本文主要是介绍C语言之函数和函数库以及自己制作静态动态链接库并使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:函数的本质
1:C语言为什么会有函数
(1)整个程序分为多个源文件,一个文件分为多个函数,一个函数分成多个语句,这就是整个程序的组织形式。这样的组织好处在于:分化问题、、便于程序编写、便于分工
(2)函数的出现是人(程序员和架构师)的需要,而不是机器(编译器、cpu)的需要
(3)函数的目的就是实现模块话编程
2:函数书写的一般原则
(1)遵循一定的格式。函数的返回类型、函数名、参数列表等
(2)一个函数只做一件事,不能太长也不能太短,原则是一个函数只做一件事
(3)传参不宜过多,在ARM体系下,传参不宜超过四个。如果传参确实需要多则考虑结构体打包
(4)尽量少碰全局变量,函数最好用传参返回值来和外部交换数据,不需要用全局变量
3:函数是动词,变量是名词
(1)函数将来被编译成可执行代码段,变量(主要指全局变量)经过编译后变成数据或者运行时变成数据。一个程序的运行需要数据和代码两方面的结合才能完成
(2)代码和数据需要彼此配合,代码是为了加工数据,数据必须借助代码来起作用。
4:函数的实质是:数据处理器
(1)程序的主体是数据,程序运行的主要目标是生成目标数据,程序员写代码也是为了目标数据。如何得到目标数据?必须两个因素:原材料和加工算法。原材料就是程序输入的数据,加工算法就是程序
(2)程序的编写和运行就是为了把原数据加工成目标数据,所以程序的实质就是一个数据处理器
(3)函数就是程序的一个缩影,函数的参数列表就是为了给函数输入原材料数据,函数的返回值和输出参数就是为了向外部输出目标数据,函数的函数体内部的那些代码就是加工算法。
(4)函数在静止时没有执行(待在硬盘里),此时只会占用一些存储空间但是并不会占用资源(cpu+内存);函数的每一次运行时都需要耗费资源(cpu+内存),运行时可以对数据加工生成目标数据;函数运行完成后会释放占用的资源
(5)整个程序的运行其实就是很多个函数相继运行的连续过程
二:函数的基本使用
1:函数三要素:定义、声明调用
(1)函数的定义就是函数体、函数的声明就是函数的原型、函数的调用就是使用函数
#include <stdio.h>int add(int a,int b); //函数声明int main(void)
{int a = 3;int b = 5;int c = 0;c =add(a,b); //函数调用printf("c = %d\n",c); //结果8 printf("3+5 = %d\n",add(3+5)); //8 //add函数的返回值作为printf函数的参数return 0;}//函数定义
int add(int a,int b) //函数名、参数列表、返回值
{return a + b; //函数体
}(2)函数定义是函数的根本,函数定义中的函数名表示了这个函数在内存中的首地址,所以可以使用函数名来调用执行这个函数(实质是指针解引用访问);函数定义中的函数体是函数的执行关键,函数将来执行主要就是执行函数体。
(3)函数声明的主要是告诉编译器函数的原型
(4)函数调用就是执行一个函数
2:函数原型和作用
(1)函数原型就是函数的声明,就是函数的函数名、返回值类型、参数列表
(2)函数原型的主要作用就是给编译器提供原型,让编译器在编译程序时帮助程序员进行参数的静态类型检查
(3)编译器在编译文件时是以单个源文件为单位的(所以一定要在哪里调用在哪里声明),而且编译器工作时就已经经过预处理了,最重要的是编译器编译文件时是按照文件中语句的先后顺序来执行的
(4)编译器从源文件的第一行开始编译,遇到函数声明时就会收到编译器的函数声明表中,然后继续向后。当遇到一个函数调用时,就在本文件函数声明表中去查这个函数,看有没有原型相对应的一个函数(这个相对应的函数有且只能有一个)。如果没有或者只有部分匹配只会报错和报警告,如果发现多个则会报错和报警告(函数重复了,C语言中不允许2个函数原型完全一样这个过程其实是在编译器遇到函数定义时完成的,所以函数可以重复声明但是不能重复定义)
3:函数传参
(1)函数传参的个数和类型要匹配
(2)如果传参个数太多可以用结构体打包
三:递归函数
1:什么是递归函数
(1)递归函数就是函数值调用了自己本身的函数的函数
(2)递归函数和循环的区别。递归不等于循环
(3)递归函数解决问题的典型就是:求阶乘、求裴波那切数列
//求阶乘
#include <stdio.h>int jiecheng(int n); //函数声明int main(void)
{int a = 5;int c = 0;c = jiecheng(a); //函数表达式展开首先>1 != 1 ,所以进入else 中//retuen (n * jiecheng(n-1))//就等于 (5 * (4 * (3 * (2 * (1))))) 结果为120printf(" c = %d\n",c);return 0;}int jiecheng(int n)
{if(n<1) //判断是否小于1 ,小于1 输出n!<1 并返回 -1{printf("n !<1");return -1;}else if(n == 1){return 1; //n等于1返回 1 }else{return (n * jiecheng(n-1)); //n<1则返回 n * 函数本身(传参-1),直接调用 //本身这个函数,直到不满足<1时不在继续调用执行本身函数返回所乘的值}}2:函数的递归调用原理
(1)实际上递归函数是在栈内存上递归执行的,每次递归执行一次就需要耗费一些栈内存
(2)栈内存大小是限制递归深度的重要因素
3:使用递归函数的调用原则:收敛性、栈溢出
(1)收敛性就是函数必须要有一个终止递归的条件。当每次这个函数被执行时,我们判断一个条件决定是否结束递归,这个条件最终必须被满足。如果没有递归终止条件或者这个条件永远不能被满足,则这个递归没有收敛性,这个递归最终要
(2)因为递归是占用栈内存的,每次递归都会消耗一些栈内存。因此必须在栈内存耗尽之前递归收敛(终止)否则栈就会溢出
四:函数库
1:什么是函数库?
(1)函数库就是一些事先写好的函数的集合
(2)函数是模块化的,因此可以被复用。程序员写好了一个函数,可以被反复使用。也可以a写好了一个函数共享出来,当b有需求是就不用重新写这个函数直接用a写好的就可以了
2:函数库的由来
(1)最开始是没有函数库的,每个人写程序都要自己重头开始自己写。时间久了程序员就积累了一些有用的函数(经常要用到的函数 )
(2)早起的程序员经常参加行业聚会,在聚会上大家交换各自的函数库
(3)后来的行业大神就提出把大家各自的函数收拢在一起,然后经过校验和整理,形成一份标准的函数库,就是现在公开的函数库,
3:函数库的提供形式:动态链接库与静态链接库
(1)早起的函数共享都是以源代码的形式进行的。这种共享的方式是最彻底的(后来这种源码共享的方向就变成了现在的开源社区)。但是也有缺点,缺点就是无法以商业化的方式发布函数库
(2)商业公司需要将自己有用的函数共享给别人(付费的形式),但是不能给客户源代码,这时候的解决方案就是以库a(主要是以静态库和动态库)的形式来提供
(3)比较早出现的是静态链接库。静态库就是商业公司将自己的函数源代码只编译不链接形成.O的目标文件,然后用ar工具将.O文件归档成.a的归档文件(.a的归档文件又叫静态链接文件)。商业公司通过发布.a库文件和.h头文件来提供静态库来给客户使用:客户拿到.a和.h文件之后,通过.h头文件得知库中库函数的原型,然后在自己的.c文件中调用这些库文件 ,在链接的时候链接器会去.a文件中拿出被调用的那个函数的编译后的.o二进制代码段链接进去形成最终的可执行程序
(4)动态链接库比静态链接库要出现的晚一些,效率要高一些。现在基本上都是用动态库的。静态库在用户链接自己的可执行程序时就已经把调用的的库中的函数的代码段链接进最终的可执行程序中了,这样的好处是可以执行,坏处是太占地方了。尤其是有多个应用程序都使用了这个库函数的时候,实际在最后生成的可执行程序中都各自有一份这个函数的代码段。当这些应用程序同时在内存中运行时,实际上在内存中有多个这个库函数的代码段,这完全重复了,而动态链接库本身不将库函数的代码段链接到可执行程序,只是做个标记,然后当应用程序在执行时,运行时环境发现调用了一个动态库的库函数时,会去加载这个动态库去内存中,然后不管以后多少次调用执行这个动态库中的函数都会跳转到第一次加载的地方去执行,不会重复去加载。
//使用静态链接动态链接编译链接递归函数实现阶乘程序来查看动态链接和静态链接的区别
#include <stdio.h>int mem(int n)
{if(n<1){return -1;}if(n== 1){return 1; }else{return n * mem(n-1);}}int main(void)
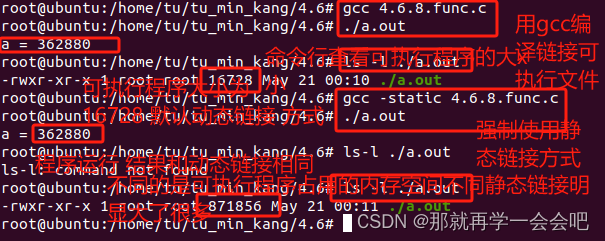
{int a = mem(9);printf("a = %d\n",a);return 0;}使用linux环境下用gcc编译工具链
用gcc默认编译目标文件4.6.8.func.c (默认为动态链接) 输出 a = 362880查看可执行文件./a.out文件大小为16728
使用强制静态链接方式编译链接目标文件4.6.8.func.c 输出a = 362880 查看可执行文件大小为871856
4:函数库中库函数的使用
(1)linux的gcc中编译链接程序默认是使用动态链接,要想使用静态链接需要显示使用-static来强制静态链接
(2)库函数的使用需要注意四点:第一,包含相应的头文件;第二,调用库函数时要注意函数原型;第三,有些库函数链接时需要额外用-lxxx来指定链接;第四,如果是动态库,要注意-L指定动态库的地址
五:字符串函数
1:什么是字符串
(1)字符串就是在多个字符在内存中连续分布组成的字符结构。字符串的特点是指定了开头(字符串的指针)和结尾(结尾为固定字符'\0'),而没有指定长度(长度由开头地址和结尾地址相减得到)
2:常用字符串处理函数
(1)c库中字符串处理函数包含在string.h头文件中,这个文件在ubuntu系统中在/use/include中
(2)常见字符串处理函数及其用法
六: 数学库函数
1:math.h
(1)真正的数学运算函数定义在:/usr/include/i386-linux-gnu/bits/mathcalls.h
(2)使用数学库函数的时候,只需要包含math.h即可
2:计算开平方
(1)库函数:double sqrt(double x);
//使用库函数中math.h头文件中声明的sqrt函数来计算开平方的值#include <stdio.h>
#include <math.h> //数学库函数int main(void)
{double a = 16.0; //定义一个double类型的变量double b = sqrt(a); //计算a变量存的值的平方printf("b = %lf\n",b); return 0;}但是如果在linux中进行编译链接可能会出现报错
分析:这个链接错误的意思是;sqrt函数有声明(声明就在math.h中)有引用(在math.c)但是
没有定义,链接器找不到函数体。sqrt本来是库函数,在编译器库中是有.a和.so链接库的(函
数体在链接库中的)

这里显示main函数中的sqrt未定义引用,其实是定义声明了的只是找不到函数原型
但是当我们把头文件包含的math.h函数屏蔽时的报错
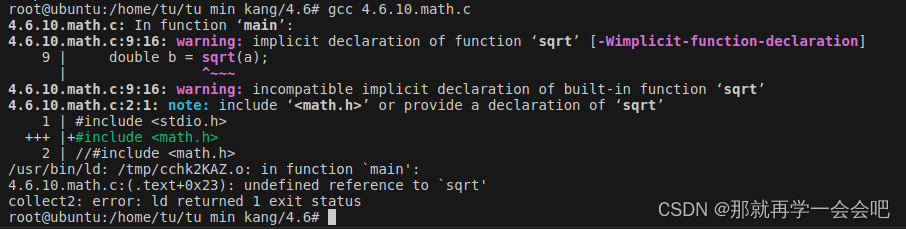
解决办法是在编译链接文件时后面加-lm也就是: gcc 4.6.10.math.c -lm
下面图可以看到添加了-lm之后不报错,运行可执行文件也输出了a的值的开平方也就是16的开平方4

链接器的工作特点:因为库函数有很多,链接器去库函数目录搜索的时间比较久。为了提升速
度想了一个折中的方案:链接器只是默认的寻找几个最常用的库,如果是一些不常用的库中的函
数被调用,需要程序员在链接时明确给出要扩展查找的库的名字。链接时可以用-1xxx来指示链
接器去到libxxx.so中去查找这个函数
3:链接时加 -lm
(1)-lm就是告诉链接器到libm中去查找用到的函数
(2)高版本的gcc会出现不用加lm也可以编译链接成功
七:自己制作静态连接库并使用
1: 第一步,自己制作静态链接库 (在ubuntu系统中)
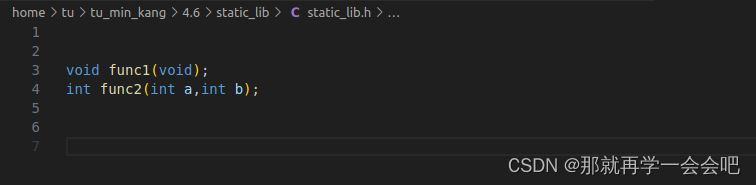
在ubuntu中创建文件夹(名为static_lib)-> 进入创建的文件夹static_lib -> 创建一个名为static_lib.c的.c源文件和一个名为static_lib.h的文件 -> 在static_lib.c源文件中写入代码 -> 在static_lib.h头文件中声明函数 -> 使用gcc static_lib.c -o static_lib.o -c命令行命令只编译不链接生成static_lib.o文件 -> 使用ar -rc libstatic_lib.a static_lib.o命令行命令使用ar工具打包成.a归档文件



#include <stdio.h>void func1(void)
{printf("func1 in static_lib.c.\n");}int func1(int a,int b)
{printf("func2 in static_lib.c.\n");return a + b;}


(1)首先使用gcc -c 只编译不链接,生成.o文件;然后使用ar工具进行打包成.a归档文件
(2)库名不能随便乱起,一般是lib+库名称,后缀名是.a表示是一个归档文件
(3)制作出来静态库后,发布需要发布.a文件和.h文件
2:第二步,使用静态链接库
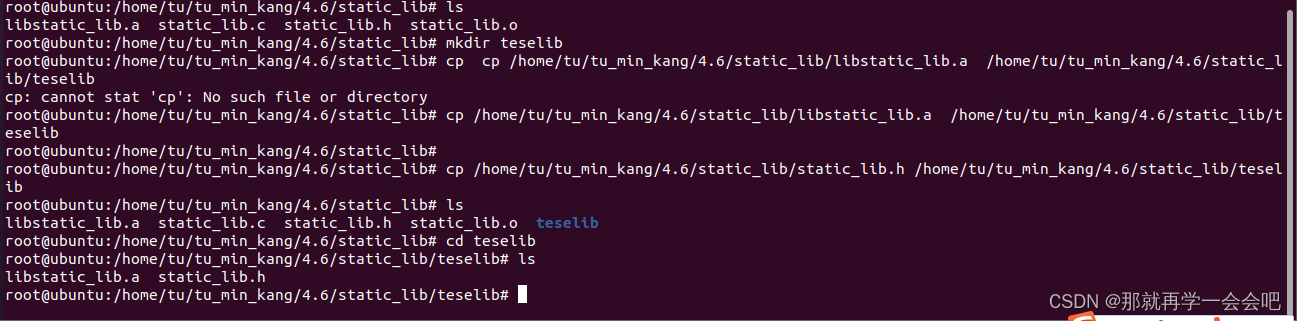
在static_lib文件夹中创建一个名为static_lib的子文件夹 -> 将刚刚生成的归档文件libstatic.a和static.h文件复制到ststic_lib子文件夹中->创建一个名为test.c的源文件,在里面写入代码调用静态库内的函数->使用gcc test.c -o test -lstatic_lib -L.命令编译链接生成可执行文件->运行可执行文件
cp /home/tu/tu_min_kang/4.6/static_lib/libstatic_lib.a /home/tu/tu_min_kang/4.6/static_lib/teselib
cp /home/tu/tu_min_kang/4.6/static_lib/static_lib.h /home/tu/tu_min_kang/4.6/static_lib/teselib

#include "static_lib.h"
#include <stdio.h>int main(void)
{func1();int a = func2(3,5);printf("a = %d\n",a);return 0;} 
(1)把.a文件和.h放在需要引用的文件夹下,然后在.c文件中包含库文件使用库函数
第一次编译方法 :gcc tese.c -o test
报错:/usr/bin/ld: /tmp/ccniBjn5.o: in function `main':
test.c:(.text+0xd): undefined reference to `func1'
/usr/bin/ld: test.c:(.text+0x1c): undefined reference to `func2'
collect2: error: ld returned 1 exit status
第二次编译方法:gcc test.c -o test -lstatic_lib
报错:/usr/bin/ld: cannot find -lstatic_lib collect2: error: ld returned 1 exit status
第三次 编译方法:gcc test.c -o test -lstatic_lib -L.
无报错
运行结果:

八:自己制作动态链接库并使用
动态链接库的后缀是.so(对于windows系统的dll),静态库的扩展名是.a
1:创建动态链接库并使用流程
编写.c源文件和.h源文件 -> 使用gcc dynamic_lib.c -o dynamic_lib.o -c -fPIC 命令将.c源文件只编译不链接生成.o文件(-fPIC是告诉编译器在编译时将程序变成位置无关码,这意味着生成的目标文件是与其载入的内存位置无关的,可以被载入到进程的任何位置,只要所有的内存访问都是正确的。位置无关码对于共享库(如.so文件)是非常重要的,因为它们需要能够被多个进程同时使用,而不会相互干扰。) -> 再使用gcc -o libdynamic_lib.so dynamic_lib.o -shared生成动态链接库(-shared告诉编译器我们要将它设用置为共享库的方式来进行链接)->编写一个.c文件来调用生成的动态链接库 -> 使用gcc test.c -o test -ldynamic_lib -L 命令来编译链接文件 -> 将动态链接库复制一份到/usr/lib目录下 ->./test执行程序
#include <stdio.h>void func1(void)
{printf("func1 in static_lib.c.\n");}int func1(int a,int b)
{printf("func2 in static_lib.c.\n");return a + b;}
void func1(void);
int func2(int a,int b);

#include <stdio.h>
#include "dynamic_lib.h" int main(void)
{func1();int a = func2(3,5);printf("a = %d\n",a);return 0;}


第一次编译:gcc test.c -o test
报错:/usr/bin/ld: /tmp/ccDhA63w.o: in function `main':
test.c:(.text+0xd): undefined reference to `func1'
/usr/bin/ld: test.c:(.text+0x1c): undefined reference to `func2'
collect2: error: ld returned 1 exit status
第二次编译:gcc test.c -o test -ldynamic_lib
报错:/usr/bin/ld: cannot find -ldynamic_lib
collect2: error: ld returned 1 exit status
第三次编译:gcc test.c -o test -ldynamic_lib -L.
无报错
但是运行test可执行文件报错 原因是:动态库在运行时需要被加载(运行程序时环境在执行test时发现他动态链接了 libdynamic_lib.so,于是会去固定目录尝试加载 libdynamic_lib.so,失败则会打印错误)
![]()

解决方法1:将动态链接库复制一份到/usr/lib目录下
使用ldd指令查看 :ldd test

解决方法2:使用环境变量LD_LIBRARY_PATH 操作系统在加载固定目录/uer/lib之前会去 环境变量LD_LIBRARY_PATH指定的目录去寻找,如果找到就不要去/usr/lib目录下找,没找到才会去/usr/lib
export
LD_LIBRARY_PATH=$LD_LIBARY_PATH:/home/tu/tu_min_kang/4.6/4.6.12.dynamic_lib/testlib
这篇关于C语言之函数和函数库以及自己制作静态动态链接库并使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




