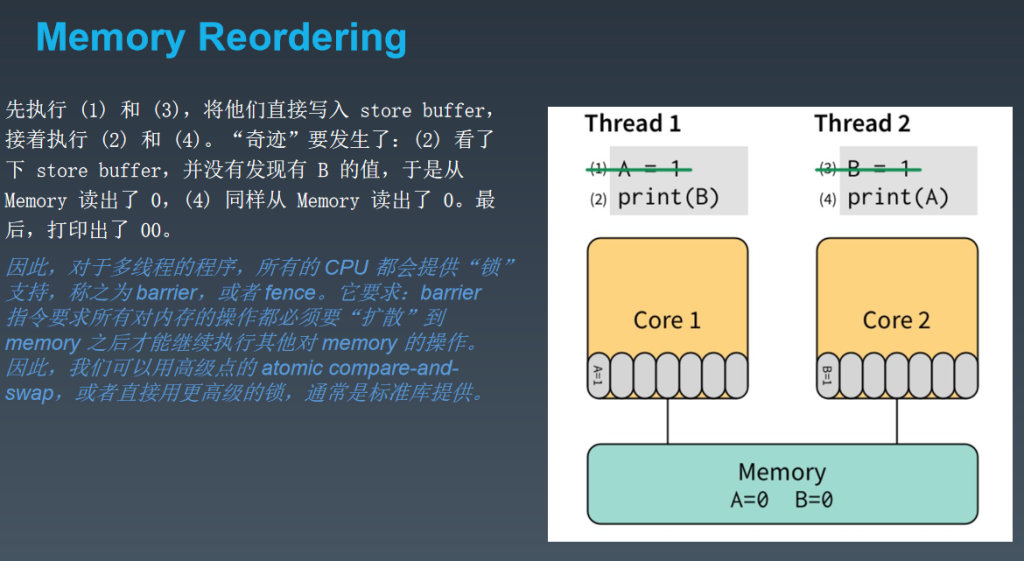
为了说明读和写的必要条件,我们定义了先行发生(Happens Before)。如果事件 e1 发生在 e2 前,我们可以说 e2 发生在 e1 后。如果 e1不发生在 e2 前也不发生在 e2 后,我们就说 e1 和 e2 是并发的。
在单一的独立的 goroutine 中先行发生的顺序即是程序中表达的顺序。
- 当下面条件满足时,对变量 v 的读操作 r 是被允许看到对 v 的写操作 w 的:
- r 不先行发生于 w
- 在 w 后 r 前没有对 v 的其他写操作
- 为了保证对变量 v 的读操作 r 看到对 v 的写操作 w,要确保 w 是 r 允许看到的唯一写操作。即当下面条件满足时,r 被保证看到 w:
- w 先行发生于 r
- 其他对共享变量 v 的写操作要么在 w 前,要么在 r 后。
这一对条件比前面的条件更严格,需要没有其他写操作与 w 或 r 并发发生。

Package sync
data race : 线程竞争,在线程模型中Go 没有显式地使用锁来协调对共享数据的访问,而是鼓励使用 chan 在 goroutine 之间传递对数据的引用。这种方法确保在给定的时间只有一个 goroutine 可以访问数据。
go buid -race go test -race
i++是原子性操作吗? 不是,i++的底层是三行代码,并不是原子性。
Copy-On-Write 思路在微服务降级或者 local cache 场景中经常使用。写时复制指的是,写操作时候复制全量老数据到一个新的对象中,携带上本次新写的数据,之后利用原子替换(atomic.Value),更新调用者的变量。来完成无锁访问共享数据。这也是 Redis 进行写操作来更改数据的一种方法。
Mutex
- go的几种 Mutex 锁的实现:
- Barging. 这种模式是为了提高吞吐量,当锁被释放时,它会唤醒第一个等待者,然后把锁给第一个等待者或者给第一个请求锁的人。
- Handsoff. 当锁释放时候,锁会一直持有直到第一个等待者准备好获取锁。它降低了吞吐量,因为锁被持有,即使另一个 goroutine 准备获取它。(一个互斥锁的 handsoff 会完美地平衡两个goroutine 之间的锁分配,但是会降低性能,因为它会迫使第一个 goroutine 等待锁。)
- Spinning. 自旋在等待队列为空或者应用程序重度使用锁时效果不错。parking 和 unparking goroutines 有不低的性能成本开销,相比自旋来说要慢得多。
errgroup
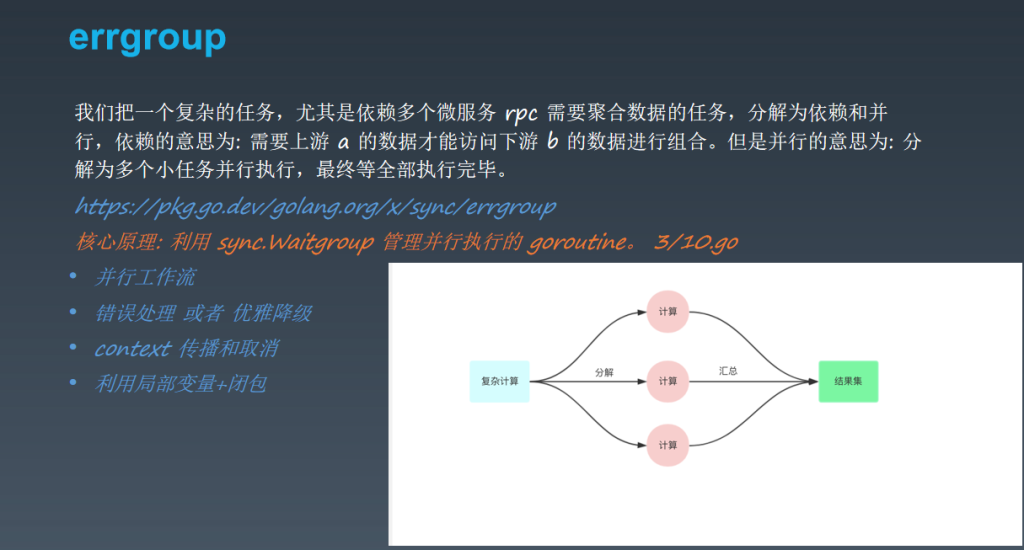
实际生活中我们的errgroup使用的更多一些,用几个gooroutine 去进行分布处理业务,然后通过sync进行控制管理各个分支,把最后的数据再集合起来。 sync.waitGroup()
Chan
各个goroutine通过chan管道来进行实时通信。
channels 是一种类型安全的消息队列,充当两个 goroutine 之间的管道,将通过它同步的进行任意资源的交换。chan 控制 goroutines 交互的能力从而创建了 Go 同步机制。当创建的 chan 没有容量时,称为无缓冲通道。反过来,使用容量创建的 chan 称为缓冲通道。
无缓冲chan
ch := make(chan struct{})
无缓冲 chan 没有容量,因此进行任何交换前需要两个 goroutine 同时准备好。当 goroutine 试图将一个资源发送到一个无缓冲的通道并且没有goroutine 等待接收该资源时,该通道将锁住发送 goroutine 并使其等待。当 goroutine 尝试从无缓冲通道接收,并且没有 goroutine 等待发送资源时,该通道将锁住接收 goroutine 并使其等待。
意思就是双方都得准备好才能进行下去 , 无缓冲信道的本质是保证同步。
- Receive 先于 Send 发生。
- 好处: 100% 保证能收到。
- 代价: 延迟时间未知。
有缓冲的chan
buffered channel 具有容量,因此其行为可能有点不同。当 goroutine 试图将资源发送到缓冲通道,而该通道已满时,该通道将锁住 goroutine并使其等待缓冲区可用。如果通道中有空间,发送可以立即进行,goroutine 可以继续。当goroutine 试图从缓冲通道接收数据,而缓冲通道为空时,该通道将锁住 goroutine 并使其等待资源被发送。
- Send 先于 Receive 发生。
- 好处: 延迟更小。
- 代价: 不保证数据到达,越大的 buffer,越小的保障到达。buffer = 1 时,给你延迟一个消息的保障。
Context
context 的使用因该是贯穿全过程,而不是被把它放到一个对象结构体中去使用

context.WithValue() : 用于创建一个context对象
context.WithValue 方法允许上下文携带请求范围的数据。这些数据必须是安全的,以便多个 goroutine 同时使用。这里的数据,更多是面向请求的元数据,不应该作为函数的可选参数来使用(比如 context 里面挂了一个sql.Tx 对象,传递到 data 层使用),因为元数据相对函数参数更加是隐含的,面向请求的。而参数是更加显示的。
同一个 context 对象可以传递给在不同 goroutine 中运行的函数;上下文对于多个 goroutine 同时使用是安全的。对于值类型最容易犯错的地方,在于 context value 应该是 immutable 的,每次重新赋值应该是新的 context,即: context.WithValue(ctx, oldvalue)
比如 染色,API 重要性,Trace
注意选择使用 copy-on-write 的思路,解决跨多个 goroutine 使用数据、修改数据的场景。
COW: 从 ctx1 中获取 map1(可以理解为 v1 版本的 map 数据)。构建一个新的 map 对象 map2,复制所有 map1 数据,同时追加新的数据 “k2”: “v2” 键值对,使用 context.WithValue 创建新的 ctx2,ctx2 会传递到其他的 goroutine 中。这样各自读取的副本都是自己的数据,写行为追加的数据,在 ctx2 中也能完整读取到,同时也不会污染 ctx1 中的数据。
COW就是 copy-on-write
当一个 context 被取消时,从它派生的所有 context 也将被取消。WithCancel(ctx) 参数 ctx 认为是 parent ctx,在内部会进行一个传播关系链的关联。Done() 返回 一个 chan,当我们取消某个parent context, 实际上上会递归层层 cancel 掉自己的 child context 的 done chan 从而让整个调用链中所有监听 cancel 的 goroutine 退出。
如果要实现一个超时控制,通过上面的 context 的 parent/child 机制,其实我们只需要启动一个定时器,然后在超时的时候,直接将当前的 context 给 cancel 掉,就可以实现监听在当前和下层的额 context.Done() 的 goroutine 的退出。
这篇关于concurrency 并行编程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





