官方文档请查看:https://docs.djangoproject.com/en/1.11/topics/logging/
1. 配置工程日志,在setting.py里,如下
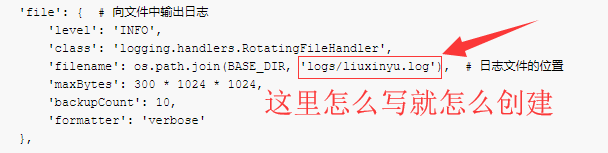
LOGGING = {'version': 1,'disable_existing_loggers': False, # 是否禁用已经存在的日志器'formatters': { # 日志信息显示的格式'verbose': {'format': '%(levelname)s %(asctime)s %(module)s %(lineno)d %(message)s'},'simple': {'format': '%(levelname)s %(module)s %(lineno)d %(message)s'},},'filters': { # 对日志进行过滤'require_debug_true': { # django在debug模式下才输出日志'()': 'django.utils.log.RequireDebugTrue',},},'handlers': { # 日志处理方法'console': { # 向终端中输出日志'level': 'INFO','filters': ['require_debug_true'],'class': 'logging.StreamHandler','formatter': 'simple'},'file': { # 向文件中输出日志'level': 'INFO','class': 'logging.handlers.RotatingFileHandler','filename': os.path.join(BASE_DIR, 'logs/liuxinyu.log'), # 日志文件的位置'maxBytes': 300 * 1024 * 1024,'backupCount': 10,'formatter': 'verbose'},},'loggers': { # 日志器'django': { # 定义了一个名为django的日志器'handlers': ['console', 'file'], # 可以同时向终端与文件中输出日志'propagate': True, # 是否继续传递日志信息'level': 'INFO', # 日志器接收的最低日志级别},}
}
2. 准备日志文件目录,在工程文件下创建logs文件夹,在logs文件夹里创建liuxinyu.log文件(根据上面的配置来的)

3. 日志记录器的使用
不同的应用程序所定义的日志等级可能会有所差别,分的详细点的会包含以下几个等级:
- FATAL/CRITICAL = 重大的,危险的
- ERROR = 错误
- WARNING = 警告
- INFO = 信息
- DEBUG = 调试
- NOTSET = 没有设置
import logging# 创建日志记录器
logger = logging.getLogger('django')
# 输出日志
logger.debug('测试logging模块debug')
logger.info('测试logging模块info')
logger.error('测试logging模块error')
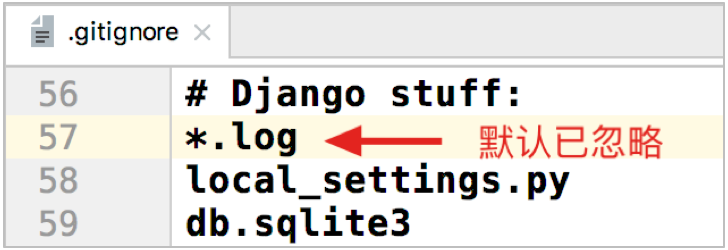
4. 取消Git记录工程日志
- 建立代码仓库时,生成的忽略文件中已经默认忽略掉了*.log。
- logs文件目录需求被Git仓库记录和管理。
- 当把
*.log都忽略掉后,logs文件目录为空。 - 但是,Git是不允许提交一个空的目录到版本库上的。
解决:
- 在空文件目录中建立一个.gitkeep文件,然后即可提交。








