本文主要是介绍人生苦短,我学python之数据类型(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

个人主页:星纭-CSDN博客
系列文章专栏:Python
踏上取经路,比抵达灵山更重要!一起努力一起进步!
目录
一.集合
1.1子集与超集
1.2交集,并集,补集,差集
1.intersection(英文:交叉)函数
2.union(英文:联合)函数
3.difference函数
4.symmetric_difference()函数
二.bytes
三.bytearray
一.集合
1.1子集与超集
子集和超集是集合论中的概念,用来描述一个集合是否是另一个集合的一部分。
子集:一个集合A是另一个集合B的子集,当且仅当A中的每个元素也是B中的元素。换句话说,A中的所有元素都在B中出现。用符号表示为A⊆B。
超集:一个集合B是另一个集合A的超集,当且仅当A中的每个元素也是B中的元素。换句话说,B中包括了A以外的其他元素。用符号表示为B⊇A。
举例来说,假设有集合A={1, 2, 3},集合B={1, 2, 3, 4},集合C={1, 2}。
- A是B的子集,并且可以表示为A⊆B。因为A中的每个元素1、2、3都在B中出现。
- B是A的超集,并且可以表示为B⊇A。因为B中包括了A以外的元素4。
- A是C的超集,并且可以表示为A⊇C。因为A中包括了C以外的元素3。
- C是A的子集,并且可以表示为C⊆A。因为C中的每个元素1、2都在A中出现。
在集合论中,空集合是任何集合的子集,因为空集合中没有元素,也就是说它的所有元素都属于另一个集合。
子集:如果集合S1的任何一个元素都是集合S2的元素,那么则称S1是S2的子集
超集:如果集合S1的任何一个元素都是集合S2的元素,那么则称S2是S1的超集
a = {1, 3, 5}
b = {1, 3, 5, 7}
print(a.issubset(b), b.issubset(a)) # 输出True False
print(a.issuperset(b), b.issuperset(a)) # 输出False Truea是b的子集,b是a的超集
a.issubset(b)用于判读a是否是b的子集,是就返回True,不是就返回False。
a.issuperset(b)用于判读a是否是b的超集,是就返回True,不是就返回False。
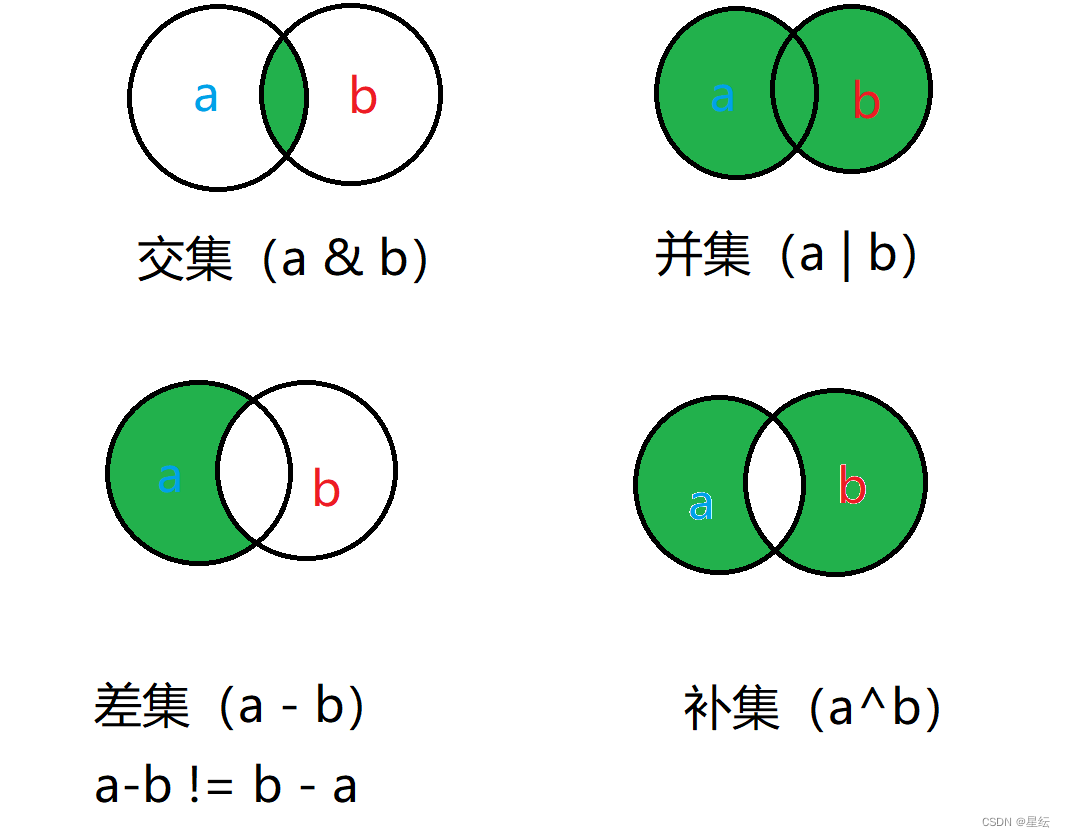
1.2交集,并集,补集,差集
a = {1, 2, 3, 4, 5}
b = {1, 3, 5, 7, 9}
print(a & b) # 输出{1, 3, 5}
print(a | b) # 输出{1, 2, 3, 4, 5, 7, 9}
print(a - b) # 输出{2, 4}
print(a ^ b) # 输出{2, 4, 7, 9}
- 操作符&求两个集合的交集
- |求两个集合的并集
- -求两个集合的差集
- ^求两个集合的补集
根据一下图示更方便理解
1.intersection(英文:交叉)函数
这个函数的作用与intersection()函数都可以求两个集合的交集。
操作符&和intersection函数实现的功能相同,即计算集合的交集。但是它们的使用方式有一些区别:
- 操作符&:操作符&是Python中的一个集合操作符,用于计算两个集合的交集。可以直接使用操作符&来计算交集,例如:set1 & set2。
- intersection函数:intersection函数是Python中集合类的一个方法,用于计算两个集合的交集。需要将一个集合作为参数传递给另一个集合的intersection方法,例如:set1.intersection(set2)。
区别:
- 操作符&是一个操作符,可以直接使用,比较简单直观。
- intersection方法是一个函数,需要将一个集合作为参数传递给另一个集合的方法,代码稍微繁琐一些。
总的来说,操作符&和intersection函数的功能相同,选择使用哪种方式主要取决于个人的编码习惯和需求。
2.union(英文:联合)函数
求两个集合的并集
操作符和union函数都可以用来合并两个或多个集合,但是它们有一些区别。
-
使用操作符"|":比如使用
set1 | set2可以将两个set集合合并成一个新的集合。这种方式会自动去除重复的元素,并且返回的结果是一个新的集合。 -
使用union函数:比如使用
set1.union(set2)可以将两个set集合合并成一个新的集合。这种方式也会自动去除重复的元素,并且返回的结果是一个新的集合。
区别:
- 语法不同:使用操作符"|"时,需要在两个集合之间使用操作符;而使用union函数时,需要调用集合对象的union方法。
- 返回值不同:使用操作符"|"时,返回的是一个新的集合;而使用union函数时,返回的是一个新的集合。
- 对原集合的影响不同:使用操作符"|"时,原集合不会发生改变;而使用union函数时,原集合不会发生改变。
总结:操作符和union函数的主要区别在于语法和返回值,但是它们都可以实现合并集合的功能。
3.difference函数
操作符 "-" 是一个二元操作符,用来计算两个数的差值。它将两个数进行减法运算,返回相减后的结果。也可以求两个集合之间的差集
而 "difference" 函数是一个集合操作函数,用于计算两个集合之间的差集。它接受两个集合作为参数,并返回一个新的集合,其中包含了第一个集合中存在而第二个集合中不存在的元素。
因此,操作符 "-" 和 "difference" 函数在功能上是有些不同的。前者用于计算数值之间的差值,也可以求差集,而后者用于计算集合之间的差集。
4.symmetric_difference()函数
操作符^和symmetric_difference函数的区别在于它们的用法和返回值。
- 操作符^:在集合运算中,操作符^表示对称差集(symmetric difference),即返回两个集合中不同时存在的元素组成的集合。使用操作符^可以直接对两个集合进行对称差集运算。
例子:
set1 = {1, 2, 3}
set2 = {2, 3, 4}
result = set1 ^ set2
print(result) # 输出{1, 4}
- symmetric_difference函数:symmetric_difference函数是集合类的一个成员函数,用于计算两个集合的对称差集。该函数接受一个集合作为参数,并返回一个新的集合。
例子:
set1 = {1, 2, 3}
set2 = {2, 3, 4}
result = set1.symmetric_difference(set2)
print(result) # 输出{1, 4}
总结:操作符^和symmetric_difference函数的功能相同,都可以用于计算两个集合的对称差集。但使用操作符^更简洁直观,而symmetric_difference函数则更灵活,可以用于任意两个集合的对称差集计算。
二.bytes
bytes是Python中的一种数据类型,它是一个不可变的字节序列。它可以存储二进制数据,如图像、音频、视频等文件,以及网络传输中的原始数据。
bytes对象由一系列的字节组成,每个字节的取值范围是0~255。bytes对象可以通过字符串、整数、字节数组等方式创建。
bytes对象与字符串对象之间可以相互转换。可以使用bytes()函数将字符串转换为bytes对象,也可以使用decode()方法将bytes对象转换为字符串。
使用bytes对象可以进行一些字节级别的操作,如截取子序列、连接、替换等。同时,bytes对象也支持一些操作符,如+、*等。
值得注意的是,bytes对象是不可变的,即不能直接修改其中的某个字节的值。如果需要修改字节,则需要先将bytes对象转换为bytearray对象,然后进行修改。
bytes对象在处理二进制数据时非常有用,特别是在网络编程和文件传输中常常会用到它。
b = b'abcdef'
print(b, type(b), len(b)) # 输出b'abcdef' <class 'bytes'> 6bytes表示只读的”字符串“类型。这样的类型是可以求len,切片等基本操作的
b = b'\x11\xff\x77'
print(b[0],b[1],b[2]) # 输出17 255 119\x后面跟数字表示这个数字是十六进制的数据。比如十六进制数据11就是十进制数字17。
b = b'a'
print(b[0]) # 输出97不同的字符在计算机中,对应着不同的数值,使用bytes这样的类型就可以将其打印出来。
三.bytearray
bytearray是Python中的一种可变的字节数组类型。它可以存储和操作二进制数据,每个元素是一个字节(byte)。bytearray可以用于读写二进制文件、网络通信、加密等场景。
bytearray对象可以通过以下方式创建:
- 使用bytearray()构造函数创建一个空的bytearray对象。
- 使用bytearray(sequence)可以通过一个可迭代对象sequence来创建bytearray对象,其中sequence中的元素是整数,范围是0-255。
- 使用bytearray(size)可以创建一个指定大小为size的bytearray对象,每个元素初始化为0。
- 使用bytearray(string, encoding)可以将字符串string按照特定的编码(encoding)转换成bytearray对象。
bytearray对象提供了许多方法来操作二进制数据,比如添加、删除、插入、拷贝、修改等。常用的方法有:
- append(x):在bytearray的末尾添加一个整数x。
- extend(iterable):在bytearray的末尾添加一个可迭代对象中的所有元素。
- insert(i, x):在bytearray的指定索引位置i插入一个整数x。
- pop([i]):移除并返回bytearray中指定索引位置i的元素,默认是最后一个元素。
- remove(x):删除bytearray中第一个值为x的元素。
- clear():清空bytearray中的所有元素。
bytearray对象还可以进行切片、迭代、比较等操作,以及与其他二进制数据类型(bytes、memoryview)之间的转换。
总之,bytearray是一种强大的数据类型,可以方便地操作二进制数据。在处理二进制文件、网络通信、加密和解密等场景中,bytearray都是一个非常有用的工具。
b = bytearray(x for x in range(5))
print(type(b), b) # 输出<class 'bytearray'> bytearray(b'\x00\x01\x02\x03\x04')bytes是可读的,bytesarray不是只读的,他是可以修改的,除此之外,两者功能类似
b = bytearray(b'abcde')
b[2] = ord('C')
print(b) # 输出bytearray(b'abCde')ord函数的功能是将一个字符串转化成对应的Unicode编码整数,对于英文字符来说,其Unicode编码于ASCII编码是类似的。
总结:列表(list),字符串(tuple),bytes,bytearray都可以视作序列类型,他们都可以通过下标或者索引访问其元素,也可以通过切片操作来获得序列。
这篇关于人生苦短,我学python之数据类型(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




