本文主要是介绍【Linux系统编程】进程概念、进程排队、进程标识符、进程状态,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
什么是进程?
浅谈进程排队
简述进程属性
进程属性之进程标识符
进程操作之进程创建
初识fork
fork返回值
原理角度理解fork
fork的应用
进程属性之进程状态
再谈进程排队
进程状态
运行状态
阻塞状态
挂起状态
Linux下的进程状态
“R”(运行状态)
“S”(浅度睡眠状态)
“D”(深度睡眠状态)
“T\t”(暂停状态)
“Z”状态与“X”状态
什么是进程?
如果要了解进程是什么,我们得从程序开始说起!
程序就是我们写的源代码进行编译和链接后形成的可执行程序,在Windows下就是以.exe为后缀的文件
到这里,我们了解了什么是程序,而接下来要讨论的内容就是程序是如何运行的
首先,从硬件的角度,也就是冯诺依曼体系结构我们可以了解到,一个数据从输入设备进入被运到CPU再到输出设备,在这个中间为了效率考虑所以才会有了一个设备,叫做内存,这些我在往期博客进行详细说过,感兴趣的可以看看: 冯诺依曼体系结构
冯诺依曼体系结构设计了一个中间件叫做内存,CPU不直接与外设打交道,而是与内存打交道,外设也不直接与CPU打交道,而是直接与内存打交道,而程序是一个文件,那么接下来的问题就是,文件放在哪?
这个问题是显而易见的,文件肯定是放在硬盘上的,而硬盘是一个外设。
程序文件中是包含的一条条二进制的指令,这个是一个常识,那么既然是指令,所以这个指令需要经过CPU的运算吗?
答案也是肯定的
所以最后我们的结论出来了,程序需要用到CPU所以它在运行的时候一定会被放在内存上,这是由冯诺依曼体系结构决定的
接下来的问题是:一个程序被运行放到内存上,难道内存上只放一个程序吗?换句话来说,难道同一个时间只能运行一个程序吗?
显然不是,依据我们的常识可以知道,可以有多个程序被放在内存,如果内存中只能放一个程序的话,那么当我们在运行QQ的时候,就不能同时运行音乐软件,但实际当中我们是可以的
而我们的操作系统的功能是要对下管理好软硬件资源,既然现在有多个程序可以同时在一片内存当中运行,所以现在操作系统肯定要对这些程序进行管理:什么是管理
而操作系统怎么管理这些程序呢?
答案是:先描述、再组织
以Linux操作系统为例,Linux是用C语言写的,那么C语言当中我们如何描述一个对象呢?
实际上,如果我们学过C语言就会了解,struct也就是结构体类型可以对一个事物进行描述
就好比如果我们要用C语言进行描述一个人这种类型,我们可以用结构体包含它的各种各样的属性
比如姓名、性别、年龄、身高、体重等等。。
struct Person
{const char* _name;const char* _sex;int _age;//....
}那么如果我们的Linux操作系统需要管理好这些程序,肯定要描述这些程序,Linux是用C语言写的,所以描述我们可以用到结构体类型,而描述在内存中的程序的结构体类型我们称为PCB
PCB(process-control-blco = 进程控制块)
PCB当中放着在内存中的程序的各种属性,我们现在可以粗力度的理解为PCB就是描述程序的
当然,PCB当中也一定会有可以找到对应程序的属性,这个属性字段我们称为内存指针字段,这个内存指针是指向PCB所对应的在内存中的程序的
当有了PCB以后,操作系统只需要查看PCB的属性字段就可以知道你这个PCB所对应的程序的属性,而不需要跑去看程序本身
所谓的PCB其实是放之四海而皆准,也就是Windows当中的描述在内存中的程序的结构体我们可以称为PCB,Linux的也可以
但如果具体到Linux操作系统,它的PCB具体实现命名为task_struct
现在,我们已经可以描述一个程序了,接下来我们需要聊聊如何组织的问题
所谓的组织,也就是当我们有了很多很多程序的PCB之后,如何管理好它们,换句话来说就是如果PCB需要删除,PCB需要增加、需要查找某个PCB,我们如何更方便的实现
其实也就是所谓的数据结构。
在Linux当中,我们把一个一个的task_struct看成是一个结点,task_struct中包含一个next指针,指向下一个task_struct,形成一个task_struct的链表,此时,当我们程序运行结束之后,从内存中放回硬盘,那么我们只需要对这个链表结点进行删除结点即可,如果我们有一个新的程序来到内存,创建好task_struct之后,我们把这个task_struct插入链表即可
此时操作系统就把对程序的管理变成了对程序所对应PCB对象的管理

到这,我们也终于可以聊聊这个标题,即什么是进程?
所谓的进程,不是指的运行期间被放在内存的程序,也不是指的PCB(Linux:task_struct)
而是运行期间被放在内存的程序及其所对应的PCB所组成的一个整体我们称之为进程
当然,由于操作系统对PCB的管理是对数据结构的管理,所以我们可以更进一步得出如下结论:
进程 = 内核数据结构 + 可执行程序
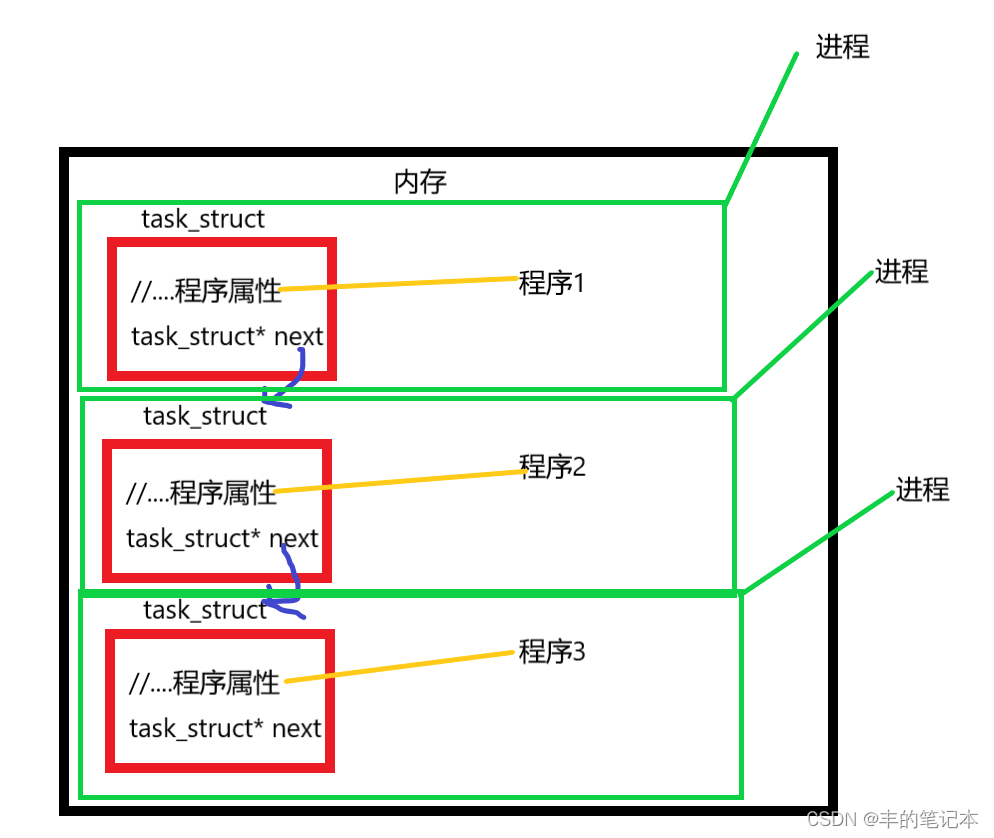
在上述中,我们谈到了task_struct是描述程序的属性,这其实是比较粗浅的理解,其实它不仅仅包含程序的属性,其实它包含了进程的几乎所有属性
浅谈进程排队
在上述的内容中,我们了解到了,进程到底是什么,并且也了解到了PCB的概念以及操作系统如何管理PCB,接下来我们谈一谈所谓的进程排队
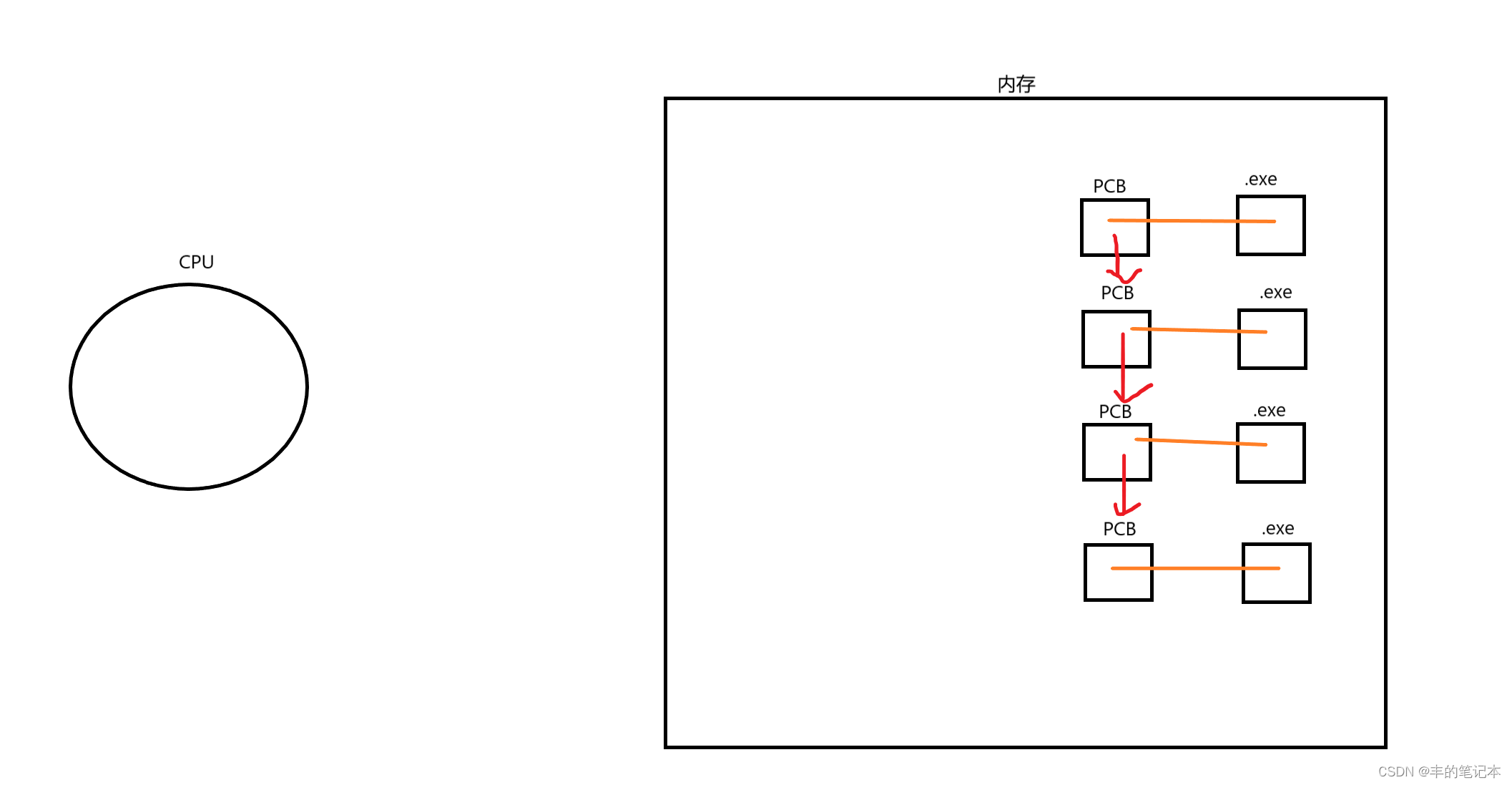
一个进程,如果需要调度CPU,那么CPU肯定只能被一个进程调度,因为CPU只有一个,哪怕它再快,也不能同时处理多个进程,所以操作系统会在内存中添加一个运行队列的概念
当一个进程需要调度CPU的时候,操作系统会把它所对应的PCB添加到运行队列中,我们就假设它是拷贝
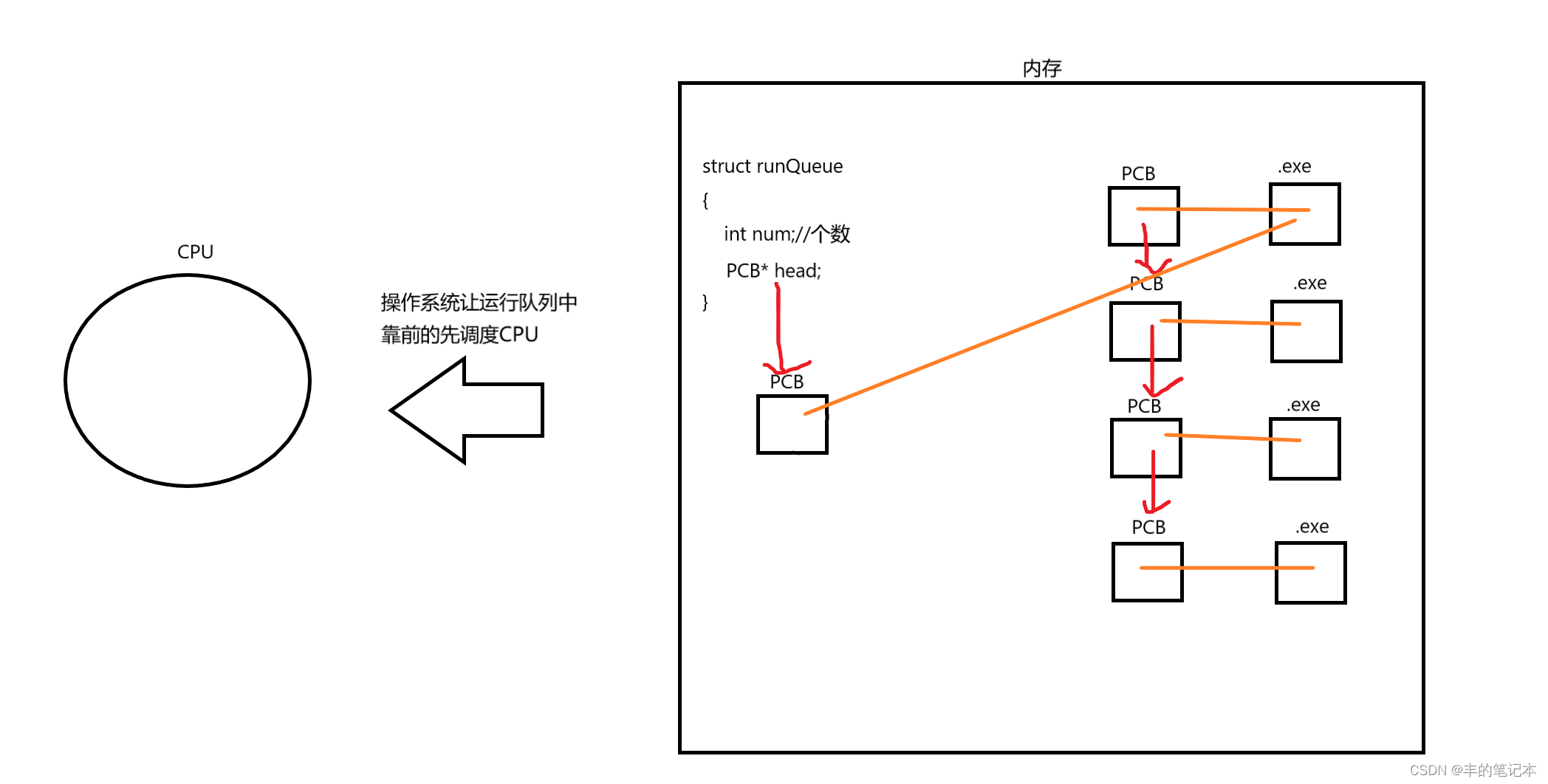
若此时再有进程需要调度CPU,那么就需要在运行队列中排队,所以所谓的进程排队指的是进程的PCB去排队,而不是进程的可执行程序去排队
所以,我们也能看出,所有的对进程的控制和操作,都只和进程的PCB有关,和进程的可执行程序无关
现在,我们已经对进程有了一定的了解了,接下来我们将分两部分进行学习
1、PCB内部中的属性信息
2、PCB作为一个整体,如何被我们使用
简述进程属性
注意:进程属性非常非常多,我们无法全部学习,只能挑一部分比较重要的内容
在我们详细学习进程属性的之前,我们先要知道进程属性到底有哪些,做到心中有数
进程属性主要内容:
1、标识符:描述本进程的唯一标识符,用来区分其他进程
2、状态:任务状态,退出代码,退出信号等
3、优先级:相对于其他进程的优先级
关于第三点我可以先说说,在之前的学习中,我们了解过进程排队,所谓的优先级就是进程排队时的前后顺序
4、程序计数器:程序中即将被执行的下一条指令的地址
关于第四点,我可以现在粗力度解释一下,接下来我要问一个问题
当你写了一个C代码之后,为什么计算机会知道你执行到第几行了呢?
实际上,在CPU内部存在着一个寄存器eip,这个寄存器也叫做pc指针或程序计数器或指令寄存器
当我们写代码的时候一行一行的语句,每一个语句都有它所对应的地址
而CPU能完成的工作主要是三个,首先取指令,取到指令以后分析指令,分析完指令之后执行指令,而当执行完指令之后就再去取指令,循环往复
但此时问题就来了,CPU去哪去取指令呢?
我们说过,cpu内部有一个pc指针,这个pc指针实际上存储的就是当前进程正在执行的指令的下一条指令的地址,当CPU需要取指令的时候就会从pc指针中取,并且更新pc指针,使它指向下一条语句
所以此时我们就了解到,所谓的循环、判断、函数跳转本质是修改pc指针
5、内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
对于第五点,其实我们之前聊到过,当操作系统对进程进行管理的时候,管理的其实是进程的PCB,但PCB并不是我们需要执行的程序,为了帮助我们拿到进程所对应的可执行程序,所以才有了这个内存指针
6、上下文数据:进程执行时处理器的寄存器中的数据
7、I /O状态信息:包含显示I/O请求,分配给进程的I/O设备和被进程使用的文件列表
8、记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
进程属性之进程标识符
所谓的进程标识符,其实正如它的名字一样,是用来标识一个进程的,并且这个进程标识符在操作系统中具有唯一性,也就是每一个进程它的进程标识符都不同
就好比人来说,为了区分你和其他人,那么你肯定是有一个唯一标识你这个人的属性的,在现实生活中这个标识就是身份证号码,而对于操作系统来说,操作系统要管理进程,那么肯定要区分不同的进程,所以就有了进程标识符
而在Linux操作系统中,这个进程标识符我们称为pid
查看进程标识符:getpid()和getppid()系统调用
进程标识符,我们可以查看,但要使用系统调用接口

getpid的参数不用写,而getpid的返回值是哪一个进程调用的getpid就返回哪个进程的pid,返回值我们可以当成是C语言中的int
如下为demo代码
#include <stdio.h>#include <unistd.h>int main() {printf("进程运行:pid:%d\n",getpid());while(1);return 0;}
我们知道了它的pid的话现在就可以通过指令查看这个pid对应的可执行程序是否是我们运行的
指令:ps axj
axj是选项,我们暂时先不管,只管用就可以了
当我们输入这个指令后,可以查找到我们当前运行的所有进程的属性信息
 可以看到,有很多很多的信息打印出来,但这些属性信息我们不知道它是什么,但首行有标题,可以通过管道打印出首行,ps axj | head -1
可以看到,有很多很多的信息打印出来,但这些属性信息我们不知道它是什么,但首行有标题,可以通过管道打印出首行,ps axj | head -1

我们还可以通过grep工具筛选出我们所要的行
上述,我们的程序在运行的时候的pid是5044
所以我们可以执行ps axj | head -1 && ps axj | grep 5044

可以看到,确实是我们运行的进程的pid
当然,除了可以这样查看,实际上在我们进程被运行期间操作系统会在/proc目录下创建它的pid所对应的目录文件,这个文件当中包含了pid所对应进程的属性信息
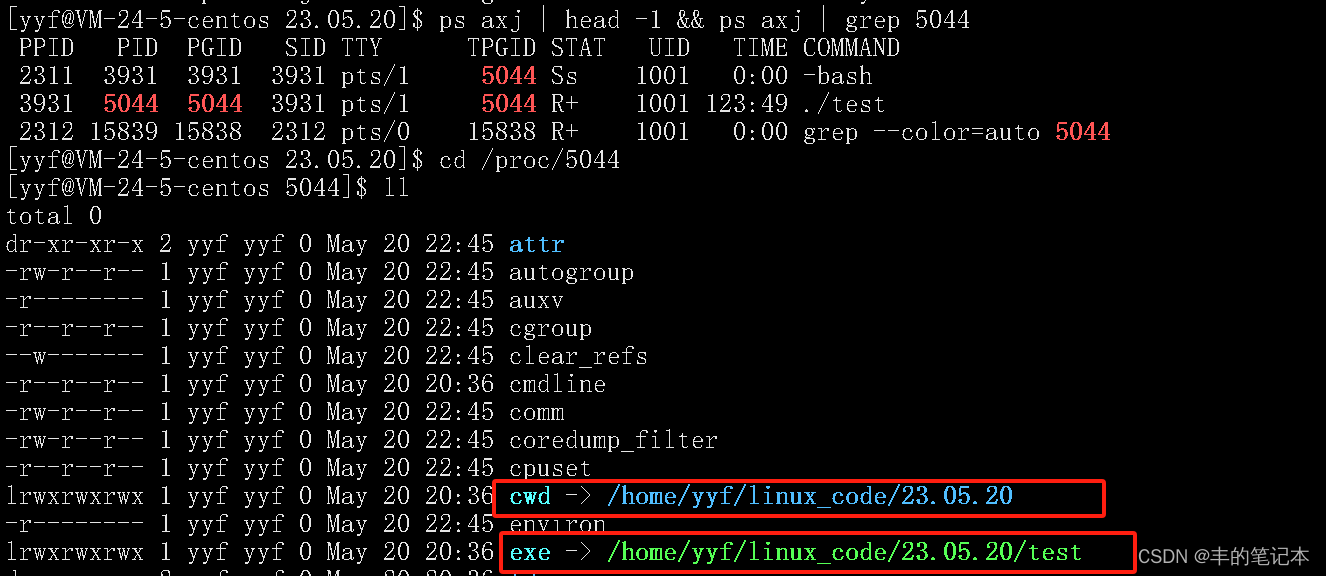 接下来我补充一个小内容,就是其他属性信息我们暂时不管,先看这个cwd和exe
接下来我补充一个小内容,就是其他属性信息我们暂时不管,先看这个cwd和exe
exe我们比较好理解,其实就是我们所对应的可执行程序的路径
主要我们来看看cwd,cwd其实是当前进程工作目录
这个有什么用呢?我举一个小例子
当我们在学习C语言的fopen函数的时候会经常看到一句话,fopen函数如果在当前目录下没有找到这个名字的文件,则它会自动创建这个文件,其实fopen所说的当前路径也就是这个cwd
这个路径我们是可以更改的
更改当前进程工作路径系统调用:chdir()
chdir的参数只有一个常量字符串,就是我们要把当前路径cwd改成什么路径,并且这个系统调用需要包含头文件unistd.h
关于它的返回值,如果为0,更改成功,如果为-1,更改失败。
如下为demo代码
#include <stdio.h>
#include <unistd.h>int main()
{const char* path = "/home/yyf";printf("更改当前路径");chdir(path);FILE* fp = fopen("test.txt","w");fclose(fp);return 0;
}
这个程序我期待的运行结果是它运行完以后在“/home/yyf”目录下创建一个test.txt文件
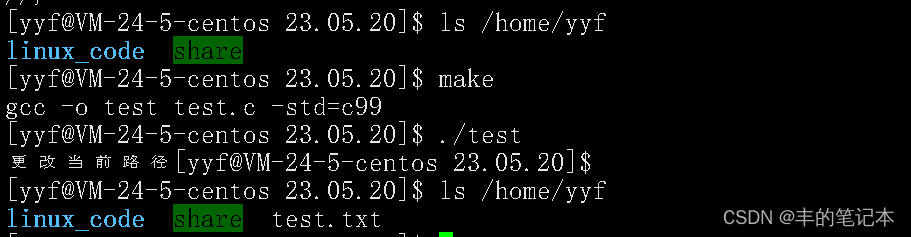
可以看到,运行结果符合我的预期,说明如果修改了当前目录cwd,那么当使用fopen函数打开创建文件时就会在你修改的目录下查找是否有,如果没有则在这个目录下创建一个文件,而我这里是以fopen为例,其他所有会在当前目录自动创建文件的函数也是同理
前面介绍了getpid系统调用,接下来介绍一下getppid系统调用
getpid和getppid是很像的,都是获得进程pid,但是getpid是获得执行getpid的进程的pid
而getppid是获得执行getppid的进程的父进程pid
getppid系统调用的返回值是当前进程的父进程的pid
所谓的父进程就是指的是创建当前进程的进程,这一部分在我的Linux基础博客中有涉及,父进程(Shell外壳章节)
如下为demo代码:
#include <stdio.h>
#include <unistd.h>int main()
{printf("I am child-process pid:%d,My father-process pid:%d\n",getpid(),getppid());return 0;
}
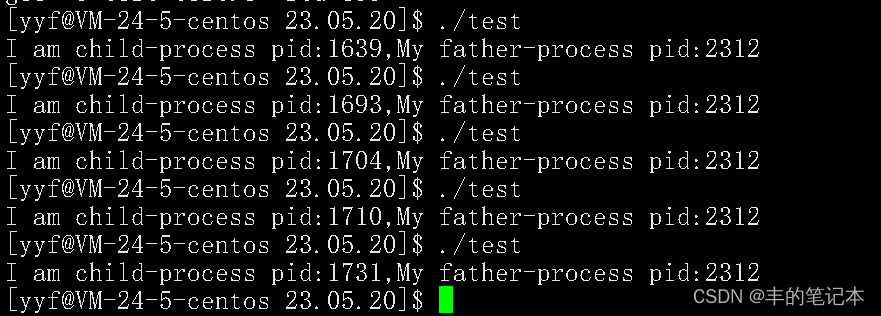
我们可以发现确实可以获得父进程的pid,但是为什么父进程的pid每一次执行的时候都一样,为什么子进程的pid每一次执行的时候都不一样呢?
要想了解这个,我们先去看看我们上面运行的进程所对应的父进程是什么东西

可以发现,我们运行的进程的父进程其实是bash,也就是我们熟知的命令行解释器
所以,如果我们不重启命令行解释器也就是shell,那么我们在命令行中使用./的方式创建的进程的父进程的pid是不会变的
进程操作之进程创建
在上述内容中,我们了解到了一种进程创建方式,即通过命令行创建,并且这种创建出来的进程,它的父进程一定是bash。
那么我们通过命令行创建的子进程是否可以再创建出子进程呢?
换句话说,我现在是父亲,我的儿子是否还可以有儿子呢?
这是肯定的,Linux中提供了系统调用fork函数可以创建子进程
初识fork
fork函数没有参数,fork函数的功能是创建一个子进程
fork函数需要包含unistd.h
接下来我们先看现象,如下demo代码
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>int main()
{printf("before fork : I am a process pid:%d,ppid:%d\n",getpid(),getppid());fork();printf("after fork : I am a process pid:%d,ppid:%d\n",getpid(),getppid());sleep(1);return 0;
}运行结果:
before fork : I am a process pid:6670,ppid:2312
after fork : I am a process pid:6670,ppid:2312
after fork : I am a process pid:6671,ppid:6670
从上面的demo代码中,我们可以了解到fork执行前的代码只执行了一次,而fork之后的代码执行了两次,这说明有两个进程都执行了这个after fork,这说明创建子进程成功
为什么说创建子进程成功呢?
我们注意观察pid和ppid
fork之后我们会发现有一个进程的ppid就是一个进程pid,说明一个是父进程一个是子进程
并且在上述运行结果中,fork之前的一个进程的pid是6670,fork之后有一个进程的pid也是6670,这说明父进程是fork之前的进程,而子进程是由fork之前的进程创建出来的子进程
总之,上述所得的结论是:fork之后,代码共享
fork返回值
接下来我们聊一聊fork的返回值问题
在man手册中,对于fork的返回值介绍如下
pid_t fork(void);
RETURN VALUE:
On success, the PID of the child process is returned in the parent, and 0 is returned in the child.On failure, -1 is returned in the parent, no child process is created, and errno is set appropriately.
上述的意思是:
fork如果创建子进程成功,那么就把子进程的pid返回给父进程且把0返回给子进程
fork如果创建子进程失败,那么就把-1返回给父进程且没有子进程被创建且错误码被设置
通过上述介绍,难道它想说的是fork有两个返回值吗?我们先看demo代码
int main()
{printf("before fork : I am a process pid:%d,ppid:%d\n",getpid(),getppid());pid_t id = fork();printf("after fork : I am a process pid:%d,ppid:%d,return val:%d\n",getpid(),getppid(),id);sleep(1);return 0;
}
运行结果:
before fork : I am a process pid:9549,ppid:5710
after fork : I am a process pid:9549,ppid:5710,return val:9550
after fork : I am a process pid:9550,ppid:9549,return val:0
首先,上述代码中打印after fork执行了两遍,分别是父子进程执行
打印的第二个after fork是子进程,第一个after fork是父进程,原因是第二个after fork的ppid和第一个after fork的pid相同
第一个after fork的返回值是第二个after fork的pid
第二个after fork的返回值是0
说明对于父子进程来说它们的id是不相同的,而id是fork的返回值,说明fork的返回值对于父子进程来说不相同,父进程拿到的返回值是子进程的pid,子进程拿到的返回值是0
从实践中我们看到,好像fork确实是有两个返回值的
接下来,关于fork的返回值我们需要了解三个问题:
1、为什么给父进程返回子进程的pid,给子进程返回0呢?难道不可以给子进程也返回父进程的pid吗?
要搞清楚这个问题,我们得搞清楚父子进程得关系是什么
首先,父进程创建了子进程,这没问题。那么父进程可以创建多个子进程吗?
不多说,这显然是可以的,只需要让父进程多次调用fork就行了嘛。那么父进程如何分清多个子进程呢?如果fork的返回值不是子进程的pid的话显然是无法区分的,所以fork会给父进程返回子进程的pid。
其次,子进程是被一个父进程创建的,这没问题。那么子进程可以被多个父进程创建吗?
这显然是不行的,对比我们现实生活中,不会有一个人有多个亲生父亲。
那么既然子进程只有一个父进程,那么子进程要找到这个唯一的父进程好找吗?显然很好找,直接getppid就可以找到父进程。既然好找,那么对于子进程来说就不需要有父进程的pid,如果给子进程返回父进程的pid,那么就是多余的操作。
最终的结论就是:父子进程是一对多的关系。父进程无法区分多个子进程所以需要从返回值中获取子进程的pid,子进程可以区分自己的父进程,所以不需要从返回值中获取父进程的pid
2、fork函数为什么会返回两次
我们都知道,fork函数的功能是创建子进程,那么接下来的问题是fork是先创建的子进程还是先返回的呢?
这个问题的答案相信不难理解,肯定是先创建的子进程再进行的返回,那么当fork函数return的时候,肯定就会执行两次,因为return也是语句,父子进程都会执行这个语句
3、上述代码id为什么既等于0,又大于0
首先,要完全理解这一点,现阶段是比较难的,我们可以初步理解一下
从需求的角度看,我们需不需要进程之间会互相影响呢?
如果要,那么今天我们登录音乐软件、聊天软件,当我们把音乐软件的进程杀掉以后,聊天软件的进程就也被杀掉了。从常识的角度,这显然是不合理的。
所以对于父子进程来说也是如此,父进程的改变不能影响子进程的改变。
那么操作系统设计的时候就要考虑这一点进行设计,至于怎么设计的,我们在下文中说
原理角度理解fork
首先,我们说过进程 = 内核数据结构 + 可执行程序
那么当fork创建子进程的时候就一定会再创建一个PCB用于描述这个子进程
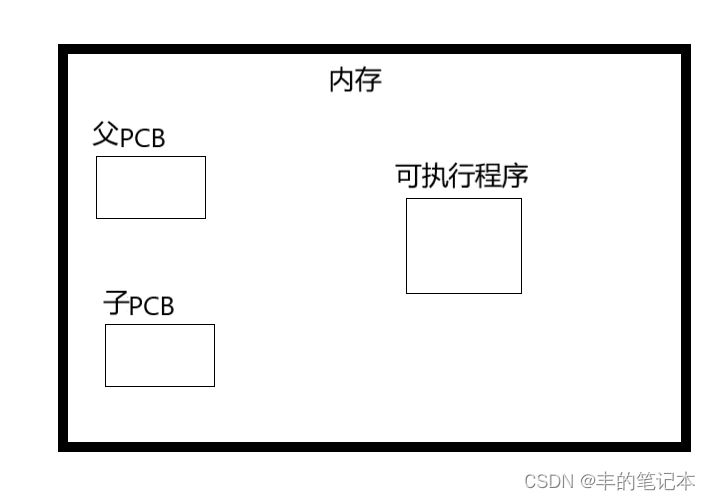
而现在问题来了,我们都说进程=内核数据结构+可执行程序,但现在我们只有一个可执行程序,且这个可执行程序是父进程的。那么我们的子进程就没有他的可执行程序,那他还是一个进程吗?
实际上,子进程其实是有可执行程序的,他其实与父进程共享,并且共享的是父进程创建出子进程之后的代码
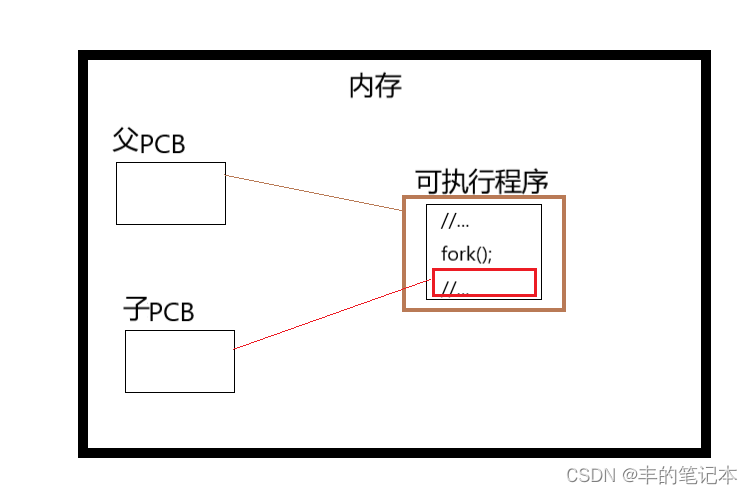
接下来的问题是,PCB中存放的是用来描述进程的属性,那么子进程的PCB中放的属性从哪来呢?
实际上,既然子进程与父进程共享一段代码,那么子进程大部分属性都会以父进程为模板,但并不是全部都以父进程为模板,有一些属性是子进程自己的,比如pid等
最后一个问题,还是fork返回值的问题,为什么fork的返回值可以为两个不同的值
实际上,为了实现父子进程互不影响,那么在对变量的存储地址的值进行修改的时候,操作系统会重新生成一个不同的内存空间,用于子进程对这个变量的修改。这其实是一种写时拷贝。所以,从表面上看是同一个变量,实际上,父子进程写入的不是同一块内存空间。
而返回的本质就是写入。所以才会发生写时拷贝
至于怎么做到同一个变量名,不同内存空间。我们需要到虚拟内存时才能了解
fork的应用
在实际使用中,我们不会像上面代码那样使用,因为创建子进程都是为了让子进程干活的,并且一般情况都是父子进程执行不同的逻辑。也就是如下使用
int main()
{pid_t id = fork();if(id == -1){//失败return 1;}else if(id == 0){//子进程执行的代码块//...}else {//父进程执行的代码块//...}return 0;
}进程属性之进程状态
再谈进程排队
在前面,我们说过进程排队就是把进程的PCB放到CPU的运行队列中,进程排队指的是进程的PCB进行排队,而不是进程的可执行程序去排队
而接下来我们要聊的是Linux内核下的进程排队实现原理
之前我们说过进程排队是从PCB链表中拷贝结点,然后把结点插入到运行队列中
但Linux下的task_struct不是按照这种方式设计的,它是在task_struct中专门有一个属性表示运行队列的结点,假设运行队列的结点,它定义为queueNode,如下图
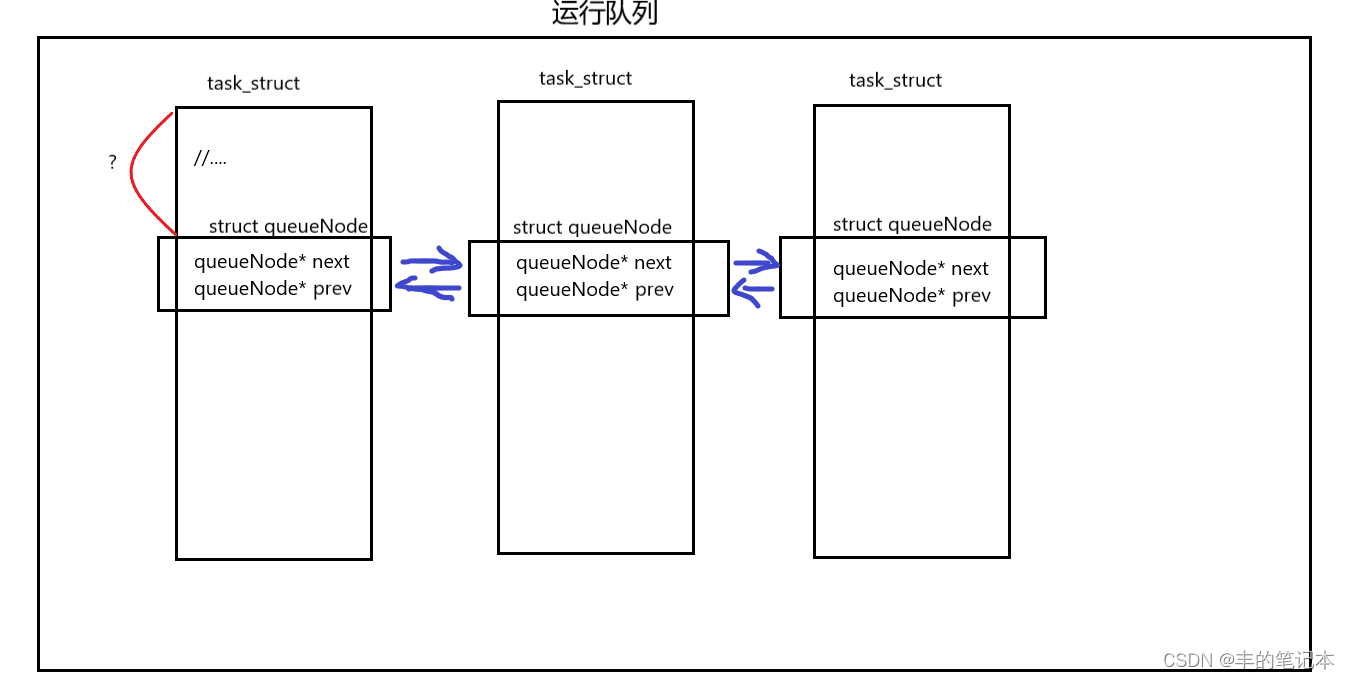
可以看到,实际上运行队列的结点被内嵌到了task_struct中
那么接下来的问题是,我的task_struct中有队列的结点,但我不是要队列结点的信息,而是要队列结点所在的task_struct的属性信息,如何做到呢?
首先要拿到属性信息,我们得找到这个task_struct的开头是在哪,在开头进行解引用就能找到信息了
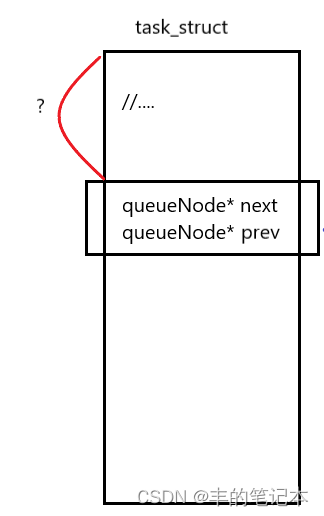
我们可以把0号地址当成是一个task_struct的开头,然后取出这个里面queueNode所在的地址最后把这个地址减去0号地址,就得到了图上?的大小,转化成代码也就是如下:
&((task_struct*)0->n)
而我们有了这个值就可以找到所对应的task_struct的开头
假设我这个队列的结点是
&q - &((task_struct*)0->n)
那么,接下来的问题是这样设计的好处是什么呢?我直接把整个PCB当成一个结点不好吗?
这样设计的好处可以使一个PCB不仅仅是链表结点,还可以是队列结点
不管它是什么结点,只要算出这个task_struct的开头,我就都能进行管理
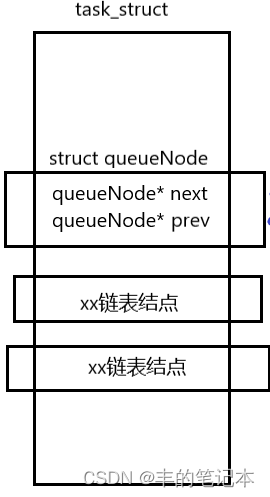
实际上,队列的底层我们就可以用链表实现,此时不管是队列结点还是链表结点,它们都共用一套增删查改的机制
进程状态
要搞清楚进程状态,我们先理解状态决定了什么!
实际上,状态本质上决定了你后续的动作
就好比我们日常生活中可能会说或听到一些话语,我今天学习状态不太好,我想休息会。
我今天工作状态不好,我想请假
灵感来自于生活,显然对于进程来说,操作系统会根据进程的状态决定它们的后续动作
大体上对于进程来说状态分为:运行状态、阻塞状态、挂起状态
补充:
我们之前说过进程排队的概念,接下来聊一聊为什么要有进程排队
实际上,在大多数的电脑中,CPU的数量是比较少的,而进程相比CPU则多的多,CPU少,进程多,这其实就是导致了进程排队的原因,所以本质上进程排队就是进程为了得到某种资源,这种资源可以是硬件资源也可以是软件资源
并且,我们需要知道,CPU被进程调度不是一直被调度到这个进程结束的,而是一个进程调度了一段时间后CPU会把它重新插入运行队列,CPU再被运行队列中靠前的调度
上述的一段时间我们称为时间片
运行状态
经过前面的铺垫,关于运行状态其实已经可以一两句话概括了
所谓的运行状态,就是指一个进程被放到CPU的运行队列中等待CPU调度时的状态
注意:这种状态不是只表示进程正在被CPU调度,在运行队列等待也是这种状态
阻塞状态
依据我们的常识可以知道,计算机中有着各种各样的硬件,比如硬盘、网卡、键盘等等
那么操作系统是如何管理这些硬件的呢?
答案是先描述、再组织
而既然要描述且这是一个抽象事物,所以就肯定要用类或结构体来描述
如下demo代码
struct device
{int type; // 1 = 键盘 , 2 = 网卡 , 3 = 显示器 ....//设备的操作方法struct device* next;//假设单链表}
那么,device中可以有队列吗?显然可以,你的task_struct中都有队列,我跟你并无区别
OK,最后一个问题,CPU是硬件吗?
很显然,依据我们的常识也知道,CPU是硬件。
既然是硬件,所以操作系统对他的描述也是device
其实,在某些时候,在运行队列中的进程可能需要等待某种资源,就好比键盘资源(scanf)
而此时,如果让他继续在运行队列中跑,那么其实是一种浪费,由于可能有多个进程都需要调用键盘资源,而键盘只有一个,所以键盘也有自己所对应的队列,实际上每个设备都有自己的队列,操作系统就把这个需要键盘资源的进程从CPU的队列放到了键盘的队列,而此时这个进程的状态就是阻塞状态,而当键盘资源已经就绪了,操作系统作为硬件的管理者会第一时间知道,此时操作系统就会把这个进程从键盘的队列中放回CPU的队列
对于需要等待除CPU以外的软硬件资源的进程我们称为阻塞
挂起状态
首先,出现这个状态有一个前提,那就是我们内存此时已经比较少了
当操作系统发现内存是比较少的时候,此时对于它来说会出现两种处理方式
第一种就是直接崩溃,第二种是想办法让内存的空间变得多一点
而操作系统肯定是选择后者,那么如何让内存变得多一点呢?
操作系统就把目光放在了一些处于阻塞状态的进程,这种进程都是为了等待某种资源
但此时它还没有得到这种资源,还无法运行,那么对于操作系统来说,它们此时是对内存空间的浪费,于是操作系统就把它们的状态改为挂起状态并且把它们所对应的代码和数据换到了磁盘中,
接下来的问题是,操作系统把他们的代码和数据放在了磁盘的哪里呢?
实际上,我们的磁盘上会有一个分区,叫swap分区,这个是专门给操作系统预留的一片空间,而操作系统就把挂起状态的进程的代码和数据放在了这个分区中
而操作系统把挂起状态进程的代码和数据放到swap分区的这一行为,我们称为唤出
当内存资源已经稍微好转了或者处于挂起状态的进程需要的资源已经就绪了,那么操作系统会把它们从swap分区中再次移动到内存,这一行为我们称为唤入
需要注意两点:
1、操作系统是把处于阻塞状态的进程的数据和代码放到swap分区,它们的PCB并没有被放到swap分区,原因是操作系统需要对PCB进行管理,如果把PCB放到外设上,就无法进行管理了。
补充:实际上,当进程刚开始创建的时候也是先创建PCB再把可执行程序放到内存,也是因为操作系统要先对这个进程做管理,就好比玩一些大型游戏的时候,虽然这个游戏体积非常大,例如80G左右,它的体积远远大于我们的内存空间大小,但我们也能流畅的玩。实际上是这个游戏进程进到内存的时候只会加载一部分,而剩下加载多少内容则放到了进程的PCB当中。所以先创建PCB也是必要的。
2、以上的挂起我们称为阻塞挂起,实际上挂起的种类非常多,还有运行挂起、创建挂起等,实际上挂起与内存资源息息相关,换句话来说,把操作系统逼急了,它什么资源都能唤入。且挂起状态我们并不常见,了解一下就好
以上,我们讲解了运行、阻塞、挂起状态,接下来从教科书的角度再理解一下进程状态
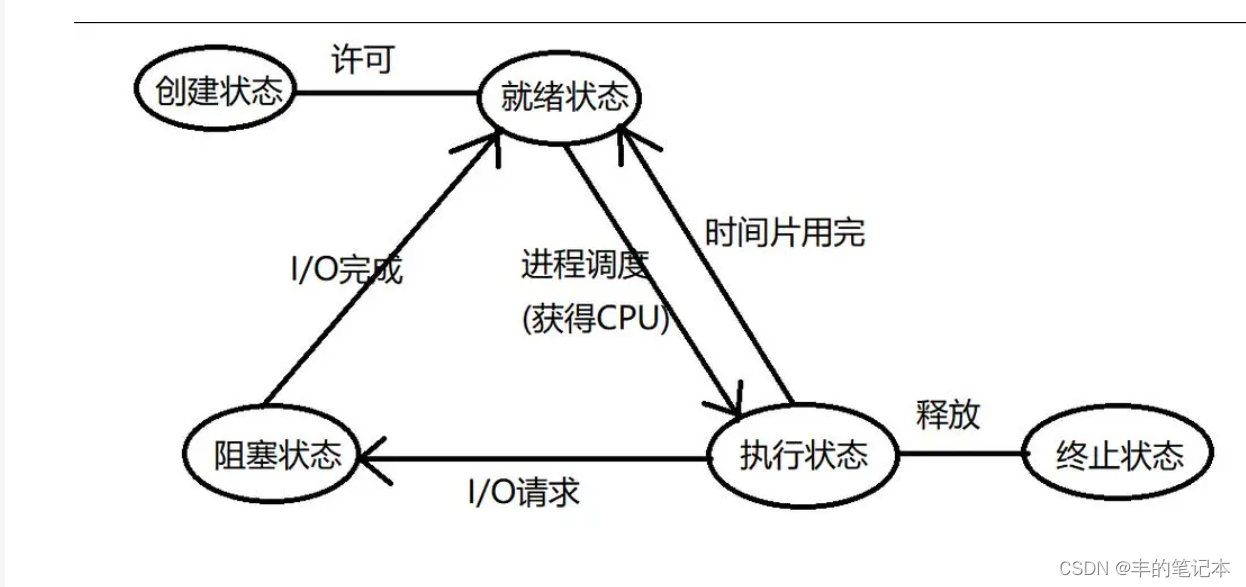
创建状态:就是进程的PCB刚被创建出来,没有被CPU加载到运行队列中
就绪状态:就是这个进程已经被加载到运行队列中,正在排队等待调度CPU
执行状态:就是这个进程正在使用CPU资源
注意:现在主流的操作系统都没有对就绪和执行状态进行区分,都把这两个状态进行二合一成运行状态
阻塞状态:由于这个进程需要等待其他的软硬件资源才能继续运行,所以这个进程被操作系统拿下来放到其他资源的等待队列中
终止状态:这个进程的代码已经执行完毕
以上,我们说了各种各样的进程状态,但实际上,上述的都是操作系统学科的进程状态分类,换句话来说,上述的这些状态在各种操作系统中都符合。
但我们作为一个学习Linux的来说,我们肯定要了解一下具体Linux的进程状态,而接下来我将介绍这个内容
Linux下的进程状态
以下,是Linux内核中实现进程状态的对应字段
static const char * const task_state_array[] = {"R (running)", /* 0 */"S (sleeping)", /* 1 */"D (disk sleep)", /* 2 */"T (stopped)", /* 4 */"t (tracing stop)", /* 8 */"X (dead)", /* 16 */"Z (zombie)", /* 32 */
};我们发现在Linux中状态一共分为7种,而我们将会对这7种进行介绍
“R”(运行状态)
运行状态其实也就是在CPU运行队列的状态,这一点在Linux下也如此
如下为demo代码
#include <stdio.h>int main()
{while(1);return 0;
}
我们把它运行起来后ps查询一下这个进程
查询结果:
[yyf@VM-24-5-centos 24.05.24]$ ps axj | head -1 && ps axj | grep test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
21990 23848 23848 21990 pts/0 23848 R+ 1001 0:40 ./test
23733 24093 24092 23733 pts/1 24092 R+ 1001 0:00 grep --color=auto test
我们看上述STAT对应的就发现test(我所运行的进程)确实为R状态,但它后面有个+是什么意思呢?
实际上,如果一个进程状态后面有+号表示这个进程在前台运行,如果一个进程后面没有+号表示这个进程在后台运行,当一个进程处于前台运行时,我们无法在命令行中使用指令。当一个进程处于后台运行时,我们可以在命令行中使用指令。我们暂时只需要知道,在后台运行的进程不能用ctrl+c的方式结束掉,必须使用kill -9 <pid>的方式进行结束
并且在查询结果中,我们会发现grep进程也是R状态,这是因为其实grep指令本身就是一个进程,而当我们使用grep指令进行过滤的时候,他只有处于运行状态才能进行过滤
“S”(浅度睡眠状态)
睡眠状态就是一个进程不在运行队列中,处于某个等待队列当中,这个进程在等待某种资源,实际上睡眠状态也就是阻塞状态的一种
如下demo代码:
#include <stdio.h>
#include <unistd.h>
int main()
{while(1){printf("hello,process\n");sleep(1);}return 0;
}
查询结果:
[yyf@VM-24-5-centos 24.05.25]$ ps axj | head -1 && ps axj | grep test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
8646 10083 10083 8646 pts/0 10083 S+ 1001 0:00 ./test
10153 10359 10358 10153 pts/1 10358 S+ 1001 0:00 grep --color=auto test
可以看到,这个进程我们进行查询时大概率都是S状态(有非常非常小的概率是在R状态)
这是因为,这个进程大部分时间都在等待sleep函数执行完成,而且就算我们把sleep注释掉,它的状态也大概率是S状态,因为printf是要在显示器上进行打印,但CPU的速度可比设备快多了,所以这个进程大概率都在外设的等待队列中进行排队等待
并且这个状态的进程我们可以通过ctrl+c进行终止进程,所以我们也把S状态称为可中断睡眠
而既然有可中断睡眠,与之对应的就是不可中断睡眠,接下来我们开始介绍不可中断睡眠
“D”(深度睡眠状态)
要想了解这个状态,首先需要搞懂为什么要有这个状态,接下来讲一个案例
注意:操作系统的内存严重不足时可能会杀掉进程
首先进程在磁盘上写入数据的时候,它肯定是让磁盘自己去写,那么当磁盘去写的时候进程在干嘛呢?假设没有D状态的话它应该是S状态,也就是它正在等待磁盘的处理结果嘛。而此时呢假设内存资源已经严重不足了,于是操作系统就需要去内存中找出空间来,而此时操作系统检测到了这个处于S状态的进程, 操作系统一看,它还在这闲着占用着内存又并不工作,所以操作系统就把这个进程给杀掉了。但磁盘在写入的时候也发现自己的磁盘空间不足了,写入失败,于是磁盘拿着这个结果去给进程。但此时进程已经挂掉了,磁盘没办法把结果给他,且这100M的数据还写入失败了,磁盘不知道怎么处理,就把这个数据丢了。而用户没有接收到任何的结果,以为成功了。所以用户就去磁盘上找这个数据,发现这个数据被丢了。并且这个数据还及其重要。所以用户一下子就懵了。
而在上述案例中,实际上每一个角色干的事都是合理的
对于操作系统来说,在内存严重不足的情况下,可以杀掉进程,这本来就是它被赋予的权利
对于进程来说,进程是一个受害者,它履行了它的责任,也是合理的
对于硬盘来说,硬盘实际上是一个搬运工,进程让他干嘛就干嘛,与他也没什么关系
每个角色做的事都是合理的,但导致的结果却不合理,问题的关键就出在操作系统杀掉进程这一步
而Linux设计者为了这方面考虑,添加了一个D状态,若一个进程是D状态则说明它此时的睡眠等待的资源是相当重要的,例如写入磁盘等,操作系统不能杀掉他。若一个进程是S状态,那说明它的睡眠等待的资源不是很重要,例如输入输出等。而上述案例中,如果进程被设置为D状态,则不会出现这种结果,这也解释了为什么Linux下的进程需要有D状态
注意:D状态也是阻塞状态,因为它也是在等待某种资源
“T\t”(暂停状态)
暂停状态是让进程暂时停下来
对于暂停状态Linux内核中主要分为两种:“T”和“t”
我们首先介绍“t”
这一种状态其实是当前进程处于被追踪的时候的暂停,就比如当我们用gdb进行调试时,这个进程运行到断点处它的状态就会被设置为这个
对于“T”,其实它的状态也是一种暂停,这个状态是当进程执行一些比较危险的指令或者操作时,操作系统会把它设置为这个状态,并把进程暂停处理
实际上,暂停状态也是为了等待某种资源,当gdb调试的时候的t是等待gdb的下一个控制指令发出,而T是等待操作系统对这个进程的指令,所以暂停状态本质也是阻塞状态
“Z”状态与“X”状态
首先,我们先聊Z状态
在刑侦片中,经常会出现的一个片段是一个人突然之间发生某种意外倒地不起了,而当警察来了之后是不是直接就把尸体直接抬走进行人道处理呢?显然不是的,警察来到现场以后首先会判断一下这个人是不是真的死了,如果这个人真的死了,那么警察还会保留现场,再调查一下这个死者的死因以及一些后续处理,最后才会把这个尸体抬走进行人道处理。
而上述处理是针对一个人死亡时的处理,那么对于进程来说呢?
首先,对于进程来说它的功能就是处理某些工作,也就是执行它的代码和数据,对于进程来说,死亡就相当于它把代码和数据都执行完了,但同样的,对于这个进程执行完毕进行退出之后,还需要知道它死亡(退出)时的情况,就比如你是正常退出的还是异常退出的,而接收这个情况的对象就是这个进程的父进程,父进程就相当于法医。而这个进程的退出情况需要被保存,那么保存在哪呢?其实也就是保存在这个进程的PCB里,而如果父进程还没有读到子进程的退出信息时,这个进程就会被操作系统设置为Z状态,这个状态也称为僵尸状态
也就是说,父进程一定要知道子进程的进程状态,如果它处于僵尸状态,说明父进程就需要读它的退出信息,所以子进程的PCB在退出时不会立马销毁,他还需要保存自己的退出信息,只有当父进程读完了子进程的退出信息后,这个子进程的PCB才能销毁
换句话来说,也就是如果父进程一直不读取子进程的退出信息,那么子进程是不是一直是僵尸状态呢?是的,基于这一点,我们写出如下demo代码
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{pid_t id = fork();if(id == 0){//子进程printf("start:child\n");sleep(5);printf("end:child\n");exit(0);}//父进程sleep(50);return 0;
}
上述代码当打印出end:child之前,子进程一直处于睡眠状态,当打印完end:child之后,由于子进程是直接退出的,且父进程没有读取这个子进程的退出码,所以它的状态是Z
[yyf@VM-24-5-centos 24.05.25]$ ps axj | head -1 && ps axj | grep test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
8646 9497 9497 8646 pts/0 9497 S+ 1001 0:00 ./test
9497 9498 9497 8646 pts/0 9497 Z+ 1001 0:00 [test] <defunct>
而至于父进程如何读取子进程的退出信息,这一点我们在之后的文章会说
注意:处于僵尸状态的进程如果不被读取也就意味着它的PCB会一直存在,此时会造成内存泄漏
接下来聊一聊X状态
这个状态是真正的死亡状态,也就是当父进程读取完处于僵尸状态的子进程后,这个子进程就是处于这个状态
而对于上述的内容,都是子进程先死亡的情况,那如果是父进程先死亡呢?于是基于这一点我们得聊聊一个新的补充概念,孤儿进程
补充:孤儿进程
首先,我将设计一个场景,就是父进程创建了子进程,然后父进程先退出,然后我们看看子进程的情况
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int main()
{pid_t id = fork();if(id == 0){//child int cnt = 10;while(cnt--){printf("I am child,pid:%d ppid:%d\n",getpid(),getppid());sleep(1);}//子进程运行10s}//fathersleep(3);//父进程运行3s后退出exit(0);return 0;
}
[yyf@VM-24-5-centos 24.05.25]$ ./test
I am child,pid:18950 ppid:18949
I am child,pid:18950 ppid:18949
I am child,pid:18950 ppid:18949
[yyf@VM-24-5-centos 24.05.25]$ I am child,pid:18950 ppid:1
I am child,pid:18950 ppid:1
I am child,pid:18950 ppid:1
I am child,pid:18950 ppid:1
I am child,pid:18950 ppid:1
I am child,pid:18950 ppid:1
I am child,pid:18950 ppid:1
可以看到,当父进程死亡后,子进程会被1号进程领养,而1号进程就是操作系统
当这个子进程的父进程死亡时,我们称这个进程是孤儿进程
至此,本篇内容结束,对于进程属性还有许多的内容,但由于篇幅有限,所以下篇博客我们再继续介绍,希望多多三连!!
这篇关于【Linux系统编程】进程概念、进程排队、进程标识符、进程状态的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









