本文主要是介绍MYSQL快速简单复习笔记(白菜教程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
登录/退出
登录
mysql -u 用户名 -p
Enter password:******
退出
exit
创建数据库
CREATE DATABASE 数据库名;
删除数据库
DROP DATABASE 数据库名;
选择数据库
use 数据库名;
数据类型
常用
数值类型
- TINYINT
- INT
- BIGINT
- FLOAT
- DOUBLE
日期类型
- DATE
- TIME
- DATETIME
- TIMESTAMP
字符串类型
- VARCHAR
- BLOB
create tabele 创建表
CREATE TABLE table_name (column_name column_type);// example
CREATE TABLE IF NOT EXISTS `runoob_tbl`(`runoob_id` INT UNSIGNED AUTO_INCREMENT,`runoob_title` VARCHAR(100) NOT NULL,`runoob_author` VARCHAR(40) NOT NULL,`submission_date` DATE,PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
drop table 删除表
DROP TABLE table_name;
insert into 表中插入数据
INSERT INTO table_name ( field1, field2,...fieldN )VALUES( value1, value2,...valueN );
注意:
如果添加过主键自增(PRINARY KEY AUTO_INCREMENT)第一列在增加数据的时候, 要写为0或者null
select 查询数据
SELECT column_name,column_nameFROM table_name[WHERE Clause][LIMIT N][ OFFSET M]
*表示所有字段
where
如需有条件地从表中选取数据,
可以使用 AND 或者 OR 指定一个或多个条件
注意:
MySQL 的 WHERE 子句的字符串比较是不区分大小写的。
你可以使用 BINARY 关键字来设定 WHERE 子句的字符串比较是区分大小写的。
比较符注意这个:
<>, != 这两者都为不等于
补充:MYSQL运算符
BETWEEN
在两值之间 >=min&&<=max
select 5 between 1 and 10;
<=>
严格比较两个NULL值是否相等 两个操作码均为NULL时,其所得值为1;而当一个操作码为NULL时,其所得值为0
<>, !=
不等于
IN
NOT IN
update set
更新表中指定的数据字段,可以是多行
UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause]
delete
删除 MySQL 数据表中的记录。
能清空表中记录,但无法删除该表
// 清空表记录
DELETE FROM table_name; // 未指定whhere条件,清空表中所有记录// 清空指定记录
DELETE FROM table_name [WHERE Clause]
like
配合%模糊查询,类似正则
SQL LIKE 使用百分号 %字符来表示任意字符
mysql> use RUNOOB;
Database changed
mysql> SELECT * from runoob_tbl WHERE runoob_author LIKE '%COM';
+-----------+---------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+---------------+---------------+-----------------+
| 3 | 学习 Java | RUNOOB.COM | 2015-05-01 |
| 4 | 学习 Python | RUNOOB.COM | 2016-03-06 |
+-----------+---------------+---------------+-----------------+
2 rows in set (0.01 sec)
UNION
联合查询
- 用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。
- 多个 SELECT 语句会删除重复的数据。
有两个选项:
- DISTINCT: 删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
- ALL: 可选,返回所有结果集,包含重复数据
UNION 语句:用于将不同表中相同列中查询的数据展示出来;(不包括重复数据)
UNION ALL 语句:用于将不同表中相同列中查询的数据展示出来;(包括重复数据)
使用形式如下:
SELECT 列名称 FROM 表名称 UNION SELECT 列名称 FROM 表名称 ORDER BY 列名称;
SELECT 列名称 FROM 表名称 UNION ALL SELECT 列名称 FROM 表名称 ORDER BY 列名称;
ORDER BY
对SELECT读取的数据进行排序
- 可以使用任何字段来作为排序的条件,从而返回排序后的查询结果。
- 可以设定多个字段来排序。
- 可以使用
ASC或DESC关键字来设置查询结果是按升序或降序排列。 - 默认情况下,它是按升序排列,相当于使用
ASC。
GROUP BY
根据一个或多个列对结果集进行分组。
使用 COUNT, SUM, AVG等函数。
JOIN
INNER JOIN
内连接:获取两个表中字段匹配关系的记录。
INNER JOIN(也可以省略 INNER 直接使用 JOIN,效果一样)
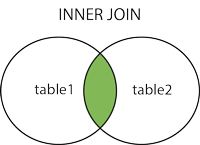
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
LEFT JOIN
左连接:获取左表所有记录,即使右表没有对应匹配的记录。
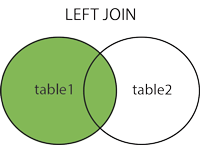
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a, tcount_tbl b WHERE a.runoob_author = b.runoob_author;
RIGHT JOIN
右连接:用于获取右表所有记录,即使左表没有对应匹配的记录。
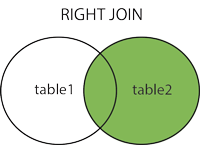
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a LEFT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
NULL值处理
使用WHERE,如果提供的查询条件字段为 NULL 时,该命令可能无法正常工作。
也就是如下列条件中使用 = 或 != 无法与NULL作判断
mysql> SELECT * FROM runoob_test_tbl WHERE runoob_count = NULL;
Empty set (0.00 sec)
mysql> SELECT * FROM runoob_test_tbl WHERE runoob_count != NULL;
Empty set (0.01 sec)
要使用 IS NULL 或 IS NOT NULL,修改成如下样式即可
mysql> SELECT * FROM runoob_test_tbl WHERE runoob_count IS NULL;
mysql> SELECT * from runoob_test_tbl WHERE runoob_count IS NOT NULL;
并且注意
<=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
regexp 正则表达式
REGEXP: REG 正则+ EXP表达式的组合
| 模式 | 功能 |
|---|---|
^ | 匹配输入字符串的开始位置, 如设置 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
$ | 匹配输入字符串的结束位置, 如设置 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
. | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,使用 [.\n] 的模式。 |
[...] | 字符集合。匹配所包含的任意一个字符。 |
[^...] | 负值字符集合。匹配未包含的任意字符。 |
p1|p2|p3 | 匹配 p1 或 p2 或 p3。 |
* | 代表 0~N个前面的子表达式 |
+ | 代表 1~N个前面的子表达式 |
| {n} | 非负整数。匹配确定的 n 次。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
使用样例:
查找name字段中以任何元音字符开头或以’ok’字符串结尾的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION,或者执行命令 SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
BEGIN 开始一个事务 等同 START TRANSACTION
ROLLBACK 事务回滚 等同 ROLLBACK WORK
COMMIT 事务确认 等同 COMMIT WORK
2、直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
使用保留点 SAVEPOINT
savepoint 是在数据库事务处理中实现“子事务”(subtransaction),也称为嵌套事务的方法。
事务可以回滚到 savepoint 而不影响 savepoint 创建前的变化, 不需要放弃整个事务。
ROLLBACK 回滚的用法可以设置保留点 SAVEPOINT,执行多条操作时,回滚到想要的那条语句之前。
使用 SAVEPOINT
SAVEPOINT savepoint_name; // 声明一个 savepointROLLBACK TO savepoint_name; // 回滚到savepoint
删除 SAVEPOINT
保留点再事务处理完成(执行一条 ROLLBACK 或 COMMIT)后自动释放。
MySQL5 以来,可以用:
RELEASE SAVEPOINT savepoint_name; // 删除指定保留点
ALTER
可修改表名,表字段(列名及类型)
也可修改存储引擎,删除外键约束,修改表字段默认值
修改表名
mysql> ALTER TABLE tbl_name1 RENAME TO tbl_name2;
修改表字段
删除表中某列字段,注意:表中如果只剩最后一列了,则无法删除
mysql> ALTER TABLE 表名 DROP 列名;
添加表中某列字段
mysql> ALTER TABLE 表名 ADD 列名 数据类型;
添加表中某列字段,也可以指定位置
关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)。
mysql> ALTER TABLE 表名 ADD 列名 数据类型 FIRST;
mysql> ALTER TABLE 表名 ADD 列名 数据类型 AFTER 要设定的列名;
修改存储引擎:修改为myisam
alter table tableName engine=myisam;
删除外键约束:keyName是外键别名
alter table tableName drop foreign key keyName;
修改字段时,你可以指定是否包含值或者是否设置默认值。
以下实例,指定字段(列名) 为 NOT NULL 且默认值为100 。
mysql> ALTER TABLE 表名 MODIFY 列名 BIGINT NOT NULL DEFAULT 100;
如果你不设置默认值,MySQL会自动设置该字段默认为 NULL。
MODIFY
修改某列字段的类型
mysql> ALTER TABLE 表名 MODIFY 列名 要修改的类型;
CHANGE
既可以修改列名,可以修改该列字段的类型
// 只修改列名 或 既修改列名也修改其类型
mysql> ALTER TABLE 表名 CHANGE i j BIGINT;// 不修改列名,只修改类型
mysql> ALTER TABLE 表名 CHANGE j j INT;
INDEX 索引
索引提高MySQL的检索速度。
教程中打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
索引分单列索引和组合索引。
单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。
组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
普通索引
添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD INDEX index_name (column_list): // 添加
ALTER TABLE testalter_tbl ADD INDEX (c);// 删除ALTER TABLE testalter_tbl DROP INDEX c;
唯一索引
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list)
主键索引
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
// 添加
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list);// 删除,
ALTER TABLE testalter_tbl ADD PRIMARY KEY (i);
// 删除主键时只需指定PRIMARY KEY,但在删除索引时,你必须知道索引名
ALTER TABLE testalter_tbl DROP PRIMARY KEY;
全文索引
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list);
显示索引信息 SHOW INDEX FROM table_name; \G
临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间,也可以手动销毁。
1. 创建
和正式的表创建不同的就是创建表时加一个TEMPORARY关键字
mysql> CREATE TEMPORARY TABLE SalesSummary (-> product_name VARCHAR(50) NOT NULL-> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00-> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00-> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
2. 删除
默认情况下,当你断开与数据库的连接后,临时表就会自动被销毁。当然你也可以在当前MySQL会话使用 DROP TABLE 命令来手动删除临时表。
和删除正式的表的方法是一样的
DROP TABLE SalesSummary;
3. 临时表的好用的方法
用查询直接创建临时表的方式:
具体要多少自己调整
CREATE TEMPORARY TABLE 临时表名 AS
(SELECT * FROM 旧的表名LIMIT 0,10000
);
复制表
方式一 :比较传统的方式
步骤一:获取数据表的完整结构。
SHOW CREATE TABLE 表名;步骤二:修改SQL语句的数据表名,并执行SQL语句。步骤三:拷贝原数据表的数据
INSERT INTO 新表名 (字段1, .., 字段n) SELECT 字段1, .., 字段n FROM 旧表名
方式二:推荐
完整复制表的方法:
CREATE TABLE targetTable LIKE sourceTable;
INSERT INTO targetTable SELECT * FROM sourceTable;其他:可以拷贝一个表中其中的一些字段:
CREATE TABLE newadmin AS
(SELECT username, password FROM admin
)可以将新建的表的字段改名:
CREATE TABLE newadmin AS
( SELECT id, username AS uname, password AS pass FROM admin
)可以拷贝一部分数据:
CREATE TABLE newadmin AS
(SELECT * FROM admin WHERE LEFT(username,1) = 's'
)可以在创建表的同时定义表中的字段信息:
CREATE TABLE newadmin
(id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY
)
AS
(SELECT * FROM admin
)
元数据

序列
自增:AUTO_INCREMENT
在MySQL的客户端中你可以使用 SQL中的LAST_INSERT_ID( ) 函数来获取最后的插入表中的自增列的值。
重置序列:
- 删除序列
- 重新添加
mysql> ALTER TABLE insect DROP id;
mysql> ALTER TABLE insect-> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,-> ADD PRIMARY KEY (id);
设置序列的开始值
一般情况下序列的开始值为1,但如果你需要指定一个开始值100,那我们可以通过以下语句来实现:
mysql> CREATE TABLE insect-> (-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,-> PRIMARY KEY (id),-> name VARCHAR(30) NOT NULL
)engine=innodb auto_increment=100 charset=utf8;
或者你也可以在表创建成功后,通过以下语句来实现:
mysql> ALTER TABLE t AUTO_INCREMENT = 100;
重复数据处理
防止表中出现重复数据
你可以在 MySQL 数据表中设置指定的字段为 PRIMARY KEY(主键) 或者 UNIQUE(唯一) 索引来保证数据的唯一性。
如果你想设置表中字段 first_name,last_name 数据不能重复,你可以设置双主键模式来设置数据的唯一性, 如果你设置了双主键,那么那个键的默认值不能为 NULL,可设置为 NOT NULL。如下所示:
CREATE TABLE person_tbl
(first_name CHAR(20) NOT NULL,last_name CHAR(20) NOT NULL,sex CHAR(10),PRIMARY KEY (last_name, first_name)
);
INSERT IGNORE INTO,执行后不会出错,也不会向数据表中插入重复数据
INSERT IGNORE INTO 与 INSERT INTO 的区别就是 INSERT IGNORE 会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
INSERT IGNORE INTO 当插入数据时,在设置了记录的唯一性后,如果插入重复数据,将不返回错误,只以警告形式返回。
REPLACE INTO 如果存在 primary 或 unique 相同的记录,则先删除掉。再插入新记录。
另一种设置数据的唯一性方法是添加一个 UNIQUE 索引,如下所示:
CREATE TABLE person_tbl
(first_name CHAR(20) NOT NULL,last_name CHAR(20) NOT NULL,sex CHAR(10),UNIQUE (last_name, first_name)
);
统计重复数据
mysql> SELECT COUNT(*) as repetitions, last_name, first_name-> FROM person_tbl-> GROUP BY last_name, first_name-> HAVING repetitions > 1;
过滤重复数据
mysql> CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl -> GROUP BY (last_name, first_name, sex);
mysql> DROP TABLE person_tbl;
mysql> ALTER TABLE tmp RENAME TO person_tbl;
也可以在数据表中添加 INDEX(索引) 和 PRIMAY KEY(主键)这种简单的方法来删除表中的重复记录。方法如下:
mysql> ALTER IGNORE TABLE person_tbl-> ADD PRIMARY KEY (last_name, first_name);
这篇关于MYSQL快速简单复习笔记(白菜教程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





