本文主要是介绍键值对系统的一致性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用一致性哈希环,可以给下n个服务器发送消息,从而数据复制
分布式集群的一致性
强一致性模型:在写入数据时不能读
弱一致性模型:可能读到不是最新的数据
最终一致性模型:弱一致性模型的一种形态,经过足够长的时间,所有数据将会传播开,并且所有副本变得一致。
分布式一致性协议:
Paxos:Paxos是一种经典的分布式一致性算法,用于确保多个节点之间达成一致的值。
Raft:Raft是一种更易理解和实现的一致性算法,类似于Paxos,但更加模块化和易于理解。
分布式事务:
两阶段提交(2PC):在2PC中,事务的提交分为两个阶段,首先进行投票阶段,然后进行执行阶段。尽管2PC有一些缺点,如单点故障和阻塞,但在某些情况下仍然是有效的。
三阶段提交(3PC):3PC是对2PC的改进,旨在解决2PC的一些问题,如阻塞和单点故障。
副本一致性:
主从复制:通过将数据复制到多个节点来实现副本一致性。写操作通常发送到主节点,然后主节点将更改复制到备份节点。
分布式数据存储:使用分布式存储系统,如Apache ZooKeeper或etcd,来确保多个节点之间的数据一致性和可靠性。
乐观并发控制:
版本向量时钟:在分布式系统中跟踪不同节点的操作顺序,以解决并发操作的冲突和一致性问题。
基于时间戳的并发控制:使用时间戳来确定事件的顺序,并在此基础上进行冲突解决。
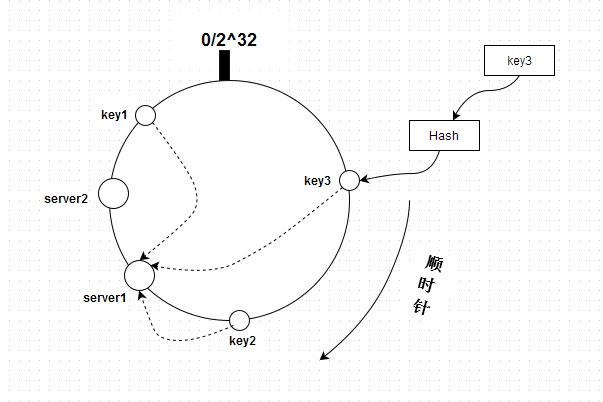
一致性哈希:
一致性哈希算法:用于将键值对分布到不同的节点上,以实现负载均衡和故障容错,并确保节点之间的数据分布均匀和一致。
不一致的解决方案:版本控制
这篇关于键值对系统的一致性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!