100gb专题
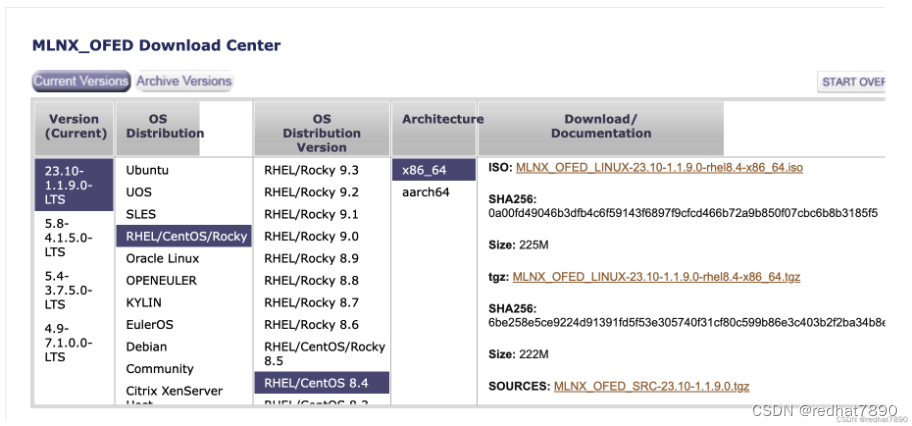
100GB Mellanox InfiniBand 网卡虚拟化技术调研
调研目的 验证 Mellanox InfiniBand 100GB网卡和SR650 Server能兼容 ThinkSystem SR650 Power On (Booting OS or in undetected OS) Machine Type/Model7X05CTO1WW 验证 SR-IOV虚拟话技术在BIOS/Firmware/Kernel/QEMU/Libvirt能被支持
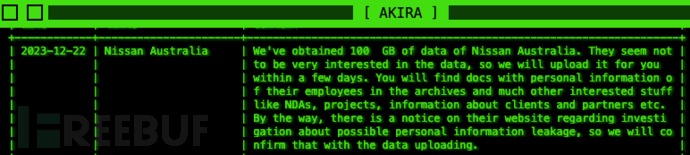
公开100GB数据,日产汽车遭勒索组织“撕票”
Bleeping Computer 网站消息,Akira 勒索软件团伙声称成功入侵了日本汽车制造商日产汽车澳大利亚分公司的内部网络系统。 12 月 22 日,Akira 勒索软件团伙在其泄漏博客上添加了一个新的“受害者”,并表示其成员从日产汽车制造商的内部网络系统中窃取了约 100GB 的文件资料。值得一提的是,威胁攻击者还宣称鉴于日产汽车公司拒绝支付赎金,接下来会陆续把盗取的敏感业务和

0.052 秒打开 100GB 数据,这个 Python 开源库火爆了!
本文转载自 GitHubDaily 许多组织都在尝试收集和利用尽可能多的数据,以改善其经营方式,增加收入和提升影响力。因此,数据科学家面对 50GB 甚至 500GB 大小的数据集情况变得越来越普遍。 不过,这类数据集使用起来不太容易。它们足够小,可以装入日常笔记本电脑的硬盘驱动器中,但同时大到无法装入 RAM,导致它们已经很难打开和检查,更不用说探索或分析了。 处理此类数据集时,通常采用
使用Python『秒开』100GB+数据!
前言 如果你50GB甚至500GB的数据集,打开他们都很困难了,更别说分析了。 在处理这样的数据集时,我们通常采用3种方法。 第一种对数据进抽样:这里的缺点是显而易见的,样本数据能否代表整个数据。 第二种使用分布式计算:虽然在某些情况下这是一种有效的方法,但是它带来了管理和维护集群的巨大开销。想象一下,必须为一个刚好超出RAM范围的数据集设置一个集群,比如在30-50GB范围内。这有点过分了。
秒开 100GB 数据,甩 Pandas 几条街
来源:量化投资与机器学习 作者:Jovan Veljanoski、QIML编辑部(译) 前言 如果你50GB甚至500GB的数据集,打开他们都很困难了,更别说分析了。 在处理这样的数据集时,我们通常采用3种方法。 第一种对数据进抽样:这里的缺点是显而易见的,样本数据能否代表整个数据。 第二种使用分布式计算:虽然在某些情况下这是一种有效的方法,但是它带来了管理和维护集群的巨大开销。想象一下,必须