32k专题

Scaling SGD Batch Size to 32K for ImageNet Training
为了充分利用GPU计算,加快训练速度,通常采取的方法是增大batch size.然而增大batch size的同时,又要保证精度不下降,目前的state of the art 方法是等比例与batch size增加学习率,并采Sqrt Scaling Rule,Linear Scaling Rule,Warmup Schem等策略来更新学来率. 在训练过程中,通过控制学习率,便可以在训练的时候采
Linux,使用魔搭modelscope下载ChatGLM3-6B-32K大模型
1.进入命令行 2.pip安装modelscope pip install modelscope 3.进入python python 4.引入snapshot_download from modelscope import snapshot_download 5. 下载模型,cache_dir是大模型的保存路径 model_dir = snapshot_download("Zhip
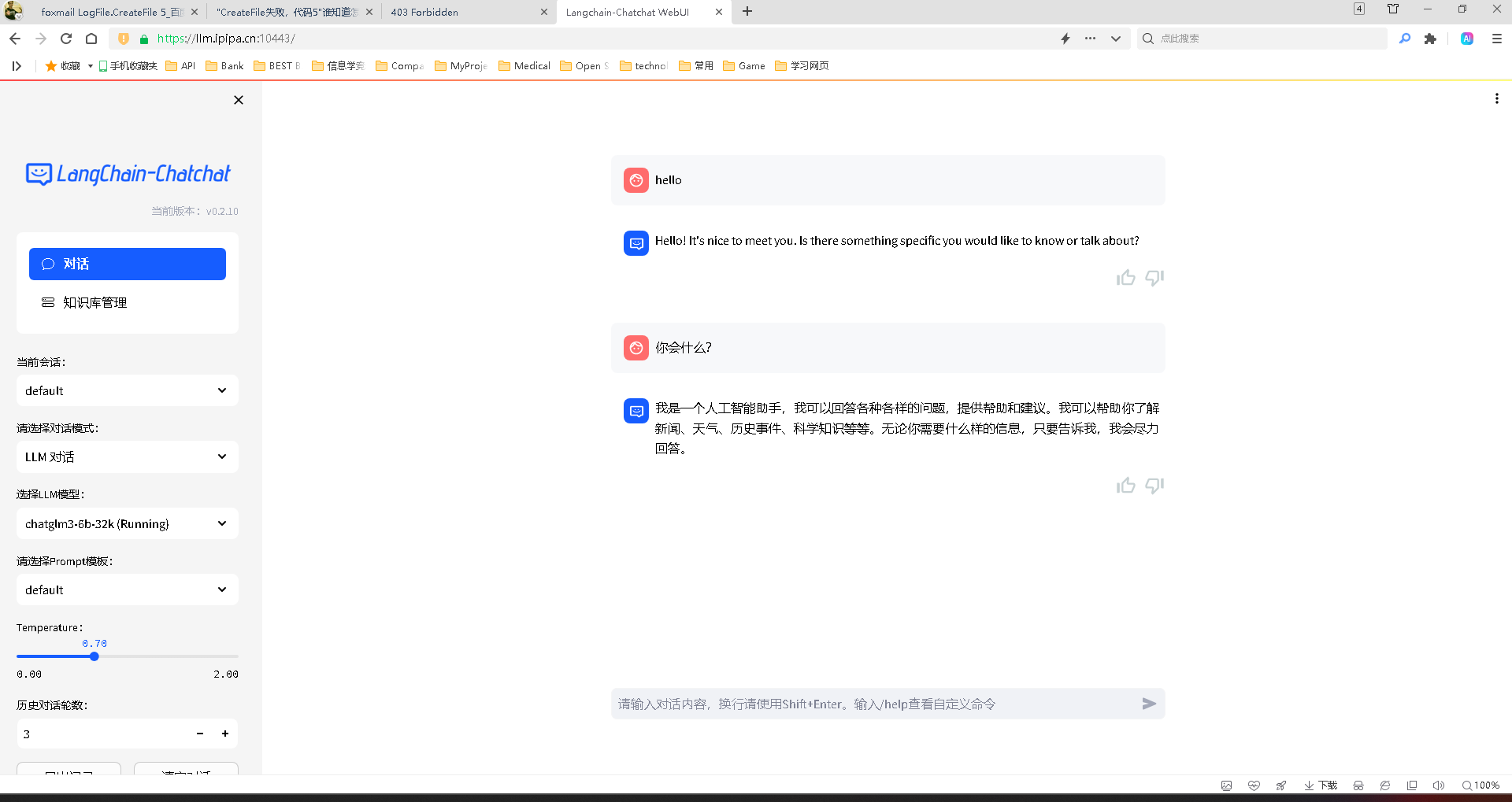
【Langchain-Chatchat】部署ChatGLM3-6B-32K教程
介绍 Langchain-Chatchat这个框架可以帮助我们更容易的部署大语言模型,之前也写过ChatGLM传统的部署教程,有兴趣的可以参考 【ChatGLM3】第三代大语言模型多GPU部署指南【ChatGLM2-6B】从0到1部署GPU版本 借助Langchain-Chatchat框架,可以用更少的配置,帮我们做了大量的细节,并且还支持知识库和Agent等功能,下面将介绍如何使用dock
FAQ资料:MT6763芯片平台能与32K兼容吗?
MTK FAQ资料: MT6763平台资料: 描述: MT6763能与32K兼容吗? 方法: MT6763只支持32 kless解决方案。

惊艳超越Claude-2.1和GPT-3.5-Turbo,Qwen1.5还藏了哪些黑科技?32K Tokens上下文支持只是开胃菜!
开源新星Qwen1.5闪亮登场!不同大小的模型,满足你的各种需求。虽然在对齐上暂时没追上GPT-4-Turbo,但别小看它!在MT-Bench和Alpaca-Eval v2的测试中,Qwen1.5可是把Claude-2.1和GPT-3.5-Turbo-0613都甩在了身后!这就是开源的魔力,未来还有更多可能等待发掘。 那么,Qwen1.5到底还有多少惊喜等着我们? 如果有其他疑问,欢迎朋友关注
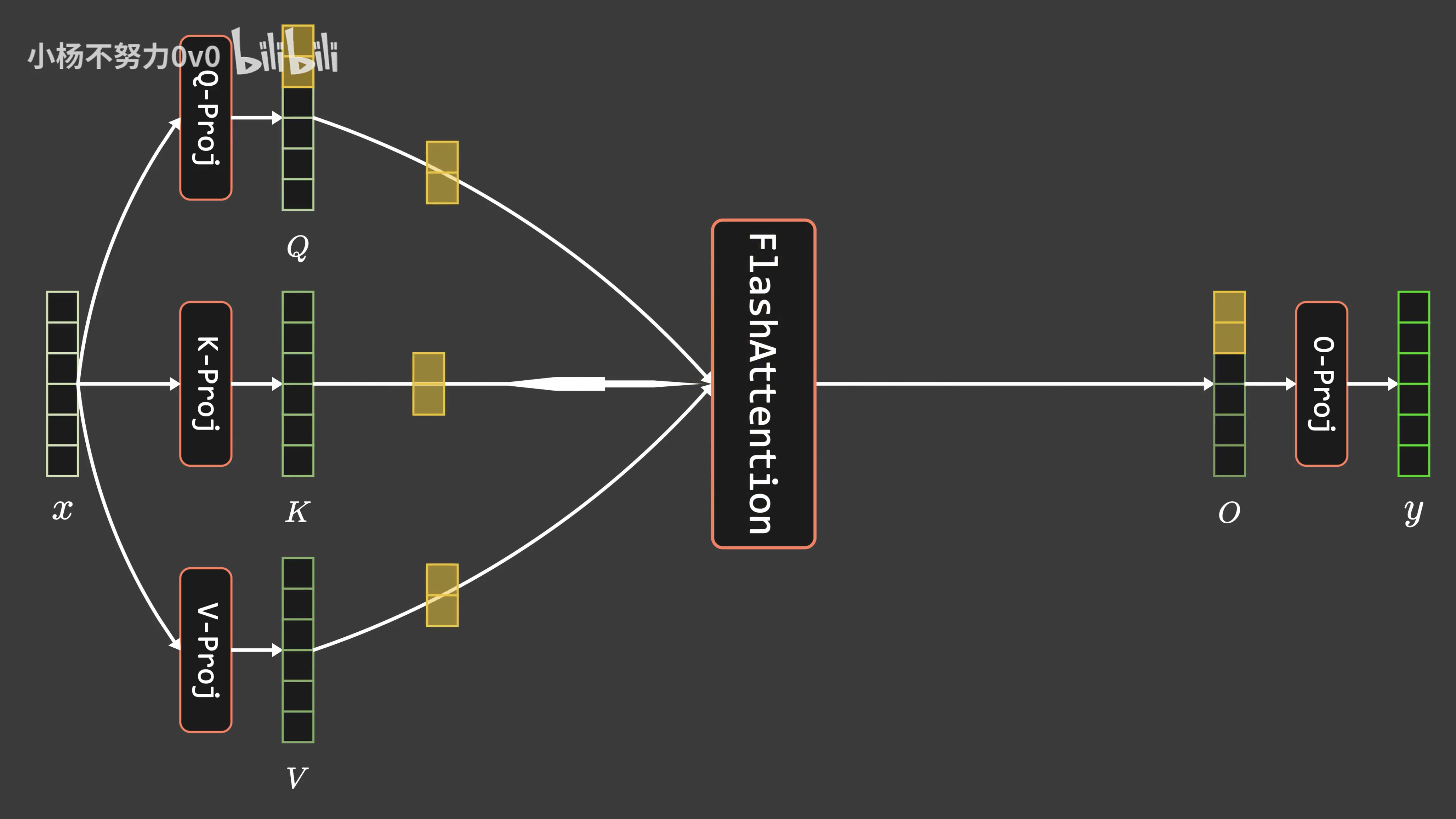
通透理解FlashAttention与FlashAttention2:让大模型上下文长度突破32K的技术之一
前言 成就本文有两个因素 第一个因素是,我带长沙的LLM项目团队做论文审稿GPT这个项目时,遇到了不少工程方面的问题(LLM方面的项目做多了,你会逐步发现,现在模型没啥秘密 技术架构/方向选型也不是秘密,最终都是各种工程细节的不断优化),比如数据的问题,再比如大模型本身的上下文长度的问题 前者已经得到了解决,详见此文《学术论文GPT的源码解读与微调:从chatpaper、gpt_academi
oracle图片大于32k,运用ORACLE的OO4O类库函数解决调用存储过程向远程数据库上传超过32K图片失败的问题...
前段时间尝试用了ODBC和ADO连接并上传图片都没能超过32K限制,最近用了OO4O终于解决了这个问题。方法及代码如下: 1 下载客户端 ORACLE官方下载链接:http://download.oracle.com/otn/other/ole-oo4o/ODAC101040.exe 2 安装并配置: 解压后,双击/disk/setup.exe,一路下一步,直到出现如下界面,并按图的顺序一路配置