ansj专题

Lucene5学习之使用Ansj-seg分词器
这回我们来玩玩ansj分词器,由于Lucene5.0在API上有点小变化,需要修改ansj分词器源码,重新打包jar包,然后mvn install到本地仓库才能引用到项目中。至于怎么修改以及怎么打包jar,我就不过多说明了,有点麻烦,我想偷个懒,哈哈。这里我就直接把打包后的jar分享给你们,jar包注意在底下的附件里下载。 我就说说,怎么在项目中使用ansj分词器,首先pom.x

跟益达学Solr5之使用Ansj分词器
OK,直接开门见山,不绕弯子啦!基于上篇博客,我们知道了在Solr中配置分词器有两种方式,一种是直接配置分词器类,比如: <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" /> </fieldType

spark + ansj 对大数据量中文进行分词
本文要解决的问题: 实现将Spark与中文分词源码(Ansj)相结合,进行一系列中文分词操作。 目前的分词器大部分都是单机服务器进行分词,或者使用hadoop mapreduce对存储在hdfs中大量的数据文本进行分词。由于mapreduce的速度较慢,相对spark来说代码书写较繁琐。本文使用 spark + ansj对存储在hdfs中的中文文本数据进行分词。 首先下载ansj源码文
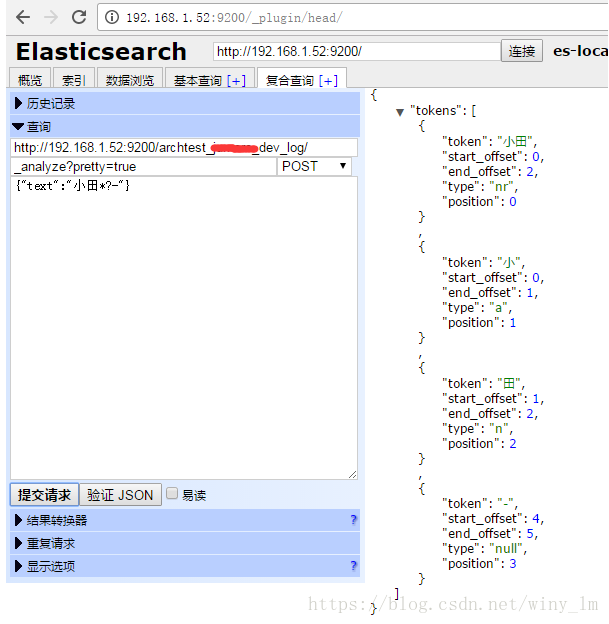
Elasticsearch ansj的停用词设置
1. 配置方法 1.1 修改elasticsearch.yml配置文件: - 打开启用停用词开关 enabled_stop_filter: true ##是否基于词典过滤 - 配置停用词文件路径: 注意这里必须是相对于 elasticsearch.yml配置文件 位置的 相对路径。 stop_path: "../dic_stop/stop.dic" ##停止过滤词典 1.2 放置