10marl专题
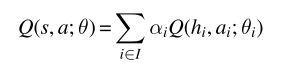
10MARL深度强化学习 Value Decomposition in Common-Reward Games
文章目录 前言1、价值分解的研究现状2、Individual-Global-Max Property3、Linear and Monotonic Value Decomposition3.1线性值分解3.2 单调值分解 前言 中心化价值函数能够缓解一些多智能体强化学习当中的问题,如非平稳性、局部可观测、信用分配与均衡选择等问题,然而存在很难直接学习价值函数等问题,特别是动作价值