armed专题

Chapter 2 multi-armed Bandit
引用:https://blog.csdn.net/mmc2015/article/details/51247677 https://blog.csdn.net/coffee_cream/article/details/58034628 https://blog.csdn.net/heyc861221/article/details/80129310 The most importa

n-armed bandit _ ucb1 algorithm
前言:家里发生了一些事情,所以又耽搁了一段时间,这周交的report都有点潦草,好在ucb1本身就不是一个很复杂的算法。 参考文献:《Bandit Algorithms for Website Optimization》 This week, I have studied one of the algorithms in the UCB falmily, which is called the

n-armed bandit_Gittins index
The complexity of solving MAB (multi-armed bandit) using Markov decision theory increases exponentially with the number of bandit processes. Instead of solving the n-dimensional MDP with the state-sp

多臂老虎机 “Multi-armed Bandits”
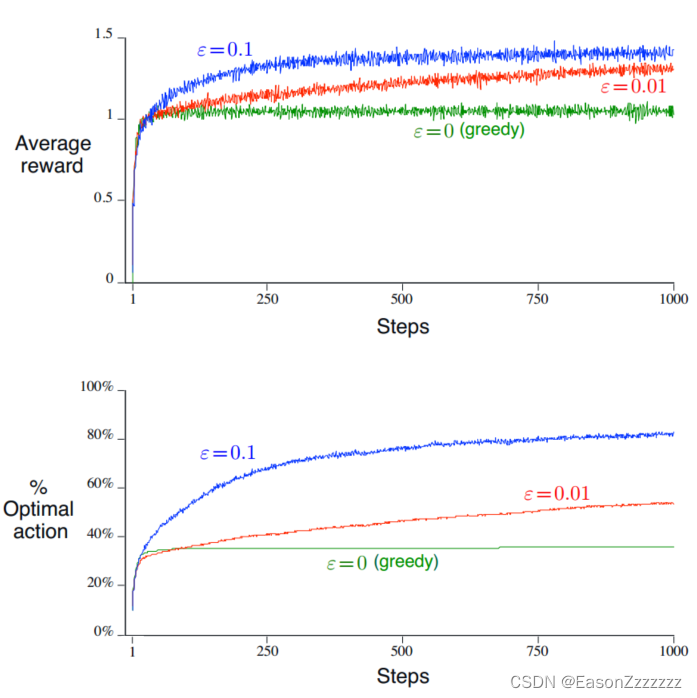
将强化学习与机器学习、深度学习区分开的最重要的特征为:它通过训练中信息来评估所采取的动作,而不是给出正确的动作进行指导,这极大地促进了寻找更优动作的需求。 1、多臂老虎机(Multi-armed Bandits)问题 赌场的老虎机有一个绰号叫单臂强盗(single-armed bandit),因为它即使只有一只胳膊,也会把你的钱拿走。而一排老虎机就引申出多臂强盗(多臂老虎机)。 多臂老虎机
【强化学习-读书笔记】多臂赌博机 Multi-armed bandit
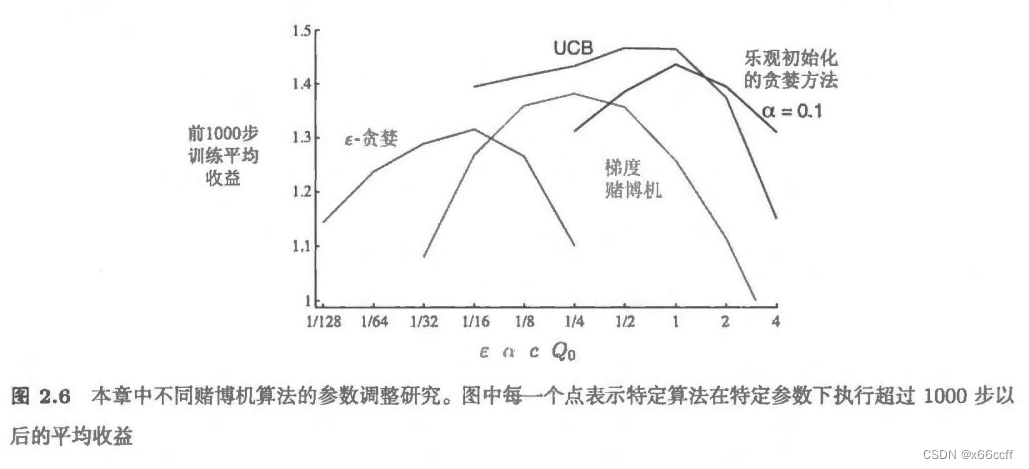
参考 Reinforcement Learning, Second Edition An Introduction By Richard S. Sutton and Andrew G. Barto 强化学习与监督学习 强化学习与其他机器学习方法最大的不同,就在于前者的训练信号是用来评估(而不是指导)给定动作的好坏的。 强化学习:评估性反馈 有监督学习:指导性反馈 价值函数